

ShaunR
-
Posts
5,034 -
Joined
-
Days Won
313
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
17 hours ago, John Welch said:
Has anyone used LabVIEW on an ARM version of Linux?
Can I Use LabVIEW on My Linux Machine with an ARM Processor?
-
On 7/13/2026 at 1:30 PM, hooovahh said:
I don't understand what you are saying here. Are you saying that if the hardware uses a DLL for example, you won't know until you try to deploy to a target where that isn't supported? I mean the VI will be broken in the context of a Linux target, so that will at least clue in the developer before having to deploy it and see it doesn't work.
No. I'm saying *if* the device is hardware independent then it wouldn't matter if a CSZ and/or Enviro device was installed and deployment of the hardware driver could be based on the platform, not the device. Rolf solved that by abstracting through VISA. However, you stipulated that you can't have both (CSZ & Enviro) classes in memory.
-
23 hours ago, hooovahh said:
I know this post is ancient by internet standards, but I've been using LVMark off and on for years now. I recently posted a Hooovahh String package here on VIPM.IO. I plan on making a video demonstrating features of that package including LVMark some day. The LVMark code is mostly unchanged from the version posted here, just some comments and VIA_Ignore tags mostly. I do think there are places where performance could be better, but I've only ever used it on relatively small strings. There seems to be other LabVIEW Markdown libraries, like the one Ton linked to (but links seem to be dead), and a QControl here that has similar functionality. I do like the simplicity of LVMark.
I wrote a markup string xcontrol. I really should look at it again because I don't think the mouse-over for links work properly on Windows 11.
-
15 hours ago, hooovahh said:
If I want to avoid always include, and if I want the code to have to be brought as a dependency, I think there are only one of two options for forcing the library to be in memory, so the dependencies are brought along. Either have a class constant somewhere, or a class specific VI. It must be one of those two options right? That was my original question of which design do people prefer and use to force some code to be dependent on that class?
Then you added not in memory for deployment to platforms. That's what messes the straight forward choice up because the platform hardware isn't abstracted.
-
21 hours ago, Rolf Kalbermatter said:
it's very flexible and does not require a static constant that needs to be installed somewhere and explicitly added to the caller in order to instantiate new device types.
Hooovahh is using the static binding for deployment though. Rather than abstract the transport he wants to abstract the device as a proxy for the transport because then platform specific deployment is automatic.
You use VISA for the hardware abstraction and configure the transport with a string. Hooovahh is attempting to configure the transport by not installing a device so that when it's deployed only the platform classes are deployed. I think he will run in to trouble if he has a device that has multiple transports but that doesn't seem an issue right now.
-
18 hours ago, hooovahh said:
And by that I mean the static dispatch parent with finding classes passed in, or explicit find for each child type?
Parking deployment for the moment (as I said, I think it's a separate issue) ...
I dislike both.
My workflow would be "Find" a chamber (i.e. detect one or more), "open" comms then start setting setpoints, dwells, ramps etc. I don't care who the manufacturer is - that was all sorted during the install, right? Ideally the "find" would return a list of available chambers (an array of class objects) so I'm not sure why I would need to use class specific "find" functions, or even use the actual class constants from a palette. If you no longer require class constants to be passed in to "find", then you can build a "found" array dynamically that users can use. In this flavour of "find, internally you can coerce to a more specific from the general type to actually probe and that coercion can be dependent on what's installed.
-
I'm not sure you can get away without dynamically loading. It seems you are basically wanting a plugin architecture. The problem with platform specific code is, I think, a separate issue. Note that a plugin architecture also solves your "find" since you can only find those that have been installed. The issue then becomes that you were reliant on static binding (class constants) to solve your deployment to target. This is the same as VI refnums.
What do you envisage the process to be when you have a chamber that has different implementations depending on platform? Let's say that the CSZ chamber must use TCP for Linux but USB for Windows? Now you don't have a static binding problem for deployment but you still have a platform problem.
-
11 minutes ago, crossrulz said:
If you have a specific structure for your chambers (ie everybody is under the "Hooovahh Chamber" directory), you could do a simple lookup and use the Get LV Class Default Value to dynamically load the classes. I do something similar with my HAL already, except I dictate what class to load based on a JSON file.
