

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
But I can see that for some applications this is useful. I would have never realized you could register all events like that.
In practice I wouldn't register all controls on a front panel like that; instead controls (or groups of controls) which need special code would have their own case. But multiple controls can be registered for the same case, either statically or dynamically as an array of references.
I would not create a polymorphic instance for temperature and for pressure. I only have the generic types that were not included in the native types library. Since both of those are DBL and I already have that I do not need a new entry.A DBL with an attached unit is a different type than a DBL (no unit). The wire will break if you wire them together (or if the units are incompatible). So to use units with messages you need separate message types for each base unit. Or use a variant.
You could just not use units, sending raw DBL messages and relying on the receiver to know what the unit is, but united numbers are useful for preventing bugs.
Edit: Maybe we should move this off of the announcements board
Probably, is there a LapDog discussion group?
-- James
-
For your entertainment pleasure, I've included the block diagram of my main vi
Could be worse, look at a project of mine from a few years ago before I learned anything about architecture (the labels you can read are in 106pt font!!!):
-- James
PS: One thing you need to attend to, though, is your wire routing. You have many places were your wires go under other structures in very confusing ways (I think one wire is running backwards under another wire!). Learn to use the "Clean Up Wire" Menu option.
-
In the past I was never able to get it to function correctly via ODBC to serve as a replacement for MS Access so I'm very interested to hear how this turns out.
I'm afraid I'm not getting much further. I can upload text into the binary container (though not download it) with ODBC, but trying to upload binary (ADO datatype adBinary or adLongVarBinary) returns "Invalid type". I'm using the Database Toolkit.
The admin who runs the Filemaker hasn't been able to do it with ODBC (non-LabVIEW) but he has uploaded binary with JDBC.
-
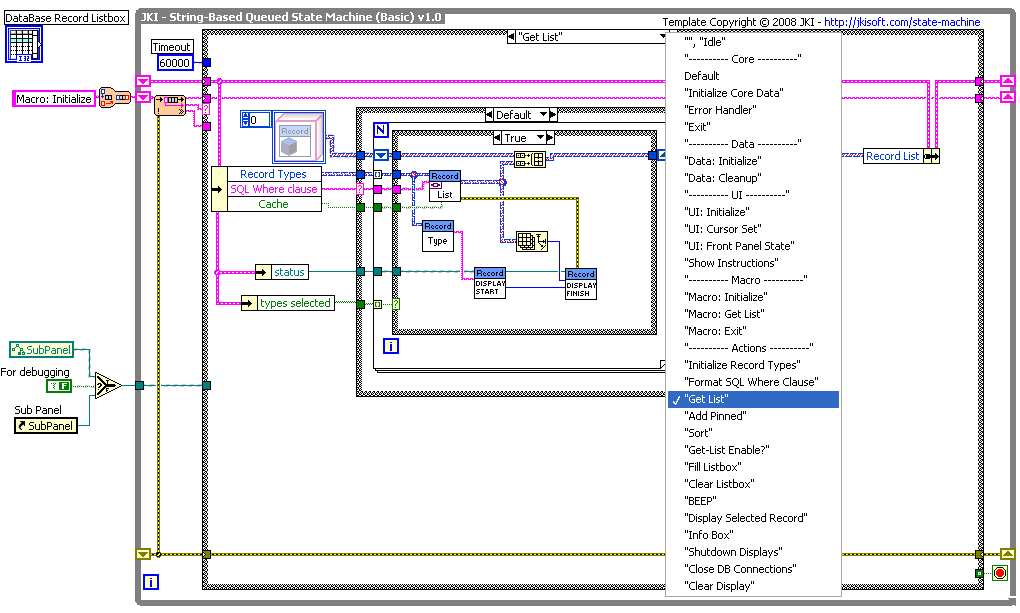
Here's an image of a recent large (for me at least) project:
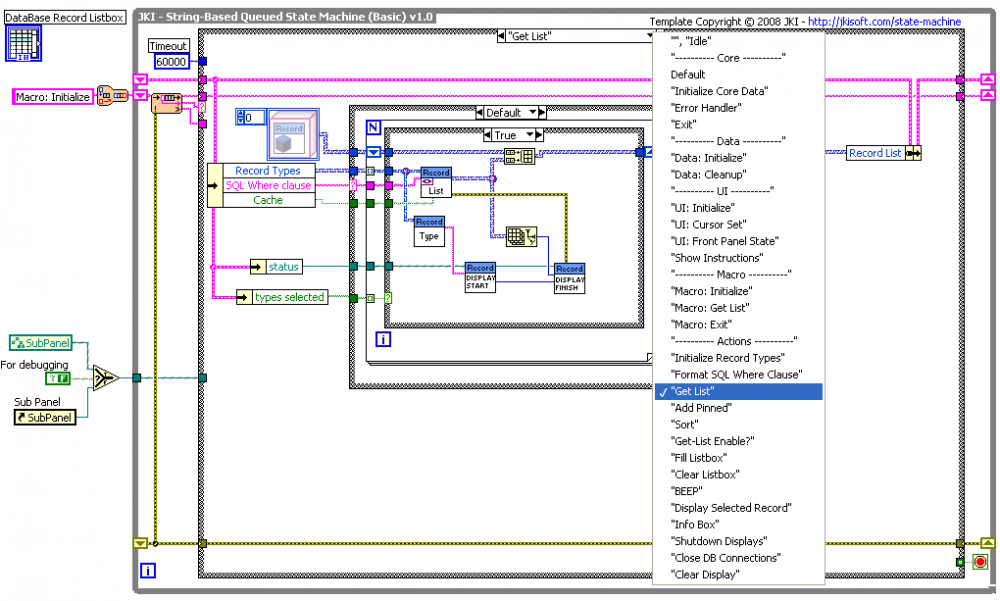
This is the top level of the program, which is a "Database Viewer" for displaying several different types of measurement records in a database. It is based on a free template available from JKI, a form of something known as a "Queued State Machine" or QSM (though Queued Operation Machine would be a more apt name). In a QSM, a large program is organized into various frames of the outer case structure, with some queuing mechanism for calling the frames in order, and some kind of memory for organizing data available to all frames. Google "JKI state machine" for more info.
