

drjdpowell
-
Posts
1,964 -
Joined
-
Last visited
-
Days Won
171
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Actually, I like the new Array sizing where the bottom edge is not the bottom of the array. in current gen, the fact that an array has a "coarse" sizing causes issues when the arrays are set to scale with the pane size. After several resizes the accumulated round-off errors build up and the array can be very out of sync with the panel size. Having a size that isn't forced to be an integer multiple of element size means that that scaling will work much better. Once, that is, they actually have panel scaling and splitterbars and the like in NXG (I could not identify any such in 5.0).
-
I think LabVIEW CG doesn't automatically resave files, when opened in new versions, anymore, so that may be the reason.
-
Hmmm, one download, eh? Nobody use SQLite here?
-
Can you run a standard LabVIEW TCP example between you two machines? That would tell me if the slowdown is in Messenger Library itself, or in the lower level TCP layer.
-
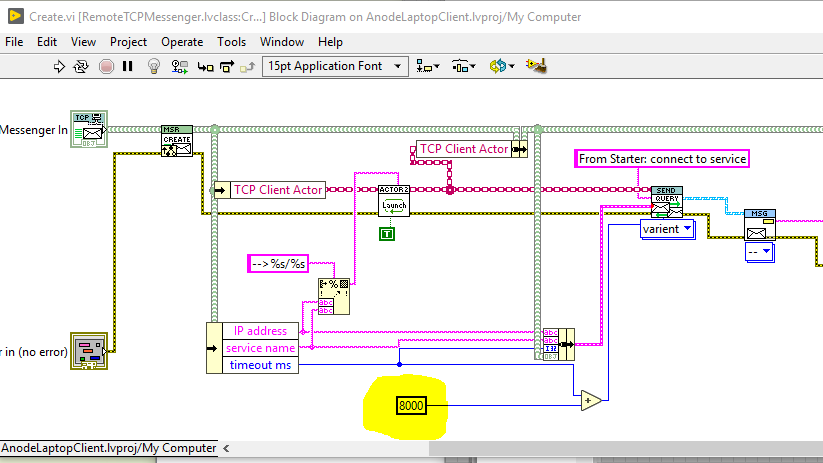
An annotated handling of the "From Starter: Connect to service" message. The Negotiate Version subVI (which talks to teh Server) is taking longer than the default timeout.
BlockDiagram.png.5d317f3019cb25121f7f8ae5681e45e0.png)
-
Are you using the debug tools? Such as Tools>>Messenger Library>>Actor Manager, where you can open the diagram of any running actor:
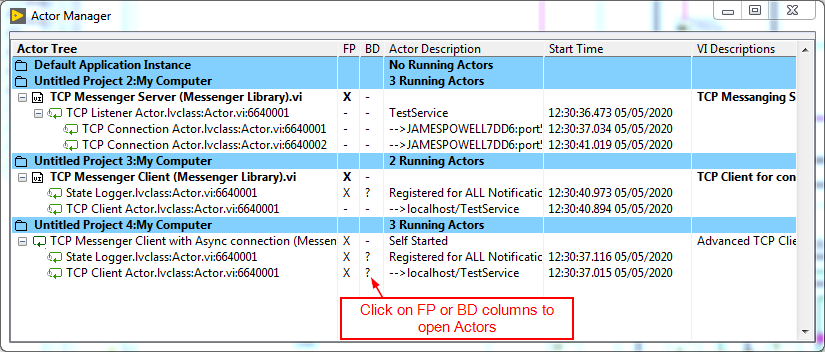
Here I'm running the TCP example included in Messenger Library.
You can open the TCP Client actor and see where it handles the message:
BlockDiagram.png.ff09671b92d6ed8182a63c1eb3e3ce58.png)
-
This is Issue 34, I think?
-
I first got depressed about NXG at one of the CAB sessions at a CLA Summit. It was on UI improvements with NXG. More modern UIs is something that could be significantly improved over CG. Think of all the techniques demonstrated in web pages or smart phones. At the very least, I was interested in the improved menus NXG would have (icons? Tip strips?).
Instead I sat there looking at a giant skeumorphic dial. Lots of detail, sharp and pretty. And resizes, which is nice. But nearly useless to me, as I've had no need of dials in decades. And as far as I know, NXG has yet to even have short-cut menus on controls, let alone have any improvements.
It is seriously sad that vector graphics resizability is the only thing NXG has going for it, UI-wise.
-
 2
2
-
-
Neil, your almost getting me to consider installing the latest NXG and try and give feedback again. Almost. It's too depressing. And there's no good channel for feedback; that forum link AQ gave is practically dead. And I doubt any NXG Devs are keeping up with LAVA. I gave some feedback on the Champions forum, but that's not public.
-
2
-
-
There is no set way to do things. Please use typedefs if you prefer. There are many possibilities, and I am not necessarily using the best ones.
-
 1
1
-
-
Unfortunately, rather than go "where can we make a few key changes that will significantly improve LabVIEW", they went "let's change everything!"
