

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
Sorry, Shaun, I didn’t really follow (though I happily nod along with you bringing up “execution state”). I still don’t know what this has to do with OOP (or “services” or “non-reentrant subVIs” for that matter).
-
3 hours ago, ShaunR said:
Why would you want a dataflow construct when the language supports it implicitly, then?
It doesn’t fully support it as message flow between loops. A message to a loop, that prompts further messages from that loop, is like a subVI call in regular LabVIEW programming, in that the action waits for the “input”to be available before it happens. However, this only works for ONE input; a subVI can wait for multiple inputs before it executes. My primary use of Futures is to extend this such that a loop can take an action only when multiple input messages are received. It also helps with ordering arrays. If I call three subVIs in parallel and combine their outputs in an array, that array has a defined order. But if i send a message to three loops, the reply messages can come in arbitrary order, unless I use Futures to specify the order.
There are no OOP concepts involved.
-
I didn’t get the OOP reference, and don’t want the casual reader to think that “Futures” are an OOP concept. They’re a Dataflow concept. We don’t have “Futures” explicitly in LabVIEW, because every wire is implicitly a future.
-
My “reply addresses” in “Messenger Library” are also actually callbacks. Callbacks are very flexible.
Just as a note, my experience with “futures” (or “Write-once, destroy-on-reading Queues” as they are implemented as) is that I mostly use them to easily implement the Scatter-Gather messaging pattern, plus occasionally a Resequencer. Both come up when one is interacting with multiple loops, and reply messages can arrive in arbitrary order. “Future tokens” allow enforcement of a specified order.
-
12 hours ago, Daklu said:
I can't speak to the attitudes of the larger community, but my terminology preference is "future token" and "redeem." I do agree with Shaun though, it probably doesn't matter as long as you communicate it effectively and are consistent.
Searching “Futures” implementations in other languages, I couldn’t find a standard set of terms. Some even used the generic and non-evocative “Get” for the part where one waits for a future to become an actual thing. So I’ll stick with redeeming my tokens. Thanks.
-
Does anyone else use “Futures”-like features in their code? If so, a question about terminology. Four years after this conversation “Future Tokens” are a significant part my reuse code (“Messenger Library”) and I use them often for handling multiple “actor” loops as arrays. I was just reading the docs for the Akka actor extension for Java and Scala and they use slightly terminology for their equivalent feature. They “await” a “future”, while I “redeem” a "future token”. Which is better or more intuitive?
I like “token” because this is a physical thing that represents something else (a message) that has yet to exist. But I like “await” because it stresses the fact that we block until the message actually arrives.
-
Yep. Right-click on Combo box (inside cluster) and Create>>Property Node>>Strings[]
-
I just tried it and I had no problem making property nodes for a combo box inside a cluster.
-
The lock will be being caused by something else than the code being blocked, so you should post the rest of your code. Are you properly closing the “SQLite Connection” when finished with it? Leaving a transaction uncommitted? A Prepared Statement unreleased?
BTW, you don’t need the BEGIN/COMMIT VIs in that code, as it’s only one SQL statement.
-
All the functionality is in those two poly VIs (personally, I’d prefer a more spread-out pallet). There are a few examples installed with the package.
-
I’ve been doing Approach #1. I haven’t encountered the problem you mentioned, though.
-
2009 is what OpenG is currently in, I think, so recursion should work.
-
-
But I have direct recursion, not via VI Server, in packages in 2011 (example: Shortcut Menu from Cluster), and, at least in LVOOP classes, I had recursive calls in LabVIEW 8.6. OpenG uses VI Server because it was written well before that.
-
Does it require 2012? I thought recursion worked well before that.
