

ShaunR
-
Posts
4,856 -
Joined
-
Days Won
293
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
Ton. For your path example, I would have gone for something like this. Has one other advantage over the BFI method in that paths like "c:\temp\//test//text.txt" where you have multiple separators back-to-back, are also catered for. Slightly more complicated than it needed to be really, due to the regex escape char being the same as the windows path char. I'm sure this can be improved upon though.
-
Nice!
Here is my contribution to find an object's name

// Custom TypeOf Function function returnObjectType(object) { // Constructor has syntax 'function Object(){ [native code] }' var typeRegex = /function [A-z_][A-z0-9_]*\(/; var testType = typeRegex.exec(object.constructor.toString()); // Parse and return the object's name, otherwise return null if (testType != null) { // Slice off leading 'function ' and trailing '(' to resolve object's name return testType.toString().slice(9, -1); } return null; } // Test checkObjectType function // Constructor for Data Type function UserDataType() {} document.write(returnObjectType("hi") + '<br />'); // returns String document.write(returnObjectType(2) + '<br />'); // returns Number document.write(returnObjectType(true) + '<br />'); // returns Boolean document.write(returnObjectType(new Array) + '<br />'); // returns Array document.write(returnObjectType(new UserDataType()) + '<br />'); // returns UserDataType[/CODE]Great. So you can do my documentation and my client side stuff too
 Funny how you do in your JS exactly what I'm talking about in Labview with strings eh?
Funny how you do in your JS exactly what I'm talking about in Labview with strings eh? -
Not to go off topic - but doesn't typeof just return 'object' in javascript for any user defined data types?
E.g.
function Test() {} alert(typeof new Test()); // alerts 'object' [/CODE]Yup (for objects). It will return if it is a boolean, number etc.My bad (good call)."[color=#000000]myobject.prototype" will return the class and you can just check with "===".[/color]
-
 1
1
-
-
No, Shaun. You'd create JSON Object.lvclass. As each one comes in, you'd create the object of the named type (all of which inherit from JSON Object), and then invoke "JSON Object.lvclass:Do Appropriate Processing.vi" and each class would have overridden the method to do whatever it needs to do. At no point would you type test.
Ideally you would implement this as an interface, if LV had those, but plain inheritance would suffice for the problem as you've described it here. Oh, and you'd be a lot better off than the string testing of the non-OO solution.
Show me. The string version (which I already have - see Passa Mak for a rough idea how) is about 15 VIs. If you can do even just a chart in less than 50 hand made VIs with LVPOOP I'd be surprised (It got ugly very quickly, but maybe you have a better grasp on an approach without re-inventing every property and method for every object in LV).
Back OT. I see what you are saying with a JSON object (I think). By adding an extra layer of abstraction, you can take advantage of the dynamic despatch so that type checking isn't required. But inside it is still the same. You still need to create the individual objects (from the string as said), but unless you are prepared to re-code every property and method that LV has in your child classes, you are no better off apart from if you want to substitute an XML version instead. It will still be a monster. If you can type check the object, then you can reduce the properties and methods of your children and get away from the linear escalation of the VIs.
-
But we're still back to the same fundamental point: why do you really want to check for such "equivalence"? I know and understand that some people "clearly want to" as you point out but that does beg the question IMO. Isn't there at least one better way to architect so that checking for such equivalence isn't needed?
Lets say you have a JSON stream where each element is an object (which is what JSON is). So it comes in via TCPIP and you create an object of that type using simple string/case detection so that it can be shoehorned into a class ASAP. Depending on what that type is (histogram, chart,value etc) you need to check it's type and do the appropriate processing for that class (e.g. update a chart display).Sooner or later you will need to test the equivalence (since you can't just wire a class to a case structure as you can with strings). To do this you would use the "typeof" in JavaScript if roles were reversed.
I'm all ears on a "better" architecture apart from (of course) not using classes at all - where it becomes trivial.
-
P.S. Anyone else care to guess what object comes out of the zero-iteration loop?
