

drjdpowell
-
Posts
1,986 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by drjdpowell
-
-
C'mon guys, throw me a bone. Did anyone at least get it to run?
-
Your images show neither the creation, destruction, nor actual use of your DVRs, so it's hard to be of any help.
As far as I know, a DVR is valid until no VI makes use of it anymore.Like other LabVIEW references, the DVR will be tied to the VI hierarchy that created it, and will be destroyed if that hierarchy goes idle. However, unless the OP is using dynamic launching of asynchronous VIs, there will only be one hierarchy, so that wont be an issue.
-
As I have said already. They behave exactly like queues which is why you cannot have multiple dequeuers (Event Handler Structures) attached to the same registration just as you cannot have multiple dequeuers for a queue without unpredictable and unwanted results.
Multiple dequeuers on a Queue are predictable; one and only one dequeuer will get each element. This can be wanted if what you want is a worker pool. But multiple Event Structures drawing from the same Event Registration is unpredictable, because at least one, but possible multiple, of the structures will receive the event. This is always unwanted behaviour, so one cannot do a worker pool with User Events.
-
Not really. You can only have one dequeue as dequeue destroys the element (readers and dequeue confusion here) and sure you can "peek" the queue, but that does not destroy the element. So having "multiple dequeuers pulling out of the same queue" is unpredictable and results in unwanted behaviour on the most part. In fact. It is a common bug by rookies. This is encapsulated by the axiom that queues are "many-to-one" and if you keep to that, you will be fine..
I think Jack is referring to a 1-to-N "Worker Pool", where one desires one (and only one) worker to handle each task. This is simple with a Queue but can't be done with User Events. You're talking about a 1-to-N multicast, where every receiver gets a copy. This is easy with User Events but requires an array of queues to work with Queues.
-- James
-
Why was it only a problem in an EXE? That should be a problem in the IDE also.
-
But, could it be possible that the three subpanel VIs that are not in the subpanel control are unable to react to the user events, and hence have an ever-increasing queue stack?
I doubt it, but a good debug mode is to have all your subUI VIs open their front panels instead of inserting them selectively in the subpanel. Try that and see if that makes to memory issue go away (and check that all are functioning and not blocked when they are "closed").
-
I your app working normally while this memory is building up? If one of your components' event loop were somehow paused (by something that happens only in an exe) then User events would build up as observed.
-
Any comments on this? Too complicated? Too simple?
-
Is there a possibility to have 4 prepared Statements?
You can use lots of them; I often prepare several statements once just after I open the database connection.
-
It can likely reduce mistakes many new programmers make, and for the advanced programmer I don't see it imposing any real restriction-- to the contrary I see it promoting good practice.
But does it leave a path of easy steps for new programmers to learn? If you can only use technique X if you also use techniques Y and Z too, then you’ve introduced a high all-or-nothing step in the learning curve.
-
I can do without extra event structures as long as we get an event structure that we can wire TCPIP,UDP, Bluetooth and VISA refnums to.
Here’s the long neglected Idea Exchange entry for that very worthy idea.
-
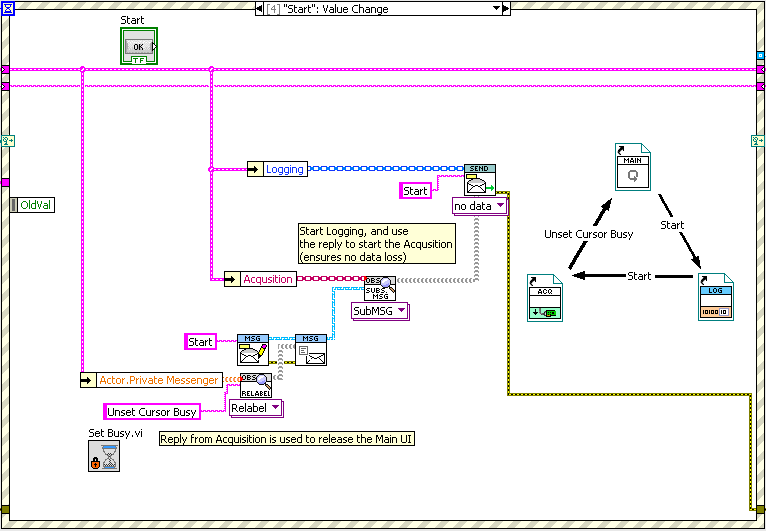
In particular, is code like this (the most complicated interaction, I think) understandable without heavy documentation? It’s a “Start Logger, then Start Acquisition, then Unset the Busy Cursor” three-actor chain message:
An alternate is below, using synchronous “queries”, where the subVI waits for the remote actor to reply to the command (we don’t care about the contents of the reply, just it’s existence).
