

Jim Kring
-
Posts
3,905 -
Joined
-
Last visited
-
Days Won
34
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Jim Kring
-
-
This is a bug inherited from 6.1 and 7.0. You can find the original posting here.
-
There is a nasty little bug in the Notifier compatibility VIs that causes a sever performance hit, and memory leak. This is caused by the caching of the notifier names and not ever flushing stale notifier references when they are destroyed. This bug exists in LV 6.1, 7.0, and 7.1.
BUG
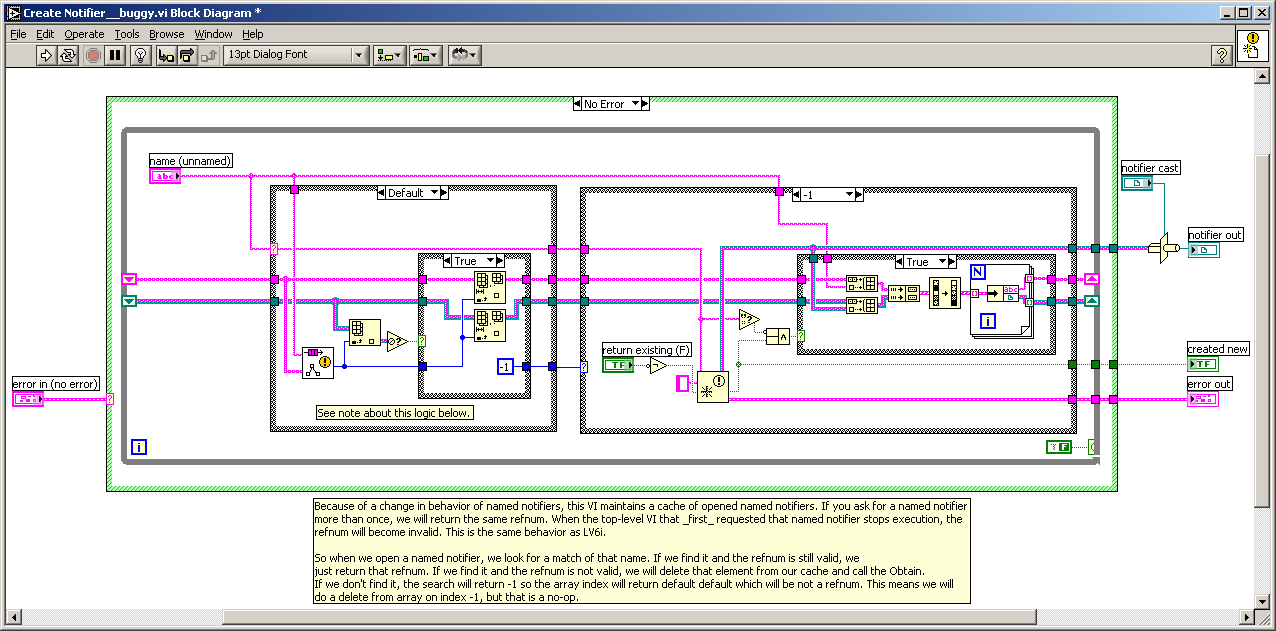
FIX
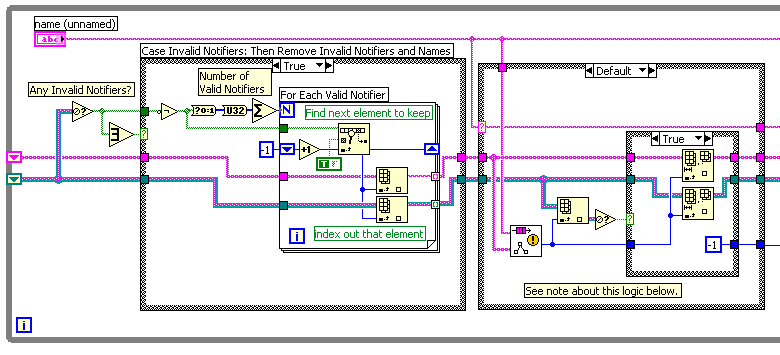
DOWNLOAD
If you are interested in obtaining this fix, I have created a patch which is packaged as an OpenG Package File. This can be downloaded using the OpenG Commander. Download the "ogpatch_notifier_bugfix" package. When installed this package will apply the patch, and when it is uninstalled it will restore the original (buggy) VI.
