
JKSH
-
Posts
497 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JKSH
-
-
3 hours ago, hooovahh said:
You can put things in various menu bar items, like Tools, and File which can be useful for calling VIs to perform actions on the open VI.
I'm interested! Where can I find info on how to do this?
3 hours ago, hooovahh said:And there is the Project Provider Framework, which has the ability to add items to the project toolbar, but not many people do this because it can be a pain to work with, and is somewhat incomplete.
The application form sounds like this is meant for companies with a serious product. Do you know if NI accepts applications for hobby projects (or projects not ready for prime time yet)?
-
On 5/17/2016 at 10:57 PM, mwebster said:
It was the one you actually mentioned in your documentation with the dynamic GUI composition, where selecting Tab Widget, Splitter, or MDI Area causes LabVIEW to freeze when transitioning back to edit mode.
This one looks like a LabVIEW bug. I've reported it at http://forums.ni.com/t5/LabVIEW/BUG-Certain-code-paths-make-LabVIEW-deadlock-freeze-when/m-p/3299411 (I hope they won't say something like "callbacks are only meant for use with .NET...")
If you modify the example and manually create the new Growable Widget yourself (without triggering any callbacks), you can dynamically add tabs/splitters/MDIs to the top-level tab without causing the freeze.
On 5/17/2016 at 10:57 PM, mwebster said:I do agree that the learning curve would be easier to absorb into a large scale project. I guess my problem is I work on too many medium scale (1 or 2 developer) projects. The intimidating thing to me was the thought of using this for the entirety of the project, I'm much more comfortable with using a piece of it to implement something LabVIEW can't do on its own.
Agreed, using LQ Widgets to complement LabVIEW front panels is the most sensible way to start.
Regarding the learning curve in general: What are your thoughts on the "Hello World - Introduction to Widgets" example/tutorial? Was it easy to follow, and was it complete enough?
On 5/17/2016 at 10:57 PM, mwebster said:I was wondering though, can you get any events from the widgets besides the signals they emit (valueChanged, sliderPressed)? i.e. mouseover, mouse down with modifier keys, etc?
Kind of (not in LabVIEW yet). In C++, the most common way to act on these events is to override the widget's mousePressEvent method, for example. In your override, you can query the event parameters (which does include modifier keys) and run custom code. To integrate this mechanism into LabVIEW, we need to make the C++ side call your LabVIEW-defined event handling code and wait for your result before continuing. I've got an idea but haven't tried it yet.
Do you have a use case in mind? Perhaps there's an alternative solution that doesn't involve handling these events.
-
20 hours ago, pato7 said:
@JKSH Thank you for your reply. I have attached here 2014 Version files. Basically I have just created the server code and a read from file code but its still not integrated in the server code. I will try to work with CSV files and use the For loop method, Thanks for the advice. I am trying to find a way how to relate each item read to its corresponding folder and also if there's more than one item related to the same folder.
You're welcome
")
It looks like you already know how to use the OPC UA server VIs. So, what you need to do next is take the strings that you read from your file and pass them into those VIs (in a loop).
If you're new to LabVIEW programming, it's worth spending some time to learn LabVIEW properly. If your university has any LabVIEW training courses, attend them. Otherwise, see http://www.ni.com/getting-started/labview-basics/
-
@mwebster, thank you again for taking the time to test drive LQ Widgets. Very much appreciated! Thanks also for your vote of confidence. It has certainly given me the motivation to work faster
14 hours ago, mwebster said:(lots of work has obviously gone into Qt Widgets)
Indeed. Qt Widgets is very mature and stable; that's the main reason why I picked the widgets API as a starting point for this project.
The Qt Company is now pouring resources into the next-gen GUI framework; it's definitely more powerful than the widgets, but it's still evolving. I believe Qt Widgets will remain relevant for the core Qt users for many years to come.
14 hours ago, mwebster said:I really like the way you can link objects together solely through the Qt framework or through events or through callbacks. I hope I can find an excuse to use it.
Same here
14 hours ago, mwebster said:However, I have absolutely no vision of how to use this on anything outside the smallest of projects. The overhead required to do manual, programmatic layout removes one of Labview's biggest advantages ((relatively) quick GUI development).
Interesting. I was thinking the exact opposite, actually: Given the overhead involved in creating and wiring up the GUI, I thought it's an overkill for small projects. In contrast, LQ Widgets could be a good investment for large, long-term projects that need complex GUIs.