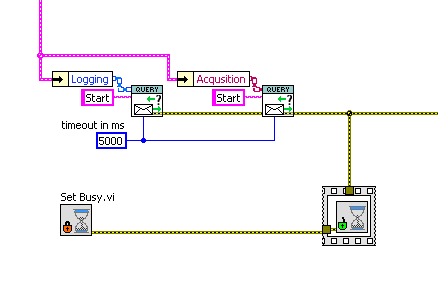
This seems a lot clearer. It’s disadvantage is that the Main message-handling loop is blocked while the two subActors start up, but in this case that is no problem, as we are preventing the User from doing anything anyway with the Busy Cursor.
-
I’m hoping to add some sample projects to my “Messenging” package, and I thought it would be easy and instructive to rework one of NI’s templates, “Continuous Measurement and Logging”, as it is already somewhat actor-like with three communicating modules. Attached is a (back-saved for 2011) copy of the NI project, with my version included (run “Main.vi” for the original, “Main.lvclass:Actor.vi” for my version).
I kept the basic functionality the same, but couldn’t resist changing some of the UI (in the old code, “Main” controls the UI; in the new code, published state messages from the Acquisition and Logging Actors set the UI).
Continuous Measurment and Logging with Messenging.zip
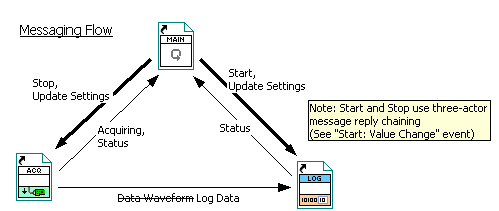
Any comments appreciated. Is this example less clear than the NI original? Why? How could I improve it?
In particular, is code like this (the most complicated interaction, I think) understandable without heavy documentation? It’s a “Start Logger, then Start Acquisition, then Unset the Busy Cursor” three-actor chain message:
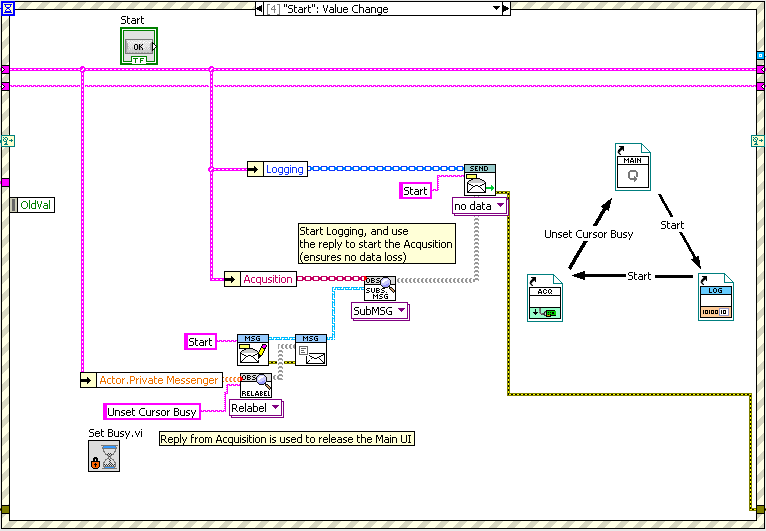
I’m thinking of making a “Send Chain Message” subVI (that accepts arrays of addresses and message labels) to replace the above code.
