

torekp
-
Posts
216 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by torekp
-
-
Further further testing shows that the problem is probably the other computer, not Labview or the NI hardware. My bad!

-
Further testing shows that a simplified version of my VI runs just fine regardless of the specified rate. Now I am really confused.
-
This NI document says
Problem:Why do I have to specify a rate when using an external Sample Clock?
Solution:
NI-DAQmx uses the rate input to calculate the buffer size for the task. If you want to specify a particular buffer size, use the DAQmx Configure Input Buffer VI or the DAQmx Configure Output Buffer VI.
The rate input of the Sample Clock VI is also used to calculate the dt component of the waveform data gathered by calling DAQmx Read. By modifying the rate input you will see the data being displayed differently each time due to the dt being changed with each different rate input. As noted in the documentation for the DAQmx Timing VI, it is recommended to have the rate set for the maximum expected rate of the external clock.
But that's not the whole truth: it leaves out the most vital fact.
I have an Analog Output and Analog Input task which share an external sample clock. The external clock comes from a belt encoder and averages 125 kHz with small fluctuations around +/- 1 kHz. The external clock line also drives another process on another computer, which I can use as a check on my process. When my process is working properly, it will stay in sync with the other computer.
When I set the "rate input" to 147 kHz (which used to be accurate, but things have changed since then) my process goes out of sync by a very small amount. My process "sees" only about 99.8 percent of the clock pulses; or at least, that's how much it falls behind. When I set it to 125 kHz, the actual rate, it does not go out of sync, or perhaps it does but in a much more subtle way. (I would have to run an eight-hour test to be sure it does not go out of sync enough to matter.)
Has anyone else noticed this phenomenon? How close to the truth does my rate input have to be, to avoid this problem? Or am I just doomed? I'm using a PCI-6110 board for AI and PCI-6733 for AO.
I wonder if this NI document contains the seed of an answer to my issue.
Problem:I am trying to generate a square wave of 10682 Hz with an update rate of 800 kS/s on the PCI-6733. Why does the frequency of the output signal oscillate? Why am I not getting a stable frequency output?
Solution:
The output frequency is not stable because the PCI-6733 can only generate discrete frequency values for a given update rate. These set of discrete values are obtained by dividing the update rate by a integer value.
For example, if you have an update rate of 800 kS/s, the PCI-6733 can generate 10810 Hz and 10667 Hz with an accuracy of 1 Hz. These two values are obtained by dividing 800 kS/s by 74 and 75, respectively. If you try to generate 10682 Hz, the 2 closest levels to this value are 10810 Hz and 10667 Hz, so the output oscillates between these two values.
Maybe NI is like the X-files: the truth is out there, but good luck finding it?
-
Here's an update. For the case where you have headers for dimensions > row,col, I create a separate file containing those. This file is in the lowest-level folders (i.e. each volume's folder has a copy of the file). Also, the first cell with a header contains some info about whether there are both row and column headers, or whether only one dimension is labeled.
-
Thanks Michael. Does anyone have any feeback about the size-matching trick for headers, and the columns-first priority? Should I add an optional control whereby the user specifies which headers match to which dimension? Should I just be "normal" and try to match your first header array to the first dimension possible, rather than the last? Note that you can always prevent confusion by supplying headers for every dimension, even if some headers are just blank strings.
Also, if you specify headers for pages, volumes, etc., these go into the file names and folder names. Thus, when you write a 4-D array without headers, you get folder names like array_0, array_1, etc., and file names like array_0_0.log, array_0_1.log, etc. When you write the same array WITH headers, you get folder names like array_0_4{[pt}]5Volts, array_1_3{[pt}]5Volts, etc., and files names like array_0_0_10mA.log, array0_1_20mA.log, etc. Maybe this isn't good? Instead, the folder containing the pages of the array could contain a text file listing the headers for each file (i.e. each page), and the next-higher-level folder could contain a text file listing the volume headers. Then I wouldn't have to replace special characters like the decimal point.
-
'Cause I'm an ignoramus! I'll take a look at Peer Review and probably move it to there.
-
Name: Self-Decimating Storage VIs
Submitter: LAVA 1.0 Content
Submitted: 03 Jul 2009
Category: General
LabVIEW Version: 8.0
Version: 1.0.0
License Type: Creative Commons Attribution 3.0
Potentially make this available on the VI Package Network?: Undecided
Copyright © 2007, Huron Valley Steel Corporation
All rights reserved.
