

drjdpowell
-
Posts
1,970 -
Joined
-
Last visited
-
Days Won
172
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Hi Max,
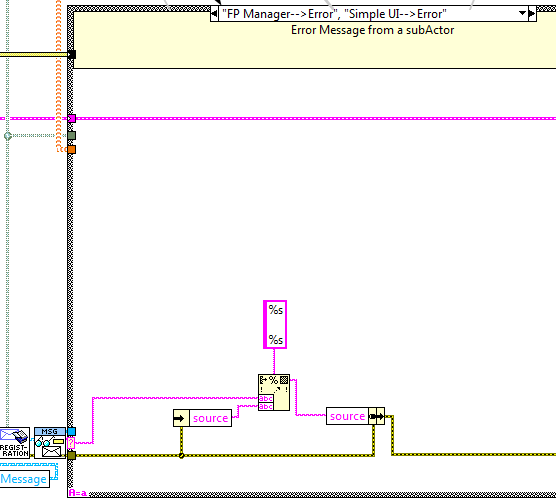
I just use the message translation for errors, as well as other messages. There is more than one way to do it; a simple way is to just register for all errors and relabel the messages. For example, here I launch a "Simple UI" and relabel its error notifications as "Simple UI --> Error". Then, in the case that handles that error (as well as differently-named error messages from other actors, I just attach the message label the the error description, so that the User knows where the error came from.
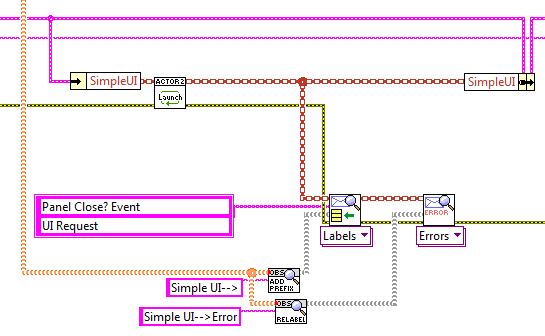
Then, in the case that handles that error (as well as differently-named error messages from other actors) I just attach the message label the the error description, so that the User knows where the error came from.
-
 1
1
-
-
15 hours ago, ShaunR said:
It's like saying a kitchen, bedroom or bathroom is a house.
Yeah, but some of your room types are complimentary and some are not. You’d have a kitchen and a bathroom in your house, but not a modern kitchen and a 19th-century kitchen.
-
By "Producer/Consumer”, do you mean the simplest interpretation of “you can have a loop that consumes elements from a queue that are enqueued elsewhere”**, or the application of that in many NI examples of a “Producer” loop that receives Events and send enqueues messages to a second “Consumer” loop (which also enqueues messages to itself), as in the “Queued Message Handler” or “Continuous Measurement and Logging”? It’s the latter architectures I find poor^^.
A better architecture is to have a “main” loop that is based on handling Events (the JKI “statemachine” template is a good example), with blocking operation like Dialogs handled in a small, simple, specialized parallel loop, that sends its results back to the main loop.
** A very important concept but not, by itself, enough to be an architecture.
^^ a pet peeve of mine; I’ve actually given talks on weaknesses in these examples (link)
-
Personally I recommend against using NI’s “producer consumer” stuff as a guide. Both your UI loop and your PLC loop need to both produce and consume information.
-
4 hours ago, ASalcedo said:
Could you tell me how I can use those can of asynchronous dialogs that you use?
Mine are built in to Messenger Library, the framework I use. A video on them.
But separate UI and PLC loops might be a better option for you.
-
You need some kind of parallel structure so your dialog can go on in parallel to your hardware handling. I actually use a special version of dialogs that are asynchronous and send their results back as a message, but the more common way is to have a separate loop of some sort.
-
20 hours ago, hooovahh said:
I don't see myself ever using the pink-ish one but all the others I could see uses for depending on the UI design.
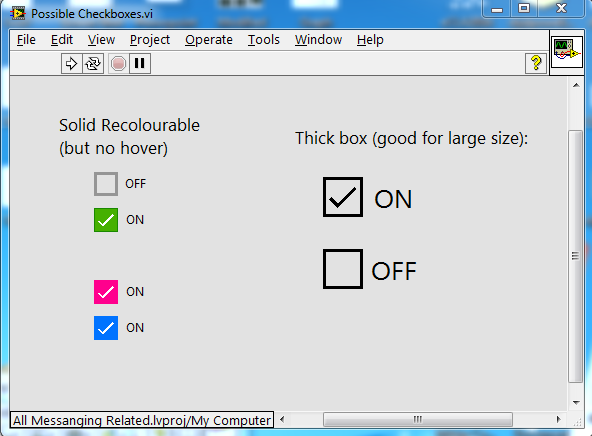
You can colour it whatever you want. I just copy-pasted the green one a couple of times and changed the colour**. I just wanted to make sure people knew that, as most custom control sets available on the Tools Network are based on PNGs, which cannot be recoloured (and don’t resize well either). I’m trying for resizability and recolourability. I include the “Google style” checkbox, because it is nice and fits well with other Google Icons, but it is not resizable or recolourable, unless you manually swap out the icons with new ones from materialdesignicons.com.
**Note: it’s slightly tricky to change the colour, as the checkmark’s invisible containing box blocks the colour tool from affecting the box underneath, unless you click near the edges. Unfortunately, the checkmark isn’t recolourable (it’s a vector graphic imported from LibreOffice).