Not so obvious, but seen in the image is another technique: clustering closely-related information on one wire and having a set of subVI's that act on that wire. This allows the top-level diagram to be much clearer and simpler. The best way to do this is with LVOOP "Classes", though one can instead use type-def clusters. In the image you can see the use of a "Record" class, and most of the complexity of the program is hidden in that class's subVI's.
-- James
-
I attempted to create some custom probes in my last LVOOP project and ran into a few stumbling blocks:
I've tried adding a dynamically-dispatched method called something like "Text Description" to my classes, which outputs a human-readable summary of the object data. "Text Description" in child classes call their parent's "Text Description" and add-to or modify it, building it up (possibly through several levels of inheritance). Then this method can be used in a single probe that works on all child classes.
There are some probes of mine in this image from another conversation:
The probes themselves only work with Text. It works well if each level of the class hierarchy isn't too complicated, and can be meaningfully summarized in a few words.
-- James
-
I have created a bunch of datatypes as I needed them and put them into my own library. I gave up on adding them all to the palette and now my create and get messages are all in polymorphic VIs. Variant is one of them. But I don't like that one because I have to convert the message to the variant subclass then to the datatype. I would rather just add a new entry to my polymorphic VI whenever I need something not already there.
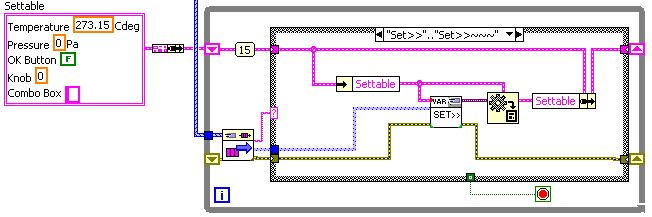
I guess one of my problems is that my own messaging design has too many polymorphic VIs to add to. In the quest to make the wiring simple I have polymorphic VIs for Write(create), Extract(get), Send, Reply, Query, and Notify Observers. So using the inbuilt polymorphism of the variant-to-data primitive is attractive. For example, here's a quick rewrite of the lower receiving loop in my previous example, where the "Sett>>..." messages set the internal data values of a cluster in a shift register (a form I use a lot):
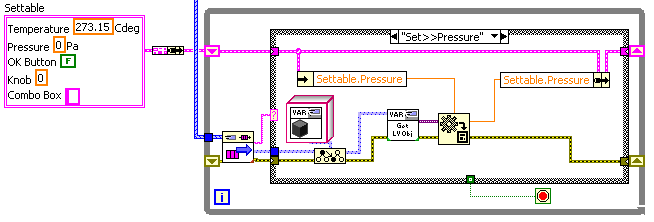
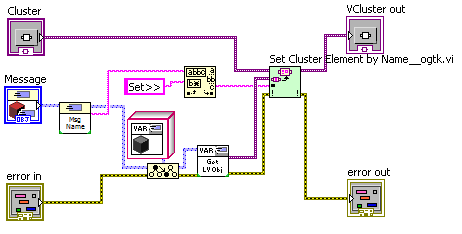
To extend this to accepting Set>>Temperature messages, I just need to duplicate the frame and select the right element of the shift-register data cluster. I don't need to change the message type. Or alternately I could use the OpenG Variant tools and write one case to handle all "Set>>..." messages:
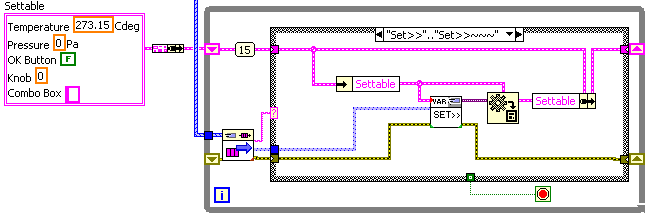
The "Set>>" subVI:
Now I can add new "settable" items to the shift-reg cluster (and drop corresponding controls in the UI) without any new wiring to do.