-
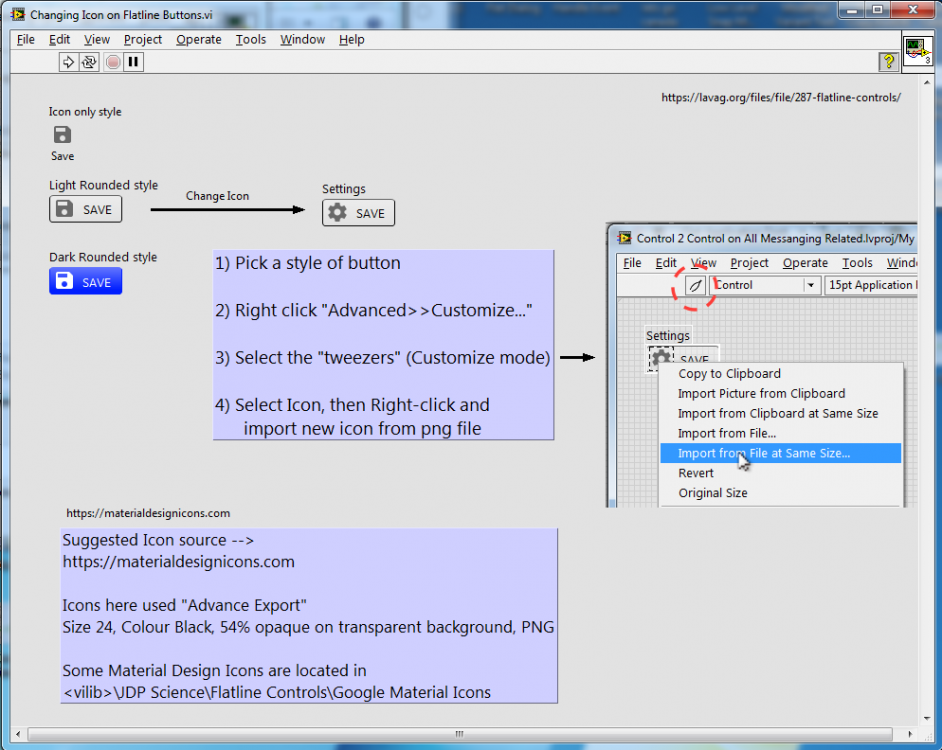
The latest version contains an example, "Changing Icon on Flatline Button.vi” which contains instructions on how to substitute your own icons into the provided icon buttons (which all start with a “save” icon). I did this, rather than provide a suite of ready-made buttons, because there are just too many types and styles of icons.
-
 1
1
-
-
I’ve been working on a wrapper for libpq.dll, which theoretically could be made to work on Linux by just using a libpq.so file, but I have only tried Windows so far.
-
20 hours ago, smithd said:
The real reason I'm posting is just to bump and see how jsontext is coming. It looks like you're still pretty actively working on it on bitbucket...do you feel more confident about it, or would you still call it "VERY untested"? I'd love to try it out for real when you get closer to, shall we say a 'beta' release?
Also, from what I could tell there isn't a license file in the code. Are you planning on licensing it any differently from your other libraries, or you just never got around to putting in a file?
I’ll call this beta if you want to give it a try:
jdp_science_jsontext-0.2.0.9.vip
BSD license.
-
1
-
-
13 hours ago, smithd said:
Using them for current project, and they really de-labview the user interface
")
I find the biggest improvement with Flat design is in the simplest of front panels. Here's a dialog box:
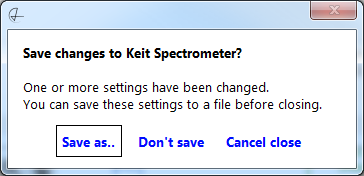
Here I just used link-style buttons (the square around "Save as.." is placed by LabVIEW as it is bound to the Enter key). I eliminated the window tittle normally on the window frame, and instead placed that text in bold. This makes a very clear, uncluttered dialog box.
-
1
-
-
6 hours ago, Neko said:
Is there any way to change the ON color of a Dark-colour Button?
Do you know how to Customise controls?
