

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
I keep meaning to make time to work on JSON but here’s an idea:
Instead of storing the JSON Object’s values in a Variant look-up table, store them in an array and store the index to that array in the lookup table. That might have better performance since one may be able to do some operations in-place on the array (Variant attributes always make copies, sadly). As an added advantage, one can output the JSON Object in the original order by using the array order. There would be some overhead here, as you’d have to sort the names based on the indexes to match them to the array order, but this part could be easily be optional based on a boolean input (similar to “Pretty Printâ€).
Let me think about it some more...
-
To be honest, it's a little esoteric to me right now
The basics isn’t complicated. I don’t even have a formal MVC architecture like mje and couldn’t tell you exactly what’s the “model†in my projects. The central idea is that state is held (“ownedâ€) by the component furthest down towards the actual thing that the state is about (data, as mje talked about, or hardware, as is more likely in my case). This component is the Model. UI commands flow down to this Model. UI “views†(the information shown to the User) flow up from the Model. There is a clear C —> M —> V linear chain of action.
The simplest MVC in LabVIEW is to call a write method on an object, setting it with a Front Panel control, then calling the read method periodically and writing to a local variable of the same control. For example, if set “Output Voltage†to 6V and the limit is 5V, then my control will say 5V, the actual output value, rather than 6. If an automatic safety feature kicks in a limits voltage to 1V, then my control will show 1V. My FP control, acting as a “Viewâ€, will always reflect the true state of the system, while still serving its dual role as a “Controller†element.
When I first started doing this I used to hard-code the notification mechanism, but found myself often creating brainless loops where the sole responsibility was to go translate one transport mechanism to another (convert a queue to a user event, for example). When going about this, do yourself a favor and abstract the subject/observer interface. The subject shouldn't care if the transport mechanism is a notifier, queue, user event, or some derived construct. Make the subject take an abstract class, and have the observer decide how it would best like to receive that notification. Is my observer an Actor? Fine, it will supply a concrete observer class that packages the notification into a message and shoots it off. Maybe my observer is a primitive UI loop? Fine, it will supply an observer that packages the notification into a user event. Maybe my observer is a remote object so we use a class which pushes notification over TCP/IP. You can change all this without any modification to the model or other views which already use the model.
Note: I also highly recommend abstracting away the transport method from the sender of information via a “callbackâ€-like feature. That’s a central feature of the framework I use.
-
Some sort of MVC if that helps (I don't think in those terms).
Start thinking in those terms. The Model IS the state. The Model never requests anything from the UI (View Controller). Nor is state “copied†into it. The Controller commands the Model and the Model updates the View with a copy of any state info the View requests.
-
 1
1
-
-
Would it really hurt that much to make the output look exactly like the input which is what we all kind of expect and know to be right? Relying on a specs throw away description about an unordered list seems a bit of a cop out to me and it would probably make testing much easier and simpler as you could do a straight input/output compare. It wouldn't break existing code, either. So I'm not sure what the resistance is apart from the effort required which has already been done.
I haven’t looked at the change, but I imagined that it involved building a separate array of item names. If so, that is a significant additional overhead that will reduce performance. If this ordering can be added either without significant overhead (or can be turned on optionally when needed) then I don’t really object.
Note, though, that “what we all kind of expect and know to be right†is the assumption that caused the other-language JSON implementation to be released in such a flawed and brittle state.
— James
-
The call to "Get LVOOP Name" is slow,...
Side comment: you’re using Property Nodes; relative to that, “Get LVOOP Name†is fast.
-
SQLite is the nicest solution, but if you only need a decimated graph of the full data (no zoom in for fine scale), then a quick fix is a “self-compressing arrayâ€. An example taken from a past project:
This automatically decimates the data to keep the total under a fixed size. Never allocates memory except at initialization. But you can’t zoom in; for that and other cool features you have to go with SQLite.
-
1
-
-
I wouldn’t be in favor of adding overhead to all uses of JSON Object just to support one badly broken implementation in another language. You might be able to make a child-class of JSON Object (“Ordered JSON Object�) that you could optionally use.
-
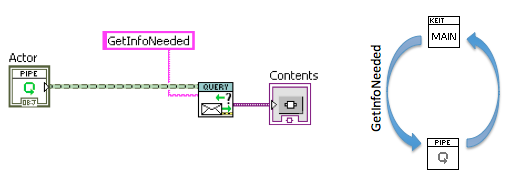
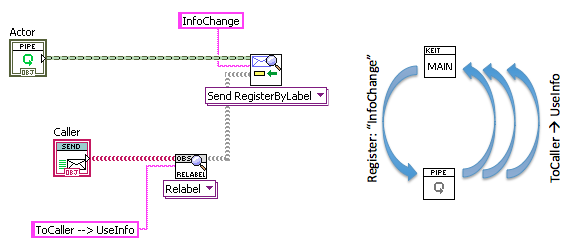
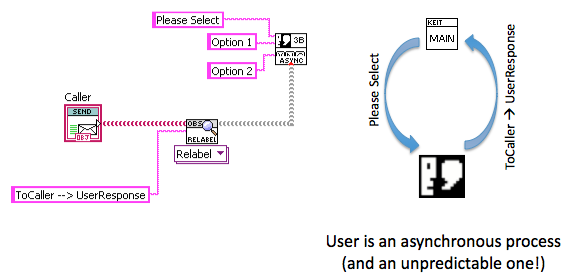
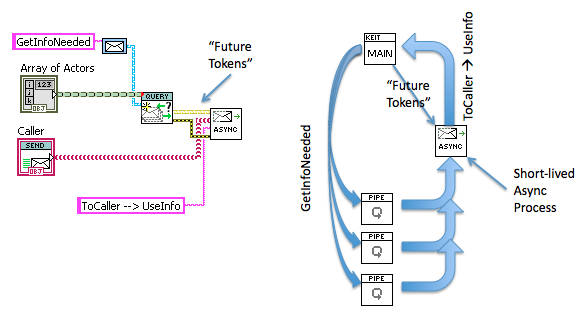
Some overheads on common messaging patterns I use from a talk I gave recently:
Synchronous Request/Reply
Asynchronous Request/Reply