-
2
-
-
The choice you're making is to consider only methods that require lots of boilerplate, methods where one needs to write lots of code that basically duplicates templates with different types, be it user events or Do VIs. That is a problem that can be attacked by scripting tools, but scripting itself is a significant effort.
An alternative is to use generic messages, even something as old school as a text-variant cluster. Then you can write subVIs for communication that you can reuse. Writing a subVI to handle generic messages is a lot easier than writing a scripting tool to write the same subVI for many strict-type messages. Or hand coding all the boilerplate yourself.
Your original post is basically asking if you should do the simple but ugly shortcut rather than the correct but hard way. Your only asking the question because you've chosen techniques that are expensive without scripting tools. To me, who uses generic messages, everything you have been describing seems trivial. Because I wrote reusable communication components that handled these things years ago. They weren't trivial to make, but they're easy to reuse.
Just today I wrote code for a new loop, which requested from another loop the User Event of a third loop, then registered with that third loop for several notifications (preexisting notifications also registered for by other loops) to be sent to the User Event of the first loop. A couple of the notifications get sent by the third loop before the first loop even exists, yet the notification is still received. Not desimilar to what you're descriping.
I had to write no classes and zero new subVIs.
Oh, and the first loop exists in a different exe from the third loop and they are actually communicating though a mediating TCP client-server connection, though both loops just receive User Events and aren't written in any special way to support this (the third loop was written before this app had TCP added as a requirement).
Internally, the TCP client server is rather complicated, but for this application it is just two subVIs, which I wrote years ago. To do a similar TCP connection with multiple application-specific User Events would require a very large amount of boilerplate (or truly impressive scripting ninja skills).
-
Note: the latest 1.9.1 version includes an important bug fix: https://bitbucket.org/drjdpowell/flatline-controls-for-labview/issues/5/control-freezes-ui
Because these are controls, previous copies are not automatically updated, and will need to be swapped out. The affected controls are strings, filepath and combo boxes.
-
Timeout input is on the "Open" method, or it can be changed with a property node.
-
Hi Tom,
That's a lot to comment on, so let me just do stream of consciousness:
- SQLite is fast, but not as fast as more direct writing formats like TDMS. SQLite combines "pretty fast" with "very, very capable".
- One of the limits of SQLite is the number of Transactions per second. This is because, to have ACID compliance for Transactions, it needs to verify complete writing to disk, which takes time. A workaround is to group many statements into a few transactions per second. Note, though, that ACID compliance is a very valuable thing, before I tell you that you can disable ACID compliance and get more transactions per second.
- You appear to be using SQLite as a "current-value table", which requires a large number of independent writes per second, which is perhaps not a good use cae for SQLite. If I were doing a similar app, I would pipe the data to a central component that would buffer data and save it to SQLite a couple times a second. See the "Cyth SQLite Logger" in the LAVA-CR, which can save large numbers of log entries, but saves them once a second.
- I note that you seem to have a lot of tables of only one row to hold data. I would have expected a single table of many rows, with columns like Timestamp, itemID, Value (with Timestamp as the Primary Key).
- Have you looked at the "Attributes" subpalette of SQLite Library? This adds an Attributes table to store scalar values. It also demonstrates making a subclass of the Connection class to add capability, and the option of Preparing common SQL statements only once, rather than every time. Preparing has overhead, which, though it can be small relative to large actions (or unimportant for uncommon actions), can be high for the very small, very common actions you are doing.
It seemed strange to me that you are "querying attributes on each iteration to see if they have changed", but then I realized that you are applying "Model-View-Controller" as an application-level monolithic thing, which I don't agree with. I think the principle should be applied widely, but at a lower level. To me, every bit of state data has a natural place that it "exists". This place is the sole "Model" or "master" of that state, and if the state is in any other place those places are "copies". For example, to me it is natural to say that the "Model" for the Settings of your DAQ processes (SetPoint, etc.) is the process itself, not the saved settings in the db. Noone should be changing the saved settings in the database except the DAQ process itself. Any change of setpoint should happen by requesting the DAQ process to change, and then the DAQ process will save the new setpoint in the database. On shutdown, the DAQ process should write settings to the database. Yet at the same time as viewing the database as NOT the Model of settings, I would happily view it as the Model of the Data History.
BTW, Settings is a great use case for JSON. Save a single JSON item as configuration for each of your DAQ processes. As the DAQ is the Model, only it ever needs to know the format.
Gotta go for now.
-
1
-
Although there can only be one thing writing a specific transaction at a specific time, two or more processes can write to the same file (and same table, actually). They just end up writing one after the other.
-
Just because Actor Framework and DQMH are the two most popular LabVIEW frameworks, doesn't mean there is a binary choice between multiple User Events and the Command Pattern. Personally, I wouldn't recommend either of them for general use (unless you are a scripting wizard, perhaps). And a single message to multiple registered processes is not hard to do without User Events.