DISCUSSION
If you would like to discuss this package or the OpenG Commander, please use the OpenG Discussion and Support Forums.
Regards,
-
Hi All-
I have run into a roadblock while trying to write a general program to read/write VI controls.
The finished program would use the VI control references, read the value of each control as a variant, convert it to XML, change the value in the XML, convert it back to a variant, and replace the original control's value.
I was getting an error (#91, Property Node (arg 1)) that I have narrowed down to this:
LabVIEW does not allow you to convert XML to a populated variant; it creates only a blank variant.
The attached file shows this problem. I am not modifying the XML data, and I am using the original variant as the Unflatten prototype, but the error occurs. In effect, the reciprocal XML function does not work on variants.
Is there any way around this problem? Is there a method to create a deterministic non-blank variant? I am planning to investigate importing and exporting variants to a non-LabVIEW DLL, but haven't had a chance yet.
And, yes I know, I can use strict type definitions, and that will work fine until you get to clusters. I am just trying to make it universal, and avoid the complexities of unknown clusters!
Thanks-
-Randy
This is a known limitation of LabVIEW. It has to do with the fact that they use the strict data type as the definition of the data, rather than using the XML as the definition of the data.
The OpenG version of "Flatten(Unflatten) to(from) XML" does not have this limitation. You can obtain it from here:
You will also need to install OpenG Commander and the lvdata package (and its dependencies).
If you have any questions about the installation of the OpenG tools, please feel free to ask them in the OpenG Discussion Forums.
-
There is information about how to do this at OpenG. Visit this link for more info:
http://openg.org/tiki/tiki-index.php?page=LvDocMenuLaunchVIs
-
Actually GOOP has been hidden in LabVIEW since version 6. Furthermore, many of the native LabVIEW VIs or function nodes are objects (such as queues and the lower file IO). However what we really want is to be able to click on a GOOP wire and have a probe describe the data for that instance of an object. Maybe that will appear with 8!
cheers, Alex.
There's no reason that a GOOP class developer cannot create a custom probe for a GOOP class. The hard part is integrating these into the custom probe's framework. Right now the mechanism for integrating custom probes is a little awkward. Ideally, custom probes would be declared in a GOOP class's manifest (if such a thing existed) and LabVIEW would automatically know how to make it available to users.
Finally, for those of you who love the Universal Probe, here is another little gem called "Config File Probe". Drop it into your <My Documents\LabVIEW Data\Probes> folder and then probe a Config File wire.
Download File:post-17-1105376809.vi
-Jim
-
Here is a page at OpenG.org which is dedicated to GOOP information:
-
Jim,
On a recent project I designed a CAN "server" that would actually spawn new engines for each CAN card configured using a configuration tool. Each engine would be initialized with User event references to hook into any main program. The engine would then take care of sending/receiving event driven messages or periodic messaging.
I have to say that Michael Aivaliotis' NI week presentation opened up my eyes to this new idea in coding style. I think my next foray will be into the wonderful world of GOOP

:beer:
Derek Lewis
GOOP and Process Spawning are can be used together very nicely. For example, when spawning multiple processes (multiple instances of the same process), it is often a good idea to create a new instance of a GOOP object associated with it for managing the instance's data. Usually, I accomplish this, by doing the process spawning inside of the GOOP object's constructor. I pass the process a reference to the GOOP instance, and then the process can access the instance's data store, using that reference. I store the spawned VI's reference inside of the GOOP data store, so that a call to the GOOP destructor can kill (Abort) the spawned VI, if it can't stop it using some form of messaging.
