Kevin P
-
Posts
63 -
Joined
-
Last visited
Kevin P's Achievements
")



-
OpenG "Periodic Trigger" function -- off-by-one bug?!?
Kevin P replied to Kevin P's topic in OpenG General Discussions
Fair question. Reasons are probably mainly habit and history, not a careful evaluation and decision. Habit - having been a long-time DAQ user, I've studiously avoided the DAQ express vi's b/c they were rarely suitable, often inefficient, and always opaque. Once in the habit of avoiding *those* express vi's, I've tended to avoid all other express vi's as well. The only exception has been the neighboring floating point 'Time Delay' express vi. History - for a long time the floating point time functions were quantized at about 16 msec resolution on Windows machines. I guess that maybe changed around the time of Windows 7? I had built up a history of not relying on on built-in floating point time when I wanted msec-level precision in my timestamps. When I found the issue, I made up a function that behaves like "Periodic Trigger" but which is based on the newly-exposed "High Resolution Relative Seconds". Not sure I can argue that the extra resolution is really necessary, but given the choice I'd rather have more than less. I just ran a quick test of the native express vi "Elapsed Timer" and I'll be durned if it doesn't seem to exhibit the same high precision. I may well switch over and use it all the time, once I kick the tires a bit more to make sure it doesn't carry too much cpu overhead. Thanks for the nudge. -Kevin P -
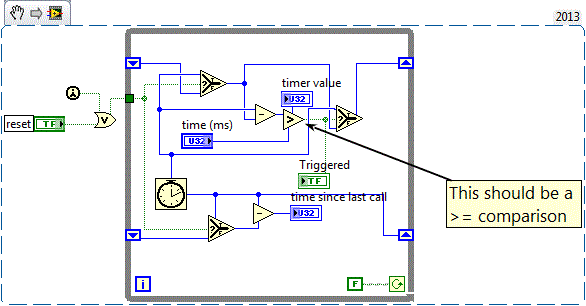
Attached is a simple test vi. Whatever value N you enter for "period (ms)", the "Triggered" boolean will actually fire with a period of N+1 msec. Looking over the block diagram of the function, it appears to me that the ">" comparison should instead be ">=". I expected to find some prior discussion about this, but was surprised to find nothing. Another screenshot is attached to show my comments on the OpenG block diagram. -Kevin P openg periodic trigger off-by-one demo.vi

-
Yeah it's an old thread, but having just stumbled across it, it's new to me. And the vi access arbitration issue is one I ran into but found a workaround for. I solved a similar latency timing issue related to FGV access arbitration on an RT system by making the FGV reentrant. Well not *only* by making the FGV reentrant, then it wouldn't be a FGV any more. Internally, I changed the data storage mechanism to be a single-element queue with a hardcoded name so every reentrant instance would get a unique reference to the single shared queue. The queue refnum was stored directly in the FGV on first access. All requests to write would dequeue first, thus blocking any parallel attempts to access the queue by other "FGV" instances. The reason this was a win is that the access arbitration mechanism for queues is very low latency, unlike the (apparent) arbitration mechanism for subvi access. Oh wait, one other detail. As I recall, it wasn't standard subvi access arbitration that was the problem, it was stuff related to arbitrating a priority inversion when a time critical loop wanted access to the FGV at an instant when a lower priority process was executing it. That particular mechanism would add a distinct spike to our main loop execution time during the occasional cycles where the collision occurred, the spike being several times larger than our nominal execution time. After making the "FGV" reentrant but with all instances accessing the same queue, voila! No more timing spikes! The other nice thing about this particular workaround was that none of the source code for the dozens of modules that accessed the FGV had to be modified. Our platform was a standard RT-capable PC rather than cRIO, and this was under LV 2010. Not sure the workaround applies to cRIO, but wanted to share an approach that might be worth a try for anyone else who stumbles onto the thread in the future. -Kevin P
-
Thanks for the replies guys. It sounds like I may in fact need to distribute both the .lvlib (or .lvclass) file which I understand to be just an XML description and also distribute all the source files for the code that is part of the library (or class). To hide implementation details would then require me to password-protect the diagrams, right? I had been resisting this approach because of config management and version control considerations. It's much easier to verify the version of a single monolithic executable than to verify a whole folder hierarchy of code. But it sounds like it may be time to bite the bullet and use the approach you describe. I haven't played with LVOOP yet and have only dabbled a little bit many years ago in text language world. Rightly or wrongly I have this idea in my head that OOP is mostly useful when there's a need to create multiple object instances with unique state variables. In my current app I won't be doing that. Executing one of my homebrew script instructions simply uses VI server and call-by-reference to call a stateless *function*. To me, my app doesn't feel like the kind of thing that would obviously benefit from classes, at least not in the sense of overall architecture. Given that, is there still an advantage to making this a class rather than an lvlib project library? Or if I first do it as a library where I won't be distracted or thrown off by the OOP terminology, should it be fairly straightforward to convert the library to a class in the future? -Kevin P
