
JackDunaway
-
Posts
364 -
Joined
-
Last visited
-
Days Won
40
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by JackDunaway
-

Using scripting to inspect code from a built exe?
JackDunaway replied to Thoric's topic in VI Scripting
Thoric, the way I do this is using Actors, where the Actor using scripting methods is running in the LV environment. Consider an actor as just an API around a shared resource, used to abstract and encapsulate state and resources. Defining an API to the Actor as a TCP/IP messenger with endpoints to handle message types (the native LV2013 Embedded Web Servers work swimmingly for this purpose) provides an API with the subset of functionality that you want to perform with the shared resource. Following your example above, one message type into the Scripting Actor would be "CreateNewVI", and the payload passed with this message are all the by-value parameters needed to constrain the creation of a new VI. That message from the remote caller is marshaled to the Scripting Actor running in the IDE, which has exposed an API through HTTP endpoints. The new VI could further be manipulated through additional messages, or information about it could be returned to the caller by-val. Limitations? Unlike .NET Remoting, we don't have native type safety between two remote applications, or "direct access" to the object itself. Additionally, this new level of indirection requires more programming -- you're creating a new by-val wrapper API as a subset of the by-ref shared resource API of Scripting. But this is both good and bad -- from a security standpoint, it's fantastic (since only the desired subset of VI Server is exposed, we have built-in declarations for things like access/error logs, security policies, access policies...). From a debugging standpoint, I'd argue it's far simpler, because all API calls are transactional with no distributed mutable state -- that's just a boon of actor-oriented design for ya. Whether or not this strategy is suited for your problem domain is sensitive to many factors (more business than technical) -- though, know that what you're wanting to do is possible (at the same time, technically elegant and concise), and i'm glad to talk more on specifics. -
It's for both reasons -- to satisfy Principle of Least Astonishment, and to allow handler processes to be subscribed to multiple concurrent messengers. In the case of the Piranha Brigade, you might typically want two registrations per Piranha (worker) -- the Job Queue, and the Abort registration. The poor man's Abort is to simply flush the Job Queue, which causes all the workers to fall into their idle/stopped condition. Not that I know of -- but it might be helpful to start a discussion to focus on this topic. I'm personally not running into roadblockers that can't currently be solved another way, but the ability would definitely clean up existing syntax. Nah, strictly the opposite! Solving existing problems such as load balancing with the absolute minimal syntax possible! Multiple readers consuming from one job queue is about a simple a load balancer as can be developed in LabVIEW. The queue acts as the endpoint from which one-or-many sources queue jobs, and multiple asynchronous workers are gobbling away at those jobs -- the queue acts as a passive load balancer, rather than needing to handle routing and scheduling between workers. To clarify -- it's an improper mental model to consider the User Event publisher a "queue". When a User Event object is created, there is no underlying queue of messages that grows with the "Generate User Event" method, and so there exists nothing to "re-transmit" to the handler queues. A better mental model is to consider the Generate User Event method as a synchronous method that enqueues directly into each of [0,N] subscriber queues. It's not an asynchronous method that enqueues an event into its own queue which is then asynchronously re-transmitted to handler queues. This is why Events semantics are so much more powerful than Queues with regards to decoupling systems in LabVIEW, and why native Queues don't make good mental models for how native Events work -- a Publisher does not create a memory leak in the case of zero subscribers. (This mental model I'm describing is just a mental model -- in reality, the underlying implementation has a more sophisticated memory-saving technique by providing one globally-scoped-to-the-context Subscription queue per Event, where each message exists as only one copy with pointers to which registration queues have not yet handled the message. Consider 100 messages each of size 1 unit. Regardless if there exists 1 subscription or 10 subscriptions, there is still only 100 units of memory necessary to hold all subscriptions, plus the relatively-small overhead of references to each subscriber per message. If there are 0 subscribers, then 0 memory is allocated or queued, and each of the 100 messages fizzled into the ether synchronous to the posting of the message) Said another way, the union of Queues and Events in LabVIEW comprise The Superset Of Semantic Awesomeness, and I wish that all merits could be accessible by one transport mechanism API without having to compromise. Heartily concur. This can be generalized to say, lots of different APIs in LabVIEW would benefit from providing asynchronous output streams that adhere to these Events pub/sub semantics. Again, this is in the spirit of enabling concurrent systems development in LabVIEW, which converges to Actor design and the current topic of asynchronous dataflow on Expressionflow.