Author:
Paul Torek
--see readme file for contact information
Description:
These files allow the programmer to maintain a fixed-sized representative sample of data, regardless of how many data sets are accumulated. The storage may be in the form of a shift register (a.k.a. VI Global) - VIG_self_decimating.vi performs this job - or in the form of a binary file on disk - VIG_decimation_indices.vi and write_2Ddbl_decim8_REentrant.vi do that job, with help from decimatd_evenly_spaced_2D_DBL.vi and decimated_cleanup_2D_DBL.vi. Note that the given VIs are intended for storing 2D DBL arrays, but it is straightforward to modify them to do other formats such as 1D i32 arrays.
Labview 8.0
Version History:
1.0.0:
Initial release of the code.
-
Name: Self-Decimating Storage VIs
Submitter: LAVA 1.0 Content
Submitted: 03 Jul 2009
Category: Database & File IO
LabVIEW Version: 8.0
Version: 1.0.1
License Type: Creative Commons Attribution 3.0
Potentially make this available on the VI Package Network?: Undecided
Copyright © 2007, Huron Valley Steel Corporation
All rights reserved.
Author:
Paul Torek
--see readme file for contact information
Instructions:
Unzip and place the folders Calculations, DB_accessory, tests, InputOutput, and Templates into one location in your file hierarchy, for example, all in user.lib. If you already have folders with some of these names, simply copy the contents into your folders. Examine the example VIs in the "tests" folder.
Description:
How would you like to cram infinite data into finite file space, with rapid reads and writes? Sorry, I can't deliver that - but this may be the next best thing.
These files allow the programmer to maintain a fixed-sized representative sample of data, regardless of how many data sets are accumulated. The storage may be in the form of a shift register (a.k.a. VI Global) - VIG_self_decimating.vi performs this job - or in the form of a binary file on disk - VIG_decimation_indices.vi and write_decim8_REentrant.vi do that job, with help from other VIs included as subVIs in test_decim8file_V101.vi. Note that the binary file VIs are polymorphic for storing 2D DBL arrays, 1D i32 arrays, and a few other types. It is straightforward to modify them to do other formats, or to modify the VI Global likewise.
Each time the storage fills up, the decimation factor doubles, and the storage begins to fill with the data at the new lower frequency, overwriting previously stored data that had been logged at a higher frequency.
Labview 8.0
Version History:
1.0.0:
Initial release of the code.
1.0.1:
New subVIs allow ease of reading decimated files, one record at a time.
-
File Name: VI_path_listing
File Submitter: LAVA 1.0 Content
File Submitted: 02 Jul 2009
File Updated: 02 Jul 2009
File Category: General
LabVIEW Version: 6.1
File Version: 1.0.0
License Type: Creative Commons Attribution 3.0
Potentially make this file available on the VI Package Network?: No
VI_path_listing V1.0.0
Copyright © 2006, Huron Valley Steel Corporation
All rights reserved.
Author:
Paul Torek
contact through http://forums.lavag.org, by sending PM (private message) to torekp
Description:
Lists the paths of all VIs in memory other than itself, with the (optional) exception of vi.lib VIs. Note that if you do not exclude vi.lib, some of this VI's subVIs will appear on the list. Prompts user to save the list to a text file or to Cancel the save operation.
This VI might be useful to those who do not use a rigorous source code control scheme, but still want to keep track of many VIs.
Version History:
1.0.0:
Initial release of the code.
-
Description of my VI (Labview 8.5):
Based on the MooreGoodIdeas VI Process Array Elements, which is a subVI of Write Anything.vi. This VI writes a 2D array along with optional row and column headers to a spreadsheet file. A more-than-two dimensional array will create a folder or hierarchy of folders, with each page of the array written to a separate file.
Includes Freeware from Moore Good Ideas, www.mooregoodideas.com. Do not remove this line.
Headers as Variant can be an array, or cluster containing arrays. The VI will attempt to match the number of elements in each header array with the number of columns, then the number of rows, etc., in that order. Thus if you wish to label both rows and columns and you have the same number of rows and columns, you should list the column headers in the first array and the row headers in the second. If no dimension size matches to the size of one of your header arrays, the VI generates a warning and does not use the header.