-
I'm coming late to the party on the lvlib project library and am struggling a bit to figure out whether they can be the magic bullet to solve a particular problem of mine. What I've done so far: I've got a plugin-like architecture which implements a small homebrew scripting language. Each implemented instruction is placed on disk according to a convention of "<base instruction path>\Instruction\Instruction.vi" and all supporting subvi's for "Instruction.vi" are found in or under it's folder. At run time, these vi's are found and enumerated as the set of available scripting instructions. Later, a text script will be parsed and its tokens are compared against these instructions to determine what code to call dynamically. This is how I handle all of what I call the "built-in" instruction set. However, I then took a shortcut to ease version control and made sure that all these built-in instructions are contained inside the built executable. I still call them dynamically, but they reside inside the exe. In addition to these built-in instructions, dynamic plugin instructions can also be defined and placed under a special <plugins> folder. Here one can place newly invented scripting instructions that are found and run by the executable without recompiling. All this stuff works such as it is. What I'd like: I've always kinda wished I could *also* use the <plugins> folder as a way to REDEFINE an existing built-in instruction as a means for quick bug-fixing or feature-extension. However, the namespacing issue has prevented this since any attempt to load a plugin at "<plugins>\Instruction\Instruction.vi" will in fact load up the already-loaded "<base instruction path>\Instruction\Instruction.vi" since they ultimately both resolve as a simple "Instruction.vi" LVLIB confusion: I've finally started tinkering with the lvlib project library in hopes of making such a scheme possible. The idea would be that all built-in instructions would be part of an lvlib and would have namespacing like "InstrLib:Instruction.vi" Then I could still load in a plugin that's namespaced as a simple "Instruction.vi" without conflict. (I can handle the parsing needed to determine that the newly loaded plugin should override the statically linked instruction.) I've searched this site and ni's and have found some ways to use vi server and library references to help enumerate the library's contents. But when I look at the name properties of the "Callees[]", I find that they are not namespaced with the "InstrLib:" qualifier. I'm also beginning to question how an approach based on lvlibs would translate into a built executable. It looks like vi's from the lvlib and the lvlib itself would not be inside the executable but would be distributed as source files in a folder under the executable. In short, my brief overview idea of the lvlib made me expect it to be part of a neat and straightforward solution. Right now, it appears that it's gonna be fairly convoluted. I'm starting to think I'm better off adopting a simple convention like, "All plugins will have filenames that start with 'PLUGIN_', and then I just text-parse my way through the problem. Am I missing something? Is there a simpler way to build an executable which contains vi's that are namespaced in a lvlib and will be called dynamically? -Kevin P
-
One tiny suggestion: when I've had a need for this kind of thing, there have been 2 or 3 ways to consider handling it. 1a. (Applies to an unbuffered freq measurement task.) Use a short timeout value. On a timeout error, clear the error and report 0 freq for that software query interval. Attempts to report the instantaneous freq *right now*. In absence of pulses, 0 Hz is a reasonable estimate. 1b. (A variation of 1a for certain kinds of apps.) On a timeout error, clear the error and report the most recent successfully-measured freq, which you could store in a shift register. Reports the freq of the most recently observed actual pulse. 2a. (Applies to a buffered freq measurement task with continuous sampling.) More complicated, but has its uses. Sometimes I want to do some averaging or trending across the most recent N freq measurements. I configure the task so that the Read call returns the N most recent samples. If there are no new ones from one loop iteration to the next, I'll end up reporting the same old (stale) average. 2b. (A variation of 2a.) I may choose to query the task for the TotalSamplesAcquired on each pass through the loop. Then I can do different stuff if I notice that value remaining constant over several iterations. In rare cases, I may even combine that total with a query for the software msec tick count as a cruder measure of recent average pulse rate. It can help as a sanity check sometimes. -Kevin P.
