drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
It's reasonably easy to use SQLCipher. Just pass in the dll and execute two SQL PRAGMAS, one with your license for SQLCipher and one with the database's key (https://www.zetetic.net/sqlcipher/sqlcipher-api/). No new calls are needed.
-
Sorry I never got back to you here. That error looks like the extention dll is missing. I would check to see if it is at the path specified in teh error message.
-
Mapping Enums onto SQLite Text type is intentional. The "Parameters" feature didn't exist back in version 1.7.3. Note that if you are converting data selected from the database, you can convert either Integer or Text as Enums, but with Paramaters (going into the database) one has to make a choice of type for Enums, and the choice I made is Text. You can still make Enums Integers, but you will have to use another method, such as "Prepare Statement".
-
JSON is always in UTF-8, and JSONtext will try and convert to your computer's character set automatically, so I don't think you need any of that stuff that has "UTF8". Try simply using the single function to convert to a 2D array of strings. However, by sure you are actually passing true JSON, with UTF8 encoding, not whatever your computer is using.
-
I checked that it works for me, in LabVIEW 2021. Does code this simple fail for you:

-
Does that DLL exist at the stated path?
-
Can you give an example VI showing the problem. It seems to work in teh current source code.
-
 I think this is teh same issue as this: https://forums.ni.com/t5/JDP-Science-Tools/Cannot-Install-JDP-Science-Common-Utilities/m-p/4418396#M205 The SQLite package requires JDP Common Utilities, and that package seems to have a problem. Workaround is to download it and have VIPM install it directly, rather than try and get it from the Tools Network servers (it's a server issue, not a problem with the package itself). I'll attach it here as well. Try installing this and then retry installing SQLite. jdp_science_lib_common_utilities-1.4.1.18.vip
I think this is teh same issue as this: https://forums.ni.com/t5/JDP-Science-Tools/Cannot-Install-JDP-Science-Common-Utilities/m-p/4418396#M205 The SQLite package requires JDP Common Utilities, and that package seems to have a problem. Workaround is to download it and have VIPM install it directly, rather than try and get it from the Tools Network servers (it's a server issue, not a problem with the package itself). I'll attach it here as well. Try installing this and then retry installing SQLite. jdp_science_lib_common_utilities-1.4.1.18.vip -
Does making it a typedef prevent the problem?
-
What was this error? I can't seem to reproduce it.
-
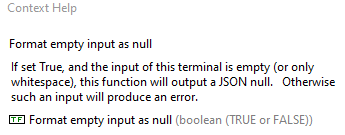
I will change the terminal name to "Format empty input as null" to prevent reading it as referring to JSON Strings in the input rather than the entire LabVIEW string. And I'l try and give a better description:
-
I confirmed the behaviour on my machine. It is that the Write doesn't pass the file reference through if there is an error in. Seems like a bug to me.
-
I just checked, and it doesn't close teh file reference, but it does pass out a null reference. The original reference is still valid. This is still unexpected behavior, though.
-
Yes, Queues don't make unnecessary copies, but User Events make two copies, so the EventDVRmessenger is just to work around that.
-
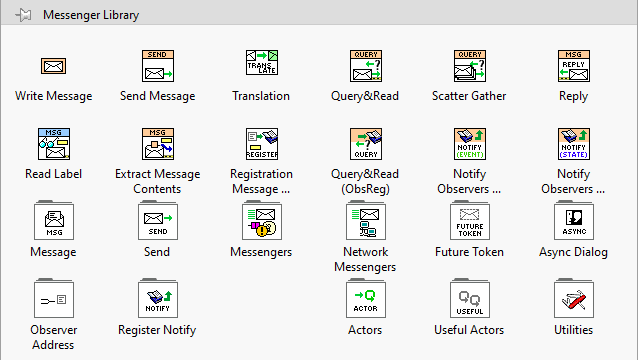
I have put some effort into improving the VI icons in Messenger Library, in hopes of making things clearer. I have particularly been trying to get rid of the magnifying glass icon, which was standing in for too many concepts. I have also tried to improve the Palettes by putting the standard VIs (that one would most commonly use) in the root-level palette: The 2.0 version also introduces Malleable API methods (the orange-coloured ones), which make code cleaner. If anyone could spare some time, it would help me to have feedback. Especially from people who have not used Messenger Library before, so I can get an idea if the key concepts come across. New 2.1.3 version is available here: https://forums.ni.com/t5/JDP-Science-Tools/New-icons-for-Messenger-Library/m-p/4412550#M192
-
- 3
-

-
I'm sorry, you posted just before I went on a full month of holiday and I never saw this. Do you still need help? Any further info?