I find LabVIEW GUIs great for rapid prototyping -- we can get something up and running very very quickly. However, it's somewhat limiting, and requires me to perform gymnastics to do anything fancy (e.g. dynamically composing a dialog requires image manipulation). I'm aiming to make this API less tedious and more intuitive than those gymnastics moves.
Anyway, LabVIEW front panels and LQ Widgets can coexist happily in the same project, as you mentioned already.
14 hours ago, mwebster said:it reminds me of the Labview TestStand OI. That thing makes me cross-eyed every time I delve down into it. So many callbacks and hooks.
I think that's because TestStand OIs rely heavily on ActiveX, so you need to do the things that @ShaunR mentioned.
It's definitely a very different paradigm from LabVIEW's traditional dataflow. Having said that, GUI interactions are asynchronous, which doesn't fit neatly into the dataflow world.
14 hours ago, mwebster said:Obviously the Labview crashing thing needs to be figured out.
Did you encounter any crashes when test-driving LQ Widgets? If so, do you remember what caused them?
14 hours ago, mwebster said:We should be able to rename event wires
Yep, I've been looking for a good way to name events too (and so have many others).
The demo video above shows "casting" in action, at 3:37.
14 hours ago, mwebster said:You speak of possibly having a GUI editor in the far future. Something like the QT Creator IDE frontend that figures out how to use VI scripting to create the equivalent Labview calls? Unfortunately I feel like I would probably need something at that level before diving in headfirst.
All of that said, I do plan to keep an eye on this. Some of the capabilities of QT are really cool looking, especially in regards to themes, graphs, and accelerated 3d visualizations.
Yes, I can see how the WYSIWYG editor can lower the entry barrier. OK, I'll bump this up in my priority list. Stay tuned!
14 hours ago, mwebster said:Some of the capabilities of QT are really cool looking, especially in regards to themes, graphs, and accelerated 3d visualizations.
Mm, my mouth watered the first time I saw the 3D stuff. They used to be restricted to enterprise customers only, but in about 2 months from now they will be released to the open-source community! (GPL only, so they can't be used in proprietary apps without buying a commercial license, but still…)
3 hours ago, ShaunR said:this is, or is potentially, cross platform.
Exactly right. I'm very confident that LQ Widgets can be ported to Linux (including Linux RT CompactRIOs with Embedded UIs) with minimal effort. Not sure about OS X though.
-
 2
2
-
-
On 5/14/2016 at 2:13 AM, pato7 said:
Normally through labview we can create an OPC UA server and add folders/ Items/Properties to create the data structure. But this is done manually by adding the vi for each folder and item and connecting them. This is reasonable if we have two or three items or properties in the data structure. But if we have for example 40 items, then it would get messy. So i am thinking of a way to read the data from an excel sheet or text doc and automatically create the data structure in the OPC UA server. Offcourse, the data in the excel sheet should be arranged in a special way so that we can create the node paths easily and define the characteristics( read/write, datatype) of each node automatically. so far i was able to create the OPC UA server but I am stuck on how to transform the data from the excel file to the OPC UA server.
I can't open your VIs as I don't have LabVIEW 2015, so I can't see what you've done. However, here are some quick tips:
- CSV files are easier to parse than Excel spreadsheets: http://digital.ni.com/public.nsf/allkb/C944B961B59516208625755A005955F2
- Use a For-Loop to create your OPC UA Items: http://www.ni.com/white-paper/7588/en/ Create N rows in your CSV file, one row for each Item. Your loop should run for N iterations. Each iteration should read one row from your CSV file, and call the OPC UA Add Item VI one time (if you want to add Folders/Properties, the code will be a bit more complex)
-
3 hours ago, pato7 said:
Did I make my idea clearer now? The thing is that it's required from me to use OPC UA protocol.
Please forgive me if I've misunderstood you, but I feel that you are presenting an XY Problem here (see http://xyproblem.info/ )
To help us identify how to help you properly, please describe your project in more detail. Specifically:
- What is the name of your project? (If your project doesn't have a name, tell us the name of your unit/subject/course)
- Why are you required to use OPC UA? What does your professor want you to learn? (This really doesn't make sense to me, because OPC UA is not really designed for transferring waveforms)
- Why do you want to run the server "as fast as possible"?