-
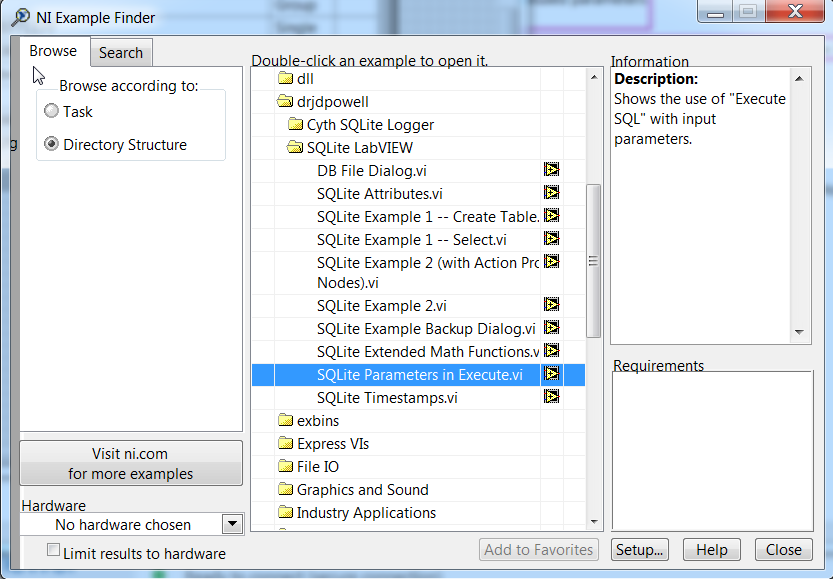
There is an example, found this way:
-
- Popular Post
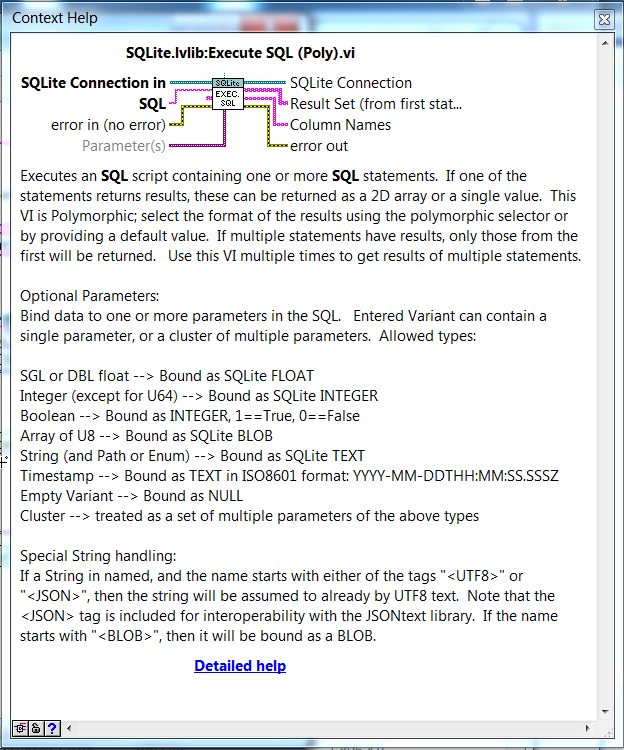
For comment, here is a beta version of the next SQLite Library release (1.11). It has a significant new feature of a "Parameter(s)" input to the "Execute SQL" functions. This can be a single parameter or a cluster of multiple parameters. Uses Variant functions and will be not as performance as a more explicit preparing and binding of a Statement object, but should be easier to code.
-
2
-
1
-
On 7/26/2019 at 3:35 PM, andy_r said:
Just small recommendation to change the library.
Concerning timestamp to string conversion:
The current format string "%Y-%m-%dT%H:%M:%S%3uZ" in "Variant to Json Text.vi" is dependent on localization. On my german windows this leads a to timestamp according to Iso 8601 of "2019-07-26T14:17:20,053Z". Notice the comma for the fractional seconds. According to the Iso both, comma and point, is valid (Apparently, the Iso even recommends the comma https://en.wikipedia.org/wiki/ISO_8601#cite_note-25). However, it seems that the point is used more regularly in practice, for example in .net (see Json.net package). So I would suggest to change the format like this: "%Y-%m-%dT%H:%M:%S%.;%3uZ". This ensures using the point instead of comma., hence the format is independent of your local setting.
Sorry, I had missed this comment at the time. That is a good idea.
https://bitbucket.org/drjdpowell/jsontext/issues/53/force-use-of-decimal-point-in-timestamps
-
I've seen that trick, but I use a single subpanel containing a "layout" subVI (a subVI containing nothing but a set of arrainged subpanels). Then a reentrant subVI containing nothing but an XY graph is placed in all the layouts subpanels. Limited in how many layouts you can have, but 4x4 is probably the most graphs you can reasonably have.
-
You can do this kind of stuff using regular plots and subpanels. Don't know if it is any better, but that's what I do.
-
I've considered a similar flatten-unflatten method, in the default case for clusters too large to handle with the other method, but I've never needed clusters that large and the flatten-unflatten method is ballpark an order of magnitude slower, I would guess.
-
Go with the second option. In general, the communication channel should be owned by the receiver.
-
2
-
Instructional videos on YouTube
in Application Design & Architecture
Posted
I strongly doubt TCP delays are your initial problem. These are designed delays of up to 200ms, so they can't cause a many-second delay.