
JKSH
-
Posts
497 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JKSH
-
-
My apologies, I remembered wrongly and gave you wrong code. I've fixed my previous post now.
The syntax is funny because:
- DoubleArrayBase is the struct itself.
- DoubleArray is a pointer to a pointer to a DoubleArray struct (yes, you read that right)
On 12/04/2018 at 9:46 PM, torekp said:I'm not trying to use a DLL in Labview. I'm trying to use a DLL (that Labview created) in C++.
Everything in the first half of my previous post (up to and including the first block of code) still applies to C++ code that reads array data from the DLL.
C++ code that writes array data into LabVIEW is a bit more complex. Look in your LabVIEW-generated header file again: Do you see functions called AllocateDoubleArray() and DeAllocateDoubleArray()?
// In the LabVIEW-generated header, mydll.h typedef struct { int32_t dimSizes[2]; double element[1]; } DoubleArrayBase; typedef DoubleArrayBase **DoubleArray; DoubleArray __cdecl AllocateDoubleArray (int32_t *dimSizeArr); MgErr __cdecl DeAllocateDoubleArray (DoubleArray *hdlPtr); // In your code #include "mydll.h" int main() { // Allocate and write the input array int32_t datasz[2] = {2, 3}; DoubleArray arrayIn = AllocateDoubleArray(datasz); (*arrayIn)->element[0] = 1; (*arrayIn)->element[1] = 2; (*arrayIn)->element[2] = 3; (*arrayIn)->element[3] = 11; (*arrayIn)->element[4] = 12; (*arrayIn)->element[5] = 13; // Call your function DoubleArray arrayOut; Linear_discrim_4dll(&arrayIn, &arrayOut, 2, 3); // Extract data from the output array, ASSUMING the output is 2x2 double cArray[2][2]; cArray[0][0] = (*arrayOut)->element[0]; cArray[0][1] = (*arrayOut)->element[1]; cArray[1][0] = (*arrayOut)->element[2]; cArray[1][1] = (*arrayOut)->element[3]; // Free the input array's memory DeAllocateDoubleArray(&arrayIn); // ... }
-
 1
1
-
On 11/04/2018 at 10:53 PM, torekp said:
So I created a DLL from a Labview VI that has a 2D array input (and some scalar inputs) and some 2D array outputs. Labview creates a .h file with these lines

And then it defines the 2D array arguments to my function as being of this type: "void __cdecl Linear_discrim_4dll(DoubleArray *dataObsFeat, int32_t grpAsz," etc etc. Trouble is, I have no idea how to fill out this structure so that the DLL can use it. Say for simplicity I had a 2 by 3 input called dataObsFeat with elements {1,2,3; 11,12,13}; how would I create the object with these values in C or C++ and pass it to the function? I am a total C++ noob, in case it isn't obvious.
See the memory layout of Arrays at http://zone.ni.com/reference/en-XX/help/371361P-01/lvconcepts/how_labview_stores_data_in_memory/
- dimSizes contains the sizes of 2 dimensions.
- element is the interleaved array. Even though the header suggests its size is 1, its real size is dimSizes[0] * dimsizes[1]. (This technique is called the "C Struct Hack": see https://tonywearme.wordpress.com/2011/07/26/c-struct-hack/ or https://aticleworld.com/struct-hack-in-c/)
If you create the 2-by-3 array in LabVIEW and pass it to your DLL, you can read it in C/C++like this:
void vi1(DoubleArray *array_fromLv) { double cArray[2][3]; cArray[0][0] = (*array_fromLv)->element[0]; cArray[0][1] = (*array_fromLv)->element[1]; cArray[0][2] = (*array_fromLv)->element[2]; cArray[1][0] = (*array_fromLv)->element[3]; cArray[1][1] = (*array_fromLv)->element[4]; cArray[1][2] = (*array_fromLv)->element[5]; // Do stuff... }
To pass array data from the DLL to LabVIEW, the idea is to do the opposite:void vi2(DoubleArray *array_toLv) { double cArray[2][3]; // Do stuff... (*array_toLv)->element)[0] = cArray[0][0]; (*array_toLv)->element)[1] = cArray[0][1]; (*array_toLv)->element)[2] = cArray[0][2]; (*array_toLv)->element)[3] = cArray[1][0]; (*array_toLv)->element)[4] = cArray[1][1]; (*array_toLv)->element)[5] = cArray[1][2]; }
VERY IMPORTANT: Before your DLL writes any data, you must properly allocate the memory. There are 2 ways to do this:
- Pre-allocate the array in LabVIEW, pass this array into the DLL, and let the DLL overwrite the array contents, OR
- Call LabVIEW Manager functions (http://zone.ni.com/reference/en-XX/help/371361P-01/lvexcodeconcepts/labview_manager_routines/ ) to allocate or resize the array before writing the data. These functions are poorly-documented, however.