-
Not explicitly true -- for Queues, an enqueuer and a dequeuer are both accessing the same Queue object, whereas with Events, the enqueuer and dequeuer are interfacing with two separate objects -- the event publisher and the event registration/subscription. Any number of writers may write to a Queue, and you may have any number of readers as well; stated another way, contrary to popular belief, you may have multiple asynchronous dequeuers pulling out of the same queue. Events have a bit different semantic than Queues in LabVIEW -- there must be one and only one Handler bound to an Event Registration at any one time, yet there may be [0,N] Registrations per publisher. With this extra level of indirection, I don't know if we can even properly classify Events as being something-to-something, but rather (N publishers)-to-(M registrations)-to-(0 or 1 handlers bound to a registration at a time). Breaking it down: Queues are many-to-many, one-to-many, one-to-one, or many-to-one, depending on what makes sense for your application domain. Events support the same configurations, though with one additional level of indirection (which enables a host of additional design patterns), and the caveat that there may never be multiple readers (Event Handler Structures) simultaneously bound to one Event Registration. This caveat is the one I would like to see lifted, that Events might act more like Queues, in order to better support concurrent processing. Actually the other way around -- Queues have the advantage in LabVIEW for the time-being for the Piranha Brigade pattern, because Event Registrations do not yet allow multiple handlers to be concurrently bound to a single registration. The run time behavior is literally undefined -- utterly random results in the total number of events handled, at least as of LV2012.
-
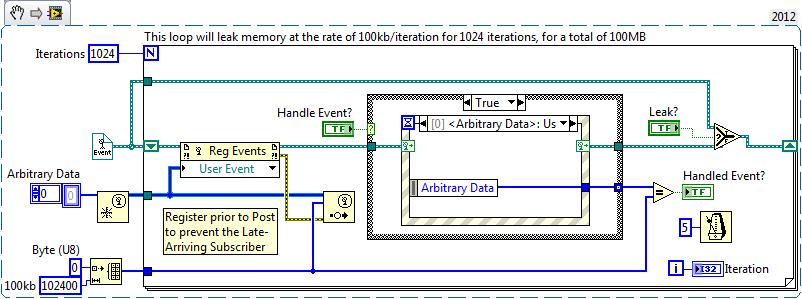
Glad you found the source of the problem! Just to dive in and explore further to this statement above -- it's perfectly acceptable to register inside the loop prior to binding the registration to the Event Handler Structure -- though perhaps not typical. I'm guessing that the memory leak you found was due to the registration not being shifted in a Shift Register inside the loop code. This would cause a memory leak, since each iteration a new Event Registration Queue is formed. Though, if it's shifted, only one Event Registration is created, and then modified each subsequent iteration. Check out the snippet below, which simulates the difference between shifting and not shifting an event registration. The two Boolean controls -- Leak? and Handle Event? -- allow you to run the example in four modes: Handle Event == TRUE and Leak == FALSE - Though it remains atypical to re-register each iteration, this is the only of the four combinations that does not produce a memory leak. Handle Event == TRUE and Leak == TRUE - This is an interesting scenario that causes a leak of 100kb/iteration, even though the data is consumed (handled). This indicates that Event Registrations, like Queues, maintain a high-water mark as an optimization technique. (Thoric, I'm guessing this unintentional scenario was the bug in your code) Handle Event == FALSE and Leak == FALSE - This scenario might be used to pre-load a work queue, which would then later be bound to a single handler. This technique is useful if the computation-to-memory ratio is high, and time needed to calculate the work to be done is relative quick compared to the amount of time needed to do the work. (I wish that LabVIEW's Event Registration binding to an Event Handler had the same semantics as a Queue, with 1:N capabilities. Then, we could dynamically launch a pool of workers bound to the same work queue, and have the Piranha Brigade munch away at the work in concurrently and asynchronous from each other) Handle Event == FALSE and Leak == TRUE - This scenario is useless and almost certainly a bug, unless the Shift Register was replaced by an Auto-Indexing output, to which the array of registrations were later each bound to handlers. (Though even with the output array of registrations, this technique is not quite as desirable as the Piranha Brigade above, especially when the amount of time to perform each job is variable.)