A NI instructor certificate?
-
I'm not a fan of the "brute force and ignorance" method of resolving stuff. I think it is an anti-pattern.
If you know what the options are, then there is nearly always a way of detecting and using the correct method/case without incurring the potentially long pauses whilst the VI "searches" for the correct solution. I do. however, use it for exiting a VI early if, for example, I'm doing a linear search and find the answer.
In your example, wouldn't the "Scan String For Tokens" allow you to find which path separator is being used and choose accordingly?
-
Here's an absurd scenario:
Me to LAVA: How do I do something?
LAVA to me: Like this.
Me to LAVA: Oh, thank you so much! That's just what I was looking for.
 That was fast; you folks are the best.
That was fast; you folks are the best..
.
.
<some time later...>
Me to myself: I can't use that code, because the author has a copyright...

Exactly! But I bet the latter never happens and you are in danger of the copyright holder coming-a-chasing with "Shaftya & Yermom Lawyers inc"
But how many times have people posted someone elses code in the vein of "I found this by joe bloggs to be really useful and will solve your problem".
-
Couldn't you also use the Get LV Object Class Path?
Or if the actual path gives problems, maybe use the Get LV Class Info.
lol. Posted too soon. It's going to be hard to beat 0 ms
-
(isn't it better to ask forgiveness than permission?
).Not when it comes to licenses. Asking for permission is free. Forgiveness is very expensive and involves lawyers.
Thanks for the answer.
It's a nice solution but, I read that it's under Creative Commons Attribution-Non-Commercial-Share Alike license. I'm not a lawyer and my English creaks a lot, therefore here my question: can I use this code and distribute it with an application which purpose is to customize a device without run into law problems? The end user of this application doesn't buy the application but the device.
PM me with your email address, and we'll sort out a commercial usage waiver to remove all doubt.
-
-
I think the bit of info you are missing is that it is an Event Queue. By using the val (sig) you are simply placing which cases to execute at the tail of the queue. It's not like event branching (as you would expect from, say a PLC). So when you execute two val (sig) within a case, you are adding two instructions to the queue. It is not until the loop goes round again, that the queue is re-read and the case at the head of the queue is taken and executed.
-
I don't believe that a forum needs to so inform particular persons. Once material is posted, unless it is specifically marked as protected in some way, it is de facto, no longer protected. If a license hold (or equivalent) of some protected code posts such code, then that person is liable for that and any subsequent non-authorized use of the code.
At least that's what I understand about it.
Indeed. As did I. However consider this:
In all countries where the Berne Convention standards apply, copyright is automatic, and need not be obtained through official registration with any government office. Once an idea has been reduced to tangible form, for example by securing it in a fixed medium (such as a drawing, sheet music, photograph, a videotape, or a computer file), the copyright holder is entitled to enforce his or her exclusive rights.
<snip>
In 1989, the U.S. enacted the Berne Convention Implementation Act, amending the 1976 Copyright Act to conform to most of the provisions of the Berne Convention. As a result, the use of copyright notices has become optional to claim copyright, because the Berne Convention makes copyright automatic.
[my own emphasis]
http://en.wikipedia.org/wiki/Copyright#Obtaining_and_enforcing_copyright
-
1
-
-
Software released in the CR obviously has its Copyright status displayed. But what about the example code etc posted in threads - not only here, but on any other boards (like NI)?
There are a lot of very useful code snippets and packages around, but is software distributed without a license at all, actually usable without recrimination as we (I at least) have assumed in the past? Are we (technically and legally) actually able to post other peoples non-licensed code or even use it without permission of the original author (who may not be available or even known)? Should sites state that any "donated" code in forums (outside the CR) becomes public domain and they forfeit their copywrite claims or make it clear that the authors original rights are entirely preserved to clarify?
-
1
-
-
I believe this to be the more right way, but one way is to do as you said, where you have a value signaling property on a control that calls an event. I feel like this is harder to follow, and harder to debug.