-- James
Opps: just noticed I left the "Get Var" subVI with the original "Get LVObj" icon; hope that isn't confusing.
-
1. Variants are usually used for custom data types, which implies typedeffed clusters or enums. I don't like using typedeffed clusters as part of my public interfaces between components. Their lack of mutation history makes it too easy to unintentionally and unknowingly introduce bugs.
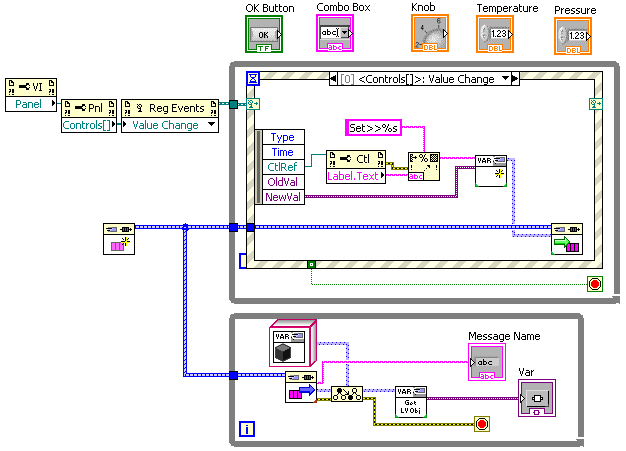
I see the great value in using custom message objects instead of custom cluster typedefs (particularly if you use the "command pattern" and dynamically dispatch off the message), but I'm talking about using variants for standard LabVIEW datatypes. From my (more limited) programming experience, I more often use variants to write "generic" code that handles multiple simple datatypes, not large typedef clusters. Now, a large number of simple-type classes (combined with large polymorphic VIs as Steve mentions) will perhaps do everything Variants do, BUT, isn't this reinventing the wheel? Variants have a lot of nice features and are pre-existing, supported by NI, and have lots of utility code written in them already (love the OpenG stuff). Using Variants lets one interface more cleanly with LabVIEW features that already use variants to represent simple data types. For example, here's a simple code for a test UI, where all front-panel controls are connected to a message queue such that all "Value Change" events on any control are sent out as "Set>>{control name}" messages in a VarMessage:
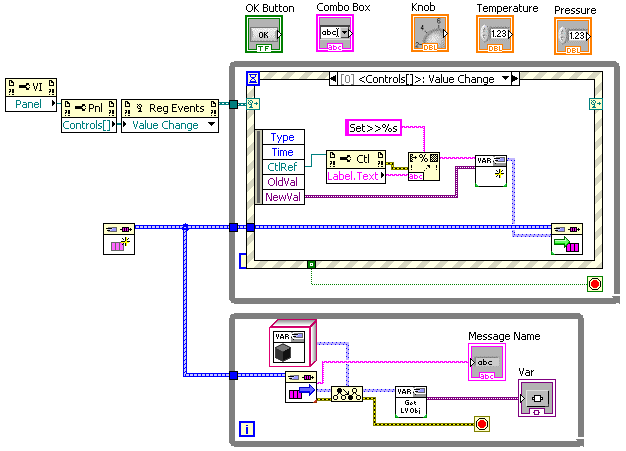
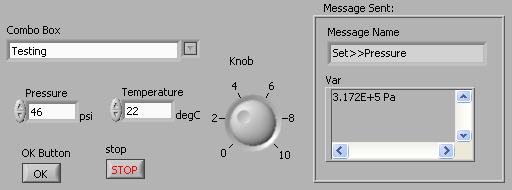
Here, I'm directly connecting to LabVIEW's ability to handle multiple control types in a single event frame, via variants. If I want to add a control, I just drop it on the front panel and give it the right name and it's done. Writing code to receive variant messages and update the appropriate control (by lookup of the control name) is only slightly more complicated. To do this UI without variants, I would have to stop and create new message types for the pressure and temperature unit DBLs (it's going to be a big polymorphic VI, Steve, once you get to all the different possible units!), then configure an event frame for each control.