-
16 hours ago, 0_o said:
However, the crashes didn't happen during execution and you refer to DWarns and not DAborts.
Thus, I think more in the line of memory issues from call libraries.
Can you elaborate as to the reason it happens.
... the memory is not freed till the calling vi is closed (BD closed) and that is often the stage when LV crashes.
That is the nature of memory corruption: Often, it doesn't cause a crash immediately. The crash happens later, when something else tries to use the corrupted memory.
16 hours ago, 0_o said:Analyzing a video and keeping the snapshots in an array can get LV from 50MB RAM to 380 MB in no time and this is a 32bit version (2GB max RAM). From my experience the issue is FP memory usage. Even 50MB under 1 control is an issue.
This is monitoring memory allocation. It helps you detect memory leaks, but doesn't detect memory corruption. They are different issues.
Memory leaks cause crashes by using up all of your application's memory. Memory corruptions cause crashes by scrambling your application data.
-
3 hours ago, Taylorh140 said:
Is it just me or is NI really bad at actually describing what their products do?
To be fair, I think DCAF is quite well-described at http://www.ni.com/white-paper/54370/en/ and http://sine.ni.com/nips/cds/view/p/lang/en/nid/213988
3 hours ago, Taylorh140 said:I had no Idea that DCAF even fell in the same realm of function as CVT. I thought it was some kind of generic configuration distribution tool thing.
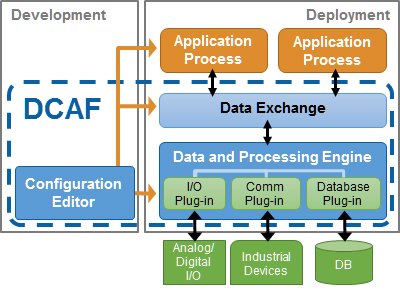
(Image from http://sine.ni.com/nips/cds/view/p/lang/en/nid/213988)
The configuration aspect just one part of DCAF, and CVT fits inside the another part: The "Data Exchange". So, I'd say that DCAF can contain CVT functionality, but CVT doesn't do most of what DCAF can do.
-
5 hours ago, ThomasGutzler said:
this might only be an issue when you work with two screens and they run on different zoom levels.
That's correct.
That also means it is an issue for me, as I have 2 screens with different scalings.

-
35 minutes ago, ThomasGutzler said:
1) Sometimes the order of the elements in the JSON string changes, which causes my conversion to fail.
2) Sometimes the "object" returned via JSON is null, which causes my conversion to fail if I use clusters within clusters. It works with variants in clusters but then I need to convert the all the variants manually
To solve both issues, insert "Adapt to Type.vi" before "Variant to Data". However, your cluster element names are now case-sensitive. "TimeStamp" will not match "timeStamp" in the JSON string.
-
1
-
-
16 hours ago, drjdpowell said:
This could easily strip comments.
If you're considering this, then the next question is: What style of comments?
- @silmaril suggested YAML, which uses "# ...".
- JavaScript (which is where JSON came from) uses "/* ... */" and "// ..."
Will you choose one to support? Will you support both (and any other style that might appear in the future)?
-
On 2/11/2018 at 7:21 PM, Ravinath said:
hye i have the arduino coding to run the servo motor.can you know how to convert it into the labview software?thanks
On 3/3/2018 at 5:33 PM, Ravinath said:can help me on this construction? i have created the serial communication in labview as below.but im not sure whether the the construction for the control pin is correct or not.by the way i want to run the g15 cube servo with gd02 rev 2.0 driver.
Please understand: All of this is a lot of work! It can take several days of full-time work to finish. It is not reasonable to expect people on this forum to do your work for free.