On 5/13/2016 at 10:11 AM, pato7 said:My task now is to compare the two signals and make sure that the data is transfered as fast as possible so when I am sampling I wont miss any data.
Who does the sampling? The server or the client?
On 5/14/2016 at 9:24 PM, pato7 said:But since there is time difference between the two waveforms. I need to compare them in a separet VI. And should calculate the offset in order to make for that time difference and be able to compare the two signals. Comparison according to (Sampling rate, frequency, phase difference, noise)
The time difference and phase difference is mainly due to the lag in transferring the data from your server to your client, right? Are you interested in measuring that lag?
Sampling rate is only relevant when you convert a physical (real) signal to a digital signal. OPC UA only transmits digital data; it does not do any conversion.
Why do you think there will be noise or change in frequency? OPC UA transmits digital data. As long as the client doesn't lose any part of the data, the data will be received perfectly at the other side, without noise.
On 5/13/2016 at 10:11 AM, pato7 said:So I am considering the signal generated at the server is IDEAL and I'll compare the signal at the client to it. And I need to measure the %error between them.
4 hours ago, pato7 said:So may I ask if... we have two random sine waveforms generated each from a separate VI. How do we compare them in this case?
You need 3 things:
- First, you must make sure you understand the types of comparisons that you want to do. This is the theory you learn from your professor and/or your textbooks.
- Next, you must identify algorithm for performing your comparisons. There might already be an algorithm available in your textbooks, or you might need to think of one, or you might be able to ask someone who knows.
- Finally, you must write a program that uses that algorithm to perform your comparisons.
We can help you with #3 quite easily (after you finish #1 and #2), but I'm not sure if we can help you with #1.
Forget about LabVIEW programming for now. Consider these sine waves:
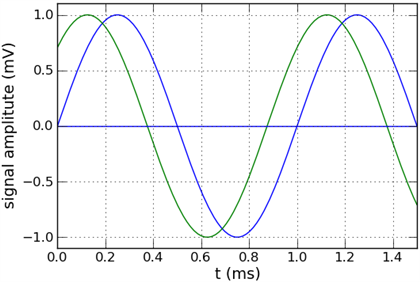
What kind of comparisons do you want to do on them? Which differences are you interested in?
-
1
-
12 hours ago, pato7 said:
@hooovahh Sorry but I believed the title of this post is "phase difference betwwen two signals" and my major question was how to measure the difference between two signals.
If you want to change the title, click "Edit".
12 hours ago, pato7 said:The idea is that its required from me to work with OPC UA labview. So regardless how fast it is , I am supposed to test its limitations and compare the results when the OPC UA server was faster or slower and try to find methods for using it in "fast as possible" mode.So for now, I need to compare the waveforms and check how much is the % error between the waveform generated at the server and the one read at the client.
But since there is time difference between the two waveforms. I need to compare them in a separet VI. And should calculate the offset in order to make for that time difference and be able to compare the two signals. Comparison according to (Sampling rate, frequency, phase difference, noise)
If you are not able to run the OPC UA VIs incase you don't have the OPC UA toolkit. My question would be the same as how to compare these two normal waveforms that are generated each in a separate VI.
I still don't fully understand what you want to do. You've said you want two things:
- Test the limitations of OPC UA
- "Compare" 2 waveforms in terms of sampling rate, frequency, phase difference, and noise.
These 2 things are completely separate. Please tell us which one is your most important goal: #1 or #2?
If I show you an easier way to test the limitations of OPC UA without using waveforms, then do you still want to know how to compare waveforms?
-
@mwebster, thanks for your kind words, and for swiftly posting your tips to help others. I'm looking forward to hearing your thoughts!
On 5/12/2016 at 0:40 AM, mwebster said:Edit:
And, obviously, you document this in the README file. Who reads README's?
I can relate
 I've added the path tidbit near the download link in my original post.
I've added the path tidbit near the download link in my original post.
-
13 minutes ago, pato7 said:
Hello Guys,
I am kindof new here, and I am trying to find some help with my project.
Hi ELias,
Your original post is already at https://lavag.org/topic/19613-phase-difference-between-two-signals/. Please continue the discussion there.
-
Hi,
I currently don't have LabVIEW 2015 so I can't open your VIs, I'm afraid.