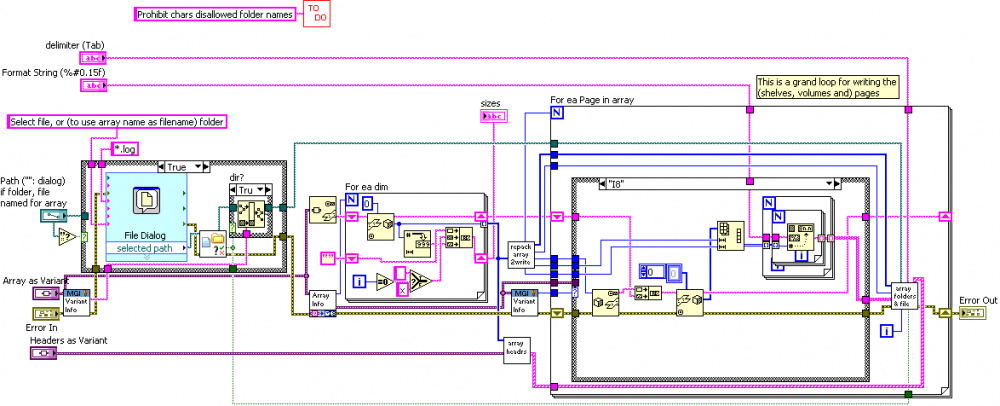
The best way to see how this works is to play with test_rw_array.vi, which you should probably locate together with Write_Array.vi from the zip file. That is, in folder Write_Array Folder\Common\InputOutput\FileArrays.
I haven't yet written a corresponding "Read_Array.vi" yet. I'd like to see what y'all think first.
One of the weird features(/bugs) about my VI is that if you want to include headers for your filed array, my VI automatically matches the size of your headers (which you feed as a cluster of 1D arrays) to corresponding sizes of your main array. Let's say you've got a 5 X 3 X 7 array, and you write a single header with 3 elements. Then my VI knows you meant these to be row headers. On the other hand, let's say you've got a 5 X 3 X 3 array, and a single 3-element header. This is where it gets weird: my VI will assume you want column headers. It will start with the lowest dimension, and if necessary work backwards until a matching size is found. Why? Mostly because I can easily see where a user would want only row and column headers for a high-dimensional array.
If I'm crazy, let me know now, before I build on top of this and make it worse.
-
QUOTE
To view TDM(S) data you can use the Excel add on tool to import the data into Excel.I just heard about this a few days ago, watching an NI presentation. I tried it and thought the way the data is organized in Excel looked ugly. But at your suggestion I looked into it more - the ugliness was my fault. With a little more effort on my part I could make it pretty. When I have used TDMS in the past, I had a need for speed, so I flattened 2D arrays into a single channel. I could create a For loop instead and label each column, and I could make sure the first column is the time, or whatever it is that I want as row labels.
You mentioned your own export vi - would you post it? That would make it easier to distribute my data: I wouldn't have to tell people to download the add-on Excel tool. Plus, I might "improve" it and you might even agree that my changes are improvements.
QUOTE ( @ May 21 2009, 08:52 PM)
You don't need that many. Just pre-process with a for loop (to give the page and you can check the dimensions to bypass) [...]Can you explain more, please? Wouldn't there be a variable number of For loops depending if it's a 3D vs 4D (vs ...) array? Or, are you implying that I should flatten all arrays first, to reduce the # of polymorphs? Hmm, that might be smart... What do you mean about dimensions to bypass?
QUOTE
I actually prefer to save different "pages" to separate files as you can load each one up as a separate sheet and it makes graphing and things easier.That probably makes sense. Then volumes can be folders, and shelves can be folders one level up, and ... and if I'm dealing with more-than-5D arrays then things are getting ugly!
 With TDMS, pages become Excel pages, volumes become different files, and so on.
With TDMS, pages become Excel pages, volumes become different files, and so on. -
I often save files in a format like this:
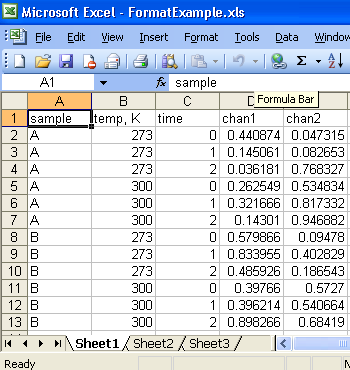
Each row and column can have a header, and sometimes each row has multiple headers, as in this example. By allowing multiple headers per row, I can save a more-than-2-dimensional array, with identifiers for each volume, page, etc. I prefer to save a text file rather than a true Excel file, because it slows things down too much to open and close Excel using ActiveX and so on.