+1 But we all do it
. I have had mixed success with using Event Structures as state-machines (UI becoming unresponsive due to lengthy code execution, getting UI updates because it's locked in another frame somewhere etc). I tend now to use the event structures only for select user events and FP events, and message a proper state-machine via queues and/or notifiers (stop, start, pause etc).Additionally, I tend to dynamically load state-machines because if all else fails, you can just crowbar it without your app freezing.
-
I have a TDMS file structure that holds calibration tables each with associated DUT header information (SN, Model Number, Manufacturer, etc) assigned as Group Properties. In SQLite it seems that I must lay everything out as a flat table, first columns being the DUT header variables and then the last column being a blob or xml string representing my cal table data. I was wondering if I am overlooking some better way of organizing the data...
Your data will (should) be split over multiple tables (whether SQLite , MySQL, or access etc). So your DUT header info will be in one table and results in another, maybe the blobs in another. They will all reference each other via IDs. It depends how you want to set up your schema, but group properties and results would be different tables.
-
Methods/accessors/wrapper VIs should be simple (do one thing, do it properly), so for most of the time there will not be the need for multiple variant inputs to the main VI.
I tend to make a distinction here. An accessor (for me) will be of the ilk "do one thing, do it properly" (get name, get value set name, set value etc). But a wrapper would be a simplifier of a more complex function or "wrap" several "Methods" to yield a new function.
There is no boilerplate code with the DVR (that is why it is less coding).
Sure data is bundled/unbundled but this is the state data i.e. the data that is persistent for that module - same as in an AE:
Of course there is. It's the IPE, (un)bundles, case structure and the "get ref". That's why all the accessors look identical at first glance and why you can use a wizard to create them (or a template vi from the palette or your Save As (copy) gets a thorough workout).
I don't agree with sharing inputs for methods.
That strikes me as a bit odd, for you to say, since since overrides (and overloading) are the epitome of input sharing.
Yes, it may appear advantageous to share them initially - especially if a module starts off small.
But it violates encapsulation (and I aside for that I find it confusing).
I disagree. It has nothing to do with encapsulation.
What if we have to change the inputs for Method 1 in the future - how do we know that it won't affect any other methods?
We don't. If each method has it's own input/output cluster then we can confidently make changes to that method.
We do not need to worry about this with the DVR-IPE implementation.
"What-ifs" don't feature much in my designs nowadays. If there is an immediate "genericism" then I will most likely code it that way. Otherwise it will be to spec and no more. I exclusively use an iterative (agile) development cycle so changes will be factored in on the next cycle and costed accordingly. If you don't need to worry about impacts of changes on other functions, then regression testing is a thing of the past, right? The fact is, most changes affect most things to a greater or lesser extent. With linear coding (which is what this is), you've just got more to check.
In the example you are referring to, this is your method's interface:
In order to reuse your states you have created an input Enum that is a subset of your module's Command Enum - now they are coupled to each other.
A change will mean you will need to make a change in two places.
Yup. Coupling is a bad thing. Oh hang on.
 I have to get info from here...to here. How do I do that if I uncouple them?
I have to get info from here...to here. How do I do that if I uncouple them?Coupling, as has been discussed here before, is a balancing act the same way as efficiency vs function.