2. Historically, the current LapDog.Messaging package evolved from a similar library where every message was a unique class. When that proved too cumbersome for my liking, I moved towards the current system with message classes based on message data-types instead of the message itself. Since my goal is to send data, not send a variant (the variant is just packaging that allows arbitrary data to be sent on the same wire,) I never had a reason to create a variant message type.But again, isn't this reinventing the wheel? Your goal is to send data, and variants are designed to send data.
3. When I'm building an application one the things I'm most concerned about is the interactions between components and what the dependency graph looks like. Variant message, imo, obscure the dependency relationships that are being created. Sending data via a variant message is as easy as hooking an arbitrary wire up to a variant input terminal. I may not realize I've created a new dependency until I go to code the message receiver and try to convert the variant to real data. Who knows how much work I'll have to redo to break the unwanted dependency. By requiring a new class for each message data type (or to a lesser extent dragging the message creator from the project window) I'm forced to confront and resolve the dependency issues before I write the code.I like things to be as "easy as hooking up a...wire". I imagine one could design a "SimpleTypeVarMessage" that would produce an error if one connected a cluster to it; that might address your dependency issues.
Ultimately, the decision about VariantMessages is left to the individual. I never intended the packaged message types to be a complete set... just the most common ones. I always create application-specific Message child classes with custom data types, and users should feel free to create their own Message child classes for reuse that are appropriate to their situation.Custom messages I see the advantages of, but that seems a lot of work. Also, isn't the use of custom messages a "dependency" in an of itself? I haven't worked with them enough to know, but it seems like custom messages to talk to a module is a dependancy.
Yep, it is. Personally I have no desire to create and maintain all of them. Maybe someday NI (or a charitable Lava contributor) will do it. I've already explained why I don't use variants, but that doesn't make the need for classes for each custom data type any less daunting. Personally I think that requirement is more or less a result of Labview's G's nature as a statically typed language. Using variants doesn't solve the problem, it just moves it around a bit and makes it harder find.But variants ARE a pre-LVOOP solution to the problem of a wire carrying multiple datatypes. Wrapping that solution in a message class is a lot easier than reinventing it.
-- James
-
So what are you waiting for? Download it now and give it a try! (Don't be afraid to leave feedback... positive or negative.)
Question: Why don't you have a "VariantMessage" Type? You have an I32Message, and one could extend that with U32Message, I16Message, DBLMessage, etc. etc. etc., but that's a lot of message types! Is there a reason not to use a single VariantMessage Type to send all simple data messages, rather than a long list of native types?
I ask because I've been experimenting with my own (similar to LapDog) message design, and there seems to me to be a lot to be said for using VariantMessages.
-- James
-
From searching around it seems doable but I will let you know how I go!
I'm currently trying to upload binary data from LabVIEW into a Filemaker 11 Container field via ODBC and I'm getting nowhere. I wondered if you were able to do this? I can upload non-binary fields fine.
-
From this simple test vi I built you can see that it is very inconsistent compared to the other methods.
The other two methods aren't precise enough to see the <0.5ms variation in times. The ms timer can only time to the millisecond, and the datetime is even less accurate.
-
I thought, "Well, maybe *I* haven't needed it, but it'll turn up in code by others," but in a brief search this morning I can't find any examples of typical programs that do this in other languages.
Actually, I just came across an example of exactly this use, in an "LVOOP Event Handler" by Francois Normandin:
http://lavag.org/top...dpost__p__79074 (you can see "Preserve Run-Time Class" being used in the image)
He uses it slightly differently, to allow the publisher to specify who can subscribe to an event, while I intend to use it to allow the subscriber to specify what events they are interested, but it's basically the same.