Sometimes I also want a general description of the whole file, which could come at the beginning or end.
I have written too many semi-specialized file writers and readers, with different kinds of headers, etc. I want to "settle this once and for all" by writing two big polymorphic VIs, a write and a read. I'm looking to y'all for advice. Anyone done this? What should I bear in mind?
I'm thinking that there would be a two-D and a many-D version. Within each of those, the main data array could be integer, DBL, or string. The headers could be either same-type-as-data, or string (and if nothing is wired for the given header, it is skipped and we start right in with the data). That's 10 polymorphs of the write VI, and 10 of the read VI. Optional general description of the file, would be preceded and followed by some code like <file header>, </file header>. Whaddaya think?
-
Thanks guys, I will take your advice :worship: Now if only y'all could just agree ...
 Actually, if SVs are just a fancy version of TCP, and UDP is easier on the DAQ computer than TCP ... then I guess ned's advice wins.
Actually, if SVs are just a fancy version of TCP, and UDP is easier on the DAQ computer than TCP ... then I guess ned's advice wins. -
Having just read this thread on communication between executables, and this communication NI guide and this shared variable guide, I have more questions. I need to have two executables on different computers, or preferably one Labview program on the DAQ computer and an executable on the user's computer. The user's computer won't do much. Currently, I am using VI server on the user's computer to open and start the DAQ program and to check periodically that the DAQ program is still running. In the future, I'd also like to get occasional updates to display on the user's computer. There is no urgency or determinism necessary in this, and it is OK if a few updates are missed. The user's computer has little CPU demand.
In contrast, the DAQ computer is running near maximum capacity. (It analyzes data on the fly as well as acquiring, though acquiring seems to be the biggest resource hog.) That bolded "periodically" in the paragraph above was originally every 1 ms, but that caused the DAQ computer to miss some of what it is supposed to see. I changed it to every second, and now it's OK.
Is shared variables a good approach, given my needs? Is it possible to host the shared variable engine on the user's computer, as the second NI guide would advise (based on having adequate processor and memory resources)? Bear in mind that the user's computer will have only an executable.
If TCP/IP or some other alternative would create less burden for the DAQ computer, please let me know. Another alternative I have thought of is to write some binary data to file on the DAQ computer, and read it from the user's computer. Whatever is easiest on the DAQ computer's processor and avoids interrupting the data acquisition and computations, that's what I want.
-
I followed Rolf's advice and came up with this Xcontrol. The VI example_relative_path shows how to use it. In addition to what's attached here, you need the VIs from my previous post.
If you put this Xcontrol in a file-reading VI, browse to an appropriate relative location, and set the default, the path stays good when you upgrade all your VIs to the next Labview version.
The State_rel_path.ctl does nothing, at this point. Maybe a future version will allow relative-to's other than Labview's home path.
-
QUOTE (eaolson @ Aug 27 2008, 09:27 PM)
It's been a while since this was originally, but what immediately comes to mind is taking the HSV color representation, picking N equally-spaced values for H, and keeping S and V at 100%. This should work for any N. Then convert to RGB for LabVIEW. They may not be the most aesthetically pleasing colors, but they would be guaranteed to be distinct. Is there an HSV-to-RGB converter out there for LabVIEW? If not, it should be pretty easy to create.ASK AND YE SHALL RECEIVE (Labview 8.5)

-
MJE, I don't understand the problem. I have had great success translating path info using Compare Two Paths and a few minor accessories. I'm attaching the VIs (8.5) I built on top of Compare Two Paths.
Rolf, thanks for the suggestion.
-
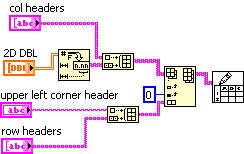
I think he probably means this:
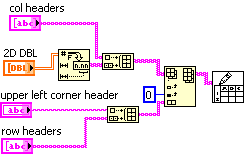
Which produces output like this:
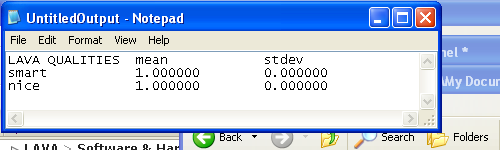
with one set of strings labeling the rows, and the other the columns
-
I just started playing with NI Labs -- Neural Nets, having just now figured out that you DON'T need 8.6 OR 8.6 realtime to use it. Vanilla 8.5 works just fine.