12 hours ago, pato7 said:I created a sine signal at my OPC UA server and I am reading that signal at my OPC UA client. I plotted the signal at both , the server and at the client. My task now is to compare the two signals and make sure that the data is transfered as fast as possible so when I am sampling I wont miss any data.
Were you required to use OPC UA, or did you choose it yourself?
If you want to make sure that you don't lose any data, then I don't think OPC UA is the best solution. Have a look at lossless streaming instead: http://www.ni.com/white-paper/12267/en/
24 minutes ago, Tim_S said:OPC is great until you want to do something that requires timing of faster than, oh, 30 seconds.OLE (OPC = OLE for Process Control) runs at the lowest priority possible in Windows.
@pato7 is talking about OPC UA, which is a complete revamp and does not use OLE: http://www.ni.com/white-paper/13843/en/
-
- Popular Post
- Popular Post
Hi all,
I'd like to introduce LQ Widgets, a library to bring advanced GUI features to LabVIEW. It is powered by the Qt toolkit plus the Qwt library (Qt Widgets for Technical Applications).
This library consists of two major subcomponents that might interest LabVIEW users:
- A GUI framework that is powerful, flexible, and comprehensive (see demos below).
- A event-driven, intra-process communications framework. You can establish connections using (i) LabVIEW user events, (ii) callback VIs, or (iii) string specifications.
Here it is in action:
Why a GUI library?
The Idea Exchange has many, many posts about improving LabVIEW's GUI capabilities. However, we likely have to wait several years at least before these wishes are granted (see AristosQueue's post at http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Make-updating-the-GUI-a-priority-in-a-near-term-LabVIEW-release/idc-p/2710511#M26394).The required technologies are actually available right now. In fact, they have been available for many years. All we need is a way to access them easily from LabVIEW. LQ Widgets aims to provide this access.
Why yet another communications framework?
Providing a comms library wasn't part of my original goal. Nonetheless, the system used by the GUI components can also be used for non-GUI purposes, so it's here for you to try.Where to get it?
-
Downloadable packages:
- Package for LabVIEW 2014 (recommended; take advantage of the the new web-based documentation)
- Package for LabVIEW 2013
-
Quick start guide at https://github.com/JKSH/LQWidgets#usage. The C++ source code is also easily accessible from here, if you're interested.
- EDIT: Most importantly, you must either extract the package to C:\LQWidgets\, or modify the output of src\LabVIEW\LQ Core\_Internal\Library Path.vi (thanks, mwebster!)
Project roadmap
See http://github.com/JKSH/LQWidgets/wiki/RoadmapKnown Issues
This is a pre-alpha release, which means (i) the API will likely change in the near future, (ii) the library is far from feature-complete, (iii) performance is not optimized, and (iv) you might experience crashes. Other issues include:- You currently can't free any resources or disconnect signals, except by calling LQCoreEngine.lvclass:Stop Engine.vi
- QWinThumbnailToolButton cannot be applied to non-Qt windows, such as LabVIEW front panels
-
After you start and stop the engine, QWinThumbnailToolButton no longer emits any signals when you click on it
- Workaround: Restart LabVIEW
- There are a few small memory leaks, which will persist until you close LabVIEW.
Request for feedback
- What do you think of the GUI-related API?
- What do you think of the communications-related API?
- What is the single most promising aspect of this library?
- What is the single most frustrating aspect of this library?
All comments and critique are most welcome.
Thanks for your time!
-
7
-
Hi @Muzz, and welcome!
This page talks about the issue of font difference, and gives you a visual comparison: http://digital.ni.com/public.nsf/allkb/92A4978076B4969586257D27004C3529
I have made one embedded UI which is meant to used on both the cRIO and a PC. I simply made sure that the fonts fit on the cRIO's UI. This ensures that they will fit on the PC's UI too, because the PC produces smaller fonts.
-
1
-
-
Googling "PCAP LabVIEW" led me to http://www.ni.com/example/27660/en/
Also, https://wiki.wireshark.org/Development/LibpcapFileFormat shows you the file format (so you can implement something yourself) as well as some links to ready-made (non-LabVIEW) libraries
-
1
-
-
24 minutes ago, Mads said:
Chrome is complaining about the security of lavag.org. It has an invalid certificate (encrypted with an outdated cipher)....
Weird. I'm using Chrome (version 49.0.2623.112), and it's telling me that my connection is private. What is the supposedly outdated cipher?
-
3 hours ago, Michael Aivaliotis said:
Does it also turn off your hue lights, or make them a dark red?