-
Has anyone had a chance to use teh new version? At least as far as trying the new examples.
-
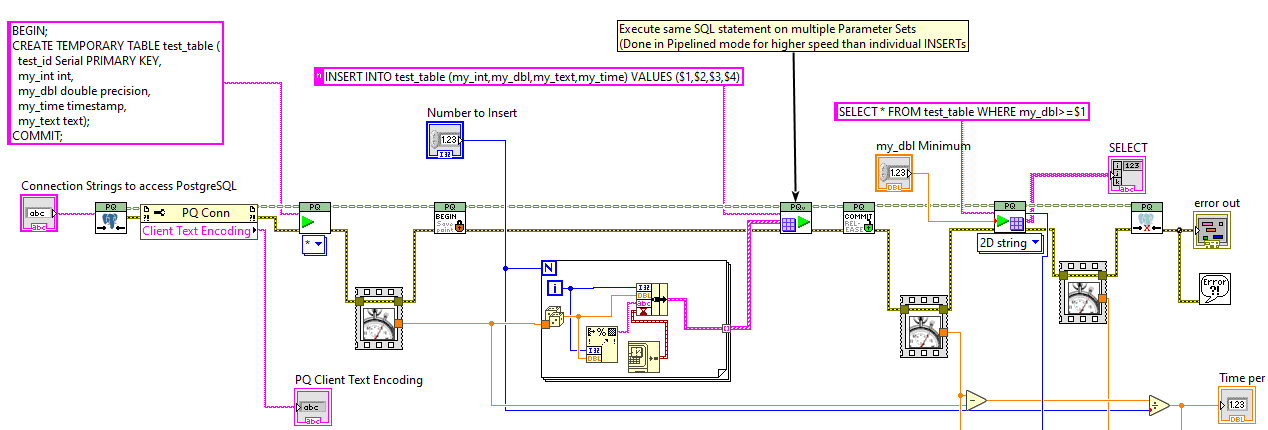
0.6.0 version now on VIPM: https://www.vipm.io/package/jdp_science_postgresql/ This involves significant improvements, as well as Examples that work with a public postgres server (and thus work without needing Postgres installed). I am hoping this is close to a 1.0 version.
-
I have published a 0.3.1 package on VIPM.io with Antoine's changes (LabVIEW 2017). Then I've accepted your Pull Requests and published a 0.4.0 version as well (LabVIEW 2019): https://www.vipm.io/package/jdp_science_postgresql/
-
VIs without Front Panels - or with several!
drjdpowell replied to GregSands's topic in LabVIEW General
I think your second point is wrong; VIs without the front panel loaded don't use any resources. EXEs don't even include the code for those front panels. -
I think this is a Windows touch-screen behaviour, due to Windows using press-and-hold to give a right click. Windows waits for the release before sending "mouse down" so it can decide to make it a right click or not. It's annoying but I have not found a way around this.
-
Note the WITHOUT ROWID keyword also, as that could make a significant performance improvement with this kind of table.
-
A non-JSON option you could try is: CREATE TABLE TestData ( Channel, Time, Data, -- individual reading at Time for Channel PRIMARY KEY (Channel,Time) ) WITHOUT ROWID This is every reading sorted by a Primary Key that is Channel+Time. This makes looking up a specific channel in a specific Time Range fast. BTW, you don't need to make an index on a Primary Key; there is already an implicit index . You would select using something like: SELECT (Time/60)*60, Avg(Data) FROM TestData WHERE Channel=? AND TIME BETWEEN ? AND 1717606846 GROUP BY Time/60
-
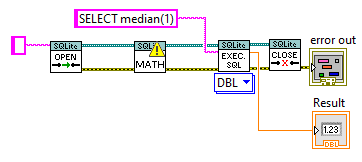
Why don't you just try it? Open your SQLite viewer app if choice and execute "SELECT * FROM sqlite_schema"
-
You're looking for the sqlite-schema table: https://www.sqlite.org/schematab.html