

Gary Rubin
-
Posts
633 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Gary Rubin
-
-
America isn't the only country that uses a "." as the decimal identifier
 I don't have any statistics, but I'd hazard a guess to say that "." is more popular that "," around the world...
I don't have any statistics, but I'd hazard a guess to say that "." is more popular that "," around the world...It depends on how you define "more popular", I guess:
-
Another thing to note is that calculating x^2 as x*x is approx 5 times faster than using x**2 in a formula node.
I know that "Power" is a very expensive operation, so this doesn't surprise me.
-
Thank you for providing your test code in LV7.1
I found a couple of other interesting things.
When I replace your Sin and Cosine functions in the subvis with the single function that calculates both, I get a noticeable speed increase (more so for the normal subvi than for the Subroutine priority). When I do the same replacement in the inline case, however, I get no improvement.
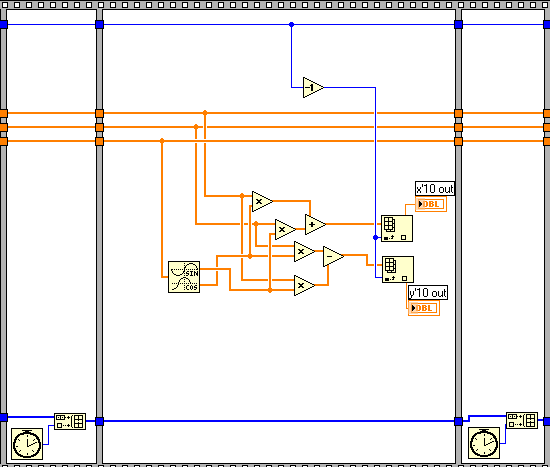
Also, when I replace the indexed inline call with an array inline call (see attached image), I saw slower speed from the array one. I believe this is due to the large number of array allocations necessary because of all the branches in the wires.
I find it interesting that this discussion, along with a previous one, are making me realize that NI's Optimization application notes are not the gospel that I once thought of them as. Instead, the appropriate technique for optimization (i.e. indexing vs. complete arrays) depends a lot on the code itself.
Regarding the use of the subroutine priority - I seem to remember that one shouldn't play around with priorities, as it tends to interfere with multithreading. This goes back a few years though - was that just something related to the way multithreading was done on non-HT processors and/or Win2k?
Gary
-
I'm very interested in what you're doing, but unfortunately, I do not have LV8. Would it be possible to post your test VI in a LV7.1 version?
Thanks,
Gary
-
Hallo everybody,
As it's monday I'm back to work and I can send you the VI with the data I use to load. I dysplayed in the front pannel the result of division, x*y and x+y and the only problem comes from the division, I wish someone can understand the problem,
Thank you very much
pesce
At the risk of sounding dense, what's the problem?
Using my hand calculator and the CS and Capacitance values, I get the same answer as your code. The quotient is very close to the CS value, but it doesn't seem that there's anything wrong with the division.
-
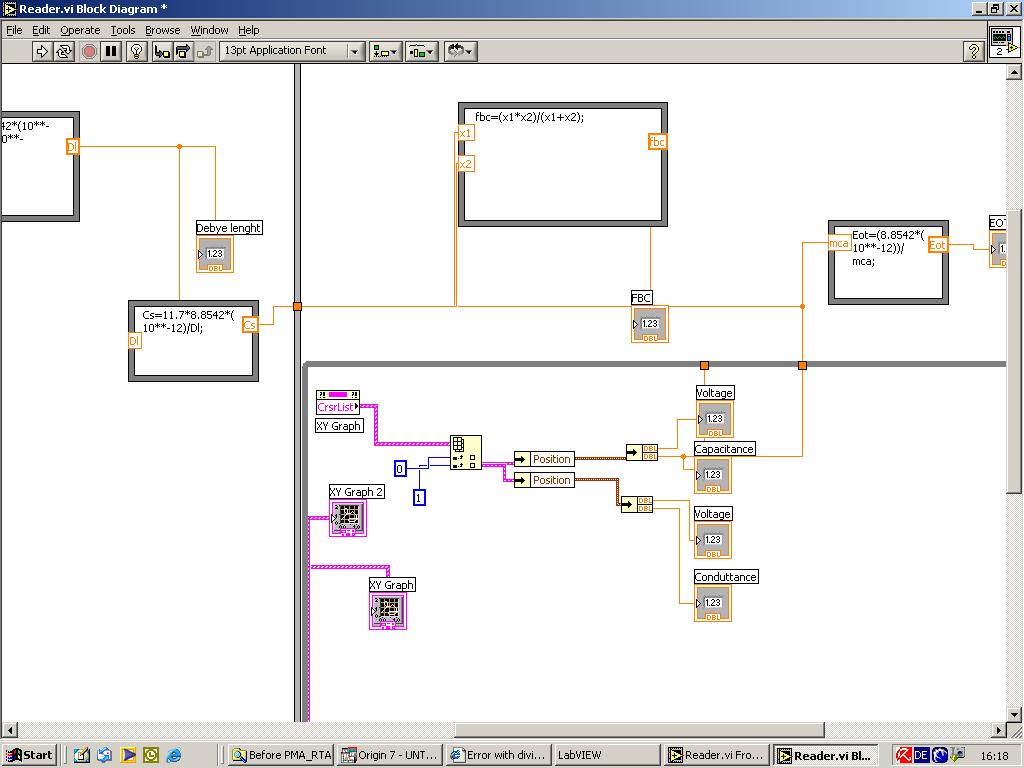
The data should be dbl 64bit
I would just suggest replacing your formula node with this subvi
-
What kind of values do you have for X1 and X2?