— James
-
 1
1
-
-
Though recently all my multiple event structures have been in separate VIs (often with front panels assembled via subpanels), I don’t see any reason why multiple ES shouldn’t be on one block diagram. And I certainly had such on multiple occasions in the past.
-
I make a project that holds EVERYTHING that references the classes involved and then rename classes and move things about in the Files tab. Once the set of things referencing it becomes too big, or I have it in a reuse VI package form, then I’m stuck with Darren’s solution.
— James
-
ØMQ is on my radar, and a few other's (we can talk about it offline, but I'm not ready to endorse it publicly). I can say, I'm eyeballing ØMQ as a particularly intriguing solution for actor-oriented design (and generally, distributed messaging) both in LV and between LV and the rest of the world.
I looked into zeroMQ with the idea of using for actors, but I couldn’t really identify how it would work for me better than just using TCP connections. ZeroMQ has many communication patterns, but none really matched up to what I need in an “Actor’s address”.
-
For anyone using this package, I’ve uploaded the latest version (should really have updated this more than once a year). I’d like comment on the following new features:
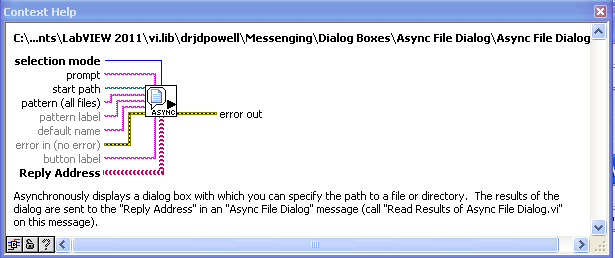
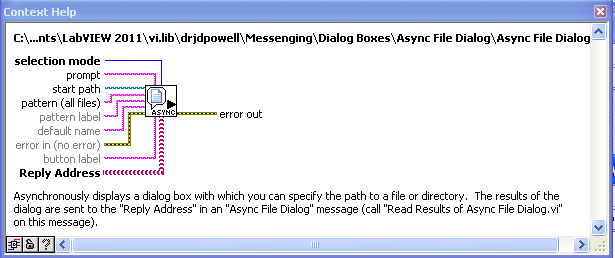
This is one of three asynchronous dialog boxes.
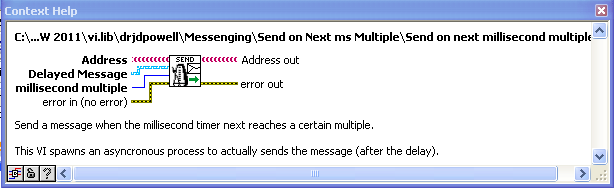
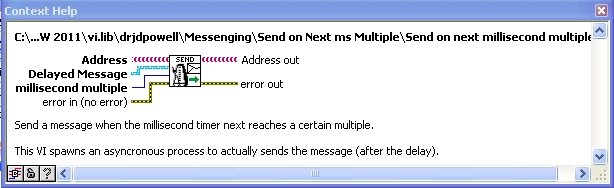
This can be used in a “delayed message to oneself” form of doing a continuously updating process (as opposed to using the “Metronome” helper actor or the (ill advised) timeout case).
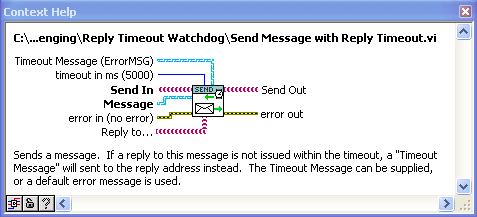
Intended for when the reply is uncertain. With this VI, a process can be confident that it will get a message of some kind back, and thus does not wait forever.