Now this method interface can still be replicated using a DVR-IPE - and I think it's cleaner/more-robust (just throw in the paths):
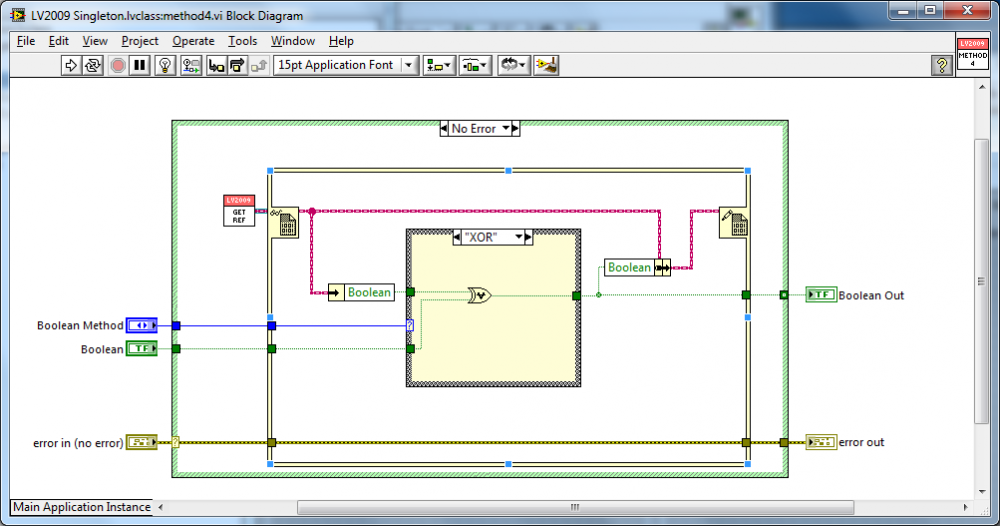
Yup. I like that. I'm still warming...not red hot yet though.
 Now re-use it for integer types.
Now re-use it for integer types.Linear programming is fine, but tends to lead to bloat, very little re-use and, if used ad-nauseam inflexible code. If you want software to create software, then it's great because it is crank the handle and you get one for everything, all the same, with a slight variation. But the cost is long term maintainability, increased code-base, compile times and re-use.
This is the reason I like polymorphic VIs, but think very carefully before using them. They, in themselves are re-usable and give the ability to adapt-to-type making it easier for users. But they are code replicators. Copy and paste managers. Hierarchy flatteners. And that doesn't sit well with me.
Back to topic

-
It does not have to be a class, here I changed it to a cluster and updated the DVR refnum and the rest of the code stays the same (in that example).
Ok so I'm clear on that now.
Ok, so now you have a wrapper methods and you have created a robust API IMHO - I like this API think it is robust like the DVR and the AE I posted e.g. you could change the implementation of underlying code (from DVR/Variant/AE) and it would not affect the API or end user.
However, I would disagree that it less work than the DVR module I posted:
That's not what I said. I said it wasn't a fair comparison (your original AE and the super slim one) and that there is little difference in effort for the more equivelent one I supplied.
So the example I posted (and you modified) is quite simple.
It's different? Wasn't intentional. I did save As (copy) a few times so that I didn't have to re-invent the wheel. Maybe something got messed up when it recompiled.
How are you going to handle multiple inputs for a method?
E.g. each method has 2 or more inputs.
For your implementation (variant) I see two options (there may be others?)
- More Variant inputs on the CP of the AE
- Or the interface to the AE stays the same and you create a typedef Cluster of the inputs for that method and convert them back on the other side.
In (1) more variant inputs could get messy fast and hard to manage in the AE?
<snip>
In (2) creating a Cluster means that you are going to have the exact same issues I have highlighted in terms of boiler plate code.
No 2. With a slight variation (I know you will pick me up on moving the typedef cluster outside the AE, but in the long run it's worth the "potential" pitfall. If we are supplying accessors, then it's only a pitfall for us, not the user). So I am deliberately sacrificing a small bit of robustness for a large gain in flexibility.
Accessor
AE
I don't think it's any different to the boiler plate code that you have to use with a DVR. But there is a big motivation for doing this as I hope you will see a bit further down.
So the typing issues has to do with the inputs/outputs to the AE not the state (persistent) data of the either module.
The DVR is the state (albeit a reference to the state - accessed safely using the IPE)
The DVR method inputs/outputs do not need to be isolated/grouped/protected etc... as there is only a single VI that will use them.
In order to handle multiple inputs I don't have to do anything special, thus this makes the DVR less coding.
Not strictly true. You still have to create the bundle and un-bundles in the accessors (and the extra controls/indicators etc) the same as I do in the above images (if changing a current implementation). If you are adding new "Methods" then yes. It only affects the new VI. Wheras I (may) have to create the new VI and add the cases to the AE.this is the point I was making about selection via frames or via VIs. This, however is both a strength and a weakness for the DVR method
.