Someone needs to read through the data sheets. They might need to reverse-engineer the Cyton G15 shield hardware and/or code. Then, they need to make wires between the myRIO and the GD02, and make wires between the GD02 and the servo. They also need to write software for the myRIO to communicate with the GD02. Finally, they need to test everything.
You should either hire someone to teach you how to do all of this, or hire someone to do it for you.
-
2 hours ago, smithd said:
Well, I'd suggest keeping the simulation-related cfg in a separate location such that there is no way to run with simulation cfg even if everything goes bad
I agree completely: Keep the Git-tracked config files separate from the deployment config files. Trying to make Git track the files and ignore the files at the same time is messy and unintuitive; if any errors occur in the process, they might be hard to detect and to fix.
Some other possibilities to consider (these ideas aren't mutually exclusive; you can implement more than 1):
-
Have your application search for config files in a "deployment" folder first. If those aren't found, then fall back to the simulation config files.
- This way, both deployment and development machines can run the same code yet read from different folders.
- This way, the "deployment" folders are untracked by Git and there's no risk of overwriting their contents.
- Make it visually obvious when your application is running in simulation mode (e.g. change the background colour and show a label).
- Deploy by building and distributing executables instead of pulling source code.
4 hours ago, Omar Mussa said:We typically do development on our development machines where the Configuration Data Folder contains configuration files that are in simulation mode and using atypical configurations.
We also deploy our development system onto tools during development and testing by cloning the repo onto the hardware supported platforms. On these machines, the configuration data is modified to remove the simulation flag and is further configured for the specific project being developed.
When we do a pull onto the deployed systems, we definitely want all the Source Code Folder changes but we generally do not want the Configuration Data. However, we want the Configuration Data to be tracked, so we do want it to be in the/a repo.
It sounds like your deployment machines run the LabVIEW source code directly. How do you manage the risk of the code getting accidentally (or maliciously) modified by an operator?
-
Have your application search for config files in a "deployment" folder first. If those aren't found, then fall back to the simulation config files.
-
1 hour ago, Axelwlt said:
Is there a way to make a type def behave as a Strict Type Def during development (so that cosmetic changes made to the .ctl are propagated), and as a Type Def. at runtime (so that the cosmetics can be still be changed with property nodes)?
Not directly.
One possible workaround: You could keep the .ctl as a Type Def most of the time. When you want to propagate cosmetic changes during development, temporarily Save + Apply it as a Strict Type Def. After that, change it back to a Type Def.
-
1 hour ago, Labview Newbie said:
I tried using JKI state machine but it seems that it does not support my current version of Labview. By the way thank you for the reply and ill try to implement your idea! If anyone have any other methods please share them with me! (:
You can use a basic state machine instead of a JKI State Machine: http://www.ni.com/tutorial/7595/en/
-
I got an email saying that the next version of NXG is out... but nothing about 2017 SP1!
-
4 hours ago, mmitch said:
I've got a 3rd party DLL (no debug info, but know it is stable) that requires callback functions to respond to. I've gone the route of creating my own DLL to support the callbacks and relay the events to a Labview event structure. The way I have it set up is: 1) Labview calls an exported function in my DLL simply so that I can store Labview's UserEvent Reference parameter for the PostUserEvent function. It gets stored in a static variable. 2) A second exported function passes its callback function pointer up to Labview and Labview passes it to the 3rd party DLL.
(1) sounds fine.
(2) could work, with caveats. You need to make sure that the data passed between LabVIEW and the 2 DLLs don't get destroyed too early. You also need to ensure that the 3rd party DLL is happy to be called from different threads, OR you make sure you only call it from the UI thread.
4 hours ago, mmitch said:So I launch the system and things seem to work at first - my DLL actually gets called and relays data from the 3rd party DLL to a Labview Event structure. What seems to be happening: Getting a valid function pointer to 3rd party DLL, getting the event trigger in my DLL, properly calling the Labview user event structure using data allocated with Labviews native memory functions. BUT, then I get memory access crashes. So my question is, do you guys think this is because Labview is trashing (deallocating) my DLL callback function rendering the pointer invalid after a certain time?? And if so, is there a way to prevent this? And or, should I be taking a different approach and actually create a wrapper where the 3rd party DLL is called from within my DLL?
No, I don't think your callback function can be "deallocated", unless you tell LabVIEW to unload your DLL. It has a permanent address in your DLL, after all.
What kind(s) of data is transferred between the DLLs and LabVIEW?