-
I just read an article on DeviceForge.com called .NET dives deeper into gadgets, which discusses the .Net Embedded platform for targeting "bare metal" (no OS). This is pretty interesting since NI has shown at NI Week that LabVIEW is being targeted at smaller and smaller embedded devices and architectures, including those without an OS, such as the FPGA platform. Since Microsoft (or at least one of its partners) is moving in this direction, it seems possible that Microsoft and National Instruments might start competing head-to-head in this arena. In the desktop and server world, the OS and developer tools are tightly coupled. In the embedded hardware world the embedded hardware and developer tools could also be tightly coupled. Maybe MS will try to extend its monopoly into the embedded world, too.
Just food for thought.
-
-
In our research lab we have a few Windows XP machines, networked together, for data acquisition and processing purposes. The actual computer I'll be using depends on which experimental system I'll be using, but I'll be using the same acquisition and storage VI's on each computer.
The issue comes with synchronizing VI updates. If I update RoutineX on Computer1, then if I use RoutineX a few days later on Computer2 I want to use the updated version. And similarly, if I update the routine again, I want the changes back on Computer1.
The way I am dealing with this now is by arbitrarily picking one lab computer as a 'server', where I store all my VI's. When I load VI's to insert, I always do it through the network, so VI's have a pathname like :
"\\ComputerName\username\Routines\Acquisition\Measure.vi"
This method works pretty well, all my routines work fine and will be properly updated if I change them, no matter which computer in the lab I am accessing them from.
I have just started using some other user-supplied tools, such as LuaVIEW and OpenG. LuaVIEW can put its VI's and palette menu anywhere, so I do that over the network. But - the OpenG tools want to go to the local computer, in the LabVIEW install directory. So for I need to install the OpenG toolkit on each local computer that I want to use it.
I'm wondering I'll be shooting myself in the foot sometime down the road. As long as each computer has the exact same version of OpenG stored in the same path, then it shouldn't be a problem whether I use a subVI that comes from the network or locally.
I'm wondering if anybody else has thought about these issues, even if you don't use OpenG or other add-on libraries, to keep your usage of VI's synchronized from a network.
Hmmm, it sounds like you could benefit from a networked source code control system (such as CVS or SubVersion) to keep all of your project files sync'ed. Once you get over the learning curve, this is light years better than a networked project folder.
Jean-Pierre summed up most of our reasoning for putting files beneath user.lib. But, you can find a little more info on OpenG's integration strategy here:
http://www.openg.org/tiki/tiki-index.php?p...grationStrategy
Also, we are working on a better way to keep packages synchronized between developers/systems using a project. We are going to support a system configuration file that will detail all the package requirements of a project and easily allow you to change between configurations. Couple this, with a networked repository of packages, and getting the right OpenG packages installed will be a breeze. OpenG Commander is coming soon!
-
Well, free open source software is the natural evolution of software development. Companies that recognize this will survive in the long-term. See this article:
Thanks to Jim Kring for pointing this article out to me.

You're welcome, Mike. And, here's another interesting read, which is related to this thread:
(notice that it is an essay from the same folks as the one you referenced)
-
It appears that the probes folder inherits its location from the 'LabVIEW Data' (aka "Default Data Directory") directory. So, I guess that it is a good practice for developers with more that one LabVIEW version installed to change this setting to a version specific folder, such as:
*********** labview.ini ***********
DefaultDataFileLocation=C:\Documents and Settings\%user%\My Documents\LabVIEW 7.1 Data
********************************
The Probes default folder is determined by the Data directory definedwithin LabVIEW. This can be changed in the following manner:
1. From within LabVIEW select "Tools->Options..."
2. Choose "Paths" from the drop down box at the top of the Options dialog.
3. Select "Default Data Directory" from the Paths drop down box.
4. Deselect the "Use default" checkbox and define a new directory to use.
5. Restart LabVIEW and now new probes will be saved in your newly defined
directory.
Please let me know if you have any more questions about this issue.