IMHO the classic AE is not as robust, I have already addressed the following as to why I think it is not and why it should be wrapped to provide a more robust API to the end user:
Additionally the Command Enum should be private/hidden as e.g. this will not allow user to run private methods.
Point of interest/view etc. I don't consider AE=API.An API might be composed of many AEs which are self-contained sub-components. (Maybe that's just in my world though)
Considering what I just said, the Cmd enum is not private in an AE, it is public. Why should it be private? (what was I saying earlier about anal computer science?). We want the user to be able to choose the methods and there is nothing in the AE that he shouldn't be accessing (unless you've not partitioned correctly and have loads of methods that are internal only-a state machine is an abuse of an AE!). If it's not on the enum, then he can't access it so why go making it harder for him to do so? You wouldn't go making a drop-down on a front panel private, would you?
I like the DVR method, now I know more about it and will certainly be looking at some of my current implementations to see if this type would be better. But it has one weakness which (as I stated earlier) is also it's strength.
So here's the kicker.
It has one accessor (VI) for each and every method!
We've covered the ground with different inputs and (I think) there is little in it (but the DVR is definitely in the lead at this point). What if we have multiple methods but the same input type?
Lets say we have in our AE example the boolean input but we can do AND, OR, XOR, NAND, NOR, NXOR etc. Thats 6 more accessors (VIs) for the DVR all looking remarkably similar except for the boolean operation. That's not promoting code-reuse and and inflates the code-base.
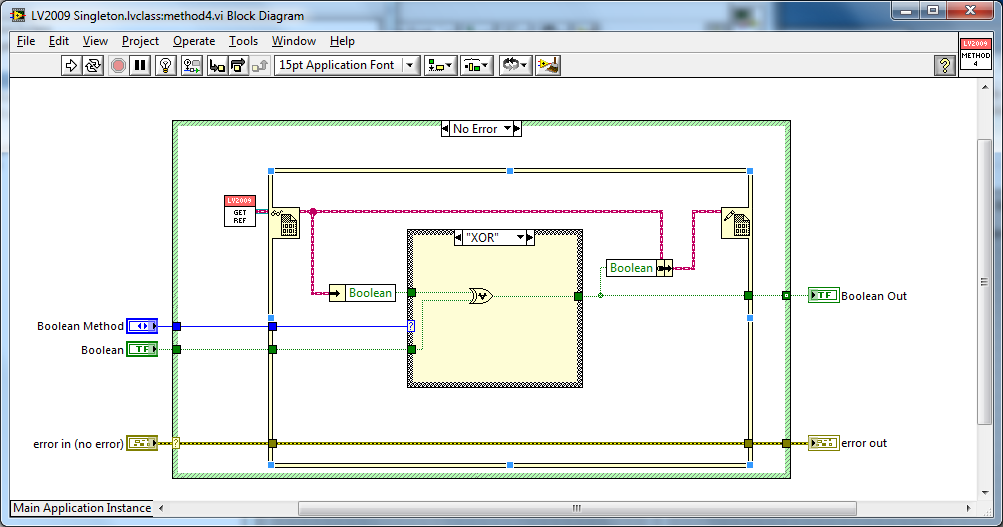
This is the (single) accessor for the AE with the 6 extra operations (1 extra type-def).
I have to modify the case structure to include the extra operations, but I only have 1 "vi" and 1 typedef ("boolean Method") to maintain regardless of the number of boolean operations. The codebase also doesn't change i.e there is zero increase in the number of VIs for increasing boolean operations. This is why partitioning is so important. If you can partition your engines so that they are grouped "by function" then maintenance is easier and code re-use is increased . The DVR code-base seems to increase linearly with the methods and there also seems to be zero opportunity for re-use of the accessors.(not mentioning the compile time here
). - More Variant inputs on the CP of the AE
-
No, the LV2009 Singleton methods do not need typedef inputs.