-
I've never used cDAQ devices, but based on knowledge of sync'ing tasks across PCI boards and such it looks very reasonable. Really only 2 minor comments: 1. I don't "get" the use of an internal 20 MHz clock as a trigger. Not clear to me what it buys you. But maybe that's a cDAQ thing... 2. If you ever request an AI sample rate that can't be generated exactly by your cDAQ device, I'm not sure if your property node query will work correctly when you query before reserving / committing / starting the task. I had a past experience where a similar query returned the exact same value I requested if I queried it before starting the task, but returned the true physically possible nearby value if I queried after starting the task. That was many versions of DAQmx ago though, so not sure if still relevant. Try putting in a task control vi after the trigger config and before the start. Set it to reserve or commit the task. Do a second query of the SampClkRate here. Then do a 3rd query after the start. See if the 3 show any discrepancies as you try various not-quite-possible AI sample rates. -Kevin P.
-
For the controller I had, it would have cost $1000 for 1GB of memory from NI. I carefully researched the memory's specs (available with some digging on NI's site) and bought from Crucial. Worked out just fine. -Kevin P.
-
Stop 2 parallels do loops while
Kevin P replied to scls19fr's topic in Application Design & Architecture
QUOTE (mross @ Apr 8 2008, 02:04 PM) Mike, I've put together code before with at least 3 independent While loops that each reacted to a single "Stop" button event. One mouse click always stopped all the loops. Every event structure that is "registered" to react to a particular event will have the event delivered to its queue. I generally only use this technique for quick prototype stuff since it seems to be a frowned-upon style, but it has always worked out fine in my experience. One little tidbit for those inclined to try it out: do *not* use the value from the button's terminal. Only read from the "NewVal" event property on the left side of the event structure. Reading from the terminal can subject you to a race condition. -Kevin P. -
How to avoid stopping and restarting my VI
Kevin P replied to mcguirpa's topic in Application Design & Architecture
If I understand you right, there *is* a more elegant method that's pretty simple. Simply use computed indices to determine which array element to increment. Supposing you wanted to locate within a 5mm x 5mm x 5mm cube, you'd simply divide the actual x,y,z location by 5 mm to produce integer (i,j,k) indices that range from 0 to 19. Then extract the (i,j,k) element, increment the value, and use "Replace Array Subset" to put it back in the (i,j,k) location. Sorry, don't have LV near my network PC or I'd post a screenshot to illustrate. -Kevin P. -
I used to use the "Run VI" method as my primary way to launch background code, and my older efforts would occasionally rely on the "Abort VI" method to kill one that was found to be still running at a time it shouldn't be. As I've re-used and refactored some of that stuff, I've started using other architectures for my background code. There is still usually a "Run VI" up at the top that launches it, but the code itself is more of a queued state machine. Internally, it has its own rules for state transitions, but it can additionally be sent action messages asynchronously from the foreground code. One of those is a preemptive "Shutdown" message which will shutdown cleanly. Each background process is accompanied by a statically-linked "Action Engine" which provides actions for "init", "shutdown", and whatever else is needed. If the foreground code calls it with a "shutdown" action, the action engine can verify successful shutdown before returning. Recap: "Abort VI" can have ugly side effects. Sometimes background code needs to be halted gracefully, but immediately. Thus it needs to be structured such that it is continually looking for such requests. Using queues is helpful because they have the nice property of allowing you to forcibly budge and put your message at the front of the line. This can be important if you need to perform a pre-emptive but graceful shutdown. Caveat: I still find aspects of my implementation to be cumbersome. I suspect there are some more elegant approaches, and I'd like to hear about them. -Kevin P.