Subscribe for future Notifications
Asynchronous Dialog
Asynchronous Multiple-Actor Request/Reply (aka Scatter-Gather)
-
A link to the conversation on why the AF uses the pool-of-clones ref in the way it does. Don’t change things until you know what “root loop synchronization†means. I use the same method in non-AF code and haven’t had any issues, so there must be something else involved in the library-locking problem.
-
The problem is when I recursively dive into sub clusters and convert them into arrays of variants (inside individual elements of the outer array). For example, if I am setting a cluster that matches the JSON text,
{subcluster1:{a:1,b:2},subcluster2:{c:3,d:4}}
then I will end up with an array of two Variants, each of which is an array of two Variants.
-
Question: can Xnodes be recursive? If the cluster has a sub cluster, and the corresponding variant in the array contains, not a cluster, but another array, can the Xnode recursively call itself?
-
Did you intentionally miss the case when you cluster has 2-4 elements?
No. My first test cluster had five elements, and then I went up without thinking.
-
I've made a recent entry on the Idea Exchange about this.
Here’s the VI I’m experimenting with, referred to in that link:
Array of Variants to Cluster of Variants.vi
It converts arrays (up to size 50) into clusters of variants, which can be then converted to clusters.
-
1
-
-
What can really make things odd is when "Lock panel (...) until the case for this event completes" is enabled in an event structure that doesn't run, and it receives a UI event.
Not really "odd"; that's exactly the stated and desired behaviour. The event locks the panel until it is handled. If you don't handle it, then it remains locked.
-
What is not clear and unintuitive is what happens if you place two event structures and connect them to the same FP control. This is THE rookie mistake, after all, I just wanna add another function to operate in parallel when I press that button, right?
Does that not work!?!
-
Steen’s understanding of how multiple Event structures act with a branched Event Registration matches mine. Not the most useful of behaviors, but you could use it in a “worker pool†system as long as you layer in a way of preventing duplicate handling (like passing a single-element queue in the User Event so only one process can actually get the data).
-
This package is now on the Tools Network, which required the following changes:
— Rename to “SQLite Library†(can’t use “LabVIEW†in name)
— move pallet to be under “Connectivity†rather than “drjdpowell†(and the sub pallet icons now look nicer)
-
“sub-level†VIs?
You’re going to have confusion regards, as “top level†can refer to more than one dependance hierarchy. Something started by an ACBR node is “top level†in one sense but not in another.
-
1
-
-
It works, but it involves a lot of data copying and reflection analysis.
Greg could build the compound JSON LVOOP object programmatically using other methods in the JSON LabVIEW package, rather than build a cluster and call the “Set Variant†VI that requires most of the data copying.
-
As I understand it, LVOOP objects are extensions of by-val clusters, not refnums. There is no create nor destroy action and no meaning to “Not and Objectâ€; there is always a valid object. If the objects class contains a refnum of something as an element (a Queue, say), then that will be uncreated by default, and you can write a class method that tests that refnum, but that is not the same as “Not an Objectâ€.
-
Sharing a single reference would solve this particular problem. It would also add more messaging overhead. The process that closes the reference would have to notify the other processes and wait for acknowledges before it could safely close the reference. Otherwise another process could attempt to access the TDMS file with a bad reference.
One of the reasons I chose to use the TDMS file format was its out-of-the box support for concurrent access. Perhaps properties writes don't work the same way as data writes do (as you hypothesize hooovahh)...

You could solve this with custom Open and Close VIs that maintain a single TDMS reference, and a running count of the number of processes that have called “Openâ€. Count up for Open and down for Closed, closing the file when the count gets to zero. One could also use a named single-element queue to hold the file, as named queues have similar “count-the-number-of-opens†properties.
-
Here's an improved example. The server is now a single VI, while the client registers two command-pattern envelopes, one for published "data" and one for the servers "shutdown" notification. Each command requires one class with one method.
-
1
-
-
That is only half the truth. For an unitialized object reference you are right but for an object reference that has been created and then destroyed the actual refnum value is not null but still not valid anymore!
I’m not familiar with by-ref GOOP, but I imagine GOOP objects wrap a reference of some kind (DVR?). So you are right, one needs to consider stale refnums. However, there’s a difference between something that might be called “null†versus something that is “invalid". An “abstract†parent object might indicate a no-op, while a destroyed object might indicate an error condition. I forget what the OP was requesting.
-
No.
That's annoying. I understand the reasoning of not letting the called code know access the subpanel ref... because I want the opposite; I don't want the calling code to access the VI ref. I have "actors" for which the actual VI that defines their UI should be private to the actor. I send "Insert yourself in this subpanel messages" and I need a way to get myself out of any previous subpanel I've been insert in.
Thanks,
-- James
[CR] SQLite Library
in Code Repository (Certified)
Posted
I apologize to users of this library. When NI made me rename the library to “SQLite Library†from “SQLite LabVIEWâ€, I inadvertently allowed VIPM to rename the root directory accordingly, so this might cause your minor conflict headaches when opening old projects. Sorry.