That's not the real problem (but the same solution as I was about to suggest). The main issue is the LabVIEW static linking. Traditionally we have gotten around it with conditional disable structures or calling CLFN's with a path.
hooovahh has created a class that isn't platform independent, only device independent and is attempting to solve platform dependencies with deployment.
I'll have to sleep on it.
-
I use a polymorphic VI. It basically just wraps the class constant for this purpose.The user can then have a single VI that they can choose the implementation method from a menu and that ripples down through the class functions. It means you only need 1 VI in the palette for the Open/New/Whatever and, once placed, the the user can change implementations without creating or deleting anything.

When there is a single type wired it looks much better because LabVIEW will show the class instance (see below) rather than the generic instance see (above).
The drawback is quick-drop (apparently) because you cannot choose a specific instance, only the polymorphic, but I ignore people that complain about that

-
8 hours ago, jro1952 said:
Hello, I'm interested in adding maps to LabVIEW and I downloaded labview-gmaps-master.zip, but I can't use it; it's for newer versions. Could someone convert the package for version 2010? Thank you very much. labview-gmaps-master.zip 563.51 kB · 2 downloads
You should contact the developer. It may use features not available in earlier versions and it is a source control nightmare maintaining subtly difference versions.
-
 1
1
-
-
-
I'll caveat this with this is only my opinion as a European. Market forces may be completely different to my perception in the US.
When I first started, LabVIEW was basically a loss-leader to sell hardware. The sales people would give it away free (or heavily discounted) if you bought the hardware. It proliferated and people like myself learnt and expanded our capabilities. Over time it launched a small consultancy industry specialising in LabVIEW. There were a few major successes such as JKI and some partnerships along with single developer consultants. The test and measurement industry had few rivals to LabVIEW's capabilities.
Fast forward to today and I think the emphasis is now firmly on large organisations with enormous hardware requirements-in particular governmental organisations. CERN is an obvious one in Europe (CERN being intergovernmental) but I believe there are many in the US. The Test and Measurement was, for the most part, lost to Python and although there are one or two consultants still operating in my neck of the woods, that part of the industry is basically gone here.
So. In my view there is still an appreciable number of opportunities working for large companies' in the US and Europe but if you are looking to be a self employed contractor (in Europe) then you would be better off with something else.
-
 1
1
-
-
18 hours ago, Rolf Kalbermatter said:
Not sure what you mean exactly.
On 6/6/2026 at 9:08 AM, Rolf Kalbermatter said:Depends what compiler you use.
On 6/6/2026 at 9:25 AM, ShaunR said:For C/C++ I always use MingW (sometimes in MSYS2, sometimes in Codeblocks) but I prefer Pascal (Free Pascal compiler).
-
19 minutes ago, Rolf Kalbermatter said:
Depends what compiler you use. Some are more difficult to force into compliance with your preferences than others.😁
All my DLLs are always cdecl or whatever the preferred calling convention is (Windows 64-bit abandoned with cdecl in favor of fastcall, and trying to force a compiler to do cdecl there, while possible in some compilers, is pretty much doomed for anyone else who is going to have to use that DLL).
For Windows APIs however you can't choose, that decision has been made by Microsoft when defining the API. For user DLLs I don't see why anyone ever would have decided to go by stdcall, unless they use a programming environment that could not deal with cdecl.
For C/C++ I always use MingW (sometimes in MSYS2, sometimes in Codeblocks) but I prefer Pascal (Free Pascal compiler). Is this something you encounter mainly in MSVC?
-
20 hours ago, Rolf Kalbermatter said:
I consider it ill advised since that name decoration is simply a Microsoft convention. Other compilers did in the past not create such names when linking a DLL. So as summary:
1) It's not mandated by Microsoft that a stdcall function should be decorated like that, but simply a convention by their linker. It's also not mandated that a non-stdcall function can't be named that way.
2) So it is not a mechanism to reliably avoid Call Library Node misconfiguration.
3) More importantly, it makes it impossible to call a function that was intentionally named that way but compiled as cdecl.
Why would someone create such a function? Well, I have no idea even if you beat me, but obviously someone did, otherwise NI would not have removed that anti-foot-shooter hack.