Can you provide a code snippet?
-
First, is there any way to increase the size of each data point on the screen to make it easier to read.
Right click on the plot, select Visible Items > Plot Legend
Right Click on the appropriate Plot Legend with the finger icon. Select Point Style and choose a bigger dot. Set interpolation to get rid of the lines and increase the line width to make the dots even bigger.
is there anyway to stick permanent shapes on the plot so it looks like this?I've done something similar using a picture control behind an X-Y graph with a transparent background. The picture control, which I think I found in the Labview Examples, contains the concentric rings and radial lines. Putting a transparent indicator on top of another front-panel object is a no-no from a performance standpoint, but I figured it was better than creating the circles as plots within the XY graph and it doesn't seem to be too bad.
-
Yuri,
Thank you for providing the LV7.1 version of your test. I've duplicated your test in my own VI that I used for benchmarking (attached) and get similar results (local is about a factor of 2 faster than terminal). I'm still very surprised by this. You are correct that the citation I made from the NI app note referred to memory efficiency, not execution time, but my previous experience has always been that the two are very closely related.
One thing I did notice is that when I show buffer allocations in my vi, it shows me that there is an array allocation associated with the terminal, but not with the local variable. This seems inconsistent with NI's recommendations, which says that local variables create copies of the data. Are there any NI lurkers out there who can comment on this?
Gary
-
4. Your topic is very interesting. I modified examples - everyone can try. Please correct them to improve. (Now for LV8 ...)
5. My results are located in examples for my PC (AMD Athlon XP 1900+ 1.6GHz, 1.5 GB RAM).
For example, for me unexpectedness: (Almost always) use reference for data writing - very slow
Yuri,
Unfortunately, I can't run your code (I'm on LV7.1), but I am quite surprised by your tables. Do I understand correctly that your results are consistently better when you pass data via a local than when you wire directly into a terminal?
I am quite surprised by this, especially considering the following from the LabVIEW
-
We are doing Labview-based radar data processing which may fit into your stream-processing definition. We have a non-NI A/D which acquires data and passes it to a bunch of DSPs for initial processing. The data is read from the DSPs by Labview, where we do further processing and display.
For such applications, we always use two parallel loops - one acquisition loop and one processing loop - using LV2-style globals to pass data from the acquisition loop to the processing loop. Obviously, average processing loop speed has to be fast enough to not fall farther and farther behind the data acquisition, but the parallel loops with the LV2-style global is critical in preventing processing or display latencies from causing a buffer overflow in the DSPs.
-
Hello all,
For as long as I can remember, the VI profiler will show a max run time of 15.6ms (sometimes 31.2ms), even for vi's that run very fast. I've seen this with at least LV 7.1 on Win2K and WinXP. I don't recall whether it also goes back to LV 6.x
In trying to get a handle on what's happening here, I've created the attached VI.
I've found that I do see unexpectedly long loop times, but not the 15.6ms. Based on that, I'm thinking that the 15.6ms number is a product of whatever Profile is doing. I'm wondering, however, what exactly is causing these loop time variations. Is it simply the non-determinism of Windows? Is some of it due to Labview's memory management, etc.? If I was using Linux, would I see more consistent loop times?
Thanks,
Gary
-
Is this what you're trying to do?
-
I used to play in WAFC, then in an informal pickup game around the Mall on Sundays. I haven't played for a couple years now -- family obligations, like you said...
Gary
-
[quote name='peteski' date='Apr 4 2006, 09:10 AM' post='11294'
I think that the real problem is that the following wording in the help file is misleading:
Pete, I would certainly agree. I think that that's where our disconnect has been.
BTW, you mentioned something in one of your other posts about playing ultimate. Do you play in the DC area?
Gary
-
I meant a binary search, I know that the 1-D Threshold Array is a NI vi, its been a part of labview for a while. I thought you were looking for a binary search vi.
I've got a binary search VI. I had to modify it to do the interpolation between the two nearest points if the search key is not found.
What I was wondering in the original post was if there was a reason that this the Threshold Array function is not a binary search, given that caveat in Labview Help that the function only works correctly on a sorted array.