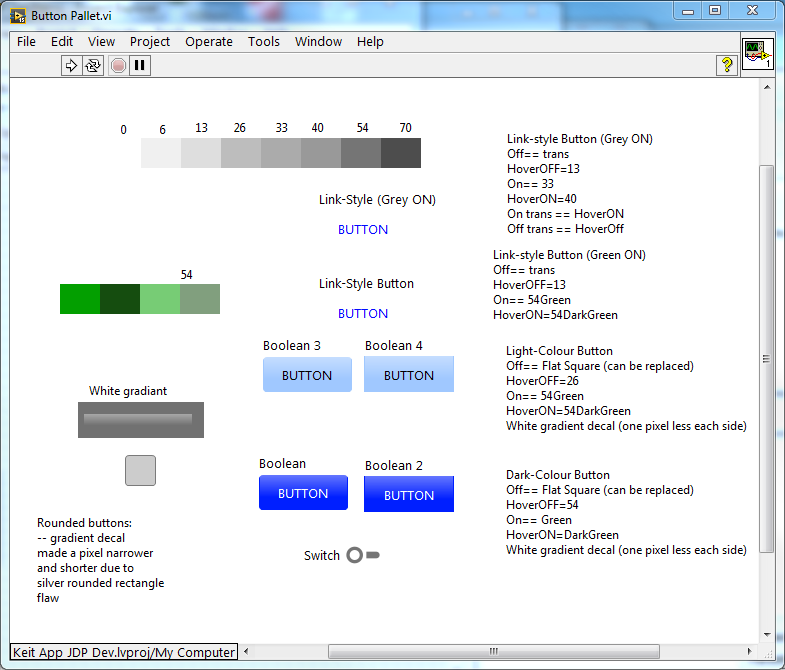
To get mouse-hover effects, I based these buttons on the System controls, which do not support different colours for ON/OFF states. So I instead made the ON state a 4x4 pixel PNG (like the hover states). If you install Bitman from the LAVA-CR, you can use the utility I used to make these PNGs:
<LabVIEW>\vi.lib\drjdpowell\Flatline Controls\Utilities\Make small transparent square in PNG.vi
Set your desired colour and Alpha transparency (I use a slightly higher Alpha for the Hover states.
You can see the "pallet" of colours I used in: <LabVIEW>\vi.lib\drjdpowell\Flatline Controls\Button Pallet.vi
To actually use your new transparencies, I'm afraid you have to manually customise the control and swap in the new PNG for the old in the ON state. If you Google you can probably fine a tutorial. Once you learn it it's not that hard.
-
Here is a demo button based on Silver buttons (instead of system buttons). No hover effects, but one can colour ON and OFF state differently, which you can't with system buttons.
-
1
-
-
1 hour ago, ShaunR said:
SQlite is single writer, multiple readers as it does table level locking. If drjdpowell had followed through with the enumeration it would (or should) have been in there. The high level API in the SQLite API for LAbVIEW insulates you from the Error 5 hell and "busy" handling (when the DB is locked) that you encounter when trying simultaneous parallel writes with low level APIs. So simultaneous parallel writes is not appropriate usage.....sort of
") .
.
Oh, that enumeration. Not sure that would be on the list as only one thing can be written to a file at one time, even by TDMS. SQLite is by default ACID compliant (now that would be on the list), but one can turn that off to get asynchronous disk writes, just like TDMS. And as long as you writes are faster than your busy-handler timeout (I set that at 5 seconds, adjustable) then there are no Busy(5) errors. The issue is just write speed, where TDMS wins.
-
1 hour ago, ShaunR said:
If drjdpowell had followed through with the enumeration it would (or should) have been in there.
Sorry, what “enumeration”?
-
1 hour ago, ShaunR said:
Only with Pragma Synchronous = OFF
No, seems to work fine without that, as long as one reading, not writing.
CTRL+SHIFT+ Shortcuts sometimes not working in LabVIEW
in LabVIEW General
Posted
Thanks from me also.