
JKSH
-
Posts
497 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by JKSH
-
-
46 minutes ago, Heiso said:
Assuming this fixes it, if I can't use the Set Time.vi to set the system clock, how can I synchronize multiple systems that are geographically isolated and have no common network timing source (e.g., NTP, PTP, etc.)? GPS is something that's readily available so I'd like to use that, but not if it's going to cause lockups days after I call the function a single time... Again, this is all predicated on disabling GPS fixing the issue.
I'm pretty sure remote time syncing ("remote" as in "light-years from civilization") is a core use-case.
Try asking at the Linux RT forums. Relevant NI engineers are quite active there: https://forums.ni.com/t5/NI-Linux-Real-Time-Discussions/bd-p/7111
-
On 11/30/2021 at 12:06 PM, Mahbod Morshedi said:
Unfortunately, having a tutor is out of the question, no low-level programmers at the research school of chemistry.
Does your institution have a school of computer science, software engineering, or similar? If you are allowed to, perhaps you could sit in on some of their introductory lectures.
-
 1
1
-
-
2 hours ago, Mahbod Morshedi said:
I am not a programmer (just a chemist), but I would love to develop my own experiments. So far, I have been developing with existing pieces of equipment, but I am keen to learn how to make some of them myself.
One thing to keep in mind: LabVIEW and Python are high-level languages, while C and C++ are low-level languages.
- High-level languages are easier to get started with, and they provide some protection against common errors. For example, if you use an invalid reference in LabVIEW, you get a helpful error messsage telling you where the issue is; if you use an invalid pointer in C/C++, you could get silent memory corruption.
- Low-level languages can be more powerful and efficient if you know how to use them properly. However, it does take a lot longer to learn them properly.
Whichever path you choose, the guidance of an good experienced teacher can get you further and faster then online tutorials.
-
1
-
2 hours ago, Benjamin R said:
Is there any LabVIEW or Windows function that I can call to get a brand new one
If I'm not mistaken, the Upgrade Code is simply a GUID: https://stackoverflow.com/questions/4313422/generate-guid-in-windows-with-batch-file
-
 1
1
-
-
10 hours ago, Lipko said:
Do you know/have some nice GUI designs or examples?
What's the context?
Traditionally, I've treated good desktop app design as different from good industrial HMI design as different from good web app design, etc. But, contemporary designers are moving towards a unified approach.
What are your thoughts on Google's Material Design, Microsoft's Fluent Design, or Apple's Human Interface Guidelines?
-
10 hours ago, David Boyd said:
I'm being told, "NO, it NEEDS a STOP button".
Can you say, "Here is the STOP button! The big red 'X' in the top-right corner of the window"? 😁
-
5 hours ago, Michael Aivaliotis said:
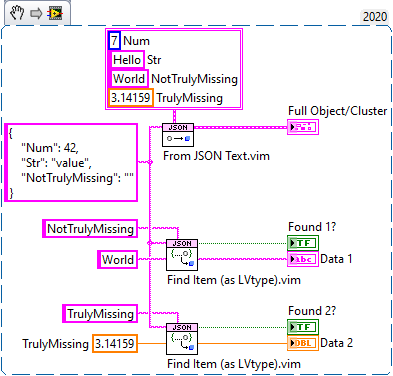
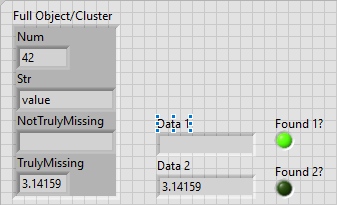
How should I handle reading JSON files where data elements are missing?
Missing as in "field does not exist in the object", or missing as in "field exists but the value is an empty string"?
- The latter is not truly missing. It exists, and its value is an empty string.
- The former can be handled using the "Data Type and Default Value" inputs
 5 hours ago, Michael Aivaliotis said:
5 hours ago, Michael Aivaliotis said:an empty string which could imply reading a non-existent JSON item.
Sounds like you're using "Find Item.vim"? Make use of the "Found" output, OR switch to "Find Item (as LVtype).vim" to specify the default value.
6 hours ago, Michael Aivaliotis said:I guess I could create custom wrappers. But I wanted to avoid the extra work for something that's common.
How do you envision providing the default value if you are able to filter out the proposed "Empty String" error?
-
8 hours ago, hooovahh said:
the work NI needs to do if LabVIEW is ever going to have official proper unicode.