-- James
-
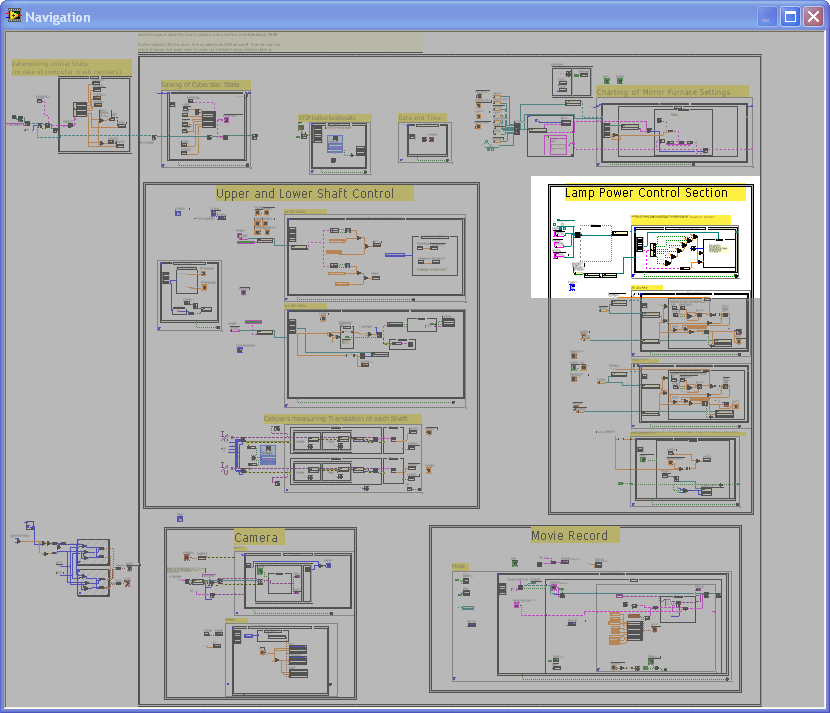
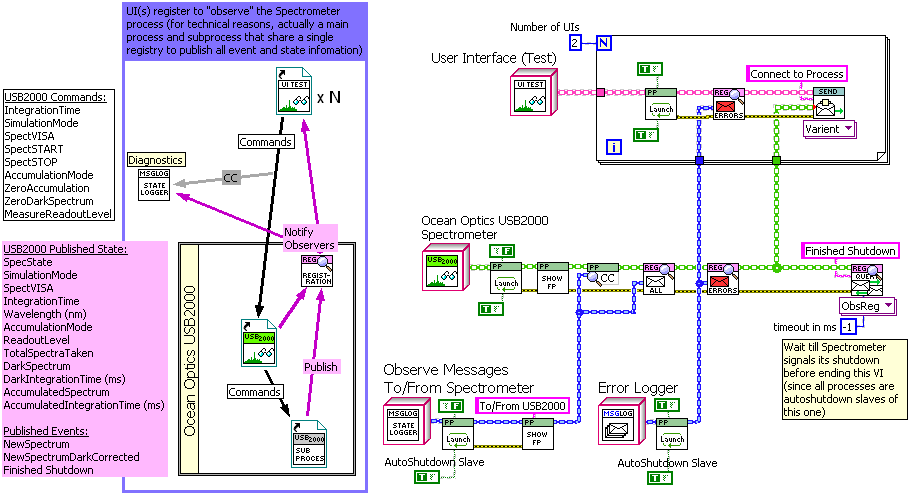
If anyone is following this, here's some images from one of my first projects using (and continuing to develop) this Active Object design. Its an active object that runs an Ocean Optics USB2000 spectrometer. There are actually 6 "Parallel Process" style objects involved: "USB2000" itself, a subprocess object ("USB2000sub") that synchronously communicates over USB to the spectrometer, two clones of the simple testing UI (two to make sure changes on one reflect in the other), and two different types of message loggers (one for errors and one to monitor all communication by "USB2000"). "USB2000" and "USB2000sub" together publish events and state information via it's Observer Register, to which the UIs and loggers subscribe. There is a mix of Queue and User-Event communication here, with "USB2000sub" and the error logger being based on the queue-messenger template I showed in the initial post, while the other active objects use User Events. "USB2000" itself is based on an adapted JKI-QSM template.