-
Looking for reasonably elegant solution. Will be acquiring multiple channels from data acq boards at same rate (shared clock). Would like to perform software lowpass filtering on each channel, but do not know # of channels at design time. Will be processing data continuously and cannot accept the transient effect of using the 'init = True' input on every call to the filter function. Will need to use the reentrancy of the filter vi's so that each channel uses its own instance and maintains state between calls. So, the problem is that there's a simple and elegant approach (of auto-indexing the 2D array on a For Loop to extract the channels, then feeding the 1D rows to a filter vi inside the loop) that happens not to work right. I need a separate instance of the filter vi for each channel, but won't know how many I need to instantiate until run time. My working plan is that on the first call to my 2D array processing routine, I would auto-index the 2D array and use VI Server to open refnums to the reentrant 1D filter function, 1 refnum per data acq channel. On subsequent calls, the array of refnums could be autoindexed with the 2D array to keep specific channels synced with their filter instance. (Note: # of channels can't change *within* a test run). It feels pretty clunky though, and I'll also have to add some further auxiliary code to deal with cleanup operations like closing the refs. Any better, more elegant approaches than this? Any obvious problems with my working plan, if nothing better comes around? Would this be a good use case for LVOOP? If so, maybe this will serve as an incentive to check it out, but I doubt I've got enough learning curve time available for immediate use. -Kevin P.
-
Aristos: Simple question but I'm offsite and will likely forget to check this out for myself later. If my memory serves me, it appears that the 1D subarray taken from the 2D array is a ROW, whose elements would be stored in consecutive memory locations. Would there be a buffer allocation and data copy when extracting a 1D COLUMN from the 2D array, since those elements would NOT be in consecutive memory locations? In AI data acq, I'm much more likely to extract column-wise than row-wise since each column represents multiple samples from an individual channel. bbean: I'm interested in memory / performance tradeoffs of waveforms vs. arrays as well. I learned NI data acq before the waveform datatype was invented. When it came out, it looked to me like an overture to new users who might have trouble handling the relationship between sample rate and elapsed time. As with many other "innovations" that seemed to be aimed at new users, I've treated the critters with an abiding suspicion. I almost always read my data acq channels as arrays. No biggie b/c I learned that way. I also tend to do a fair amount of somewhat-oddball counter stuff that makes the waveform unsuitable anyway. But over the years, more and more of the analysis and signal processing vi's seem to demand waveform inputs. I feel a bit like I'm being squeezed in a "resistance is futile" kind of way. So to echo the question, what's the real dirt on waveforms anyway? What are the considerations for when they can cause a performance hit? If I have a data array whose wire terminates where I bundle it into a waveform, will the waveform simply take ownership of the array pointer? What kinds of things can be done in-place more readily with an array than with a waveform? Finally, a side-rant: One thing that contributes to my suspicion of NI's commitment to good, efficient code is that many of the shipped examples and vi.lib files, even many of the toolkits, have some pretty ugly block diagrams. I know that ugly doesn't *necessarily* equate to inefficient, but it demonstrates a lack of attention to detail which raises more doubts. -Kevin P.
-
Best way to pass data to a dynamic VI?
Kevin P replied to John Lokanis's topic in Application Design & Architecture
jlokanis, I would go with Option 2 as well. I must add my curiosity to that of LV_Punk -- 100's of spawings per minute? Sure seems some other approach might be called for... Meanwhile, for those discussing Option 1 based on the Set Control Value / Get Control Value paradigm. There are some indications that this approach isn't fully robust. There was a recent thread on the ni forums (over here) and in that thread I linked to an older thread where I encountered similar quirks a couple years ago. I wrestled it a while, but eventually hacked up an inelegant workaround and moved on. So, either beware, or if you can, explain what's going on so I can understand why I should *expect* the observed behavior. -Kevin P. -
Could you post the LOGGER code? -Kevin P.