-
Is the current EULA with the passus LabVIEW Software License Agreement not something that should protect NI from such developments?

Since NI can (technically speaking, per the NISLA) tell you that any software is unauthorized, then perhaps the EULA does protect them. But a translator/importer/exporter does not directly compete against any existing NI product. However, it does opens the door for competitive products that are not written in LabVIEW. For example, if there exists an XML schema for storing VIs, along with an importer/exporter, then anyone can build an editor for files of that schema. This means that you don't need LabVIEW to edit G. You only need it as a compiler.
-
Who says that they haven't?
-
There is a fundamental flaw with having custom probes stored inside the "~/LabVIEW Data/Probes/" folder (for example, "My Documents\LabVIEW Data\Probes" in Windows XP).
:!: All versions of LabVIEW installed on your machine share the same custom probes folder.
:!: If you have both 7.0 and 7.1 installed and you accidently save your probe in 7.1, it will no longer work in 7.0. All I can hope for, is that the custom probes path is not hard-coded into LabVIEW and some secret INI key will allow us to redefine the default probes storage location.
However there might be a work-around. Here are some behaviors that I noticed:
* the probes folder is searched *each time* you right click on a wire and select the "Custom Probe" submenu.
* the probes folder is searched recursively, including all searchable subfolders
* subfolders will be excluded from the search, if their name begins in an underscore ("_") character.
Here is a possible solution:
Create subfolders for each LabVIEW version.
~/LabVIEW Data/Probes/7.0
~/LabVIEW Data/Probes/7.1
~/LabVIEW Data/Probes/7.2
~/LabVIEW Data/Probes/8.0
~/LabVIEW Data/Probes/8.1
Create a VI that renames all subfolders for LV Version != Running LV Version. For example, if we are running LabVIEW 7.1 the VI would rename the Probes subdirectories so that they were the following:
~/LabVIEW Data/Probes/_7.0
~/LabVIEW Data/Probes/7.1
~/LabVIEW Data/Probes/_7.2
~/LabVIEW Data/Probes/_8.0
~/LabVIEW Data/Probes/_8.1
Now, only the 7.1 subfolder will be searched for custom probes.
The VI may either be menu-launched (for example, from the "Tools" menu) or perhaps, registered to run automatically when LabVIEW launches (using lv_init.vi).
Any other ideas or thoughts?
-
Yes, that's what he means... See here:
http://zone.ni.com/devzone/conceptd.nsf/2d...dElemFormat=gif
In your example, Michael, how come the RegEx used to strip contiguoes EOL chars is "[\r\n\r]+" ? It seems like the last "\r" is redundantly redundant.
-
Happy birthday!
Yes, have a happy birthday, Jean-Pierre. Have a happy new year, too!
-
And obviously, the next question is, could you exchange an old VI for a new one of the same name? And finally, is there any reason that you could not do this programmatically? Might prove to be an interesting way to push updates out to distributed executables. It would also be a pretty serious security flaw....
Or insert "wrapper" VIs into the hierarchy that intercept and operate on data as it flows into and out of subVIs? Sure, you can.
Heres another trick... insert keys into an app's INI file that enable VI Server TCP-IP access. Now you can open a remote application reference to the app and peek/poke into the control/indicator data of its VIs (those that have FP's).
-
Interesting. If you combine these two then you would not be using the application builder, so in that case could you argue that you were not bound by the NISLA? Yes, it's a nitpicky way to make the argument, but considering the unbounded breadth of the NISLA clause...
Since VI files contain executable code which may be run using the LabVIEW Run-Time Engine, they are themselves "applications". This means that NI could say that your VI files are not authorized to be distributed for use with the LabVIEW Run-Time engine. This is one good reason why we need to be able to distribute VI source code seperately from the bytecode.
-
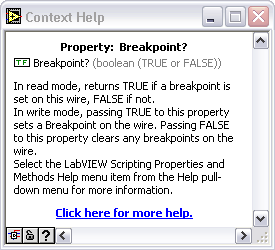
has anyone managed to set a breakpoint programmatically using scripting?