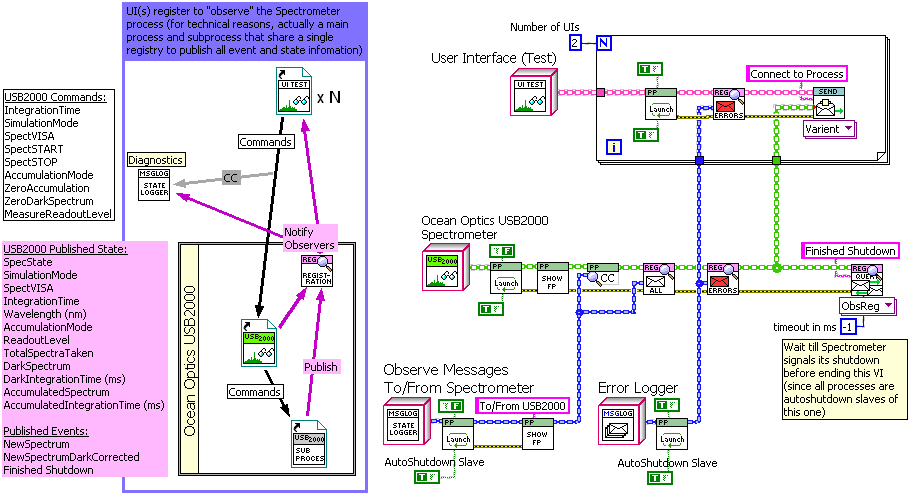
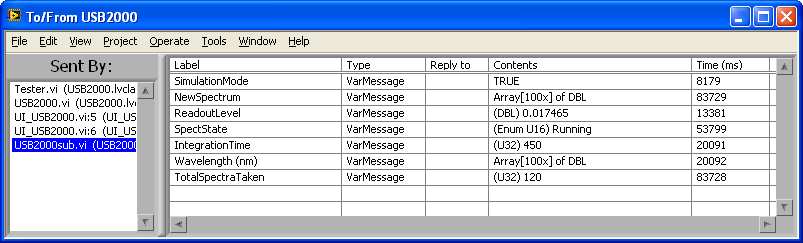
Here's a shot of the "State Logger", which displays the last received message of each label, organized by what VI sent it (here it's showing "USB2000sub"):
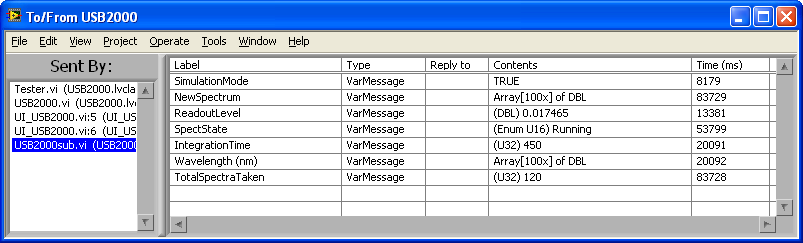
There is now two different types of published messages, "Event" and "State". The difference is that the Register keeps a copy of the last inputed "State"-type message, allowing it to immediately inform newly registering observers of the current state information.
-
I can't really come up with a way to do this in LV 8.6 short of you adding a new method to your class hierarchy for "Is X a child of me?" and a second method for "get class name", which each class overrides correctly.
I ended up leaving this feature on the to-do-list awaiting an upgrade, and just hard-wired in the ability to register for all children of "ErrorMessage", that being the only use case I need at the moment.
I'm also considering adding the ability for the publishing process to organize groups of messages into "topics", with subscribing processes registering for topics of interest. This would obviate the need for registering message classes.
-
It's a highly unusual request.
It is?
What I have is an "Observer Registry" (mentioned in my "Parallel Process" topic) that deals with "Message" objects published by one process, to which other processes can register for. I would like the other processes to be able to specify what specific types of messages they