The main difference is who cleans up the stack after a function. But again, I have avoided name mangling/decoration because it makes it difficult to figure out what to call. I guess being a mid-wit has saved me again
-
15 hours ago, Rolf Kalbermatter said:
There are posts on the NI forum about this, the earliest probably around 2012 or 2013 and I was involved in finding the issue. It's not so difficult when you look at a Call Library Node for a Windows API that crashes and then see that it is configured cdecl as there are virtually no Windows APIs with that calling convention except when they have a variable number of parameters as that can not be done in stdcall where the function itself adjusts the stack just before returning.
Why would someone "fix" an anti foot shooting protection? Most likely because there was an important customer wanting to call a DLL that used that naming decoration for whatever strange reason, while it was explicitly compiled to use cdecl, and threatened to sue the poor support person taking their call and sending an assassin squad to the NI head quarter. 😁
And in all honestly it is an ill advised protection that should not be there. What is less nice is that this functionality was simply removed without some mutation code path when upgrading pre 2011 VIs with a Call Library Node to 2011 or later. Yes there are complications, the correction was apparently done at recompilation time by actually verifying the exported name (the Call Library Node doesn't require to enter the decorated name but does the according matching to the real exported function at that moment) so if the VI was loaded in a newer version with the DLL missing, it would be impossible to properly mutate the code, but it would have been at least possible to try to mutate the VI during loading into the new version if the original was older than 2011. As it is that ship has long sailed already and it is a moot point to argue about now.
Ah right. It would be another one of those things I never came across. My API's rarely use functions outside of the binary it is wrapping (exception being ECL which uses some windows functions for things like the certificate store). I tend to use cross platform binaries so windows specific library calls are rare and unlikely to be cdecl.
I disagree it is ill advised protection. One of the reasons I chose LabVIEW to start programming in was because it was bullet proof. I think we have had a conversation before that I never encountered crashes in the early days and it would have been because of ant foot-shooting boots like this.
-
2 hours ago, Rolf Kalbermatter said:
Just one wild guess that recently bit me in another library. Does the SQLLite API in the Windows DLL use stdcall calling convention?
Until LabVIEW 2011, LabVIEW had a "helpful" feature to second guess your choice of that calling convention in the Call Library Node if the exported function had the appendix @xx with xx indicating the number of bytes passed on the stack for the parameters. The calling convention was silently "corrected" to stdcall even if you had cdecl in the configuration. Once you move to LabVIEW 2011 or later, this suddenly crashes as that silent correction was removed without any warning. The correct way when such a feature gets removed would have of course been to mutate the VI when converted from a pre 2011 version to 2011 or later. However the person removing that paternalizing feature did not think about adding an according mutation code path in the InstrumentLoad() function.
The thing bit me because I was developing code in LabVIEW 8.6 and had been also testing it in LabVIEW 2020 64-bit to be sure, wrongly assuming I had been accounting for a fairly large range of LabVIEW versions and platforms. Since LabVIEW 64-bit does not have any calling convention to choose from it did not expose that misconfiguration and someone else loading it into a newer LabVIEW 32-bit version found out the hard way that I had messed up.
Never mind, I see it is 2025 64-bit LabVIEW so there is no calling convention to get wrong.
I would probably never have been able to resolve an issue like that. What kind of monster removes anti foot-shooting boots?
It's highly likely it was just me misconfiguring some CLFN's. It's obviously been fixed in later versions. I still use the API so would have known if there was an issue with 5.0.0. I think version 1.3 was about 2010 so that version is over 16 years old - an amazing testament to LabVIEW's compatibility really.
-
4 minutes ago, viSci said:
Are you suggesting that the problem was non-uniform application of the pointer-sized integer CLFN parameters?
Not necessarily but possibly. Pointer to data instead of value or vice versa, enum sizes, pointer de-references of strings etc. Library calls are trixy.
-
34 minutes ago, viSci said:
It crashes running any of the included examples. It seems to be able to open a reference to the .db but any queries crash.
Indeed. That is usually the result of misconfigured CLFN's.
-
1 hour ago, viSci said:
I did try the latest sqlite dll from SQLite.org and also adding the AES symbol to the project but still crashes.
It is probably one or more misconfigured CLFN's somewhere that was fixed in later versions. It was worth a try though.
-
22 hours ago, viSci said:
Thanks. I have already started porting to JDP SQLite. I should have done that a long time ago.