How are you ensuring that things are thread-safe?
-
13 hours ago, rolfk said:
That is not quite true. LabVIEW for Windows 32 bit does indeed packed data structs. That is because when LabVIEW for Windows 3.1 was released, there were people wanting to run LabVIEW on computers with 4MB of memory
 , and 8MB of memory was considered a real workstation. Memory padding could make the difference between letting an application run in the limited memory available or crash! When releasing LabVIEW for Windows 95/NT memory was slightly more abundant but for compatibility reasons the packing of data structures was retained.
, and 8MB of memory was considered a real workstation. Memory padding could make the difference between letting an application run in the limited memory available or crash! When releasing LabVIEW for Windows 95/NT memory was slightly more abundant but for compatibility reasons the packing of data structures was retained.
No such thing happened for LabVIEW for Windows 64 bit and all the other LabVIEW versions such as Mac OSX and Linux 64 bit. LabVIEW on these platforms uses the default padding for these platforms, which is usually 8 byte or the elements own datasize, whatever is smaller.
TIL!
Thanks for the info, @rolfk
-
You're welcome, Fred.
I see on forums.ni.com that your code is a bit different. In particular, your Signal array has 512 elements instead of 513. Which is it? You need to count accurately, or else your program might crash.
Also, nathand posted more important points at forums.ni.com:
- You must configure the the Array to Cluster node correctly
- Each Array to Cluster node can only handle up to 256 elements. So, you need to duplicate its output to reach 512/513 elements.
-
Hi,
Your issue is related to data structure alignment and padding. See https://stackoverflow.com/questions/119123/why-isnt-sizeof-for-a-struct-equal-to-the-sum-of-sizeof-of-each-member
By default, C/C++ compilers add padding to structs to improve memory alignment. However, LabVIEW does not add padding to clusters. So, in your DLL, the structs' memory layout is probably like this:
struct Signal { uint32 nStartBit; // 4 bytes uint32 nLen; // 4 bytes double nFactor; // 8 bytes double nOffset; // 8 bytes double nMin; // 8 bytes double nMax; // 8 bytes double nValue; // 8 bytes uint64 nRawValue; // 8 bytes bool is_signed; // 1 byte char unit[11]; // 11 bytes char strName[66]; // 66 bytes char strComment[201]; // 201 bytes // 1 byte (PADDING) }; // TOTAL: 336 bytes struct Message { uint32 nSignalCount; // 4 bytes uint32 nID; // 4 bytes uint8 nExtend; // 1 byte // 3 bytes (PADDING) uint32 nSize; // 4 bytes Signal vSignals[513]; // 172368 bytes (=513*336 bytes) char strName[66]; // 66 bytes char strComment[201]; // 201 bytes // 5 bytes (PADDING) }; // TOTAL: 172656 bytes
There are two ways you can make your structs and clusters compatible:
-
If you control the DLL source code and you can compile the DLL yourself, then you can update your code to pack the structs.
- If your compiler is Visual Studio, add #pragma pack(): https://msdn.microsoft.com/en-us/library/2e70t5y1.aspx
-
If your compiler is MinGW, add __attribute__((__packed__)): https://stackoverflow.com/a/4306269/1144539
-
If you cannot compile the DLL yourself or if you don't want to change the DLL, then you can add padding to your LabVIEW clusters.
- Signal: Add 1 byte (U8) to the end of the cluster
- Message: Add 3 bytes in between nExtend and nSize. Add 5 bytes to the end of the cluster.
I must say, the Message struct is huge! (>170 KiB)-
1
-
If you control the DLL source code and you can compile the DLL yourself, then you can update your code to pack the structs.
-
6 hours ago, Tim_S said:
Eventually managed to track it down to that I'm programmatically opening a connection to a shared variable in one loop, then reading the value in a different loop (the different loops have to do with reconnecting on connection loss and startup). There is a functional global used to pass the variable to the second loop. The Read Variable primitive deallocates all but 4 bytes of memory for the previous loop handle and then allocates memory for a new handle on each iteration of the while loop, hence creating a leak. This behavior does not occur if there is only one loop where there is an open, while loop with a read, and a close.
I don't have a fix for the leak (and I haven't investigated it in detail), but I have an alternative architecture for auto-connecting comms.