-
I've got this sneaking suspicion it's not training wheels. OP is not the type to walk blindly into The Mob That Is LAVA uttering absurdities without a Pretty Good Idea to support them. :-]
-
Cool utility! +1 Short answer: the concept=no, the tools=yes, the domain=yes. :-) The concept is like ... inversion of inversion of control -- check for dependencies, then inject the dependent. It's a fresh look on an old problem. On this topic, looking forward, I'm interested in considering both dev and deployment environments as disposable appliances -- self-contained environments with no external dependencies. One important factor here is minimizing footprint -- not so much from a storage perspective, but because bandwidth (i.e., time) is an expensive UX resource. In the meantime, searching things like "Segmenting the LabVIEW Run-Time Engine" describes an unofficially-support method of solving current probs. Our root motivations are the same -- reduce pain introduced by shuffling around large dependencies. And even though IoIoC may not be optimal in many situations (especially in non-strictly controlled deployment targets), it is precipitously close to other solutions using some of the same tools. :-)
-
A VI is both beautifully and grossly overloaded to be many things. Give it a conpane and inputs/outputs -- bam, a VI is a function. Give it a loop -- bam, it becomes a process. Give it some outbound messaging transport mechanisms -- bam, active object. Give it an Event Handler Structure -- Bam. Actor. (To be fair, a VI is an actor all along... down to even the Space Constant... just many levels of pared-down actors) Now, start composing each of those roles into collections -- you get APIs, then libraries, then systems, then applications. Each of these levels of VI definition and collections of VIs requires different semantics and programming styles. I see the limitation of one Event Handler Structure per VI as a decision that has the potential to significantly improve our abilities to build the higher-level abstractions in LabVIEW that are currently laborious and suboptimal. For instance, this opens up new possibilities to expanding the API of VI Reference instances -- we can start to drop existing primitives (like Generate Event) onto a VI Reference, since that VI has defined itself as being able to handle a set of messages that it can receive, and could even declare types. Imagine: a VI could declare its asynchronous API (rather than having to manually route the plumbing yourself as a dev -- we rise from procedural definitions of behavior to declarative definitions. Though, perhaps this declarative definition is stored at the LVClass level and then routed to a handler process within the class? We can skin the cat a few ways; different syntax, same semantics.) Singletons, single instances of APIs or syntax -- those can be limiting or even crippling -- but right now I don't feel this proposal falls into this category. Now, if we were talking about only allowing one Event Registration wire (this one: ) -- I'd fight this tooth and nail, since it destroys semantics of a thoughtfully-designed active object in LabVIEW. (Spoiler: this wire and the Register For Events node, contrary to popular belief, absolutely have an N:1 relationship with any arbitrary Event Handler Structure) The Events API is perhaps my favorite API in the entire LabVIEW language -- syntax is gorgeous (five nodes and structure) and semantics are even better. Event-driven programming is the backbone of anything I create. Those of you who saw my NIWeek 2013 presentation are aware how excited i get on this topic! :-] I say this, just to emphasize good faith and optimism that even though we're discussing a restriction, what we're really talking about is bounding the bigger picture that could enable much cooler things. As with the other comments above, I'd be disappointed if this proposal is meant just to weld on the training wheels, yet incredibly excited if it's to enable better syntax and VI definitions for building systems. I'm just curious for OP to reveal a larger surface area of his genius and roadmap than a simple, controversial question.
-
What value proposition do you offer, if we agree to limit a diagram to a single Event Handler Structure? My knee-jerk reaction is fight such a change (since, naïvely, it feels arbitrarily limiting, and perhaps for benefits that don't matter to me). But having thought about this quite a bit -- any changes that enable Events to be used more ubiquitously (including registrations for many shipping APIs, and registrations on different comm types such as Queues and Notifiers) would be welcomed. I can dream even of defining systems like Tomi describes on his newly-revived blog ExpressionFlow, where rather than having Terminals enabling synchronous dataflow between networks of VIs, we have Incoming/Outgoing Event (Message) Definitions that enable async dataflow between nodes (VIs). Here, a 1:1 ratio between VI:Event Handler probably makes sense, to simplify routing.
-
CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
JackDunaway replied to JackDunaway's topic in LabVIEW General
I can second all Justin's anecdotes. Recently, this issue prevented one important workflow -- CTRL+SHIFT shortcuts are required to take a Peek at the good ol' Heap. -
Daklu hits an important request with Make namespacing and library membership independent.
-
ØMQ is on my radar, and a few other's (we can talk about it offline, but I'm not ready to endorse it publicly). I can say, I'm eyeballing ØMQ as a particularly intriguing solution for actor-oriented design (and generally, distributed messaging) both in LV and between LV and the rest of the world.