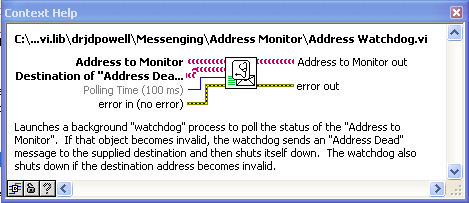
Observes an address and triggers a response if that address goes invalid.
-
2
-
-
I had original made similar probes using an Xcontrol, with the idea that display customization would then be easy (and clean, using right-click menus). But after a lot of head banging I abandoned Xcontrols as unsuitable (lossy if asynchronous; too slow if synchronous) and wrote this package in an afternoon. They are, thus, very 1.0. Haven’t felt much need for a pause option, as I can always just select a different probe for that, and I use these probes in debugging communication between parallel processes; pausing one process while the others continue can be unhelpful.
Adding a “pause the probe” option is very easy, though, and I see that Saphir’s probe has this option (labelled “Freeze display”). I’ll consider that for the next release. Thanks.
-
As an aside, there is also LabbitMQ, a LabVIEW interface to RabbitMQ, to consider.
-
Cyclic Table Probes
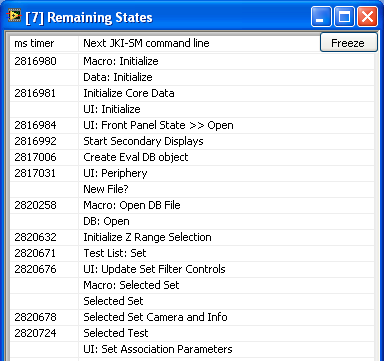
A package for creating custom probes with "history"; showing the last N values rather than just the latest. Values are displayed in a cyclic table, which wraps around automatically when it reaches the bottom of the display window. Developed to support messaging systems, where messages can be handled too quickly for the eye to see with a last-value probe. Included are some standard probes, for strings, variants, objects, and some numerics. Also included is a "Text Variant" probe, for messaging using a cluster of such, and a "JKI State Queue" probe for use in designs using the JKI "state machine" template (see image). But the expected use case is for very easily creating custom probes for whatever messages one is using (just modify one of the included probes).
Also includes "Quick Timer" probes to rapidly time execution of portions of code to accuracies of as low as 10 microseconds.
Now hosted on the LabVIEW Tools Network.
JDP Science Tools group on NI.com.
Requires VIPM 2017 or later for install.
-
Submitter
-
Submitted11/16/2013
-
Category
-
LabVIEW Version2013
-
License TypeBSD (Most common)
-
-
Try adding a method to your child classes. That seems to make them stay under “Dependancies>>items in memory”.
-
Anyone get a chance to test the new modifications on a system experiencing 1097 errors? I’ve encountered no issues with the new package, so I’ll release it to the CR soon.
-
I like to think about PID in terms of real units (maybe you do this already too). The Proportional gain is the ratio between a change in input and the corresponding change in output. The integral and derivative times likewise have real meanings - they're not just numbers. You likely know this already, but I'm always surprised at the number of people who have trouble explaining PID because they don't think about the physical meaning of the gains. I found that PID tuning suddenly made more sense to me when I started thinking about it the gains corresponding directly to units in the process, and it doesn't require a detailed mathematical model.
I like to go a step further and try and represent things graphically. For temperature control I plot the "Proportional Band”, the range of temperatures where the heater output would be between zero and 100%, on the same graph as the process variable. Tuning is still by intuition, but with more visual information to go on. You can see the effects of the PID parameters in the twists of the proportional band.
-
Your device likely only has one ADC, with a multiplexed input, that can do 200kS/sec in total on all channels, or 200/16=12.5 kS/sec on each of 16 channelschannel.
The nightmare that is renaming a class and its folder
in Object-Oriented Programming
Posted
I just rename them and let the SCC record the old class as deleted and the new one created.