Instead of opening/closing in one loop and passing the variable reference to another loop, is it feasible to keep everything in one loop using a state machine? The states could be:
- Offline (the only state that's allowed to quit the loop)
- Connecting (contains the Open Variable node)
- Online (contains the Read Variable node)
- Disconnecting (contains the Close Variable node)
Button clicks, panel close events, and read errors can be used to trigger state transitions.
-
I don't have knowledge on this topic, but I'd imagine that you can delete the existing control and add a new one. This should give you a "factory-new" control which has no custom symbols.
-
18 hours ago, ChuckBorisNorris said:
there was one Access-specific dll missing between the good and bad applications: ACEES.dll.
I copied this over from the good machine into the correct folder (C:\Program Files (x86)\Common Files\microsoft shared\OFFICE14 on my machine, it may be different for other people) and everything appears to be running smoothly.
Thanks JKSH, yatta!
P.S. How do I mark this post as solved?
Interesting. I can't think of a reason why the DLL's missing (or why reinstalling doesn't bring it back), but you're welcome and I'm glad to hear you've found a solution!
I don't think this forum supports the "mark as solution" feature.
20 hours ago, ChuckBorisNorris said:I didn't decide our company's policy on Office installations so I don't know how or why we have Access2013. Is that relevant?
It caught my attention because currently, Office 365 installs Excel 2016, Access 2016, etc. by default. I thought that perhaps reinstalling Office 365 didn't help you because your copy of Access 2013 was installed separately from Office 365.
-
On 12/4/2017 at 10:12 PM, ChuckBorisNorris said:
I've just done a complete uninstall/reinstall of Office365 and the problem still persists, just to confirm that I've tried this avenue.
A bit more info: The built application, when accessing the same database from a different machine on the same network has no issues. The error is only reported on my machine.
So the syntax is correct when sent from one PC but not the other, maybe that's a clue?
So a "good" installation of LabVIEW's DB toolkit and/or Office 365 are happy with your query. This suggests that something is different about this installation... but uninstalling/reinstalling hasn't repaired it so far.
I'm curious: You mentioned Office 365 and Access 2013. The current default version for Office 365 is Office 2016. Did you deliberately install Office 2013 via Office 365 (which requires jumping through some hoops, IIRC)? Or did you install the non-subscription version of Office 2013 separately from Office 365?
Anyway, one more thing you can try is to compare DLL versions. When the exception pop-up dialog appears, use ListDLLs or Process Explorer to see which DLLs are loaded (full paths and version numbers). Do the same on your "good" installation, and see if you can spot a difference.
-
12 hours ago, ChuckBorisNorris said:
I have tried all of the above (and without the ; as well), all give me the same error.
They give the same error code, but what about the detailed error message?
With your original query, the toolkit complained that it wasn't happy "in query expression '[UserID]'". What did it complain about in the other queries?
12 hours ago, ChuckBorisNorris said:Surely you can agree there's nothing wrong with the original syntax though, and like I said, the query functions fine in Access2013.
I do agree with you that your syntax is valid.
I was hoping that trying different syntaxes and studying the toolkit's response will yield some insight into why the toolkit is tripping up. Even though the query functions fine in Access 2013, we don't know that the Database Connectivity Toolkit passed your query as-is to Access 2013.
-
On 11/29/2017 at 6:29 PM, ChuckBorisNorris said:
I'm aware that the error code is a generic one and has multiple causes...
(Code -2147217900) NI_Database_API.lvlib:Conn Execute.vi->Untitled 1<ERR>ADO Error: 0x80040E14
Exception occured in Microsoft Access Database Engine: in query expression '[UserID]'. in NI_Database_API.lvlib:Conn Execute.vi->Untitled 1...
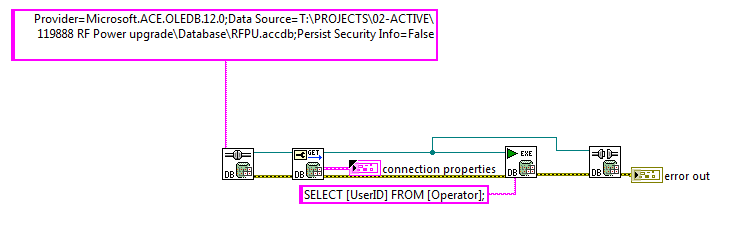
Error -2147217900 is an SQL syntax error: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000P83sSAC
Also, your error message points out that the engine doesn't like the expression '[UserID]'.