- 72 replies
-
- 1
-

-
- networkcommunications
- datasocket
- (and 1 more)
-
<xkcd-style-alt-text>I'm contemplating deriving all future API design strategy from comedians.</xkcd-style-alt-text>
-
Stobber: have you considered creating a logger actor (service/subsystem/agent) dedicated to performing this action? Other actors in your system, when they want to write an event to the log, would not perform the log write themselves; rather, the event is brokered through this Logger Actor, which contains all procedural behavior for writing to the Windows Event Log. The logger subsystem would provide a VI called "Serialize to Syslog" which has no dependencies (including, not being contained within the logger's library/class). This means that any arbitrary system in your application only needs two things: 1) a lightweight, dependency-less method to serialize into your log format du juor, and 2) access to the endpoint (actor reference/address/mailbox/enqueuer) of the logger actor. I've had good success logging within a single actor (rather than as a distributed effort throughout the system) since the disk (or generally, log store) is a shared resource. The logger actor can do things like batch writes, and it generally frees your other systems from this otherwise expensive, blocking action. This doesn't answer your original question, per se, but could at least contain the Event Logger API to a single actor on the Windows target. ***EDIT: This method is not unlike the LabVIEW Syslog Protocol Reference Library linked by Phillip, except you'd be using your existing actors and transport mechanisms. Perhaps you can pluck the APIs from that reference library and plug them into your own system...***
-
I've noticed this happens when I have a copyright symbol (©) in the build spec. Try diffing your freshly-opened-then-saved LVProj with the previous LVProj using a text diff tool -- the one character that changes for me is the © to the "exact same" © (I've not tried comparing binaries, but perhaps this could reveal an encoding issue)
-
CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
JackDunaway replied to JackDunaway's topic in LabVIEW General
Eli, I've been running Parallels 8 since it came out (last year or so?) with this issue; Parallels 9 just came out a few weeks ago, and I'm yet to upgrade to try that (waiting for the dust to settle on that and Mavericks also). "I'm pretty sure this isn't LabVIEW's problem" << Anecdotally, I think it might be LabVIEW, since every other application in the VM accepts 3-key shortcuts, including CTRL+SHIFT shortcuts -- it's just LabVIEW that's having problems. For instance, open Chrome in your VM, go to a webpage, exit that page, and hit CTRL+SHIFT+t -- the tab will re-open. Likewise, CTRL+ALT+s and CTRL+SHIFT+s works in Notepad++ -
Growing up, did you hear the kindergarten joke, "your epidermis is showing!"? Live and learn -- we all come to realize 98% of the time it's fine to have some epidermis showing, and that other 2%, you're going to have much earlier and much more distinct warning signs. Thoric, apologies for lack of a better response, but I've just stopped paying any attention to the report provided by "Find Items Incorrectly Claimed by a Library", having seen zero Real Problems in either dev or deployment environments. The compiler warns of all Real Problems.
-
Thanks all for the response -- a team is currently chatting offline to schedule an initial meeting. And just to answer a few questions publicly: This is a non-commercial, "after-hours", open source project for fun, but it's meant to help us perform our day jobs better No picture controls; all visualizations are rendered in the browser using existing javascript libraries (LabVIEW<->js communication using JSON) If you'd like to "follow along at home", ping me and I'll gladly send details to dial-in as a viewer on our video/screensharing brainstorming/work calls Best, Jack
-
Greeting, wireworkers! I have an idea and a need for some software development tools, just not the bandwidth to develop them by myself. Would you help me? Problem description: I find myself needing/wanting to visualize dependencies of code modules in LabVIEW. A "module" is loosely defined here, as perhaps a library, a VI, a project... Current tools available: VI Hierarchy gives a nice view of static dependencies of a single VI; Class Hierarchy gives a decent view of a project's object model; the Dependencies section of a LVproj give a good listing of all static dependencies of the project. Rationale for a new tool: Make it easy to visualize how code modules are interconnected, to be used as a debug and design tool for system architectures written in LabVIEW. Want to help?: Just drop a line -- either private message or email. Ideally, you've got some experience with the LV Linker and Javascript; no worries if not, I can help out. Likewise, ideally you've found yourself wanting similar tools to enhance your experience developing systems. What happens to the tools we create?: The immediate goal is to help ourselves on our own projects and scratch our recreational programming itches; in the future, perhaps there's enough polish and interest to release open source to the community. Here are a few ideas: 1. Dependencies of top-level application modules (interactive source: http://www.findtheconversation.com/concept-map) 2. Relative size of libraries and their inter-connectedness (interactive source: http://redotheweb.com/CodeFlower/) 3. How VIs connect to each other, grouped by library (interactive source: http://redotheweb.com/DependencyWheel/) 4. Coupling and cohesion between methods grouped by library (interactive source: http://bl.ocks.org/mbostock/4062045)