-
1
-
-
There are multiple ways to do things; but pick one. Be wary of mixing different methods in such a way that the result is overly complex. So when you mention mixing CVT with an independent messaging system, that’s a worry. Note that smithd’s Projects don’t mix the two.
Personally, I follow the messaging paradigm, rather than CVT-like tags (my tag-like functionality is a Register-Subscribe notification system build on messages), and I have a standard library and template for QMH “actors” (note: NOT Actor Framework) that can communicate locally or over TCP/IP (some videos).
-
1
-
-
- Popular Post
- Popular Post
Thanks. There is actually a couple more checkboxes that I've considered adding, but I have an excessive number of check boxes already.
-
4
-
I suspect the terminology is a holdover from the programmers of LabVIEW, who were loading into and unloading from the execution system, rather than memory.
-
Bad terminology then; it should be “Reserve and retain on first call” or similar.
-
For comparison, I have a 2GB test SQLite database with 660k spectra, each of about 140 wavenumber (WN) readings, a total of 91M rows of Time, WN, Value. These are stored in a "Without ROWID" table with primary key (Time,WN) I select regions of interest (ROI) in WN and Time, and I average spectra over time intervals (every 100 seconds, say), then take some statistic like a maximum of an average over each interval. With WN ROI of about 30 points, and a time range of a few percent of the data, update time is about one second. Doing the full time range takes 30 seconds.
I don't understand why MySQL and Postgres are not able to get comparable results. But I would suggest trying (Time,id) as your primary key.
Notes:
-- the 2GB file is small enough to fit in the Windows File Cache, and so there is no disk access involved.
-- SQLite is only using a single CPU for this, so it doesn't matter how many processors my computer has
-
Remind me. What Primary Key do you use? Is it (id,time) or (time,id)?
Oh, and what hardware are you running on?
-
- Popular Post
- Popular Post
On 05/05/2010 at 0:43 PM, Dan DeFriese said:Here's the example code for setting the CCSymbols programmatically.
Thanks.
Here's a more developed subVI that I've used successfully inside a Pre-build action. I use it to set a Build CC symbol to be equal to the Build Name, so different builds can enable different code.
-
3
-
 3
3
-
This example gathers references to all non-indicator controls on a Tab. Controls whose names end in "_IGNORE" are ignored.
All Controls on a Tab Control.vi
LabVIEW 2015
-
1 hour ago, ASalcedo said:
However how can I write and read the whole VI except the image? is there a shorcut way? Because it will be really tedious to put every indicator and controls except the image in the block diagram to reaad/write...
There’s a middle ground between those two extremes, where one operates on arrays of control references. You either create the array of references explicitly (lot less work that coding it), or you get it programmatically from either the pane reference or tab-control tab references. You can even do things like use prefixes in the control’s name to exclude some controls.
-
looks like they don’t have the feature you want. Re your original problem, I wonder if the issue is some very large data that you may be saving in the config file. How large are they?
-
12 hours ago, ASalcedo said:
Maybe there is another library that I can use?
You might see if the MGI Library has similar functionality.
-
I'll be interested in learning your results, as I'm considering Postgres for a data-recording application.
-
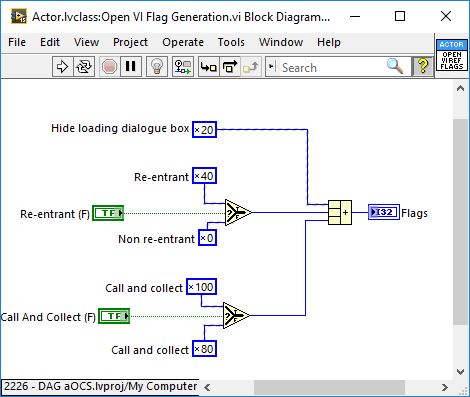
Note: 0x40 isn’t to open a ref to a re-entrant VI; it’s to open a common reference to a pool of shared clones. If you just want a single clone then don’t use 0x40.
-
Dr. Powell: While debugging, we are opening the Front Panels. How? Well... they opened automatically as set in the VI properties (to open when called). We also used an invoke node to open the front panel. It did not change anything.
If you’re using “Open when Called” then the FP will be loaded before anything else happens, so that can’t be the source of your problem. Be wary of using an invoke node on the VI block diagram, as the FP doesn’t exist until after that node executes.
-
Note, BTW, that I haven’t worked on INSERT speed yet (as my application doesn’t require it) and the example only inserts one row at a time. Better speed comes from multi-row INSERTs, and even faster is likely the COPY command, which I intend to support with the toolkit at some point.
Also, from my reading, I wouldn’t expect MySQL to be slower than Postgres (except possibly for complex queries), so I think there must be something wrong with your MySQL benchmark.
-
Also, make sure your FP is loaded before your indicator is written. Your input Controls will show default values if the subVI was run before its FP was loaded, even though the proper values were passed.
-
1
-
-
How are you opening the Front Panels of your clones? If you’re trying to use those references opened with 0x40, you will be opening a different clone that the one you started (someone on NI.com had this problem once).
-
1
-
[LVTN] Messenger Library
in End User Support
Posted
Ah, so the issue is that an actor both replies with an error message, and publishes one. One possible solution is to say that only one actor should “own" the error. If actor_a asked actor_b to do something, and an error occurs, then actor_a is the one responsible for handling/reporting it. You can do this by changing the error handling case to only publish the error message if their was no return address attached to the original request message. Thus you Reply OR Notify, rather than Reply AND Notify, and there is only one error message.