Anyway, (A) this is cool, and (B) I'm a newbie big time. There's an official NI web page to discuss this, but it doesn't have much activity. How about LAVA members?
If anyone can recommend a good Neural Nets For Dummies type book, especially one that discusses whichever variety of network NI Labs is using, I'm all ears.
I made one important discovery so far - it pays, big time, to replace NI's Read From XML with the free Read/Write Anything VIs from Moore Good Ideas. Huge performance boost when you work with big data sets.
-
A brief Google search turns up nothing, but I can't believe this doesn't already exist. I'm looking to place a file control on my VIs, with a browse button visible. When the user browses to (for example) user.lib\Paultext.txt, the new contents of the control should BE user.lib\Paultext.txt rather than C:\Progr ... bview 8.5\user.lib\Paultext.txt. In other words it should fill with the RELATIVE path. (Relative to Labview's home path - although having additional options for "relative to what" would be nice.) Then, I can have a default value for the file which makes sense even after I upgrade to 8.6 or move to a different computer, yet also have browse-ability.
If this doesn't exist yet, I'll make an Xcontrol, I guess.
-
OK, I found out that my problems come mainly from Read From Spreadsheet File (possibly, also, Open TDMS File). So to replace Read From Spreadsheet, I used a Moore Good Ideas freeware VI, called Read Entire File.vi, which has better error messages. I then added this:
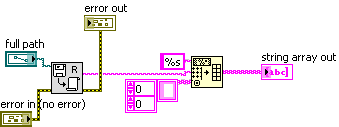
and then made versions for DBL, SGL, i32, and i64, and polymorphed 'em.
-
QUOTE (rolfk @ Feb 16 2009, 02:48 PM)
The only problem where you should get a not file found error is in fact when trying to open a file. So I do not see how you would have to wrap all FileIO functions. Just creating your own Create File/Open File function and using them consistently in your apps would help.OK not ALL file functions, just half. The reading half. Read spreadsheet file, read tdms file, read binary file, etc. (I speak loosely - some of these include the opening of the file, some require a separate opening action, but you get the point.)
-
QUOTE (jdunham @ Feb 13 2009, 11:01 PM)
[...] For example the Clear Errors function clears any error, not just one matching the error code(s) you might be expecting. [...]If you poke around the NI stuff, you can see they have a sort of syntax for adding items like the file name, so you can write code that detects a new error, and adds the info you care about to the error.source field in the format that their dialog boxes understand.
I use the General Error Handler to clear the one error I am expecting. If I don't want a popup in the case of other errors, I test whether code=mycode first.
So you are basically saying that I should write a wrapper for each file function so that errors are properly handled? Argh, my neck hurts already, in anticipation of the pain. I was hoping to just use the better file functions and avoid the worse.
-
Often times I get error messages from attempting to read a file that doesn't exist. Sometimes Labview tells me, in the error message, what file I tried to read; sometimes it doesn't. That piece of information is very useful, so I want to start writing all my code in such a way that if this error happens, I get that information.
Does it just depend on which of Labview's many file functions I use? Does anybody know which ones are user-friendly and which ones are cryptic, when this error occurs? If there's something else going on, what is it?

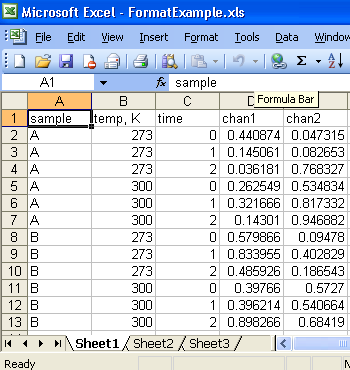

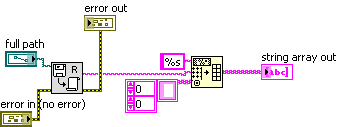
Help with data file format
in Database and File IO
Posted
Moore Good Ideas has wonderful VIs called Write Anything and Read Anything. These would be perfect at least for your header data, if not for all of it. They're free, but worth more than twice the price.
Sorry if this info comes late.