In the AE each method should access it's own data - it unbundles it's own inputs and in bundles up it's own outputs. The cluster helps enforce this which leads to more robust code. Additionally it standardises the API (i.e. CP) to the AE main VI.
In the LV2009 Singleton example I don't need to worry about any of that as each method is a VI so it only uses those inputs/outputs.
That is why I consider the examples the same.
OK. I see what you are getting at here (great documentation post, want to write my websocket help files
). The thing is though, they are not a fair comparison. and this is why......In the second example a DVR is used purely because it is the only way for you to create a singleton (maybe I'm still hung up on classes but you wouldn't be able to unbundle so easily without it). Secondly (and more importantly) it allows you to un-type the inputs and outputs to one generic type.
In your first example, you don't "un-type" the inputs and outputs, preferring instead to provide all permutations and combinations of the types for export. This has nothing to do with singletons. Just the strict typing of LabVIEW.
I've attached an "equivalent" classic AE of your 2009 API based on a method I've used in the past (My apologies to John, I think I now understand what he was getting at with variants-without using a poly wrapper, that is). There is very little difference apart from the features that I have outlined previously. Arguably potato, potAto as to variants vs DVRs. But the (major) effect is to push the typing down into the AE thereby making the accessors simpler than equivelent DVR methods (and if those god-dammed variants didn't need to be cast, you wouldn't need the conversion back at all!)
So back to the case in point. I think that the example I have provided is a fairer comparison between the super simple 2009 API and a classic AE. Which is more robust? I don't think there is a difference personally. Which is less coding? Again. I don't think there is much in it except to point out that changes are concentrated into the 1 VI (AE) in the classic method. You could argue that to extend the classic AE you have to add a case and an accessor rather than just an accessor, but you don't actually need accessors in the AE (and they are trivial anyway since they are there just revert to type).
-
<snip>
Hmmm. It seems you have picked a rather "special" action engine to demonstrate. I'd even go so far as to saying it's not one at all. Perhaps if you could put it in context with something simple (I like simple) and I'm more familiar with (e.g a list) I might be able to see the benefit.
A list will have things like Add, Remove, Insert, Get Value etc. At it's heart will be an array of something. It will basically wrap the array functions so that you have the operations exposed from a single VI. There are two inputs (a value to do the operation on and an index if required for the operation) and one output.
With this AE, how is the DVR method more robust, simpler, less coding et al?
Here she is.
-
1
-
-
I<snip>
Nope. Still not with you here....
An action engine "by default" is a singleton, however, you are using a class cluster which is not. So if your action engine is identical to your 2009 version then the cluster at the heart of it is the same........but you don't have to use a DVR to make an AE a singleton, because it already is.
Now. To make it usable for other developers you still need to expose the different parts of the internal clustersaurus (which Is what all the type-defs are presumably for in the AE and what the poly is for so that you don't have one huge in/out cluster) but in the second example you also have to de-reference the DVR too. So are you saying that in the 2009 version you de-reference and expose one huge cluster to the external software (1 x State Class/Cluster TypeDef), or lots of VIs to de-reference and output the cluster parts (class accessors)?
What I'm not getting is that you want to break the singleton feature of an action engine (by using a class cluster?) then re-code it back again (by using a DVR) and somehow that means less typedefs for identical functioning code

What am I missing here?
-
but there is a lot less code.
I don't think you are comparing like-with-like there.
The "lot less code" piccy would equate to a single frame in the AE (or as I usually do, a case statement before the main frames) and would look identical to the class version except it would have the cluster instead of the class blob (without the for loop of course).
I also suspect that your first piccy is equivalent to a shed-load of VIs.