What happens if you try the following queries? What error does each query give (if any)?:
- SELECT UserID FROM [Operator];
- SELECT UserID FROM Operator;
- SELECT * FROM [Operator];
- SELECT * FROM Operator;
-
I just logged in, and I'm able to browse forums threads just fine.
Windows 10 version 1703 x64, with Microsoft Edge 40.15063.674.0
-
On 10/26/2017 at 10:12 AM, Bira said:
we have "," , ":" and ";" as delimiters.
When you break down your string into different sub-sections, the problem becomes much easier to solve. Don't try to handle 4 delimiters at the same time.
The format for the full packet is:
!<VOLTAGE_LIST>:<TIMER_LIST><CR>
The format for <VOLTAGE_LIST> is:
<VOLTAGE_PAIR[0]>;<VOLTAGE_PAIR[1]>;...;<VOLTAGE_PAIR[n-1]>
The format for <VOLTAGE_PAIR[k]> is:
<VOLTAGE1[k]>,<VOLTAGE2[k]>
The format for <TIMER_LIST> is:
<TIMER4>,<TIMER5>
Notice that:
- The full packet only has '!' at the start, ':' somewhere in the middle, and '\r' (<CR>) at the end
- <VOLTAGE_LIST> only has 1 delimiter: ';'
- <VOLTAGE_PAIR[k]> only has 1 delimiter: ','
- <TIMER_LIST> only has 1 delimiter: ','
You can translate the above breakdown into very simple LabVIEW code:
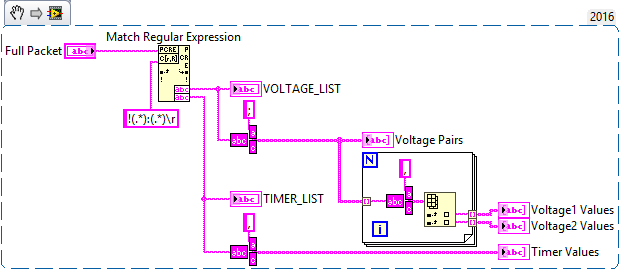
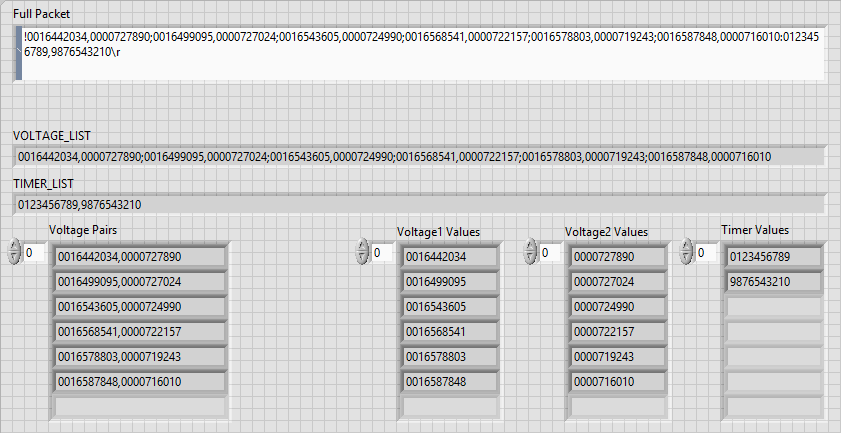
Notes:
-
The pink VI is <vi.lib>\AdvancedString\Split String.vi
- To make it appear in your palette or Quick Drop, install Hidden Gems in vi.lib from VIPM or http://sine.ni.com/nips/cds/view/p/lang/en/nid/212430
-
Alternatively, you can use OpenG's String to 1D Array.vi
- Regular Expressions (Regex) are very useful for string manipulations. Play with it at https://regexr.com/ (note: You might need to replace '\r' with '\n')
-
2
[URGENT] Database in NXG 2.0 and 2.1??!
in Database and File IO
Posted · Edited by JKSH
Cross-post: https://forums.ni.com/t5/LabVIEW/URGENT-Database-in-NXG-2-0-and-2-1/td-p/3783489
To answer your question, see the "Software Compatibility" tab at http://www.ni.com/en-au/shop/labview/compare-labview-nxg-and-labview.html