The current pink wire datatype needs to remain as a "byte string" plus "locally encoded text string" to maintain backwards compatibility.
A new type of wire (Purple? Darker than pink, paler than DAQmx wires?) should be introduced as a "universal text string" datatype. Explicit conversion (with user-selectable encoding) should be done to change pink wires to purple wires and vice-versa.
- Binary nodes like "TCP Read"/"TCP Write" should only use pink wires. Purple wires not accepted.
-
Text nodes like "Read from Text File"/"Write to Text File" should ideally only use purple wires, but they need to allow pink wires too for backwards compatibility.
- VI Analyzer should flag the use of pink wires with these nodes.
- Perhaps a project-wide setting could be introduced to disable the use of pink wires for text nodes.
-
1
-
On 10/11/2021 at 1:34 AM, Michael Aivaliotis said:
is it possible to improve the error handling for empty strings? Perhaps have a special error code I can filter on if an empty string is detected?
How about wiring the string into a case structure selector?
- Case "": Do your special output
- Case Default: Wire the string into the JSON VIM
-
If you only need to read the basic standard messages defined in J1939, then you can can treat the frames like any regular CAN frame. You just need to map the frame IDs to J1939 PGNs (for example, CAN frame ID 0x0CF00401 is for "Electronic Engine Controller 1" and bytes 4-5 contain the "Engine Speed" value)
However, if you need to do do complex things like read multi-frame data or send a command and read the response, then you need to write a lot more custom code.
Fortunately, NI has provided an example that covers a big chunk of what you need with the NI-9853: https://forums.ni.com/t5/Example-Code/J1939-Transport-Protocol-Reference-Example/ta-p/3984291 (use the non-XNET code)
13 hours ago, Sam Dexter said:What makes life even more difficult is that the CAN module is residing on the Ethernet expansion chassis NI-9147.
On the bright side, since you're doing FPGA programming, it doesn't matter if the CAN module is on an Ethernet expansion chassis or if it's plugged directly to your controller -- your code would be the same either way
13 hours ago, hooovahh said:I've never used it but the NI-XNet hardware specifically supports J1939 under the Application Protocol selection when creating the database for the API to use.
AFAIK, that only provides mapping for the basic messages that fit within a single frame, and some basic standard hanshaking + diagnostics. NI-XNET has no built-in support for multi-packet data or complex comms.
I used the XNET example from https://forums.ni.com/t5/Example-Code/J1939-Transport-Protocol-Reference-Example/ta-p/3984291 as a starting point, but still had to write a lot of custom code to encode/decode messages and handle command-response handshakes.
-
15 hours ago, ShaunR said:
Does LabVIEW free the InstanceDataPointer? - it is readable in the Abort, Reserve and Unreserve. Are we limited to a pointer sized variable? It's a (void *) so can we resize the memory it points to and, if so, does LabVIEW free that? (unlikely). Who owns that pointer?
@Rolf Kalbermatter has the answer, as usual:
The parameter type is a pointer-to-InstanceDataPtr (i.e. a pointer-to-a-pointer, or a Handle in LabVIEW terms).
LabVIEW owns the handle, you own the data pointer: You allocate the data in Reserve and you can access that same data in Unreserve/Abort. LabVIEW can't free your pointer since it doesn't know the type/size of your data.
// C++ example #include <ctime> MgErr reserveCallback(InstanceDataPtr* instanceState) { if (*instanceState == nullptr) { time_t* start = new time_t; *start = time(nullptr); *instanceState = start; } else { // We should never reach this point, unless the InstanceDataPtr was not cleared after the last run } return 0; } MgErr unreserveCallback(InstanceDataPtr* instanceState) { time_t end = time(nullptr); time_t* start = static_cast<time_t*>(*instanceState); // Calculate how much time has passed between reserving and unreserving double elapsedSecs = difftime(end, *start); // Note: The handle must be explicitly cleared, otherwise the LabVIEW IDE will pass the old pointer // to reserveCallback() when the VI is re-run delete start; *instanceState = nullptr; return 0; }
-
1
-
-
43 minutes ago, ensegre said:
Is it me, or some spammer is managing to inject spam links in jrpowell quotes?
It's a pretty common spam technique, designed to sneak spam links into innocent-sounding posts.
A moderator should clean out the spam.
-
21 hours ago, hooovahh said:
the compatible binary is libeay32.so
That means it is using OpenSSL 1.0.x or earlier.