-
I'll swap either of you straight up for a non-Retina display that does not have this problem
-
CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
JackDunaway replied to JackDunaway's topic in LabVIEW General
Here we are are while later... I'm still having this problem with all versions of LV on all VMs. AutoHotKey has been an "ok" workaround in the meanwhile -- i've chalked it up to the cost of doing business. I've pinged some additional Parallels users, and they're reporting the same prob with LabVIEW -- perhaps they'll chime in. -
Steen, thank you for the model, this helps as a talking point. Even though composition may solve your problem, one caveat is introducing a non-trivial amount of work in the form of creating proxy methods. For example, your VIFile composes an LVIcon, which has the method LVIcon::SetIcon(). Your application that uses the VIFile API probably needs access to the method SetIcon(), meaning you'll need to create a VIFile proxy that wraps SetIcon(). Likewise, that proxy will need to be written in PolyVIFile, LVLibraryFile, LVControlFile... Now, we've created several maintenance points. What if the LVIcon::SetIcon() conpane (interface) changes? We'll have to go update all the existing conpanes (interfaces) of the proxy wrappers. The alternative to proxy wrappers is to create a getters/setters for the composed objects -- though this is suboptimal, and often breaks atomicity. You're breaking encapsulation, and potentially exposing the application calling the API to race conditions or even deadlock. Now, assume LVOOP gave us Mixins or Traits. The method SetIcon() is implemented by the LVIcon Trait (rather than the LVIcon Class), and then VIFile, PolyVIFile and so forth would declare the Trait LVIcon. The method SetIcon() is written only once, and can accept object types of VIFile, PolyVIFile, and so forth, in order to manipulate the parent objects which have declared those traits. One regard where Traits or Mixins differ from Interfaces is that Traits and Mixins define implementations, rather than just interface and contract definitions. The main motivations pushing for Traits or Mixins in LVOOP are all tied to developer productivity and mental well-being. Conceptually, it can make systems easier to synthesize by providing more accurate maps to mental models, and the logistics of maintaining codebases is substantially reduced (since we agree, codebases are a liability, not an asset).
-
Yeah, the important thing to realize here is that you're not incompetent; your LVOOP toolchain just makes you feel incompetent. Without a background in Python or Java or C++ or Ruby or PHP or Scala or ... -- with only a background with LVOOP -- you're not necessarily going to realize the root of the problem modeling systems. This is me; I learned OO on the LVOOP platform. Since, I'm studying elsewhere to diagnose my lack of productivity and lack of confidence in my designs using LVOOP. This is not a slam against current LVOOP; I'm all about continuous improvement and kaizen and working toward better toolchains and systems; it's important we continue funneling positive energy toward improving LVOOP. Other wildly popular languages are still continuing to develop and release new OO (and generally, core language) features today and over teh past years, and it's important to encourage LabVIEW to do the same!
-
(Thanks, Steen, for the heads up to this thread :-] ) Here's a quote from another conversation that relates to this thread: tl;dr -- you've got an application domain where neither inheritance nor composition is the correct re-use pattern. Using LVOOP today, I would tend to take drjdpowell's advice of inheritance as far as you can without breaking the map between the object model and your domain -- this might get you a little ways down the road of pushing common methods/fields up the hierarchy. Then, take shoneill's advice of composition. You'll have some grunt-work writing proxy wrappers to the methods you have composed in each of the subclasses (consequentially, introducing overhead and points of brittleness between the interfaces of wrapper and wrappee). Finally, take a tissue to those (manly) tears you've shed over your lack of Traits or Mixins or similarly-sufficient LVOOP facilities to express your application domain. Have a bourbon. Sleep peacefully with your system "that'll do just fine". Dream wistfully of What Can Be. (By the way, you mention Multiple Inheritance, I mention Mixins and Traits -- naturally we must toss Interfaces into the mix -- no need for us to get caught up in semantics and differences between these, further than to agree collectively we gotta have something. Once it's on the docket with a budget for the next LabVIEW release, let's dive into the nitty-gritty of which makes the most sense for our language)
-
Duly Kudoed; likewise, a couple of years ago
-
Agree wholeheartedly, and I think this can be done. I'll make it a point to start a new thread on this topic in the next several weeks.