It doesn't... time to file a bug report
-
8 hours ago, Yair said:
- White. So much white. I had a similar complaint with some upgrade NI had at some point. While the LAVA situation is better than the NI one was, I still feel there isn't enough contrast in the various separators and I find the white hurts my eyes. This is probably screen-dependent, and I probably would get used to it, but I am putting it out there that I would prefer a change in the colors.
If you're using Google Chrome, try this: https://chrome.google.com/webstore/detail/hacker-vision/fommidcneendjonelhhhkmoekeicedej
-
1
-
3 hours ago, ShaunR said:
The only thing I haven't figured out (yet) is how to break quotes so I can reply in sections. I used to just change it to text and then split it up inserting the markup but I can't see a text/html button in the new editor. I expect it can be done another way, just that I was using the brute force method

Huh... I never thought of using the the edit-in-text-mode technique! All along, I've copied+pasted the entire post to create a new "section", and then erased the parts not relevant to each section.
-
Looks sleek
What happened to the LavaG logo though?
-
I saw a conversation (argument) about that at some point but I don't recall the conclusion. I think there are arguments for a global install as well as a local install, depending on the tool. For example I'm assuming nobody is arguing this should be project-specific.
I believe that the "wrongness" that @odoylerules mentioned isn't so much about having a global install, but rather having packages added to C:\Program Files\ which goes against current Windows security principles.
C:\Program Files\ is a place of restricted security, mainly for an official installer to place files required to run a program, like .exes, DLLs, and official resources. User-modifiable and 3rd-party files (e.g. config files, example code, 3rd party development libraries, etc.) would ideally go into somewhere like C:\ProgramData\National Instruments\LabVIEW 2015\user.lib\
-
1.0.1 has been released with the dependency removed. You should be good to go!
Yep, works great!
The Suggestions API returns a 2D array where the first column is the incorrect word, and the other columns are the suggestions. However, the row length depends on the entry with the highest number of suggestions. This means, if the callers want to know how many suggestions there are for a particular incorrect word, they would need to manually search for empty array elements in that row. Would it make sense for the API to return an array of clusters instead? Each cluster would have 1 string (incorrect word) and 1 1D array of strings (suggestions).
-
Possibly. If one was sending a stream of JSON (including some scalar strings) then this would cause a failure. However, if some of those scalars were number, like 123.456, then there would be no way to be sure you had the full value as 12 or 123.4, etc. are valid JSON. So to guard against partial JSON one might have to require streams to use either an Object or Array.
Agreed, there's no sensible way to figure out if a raw number is complete or not, so we shouldn't even try.
I did indeed stumble upon this while experimenting with the library's ability to handle JSON streams over TCP, but I'm not planning to send raw standalone scalars.
-
That was quick!
I thought I'd give it a test drive, but the Hunspell DLLs depend on some MinGW DLLs which aren't bundled. (I tried dropping in my own version of libgcc_s_dw2-1.dll and friends, but that crashed LabVIEW)
-
No. I want a spell checker that I can use in applications on any text - not just in the LabVIEW IDE.That's very short-sighted.

Time to write a wrapper for Hunspell, I suppose

To be honest, I don't really see a spell checker fitting in with NI's core offerings, i.e. tools that enable/simplify the work of scientists and engineers. This seems more like a job for 3rd-party developers.
(Having said that, since VIA already has a built-in spell checker, it might make sense for NI to make VIA spell checker a standalone library, and let both LabVIEW and VIA link to it).
May I ask what your use-case is?
-
Hi,
I found out that Set from JSON Value.lvclass:SON String.vi doesn't seem to notice if strings are incomplete. (Currently using version 1.4.1.34)
If I input an incomplete object, e.g.
{"Hello": "Wor...the VI reports a Parse error (error code 1). This is expected.
However, if I input an incomplete string, e.g.
"Wor
...the VI doesn't report an error. What's more, the resulting JSON Value object can be passed into JSON Scalar.lvclass:Get as Text.vi which then produces a valid LabVIEW string with no complaints ("Wor").
Is it worth making the scalar parser more robust?
UTF-8 text, SVG images, inheritable GUI components, dynamically composed GUIs, layout management, splitters-in-tabs, MDIs, taskbar integration, and much more!
in User Interface
Posted · Edited by JKSH
Add workaround for bug