In OpenSSL 1.1.0, "libeay32" was renamed to "libcrypto"
-
- Popular Post
- Popular Post
40 minutes ago, Francois Normandin said:Right-Click on the "Read From Text File" method and unselect "Convert EOL".
Or even better: Replace "Write To Text file"/"Read From Text File" with "Write To Binary File"/"Read From Binary File".
The output of "Flatten to String" is not text. (String != Text)
-
3
-
2 hours ago, Antoine Chalons said:
- if MAX is not installed, I would go to the uninstall utility of Windows and select National Instruments Software, this will launch the uninstall utility of NI, it displays everything installed
If it's a new-ish installation, the uninstall utility is replaced by NIPM. But that does also provide a comprehensive list of installed NI software.
-
I don't have one for sale, but our customers would like to purchase cRIO 904x too. Unfortunately, current lead times from NI are around 12 weeks.
-
53 minutes ago, ThomasGutzler said:
Have you tried quick-drop replacing a vi with a vim that has a different connector pane? The wires just connect to nothing, don't break and there's no indication that anything went wrong until you try to build it.
Kwality
Ouch.
Can you please wave this in NI's face? https://forums.ni.com/t5/LabVIEW-2021-Public-Beta/bd-p/labview-2021-beta
-
For those who don't want to watch the video, the list of improvements is also published in the Public Beta: https://forums.ni.com/t5/LabVIEW-2021-Public-Beta/LabVIEW-2021-Beta-Now-Available/td-p/4144143
2 hours ago, PiDi said:You don't really expect much if they start with better 3rd party software integrations.
I don't think that's a bad thing. NI can't exist as a silo and still hope to be relevant to the rest of the world.
Better interoperability makes it easier to justify using LabVIEW in a multi-technology environment (which is often the case in large organizations), and makes it easier for scientists and engineers to start using LabVIEW.
2 hours ago, PiDi said:And then there was the Future of LabVIEW slide:
...
That's just a bunch of generic slogans and integrations of niche products... Don't see any clear idea of the direction here.
Yeah, those are a bit vague.
The second half of the list sounds like the porting over of features from NXG, which seems like a sensible direction (consolidate existing features before coming up with new ones)
-
Hi @LVmigrant, and welcome!
I think nothing beats the effectiveness of a well-designed and well-delivered training course -- you'd learn the most from them in the shortest amount of time and you can be taught to avoid bad habits that might be found online. Still, forums are definitely a helpful way to learn. I studied electrical engineering and basically developed most of my software-related skills via forums, StackOverflow, and lots of home practice. After that, I got my full-time job as a LabVIEW-based programmer in a systems integration company.
-
6 hours ago, Neil Pate said:
I guess what I mean is I find it strange that people would even have local branches that are not pushed to the server. Maybe I am just paranoid about my house burning down, my computer getting stolen of my hard drive dying. For me one of big benefits of cloud based VCS is that I almost always have an up-to-date geographically distributed copy of my code.
Depends on what the server's role is, right?
- If the server is my cloud backup, then yes I should push all local branches to the server all the time.
- If the server is hosting a large open-source project that I'm contributing to, then I'm usually not allowed to push my changes to the server until I've finished everything.
- If the server is hosting my public project releases, then I keep my WIPs and experiments local, and I only push "polished" (possibly squashed/amended) commits.
That last scenario minimizes low-quality commits like "Fix typo in previous commit" that make commit history difficult to read and bloat the repository size -- this is especially important with LabVIEW, where each VI change could potentially increase the repo size by 100s of KB, leading to multi-GB repositories very quickly.
-
1
-
On 7/3/2021 at 3:51 AM, Taylorh140 said:
1. Does something like this already exist?
Not from NI, that I know of.
I did make a similar API that wraps the Qt framework. That involves creating external windows though; your toolkit has the benefit of being integrated with VI front panels.
- Original LAVA post: https://lavag.org/topic/19611-utf-8-text-svg-images-inheritable-gui-components-dynamically-composed-guis-layout-management-splitters-in-tabs-mdis-taskbar-integration-and-much-more/
- NIPM installation instructions: https://jksh.github.io/LQ-Bindings/docs/
As Mikael and Rolf said, class constants are not needed:
On 7/3/2021 at 3:51 AM, Taylorh140 said:2. Is this something that could be useful?
Definitely! LabVIEW's built-in support for dynamic GUIs is very poor. NXG was starting to show some promise with dynamic controls, but that's now dead. So, community-built tools are sorely needed.
Are you planning to make public releases of your work?