If you didn't use the encryption then you could use the SQLite binaries from SQLite.org to keep you running while you transition. I can't remember off-hand if it was supported in 1.3.1 but adding AES=NONE to the project conditional symbols enables the use of vanilla SQLite binaries (i.e. comments out encryption function calls). That said, I expect the issue with LV2025 is probably to do with calling parameters rather than the binary itself because V5.0.0. seems to work fine with LV 2025 & 2026.
-
If you have a commercial waiver then there is limited residual support but apart from that, you should be looking to transition to an alternative product.
-
The SQLite API for LabVIEW was retired 6 years ago (at version 5.0.0).
-
4 hours ago, daqnx said:
This is a problem I've seen come up more often lately.
Many applications don't necessarily need a full CompactDAQ or PXI-class system, but they still need reliable industrial I/O, current-loop measurements, modular expansion, and the ability to adapt the hardware to a specific application.
What often becomes frustrating is that once you need a specialized measurement module or a custom combination of I/O, the expansion path can become disproportionately expensive compared to the actual measurement requirements.
It feels like there's a growing need for more open and modular instrumentation platforms that sit somewhere between fully custom hardware and large proprietary DAQ ecosystems.
That's one of the reasons we're building DAQNX — modular instrumentation hardware with interchangeable function-specific modules and open software interfaces.
https://www.crowdsupply.com/daqnx/daqnx
Full disclosure: I work on the DAQNX project.
If the concept sounds interesting, feel free to subscribe to the Crowd Supply campaign.
There is definitely space in the market at this level. The success for LabVIEW is almost entirely dependent on the drivers and ease of application deployment. This is where, historically, NI have the upper hand as they have an integrated solution. Other platforms can get complicated
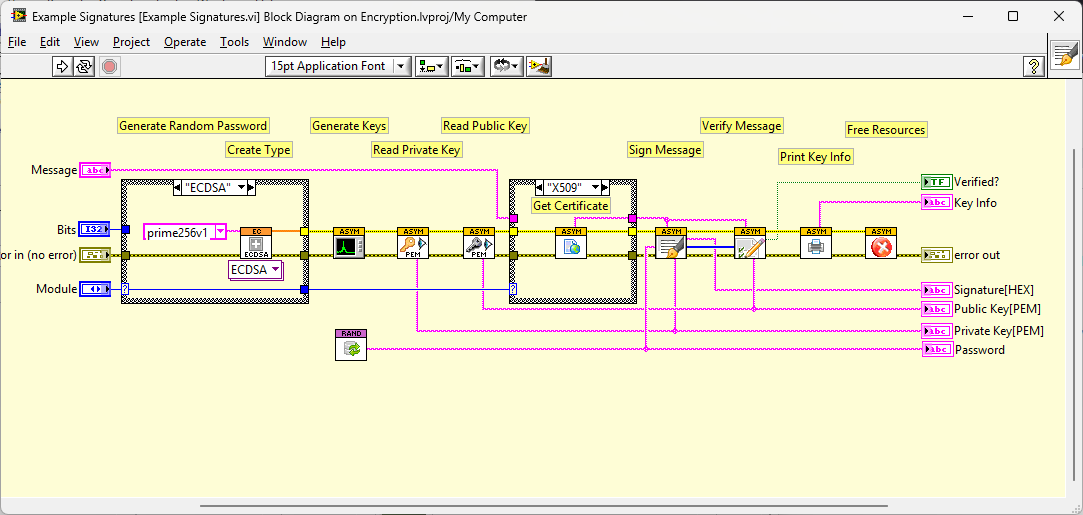
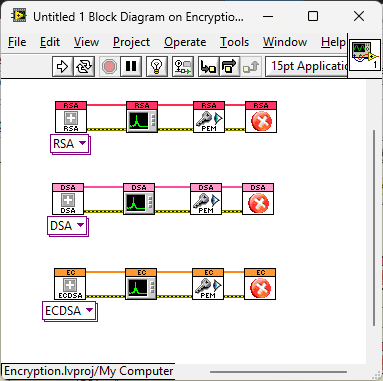
Default New VI
in LabVIEW General
Posted
Me too, for the compane. I got fed up with deleting connectors every time I created a new VI.