The only difference (in reality) between a class and an AE is that an AE uses case frames to select the operation and a class uses voodoo VIs . An AE will be 1 VI with a load of frames and a typedef to select, whereas a class will be a load of VIs with more VIs to read/write the info and selection will be what object you put on the wire. (Just because you have a wizard to generate them doesn't mean less code). In this respect by wrapping the AE in a poly, you are merely replicating the accessor behaviour (figuratively speaking-in reality you are filtering) of a class and (should) incur the same amount of code writing as writing class accessors. But you will end up with 1 VI with n accessors (for an AE) rather than m VIs with n accessors (for a class). Of course, you don't HAVE to have the accessors for an AE, it's just icing on the cake
Everything else that is different is just anal computer science.
-
This is specific to AEs:
the "typical" usage of an action engine is to use it as a SINGLETON and that the AE itself IS the API used (have fun scoping that without another abstraction layer.) Using it as a CBR node call destroys any ease of maintainability associated with AEs (typdefing the connector pane, re assigning etc.) the only alternative at this point is to make the input/output a variant to get around the octopus connector that results, performing to/from variant. I think if you are good enough to do that, you might as well just step up to classes and type-protect your inputs/outputs, and reap all the run time performance benefit of dispatching instead of case-to-variant steps.
I think singletons are inherently not extensible and lead to "god functions." Using a by-ref pattern using SEQs or DVRs is a better way to go. If you really want to go completely nuts with software engineering and maintainability, use the actor framework or some other messaging system.
FGs: I don't even consider them useful. Once again, they are a singleton; The only time I'd be happy with them is as a top level application object for immutable objects (config data?)
Maybe this is because I'm always making something work with one unit, then down the road I end up testing 6 at a time, and all the FGs are completely useless.
Try writing a logging function without a singleton.
I will pull you up on a couple of points, if I may.
1. API? Possibly. That's the developers decision. Not the fault of Action Engines.
2. Typical usage as a singleton. (I'm going to throw a controversy into the mix here
)They are not typically used as an equivalent (in OOP terms) of a Singleton, just that by default they are. They are typically used as the equivalent of an object (with minor limitations). The enumerations are the "Methods" and the storage is the equivalent of the Private Data Cluster. The terminals are the properties and if you want it not to be a singleton, then just select "Clone" from the properties (although I've found limited use for this).
If a designer stuffs so many "Methods" into an action engine, that is a partitioning issue, not a problem with Action Engines per se. It is the same as adding all properties and methods to one God Object.
Of course all the "Object Happy" peeps will cry about inheritance and run-time polymorphism. But like I said. Minor limitations (as far as LabVIEW is concerned-due to the constraints).
3. Variants as inputs.
I hate variants. There. I've said it
The "variant to data" primitive is the function that never was.Variants were the one feature that could have given native LabVIEW run-time polymorphism. Instead it's no different to using flatten to string since you still need to know the data-type and coerce it to the right type when recovering the data.The elegant approach instead of using variants (IMHO) is to use wrap the AE in a polymorphic VI to simplify the connector pane for the end user and enable it to "Adapt To Type". Then the user doesn't need to know the data type and cast. It also exposes the "Methods" as select-able drop-downs so for purists, there is no leakage of the type-def.
In summary.....
I don't think any of the points you make are attributable to the Action Engine philosophy, more of your experience with those designers that use it. All the arguments can equally be applied to by-val Objects and from the statement "Using a by-ref pattern" I'm thinking (rightly or wrongly) that the issue is with the dataflow paradigm rather than AEs.
I'm doing to change my signature back to the old one...lol
-
I'd prefer that functional globals (actually any USR) died a slow death. It is probably because I see people abuse them so easily (access scope, callers are more difficult to track than other by ref mechanisms.) As far as AEs, if I have to look at another octo-deca-pus I might just lose it.
It's not only Action Engines that suffer from God syndrome or, indeed, scope. It's like the argument between private and protected
Copyright
in LabVIEW General
Posted
I think that would be a pain. It should be sufficient that they have to check a checkbox that they agree to the sites T&Cs for software uploads (of course, the T&Cs have to exist ;p ).
The fact is that stopping it all is neigh on impossible (thinking about posting other peoples code). It's just the "arse covering" for Lavag that's important since it will be the first in line for the lawsuits if you do get a shirty uploader.