Maybe this post would have been appropriate for the Wish List forum, as a suggestion that in future releases, the function could use a binary search.
-
Have you checked the Open G stuff to see if they have a binary search? Or the NI website knowledge base?
I think the one I'm using came from NI.
-
In fact your application would be the "poster child" application for exactly a binary search! (especially since they are asynchronous timetags!)
The reason I would use the Threshold function, or a modified binary search, is precisely because the timetags are asynchronous. Say I've got position measurements at 1:30:00 and 1:30:01, and I've got measurement data collected at 1:30:00.2. The binary search would give me either the position at either 1:30:00 or 1:30:01, but what I really want is the interpolated location at 1:30:00.2. Granted, this is a piecewise linear interpolation, and I could do better with higher-order curve fitting, but if I want one unique position point per measurement point, then a standard binary search would not be sufficient.
Am I missing something in your thinking?
Gary
-
I've always interpreted the Threshold 1D Array function as more akin to a "Trigger Level", and I think that a binary search would be dangerous as such. In a traditional "signal processing" context, you would want to know the first time the "signal" crossed the threshold, and the only way to be sure of that would be do a sequential search for the "crossing of the threshold".
I typically use this Threshold 1D Array along with the Interpolate 1D Array to line up data based on asynchronous time stamps. Because I'm using time as my reference array, it's always ascending.
In fact, there's a comment in Labview's help for the Threshold 1D Array function that says:
Note Use this function only with arrays sorted in non-descending order.This function does not recognize the index of a negative slope crossing, and it might return incorrect data if threshold y is less than the value at start index. Use the Threshold Peak Detector VI for more advanced analysis of arrays.
Is that more along the lines of the usage that you were thinking of?
Gary
-
I'm not sure if I'm posting this in the appropriate forum or not...
I use the Threshold 1D Array function quite often. According to the Labview Help description of this function, and based on my experience, it only works for sorted data.
I just did a timing test, comparing the speed of this function to that of the standard sequential array search, and found it to be slower for array lengths of 500, 1000, 2000, and 10000. This tells me that, although the function only works for sorted data, it is using a sequential search, rather than a binary search. Why is this? Can anyone (from NI?) explain why the Threshold 1D Array function was implemented this way?
I guess I'll be spending some time modifying my binary search vi and going back to my code and doing some replacing...

Gary
-
...but you'll have to find those API calls with thier options and write your own code to call it.
Thanks, that's what I figured.
-
No, you don't get that level of control in the standard LV file dialog.
Sorry, I should have been more specific. I'm using native file dialogs, so this is the Windows file dialog, not the LV one.
-
I am using LV7.1 and have a question about the browse button on a path control.
I can provide a start path and pattern, which will be used by the WinXP file dialog that pops up when I click the browse button. Is there any way that I can also specify the view that I want for the file dialog (i.e. list, details, thumbnail, etc.)? I realize that I can write my own file dialog, but I'd rather not do that if I don't have to.
Thanks,
Gary
-
I've never dealt with Gage, so its good to know to be on the lookout for this!
 I know that if certain things aren't implemented well in the dll's, what might be good in the hardware specs can go to waste in the "bottle necks" created along the way. But still, even if double buffering is not happening at the card side, specifically in this application it might not matter too much, since it would seem there is a 2% duty cycle to the acquisition itself (20 usec every 1 msec). If the dll seizes the control of the CPU from the start of the request for data until the moment it is tranfered to memory, then that would be a royal pain in the...! Regardless, I agree with you that keeping the data acquisition loop as lean as possible is simply the best bet!
I know that if certain things aren't implemented well in the dll's, what might be good in the hardware specs can go to waste in the "bottle necks" created along the way. But still, even if double buffering is not happening at the card side, specifically in this application it might not matter too much, since it would seem there is a 2% duty cycle to the acquisition itself (20 usec every 1 msec). If the dll seizes the control of the CPU from the start of the request for data until the moment it is tranfered to memory, then that would be a royal pain in the...! Regardless, I agree with you that keeping the data acquisition loop as lean as possible is simply the best bet!-Pete Liiva
I think I was able to do about 2kHz max with a considerably higher duty cycle. That was DMA'ing the data right to another card though, so I didn't have to wait for the OS/Labview to deal with the data arrays.
It'd be a bit different with the multiple record. In that case, you store several triggers-worth of data and offload it all at once. It allows you to acquire at a much higher PRF for short periods of time, with the penalty that it takes even longer to offloard the data when you're done with the acquisition.

Case structure and Timers
in Hardware
Posted
You are correct that the second wait is causing preventing the acquisition from occuring every 100ms.
One option would be to do the following:
-Get rid of the sequence structure.
-Put the I/O stuff in a case structure which only executes every fifth iteration
Depending on how long you want to run, you might not want to store it all up, then export at once. Instead, write to file as you go. Check out this example provided in LV7.1: Cont Acq&Graph Voltage-To File(Binary).vi