Write a TRUE value to the Wire's Breakpoint property.
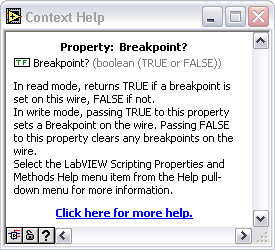
-
Mike,
Don't hold your breath waiting for a public release of scripting. There are several reasons that I think it will not be "productized" anytime soon. Here are a few...
It is not a feature that will be useful for beginning LabVIEW users (thus increasing the number of LabVIEW copies sold to NI's target audience). There aren't many advanced LabVIEW users that will be willing to pay NI, what NI thinks it is worth (and costs to support). And finally, it opens a whole can of worms with respect to the fact that LabVIEW is a closed/proprietary environment -- scripting means that people can build import/export/translator tools for moving G (source code) outside of LabVIEW and therefore NI's control. As we've seen with the developments in NI's licensing policy, the lock-down is getting tighter.
Now, that doesn't mean that NI won't continue to evolve scripting and use it as an in-house tool for making LabVIEW more powerful...
:2cents:
-
I downloaded it and was impressed. I also spoke to my brother-in-law who is a senior programmer for Fidelity Investments in Boston. Some of Fidelity's internal work is now being done on Eclipse which has been officially approved by the company. Fidelity is very conservative about the tools they allow to be used. This speaks well for the stability and safety of the code.
I, too, noticed is that it looks like a very mature and well thought out software product. It has major backing by IBM (the creator of Eclipse), CollabNet (driving force behind Tigris.org, home of SubVersion and TortoiseSVN) and hopefully Sun Microsystem. It really seams like it has a solid foundation as THE open source IDE.
As to whether to try to put LabVIEW-Java plug-ins in or just use it as a model.... that is a very good question. I think for now we might want to continue to do our major tool development in pure G, but Eclipse should be added to OpenG/LAVA projects for three reasons:1) development of those few cross-platform functions that might be better implemented in a text based language. (or for including existing open source text based code/libraries).
2) to get us into a good open source IDE since Microsoft has included verbiage in its Visual C/C++ license to try to preclude use for developing open source tools.
3) Future: for writing "OpenG" as an OpenG project in the next few years :thumbup:
What I think would be useful for OpenG to start doing, is to use the Eclipse IDE as the project-level environment for invoking the OpenG Builder, OpenG Package Builder, LabVIEW App Builder, and any other functionality needed by OpenG developers during the build/test/release process. Eclipse has good support for integrating external (command-line) applications into the build process. It would be fairly easy to build executables that allowed access to OpenG Builder and other functionality.
What we probably won't be able to do (w/o a great deal of help from NI), is to integrate the LabVIEW environment into Eclipse. Eclipse has an API for integrating breakpoints and other debugging tools directly into the target environment. This would be tough to integrate with LabVIEW.
By starting to use a "real" software IDE, I think that those OpenG Developers without experience developing in a traditional programming language/IDE will gain a lot of useful exposure to the types of tools and methodologies used for software engineering. This insight will go a long way for helping us define our direction in the context of G as a general purpose programing language. Also, I am looking forward to doing some exploration into Java and how the Eclipse plug-in/extension framework is architected. This research will go a long way for OpenG projects that wish to provide plug-in capabilities.
-
Has anyone looked at Eclipse? http://eclipse.org/
It is an cross-platform (written in Java) open source IDE for just about any type of project. According to their website... "Eclipse is a kind of
universal tool platform - an open extensible IDE for anything and nothing in particular."
I downloaded it and took it for a test drive. It is very slick, and has so many features and so much flexibility that it might be daunting for new users (it was for me). It has built-in CVS capabilities, which is useful Source Code Control integration. It is very extensible, but the plug-in API's are all Java. If nothing else, this platform could serve as a very useful example for implementing something similar in G. I think that it is worth some time investigating.