would like to be notified of. For example, Process A may be interested in all "CommandMessages", a child class of Message, and any children of CommandMessage. This could be done by Process A passing a default CommandMessage object to the Observer Register, and then having the Register check every Message published to see if it is a child of CommandMessage. The Register would then be dealing with two children of Message (on Message-type wires) and needs to see if one is the child of the other.
-- James
-
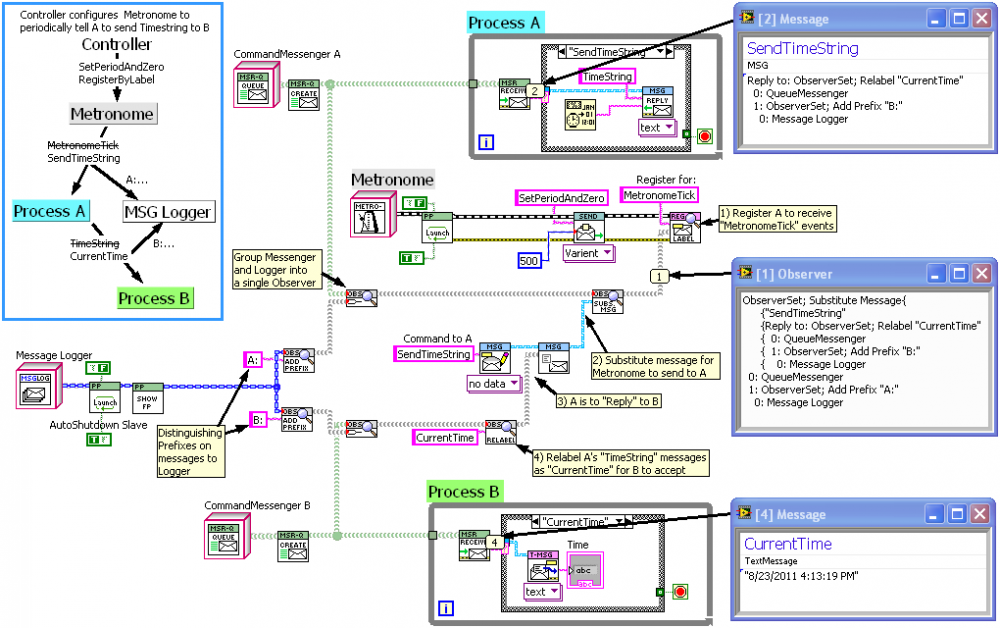
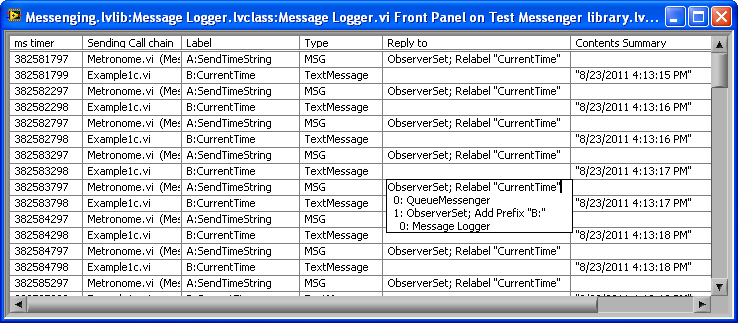
An update:
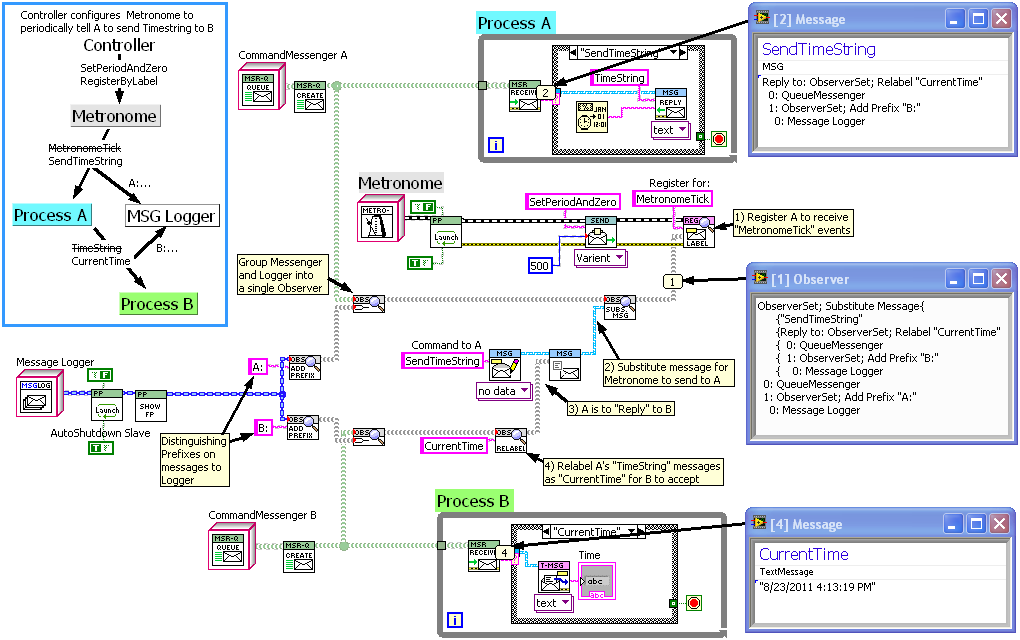
As I've had the chance to improve the API for my "ObserverSet" Class, here is the more complex example from above (the one where the Metronome object is used to instruct Process A to periodically send it's time string to Process B) redone with improvements that hopefully make it clearer. Included are some custom probes to see what the Observers and Messages look like.

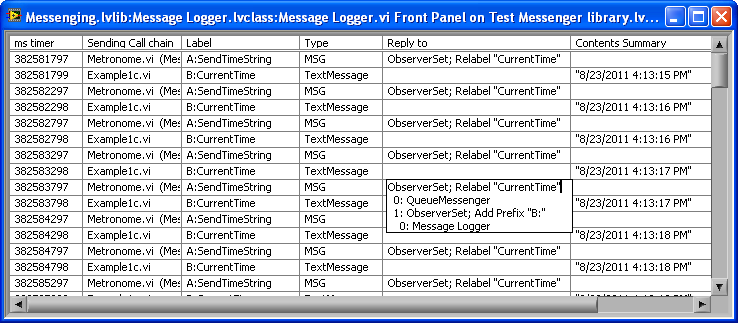
Observers (aka ObserverSets) serve as containers of any number of Messengers (or Active Objects), where sending a message to the Observer sends it to all the contained Messengers/AOs. In addition, an Observer can be set up to automatically alter ("translate") the messages sent by it: in the example they are used to relabel a message, add prefixes, and substitute one message for another. ObserverSets are internally recursive to allow multiple levels of translation.