On 7/5/2021 at 3:57 PM, Rolf Kalbermatter said:Reminds me a little of the layout principle that Java GUis have. Needs a bit getting used to when you are familiar with systems like the LabVIEW GUI where you put everything at absolute (or relative absolute) positions.
Layouts are common concept in a wide variety of GUI toolkits. Makes it so much easier to create resizable GUIs and support a variety of screen resolutions.
-
21 hours ago, Neil Pate said:
The thing I still find a bit strange is how it is possible for the remote and local branches to be totally different (even different names)..... the thing that seems weird to me is that the local can have a totally different structure.
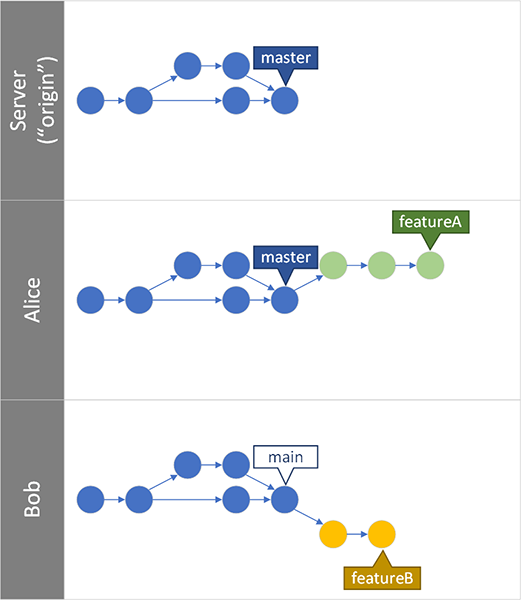
I'm not sure what you mean by "totally different structure". Could you elaborate? Is it captured in the illustration below?
Alice and Bob clone the same repo and checked out the "master" branch. Bob doesn't like master/slave terminology so he renamed his local branch to "main".
Alice and Bob each want to implement a new feature, so they each created local feature branches.
- On Alice's PC, "master" tracks "origin/master". "featureA" doesn't track anything.
- On Bob's PC, "main" tracks "origin/master". "featureB" doesn't track anything.
-
2 hours ago, Neil Pate said:
All of a sudden this makes sense!
🙌 🎉 🎊 🥳
2 hours ago, Neil Pate said:I find this a bit weird, as I presumed if you checkout a commit in say the middle of a branch somewhere you would still be on that particular branch.
What if you check out a commit that is part of multiple branches at the same time?
31 minutes ago, drjdpowell said:"Git Branches aren't branches; they're just tags pointing to commits" is the first thing one needs to understand about Git.
Indeed.
2 hours ago, Neil Pate said:(next step in my git mastery is to understand the subtleties of local and remote branches).
There's not much I can offer that's not already excellently covered by websites like the one you linked.
So, I'll offer some fun facts instead:
- A "remote" repository is usually located on a different machine, which is usually a server. But, the "remote" can also located in a different folder on your local machine. Try it for fun and for education.
- You usually set your local repository to track a remote repository, which is usually on a server and considered the "authoritative"/"master" copy. But at the same time, that remote repository also could choose to track you -- such that from their POV, your copy of the repository is their "remote".
-
6 hours ago, Stagg54 said:
Lookup the LabVIEW Python Node for calling Python from LabVIEW. That may not meet your needs on a CRIO.
Correct, the LabVIEW Python Node currently supports desktop only, not cRIOs. Here is an Idea Exchange post calling for support to be extended to cRIOs: https://forums.ni.com/t5/LabVIEW-Real-Time-Idea-Exchange/Python-Node-support-on-LabVIEW-Realtime-systems/idi-p/3904897?profile.language=en
6 hours ago, Stagg54 said:Under the linux-rt the VI runs in a chroot jail and so you have to do some tricks like using SSH to call python.
No, that's wrong. In NI Linux RT, VIs can access the entire system (as long as the lvuser account is given the required permissions).
It's the LINX Toolkit (for BeagleBone and Raspberry Pi) that puts LabVIEW in a chroot jail.
So, although the Python Node isn't available on cRIOs, you can share data between a LabVIEW application and a Python application via inter-process communication (IPC).
")
Things that make me smile when using LabVIEW.
in LabVIEW General
Posted
Not the example you were thinking of, but this one was hilarious: https://forums.ni.com/t5/LabVIEW/Compiler-is-Too-Smart-for-My-Own-Good/td-p/4188524