-
If you like that, then check out this:
http://www.heavy.com/index.php?channel=contagious
Heavy.com has some funny stuff, along the same lines. I think that I even saw the "Master Card" one there.
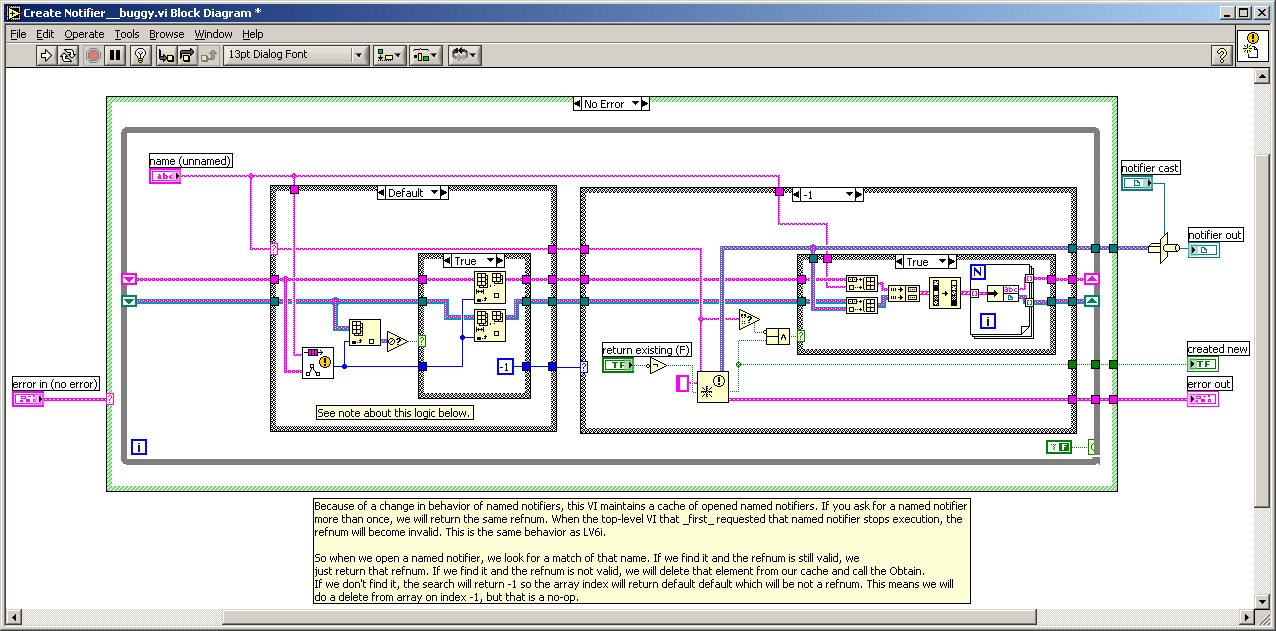
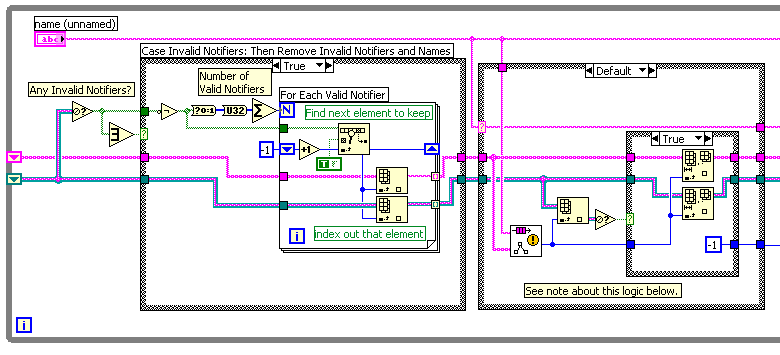


Notifier Compatibility VIs Memory Leak
in LabVIEW Bugs
Posted
I have created a homepage for this package here:
Notifier Bugfix Patch (notifier_bugfix)