Observers have the additional features of never throwing errors into the process using them to send (the Messenger throwing the error is just dropped internally), and never allowing the process using them to access the contained Messengers/AOs other than to send to them.
-- James
-
It indicates that control has a default value saved that is different than the usual default value for that class (i.e. someone probably choose "Make Current Values Default" after running the VI). The changed default value might be causing your issue.
-- James
-
 1
1
-
-
-
Check mike5's posts at the end of this thread. I am not sure it will work for you as it is a specific implementation.
I need to get around to upgrading; I can't seem to do this in 8.6 either

-
Found what I need: the "Preserve Run-Time Class" function. Unfortunately this isn't in the LabVIEW 8.6 that I'm mainly using.
-- James
-
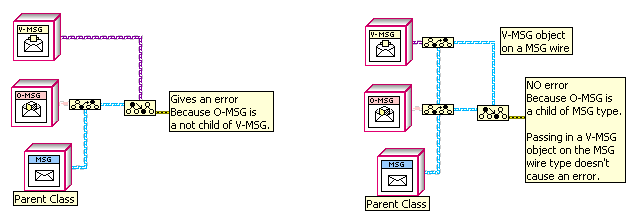
I'm confused; why wouldn't it? If you have two To More Specific Class primitives where class A goes into the reference of the first and into the target of the second, and class B goes into the other inputs, then you should get an error on both only if there is no relation between the classes.
It's because I don't know either child at runtime; I only have parent-type wires. The "To More Specific Class" function only uses the type of the wire, not the actual object on the wire at runtime. See below:
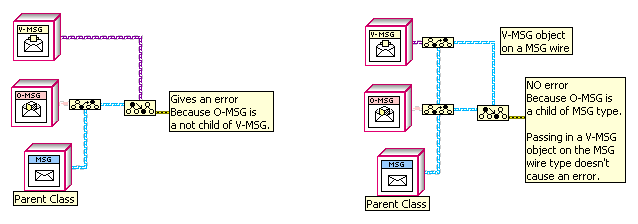
I could do what I want if I could programmatically get a list of an objects ancestors; does anyone know how to do that?
-- James
-
Have you tried using "To More Generic Class"? You should get an error if it's not a child.
Doesn't work, because those functions use one of the inputs just for the wire type (which has to be the Parent), ignoring the specific child on the wire.
-- James
-
I'm probably missing something obvious but I can't seem to do the following:
Imagine I have a class tree with parent, children, grandchildren, etc. How do I take two objects in on parent wires and tell if one object is a child of the other?
So for example, if Parent P has Children A and B, with grandchildren A1 and A2 of A, and B1 and B2 of B, I want a subVI (with two "P" inputs) that if comparing A and A1 returns "true", but if passed a B and A1 returns false.
-- James
-
Both methods require that the module have some way of discovering what Msgs it cares about or what specific waveform module it is.
This will create some additional coding to make the module more intelligent.
The benefit IMHO is you have a very loosely coupled, more reusable, debug able, testable module.
Aside from the framework parent class dependencies, Each module is stand alone and totally independent of its caller or callees.
It's up to the module developer to figure out how to register, react and send the correct Msgs.
Have you considered adding some kind of optional local scoping to your framework? Sort of a "local router subnet". If you had the option of specifying a local scope when registering to send or receive a specific message (such as string like "UI subnet") you could easily set up an arbitrary number of Waveform Generators under different scopes, communicating independently with different modules, without needing to extend the code of any module. Local scoping could also increase the flexibility of your framework, allowing more hierarchal "module-submodule" relationships in addition to stand-alone modules.
-- James
-
My acquisition device outputs 4.096V @ 15 mA and I need to control a 24V solenoid valve which draws 167mA with 144 Ω.
Note: I have a 24V source and I need to open/close this valve once in 48 hours.
Can I only use a 5V relay for this task or do I risk any damage to the acquisition device? Should I go with a transistor then?
You should be able to us a 5V input SSR. Something like this Cyrdom CN024D05.
-
1
-

LapDog Messaging Library v2 Beta 1 is available!
in Announcements
Posted · Edited by drjdpowell
Here's another modification of my example of Variant messaging, this time to send an Enumerated Constant to another module that doesn't actually know what the Enum's definition is. Imagine the sending module has a configuration Enum that it sends to the UI module to allow the User to select a configuration. Coupling would be looser if the UI didn't need to depend on the definition of the Enum. We can do this by having the UI module use the OpenG "Get Strings from Enum" VI, and setting a Ring control to match the Enums strings. When the User selects a configuration, the UI sends back the corresponding Ring value (U16), which is automatically cast back into the Enum by the "Variant to Data" primitive in the sending module:
-- James