

torekp
-
Posts
216 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by torekp
-
-
What I usually do is just add two more plots to the graph, set their plot names to "Min P" and "Max P", and use distinctive line-and-point-style combinations. For example, use lines without points for the min and max, and a line with points (or just points) for the latest reading from the sensor.
There may be a smarter way. But I don't know it.
-
QUOTE(TG @ Nov 6 2007, 07:32 PM)
Here's my main tricks along those lines - I hope this helps. Create a folder "tests" within your user.lib and unzip the contents of the zip into there, thereby creating a sub-folder within tests which holds the VIs and project. The VI "1D_dbl_data_changes" is just a random VI that I'm calling dynamically. A built executable is included. LV 8.2
http://lavag.org/old_files/monthly_11_2007/post-4616-1194402653.png' target="_blank">
-
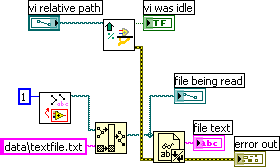
OK, so I read the Labview wiki on re-entrant VIs. And it gives a few useful examples of when to use or avoid re-entrancy. But what about everyday workhorse VIs? For example, MultiColumnSort.vi (thanks again, JFM). I use this pretty often, occasionally with large data sets, and I could easily see where two of my threads might be trying to use it simultaneously.
Should I make it re-entrant just in case? And similarly for all potentially large number-crunching operations?
What about database communication VIs? Say I've got a mid-level VI that opens a connection to an Oracle database, reads a table, and closes the connection, and I use this mid-level VI all over the place. Make it re-entrant?
In general: any good rules of thumb, not already contained in the aforementioned wiki, would be appreciated.
-
QUOTE(takimidante @ Sep 28 2007, 09:37 PM)
refer to my vi, I can create write to spread sheet after the output of shift register there.but I want to try this method...wire from array and link to write file...but I have no idea there to generate it...thank u very much...I'm not sure I understood your question, but is this what you want? It allows the user to view or modify the string array (Table) before saving it to the file.
One thing to watch out for, I put the date and time on a separate line of the file instead of being on the first line like you had it. I like my way better, of course, but you might want to change it back.
-
QUOTE(Ben @ Oct 1 2007, 03:42 PM)
Then a "Quick Check" VI can be developed an used to open (via VI server) a list of Tree.VI's and check if they are broken.Brilliant. I'm doing it. There aren't that many Labview projects in my whole workplace so it won't be too hard to retrofit. The Quick Check could also examine a list of recently changed subVIs and tell you which top level VIs depended on them.
-
Sometimes you just haven't left yourself enough extra connectors on the connector pane and you need to change your subVI's connector pattern. Or you find a strange behavior in a subVI (how it handles negative numbers, maybe) and you want to change it but can't remember how your other projects used this subVI. Maybe they needed negative numbers to be handled in that strange way. However we get there, I think most of us have had the experience of changing a subVI for the sake of one caller, only to break another calling VI in a different project. I know I have.
Can any Source Code Control provide a security check against this? That is, can it notify me when I try to check my subVI back in, "this may affect ProjectX.vi and ProjectY.vi", or some such? I haven't selected an SCC provider yet, but I was looking at Microsoft Visual Source Safe and didn't see it.
-
QUOTE(yen)
I didn't look at the code, but I would probably create a folder for each backup with a formatted timestamp as part of the folder name. Then, whenever you do a backup, you also go over the list of existing backups and delete all the folders which are older than N.Pretty much what I'm doing, except I timestamp the filenames not folders, and I do keep selected files older than N.
QUOTE(NormKirchner @ Aug 29 2007, 01:42 AM)
Am I stating the obvious, but what about source code control? It does go the 'everyting' route, but I know for sure that Perforce optimizes the different versions so it does not necessarily save the entire file for each version.Not obvious at all (or maybe I'm just slow). But this means I'd have to start using source code control - probably a desperately needed idea even without this side-benefit... Thanks for the suggestion.
-
Say you've got some file that you keep changing over and over. You want to save some backup copies but there's no need to save every single one for all eternity. Maybe you want to keep everything less than a week old, then keep another from a month or so ago, then another from 6 months, then another from a year or so ago - for instance.
Or maybe something else. What other ways of managing the backlog of backups make good sense? (Besides the obvious methods, keep everything, or keep nothing.)
Here's what I wrote that does what I just described, for what it's worth. I already want to add one feature to it, which is to keep at least N backup files, no matter what. Where N is the number of "ages" to keep (3 in the above example). LV 8.0.
http://forums.lavag.org/index.php?act=attach&type=post&id=6777http://forums.lavag.org/index.php?act=attach&type=post&id=6778
-
QUOTE(tcplomp @ Aug 21 2007, 04:33 AM)
May I suggest another extremely useful moving average, the exponentially weighted moving average:
http://en.wikipedia.org/wiki/Exponential_smoothing''>http://en.wikipedia.org/wiki/Exponential_smoothing' target="_blank">http://en.wikipedia.org/wiki/Exponential_smoothing
Easy on the processor and on the memory.
-
QUOTE(shoneill @ Aug 15 2007, 07:42 AM)
It's quite possible to have a well multi-threaded QSM if you use the right structure. Of course, I'm takling about an architecture with more than just 1 producer and 1 consumer. Goes more towards component programming than anything else, but it's core is still a QSM.Can you explain this in more detail to someone like me? Someone who's "Not A Real Programmer, But I Play One At Work."

-
QUOTE(abuch06 @ Jul 27 2007, 03:07 PM)
I'd like to suggest two alternate ideas instead of your 3D array:
(A) a 1D array of clusters, each cluster containing {channel, value, time}
Idea (B) lends itself to display on an Intensity Graph:
http://forums.lavag.org/index.php?act=attach&type=post&id=6504http://forums.lavag.org/index.php?act=attach&type=post&id=6505
-
QUOTE(Kevin P @ Jul 18 2007, 01:41 PM)
Don't have an answer here, just some questions in hopes that they may be useful mental prods for someone.-Kevin P.
1. Right, the X-Y boundaries are pretty well defined.
2. The speed ratio of belt and sensor is known, and max sensor speed >> belt speed.
3. The sensor produces a small XY image array, where "resolution" improves as you allow the sensor more time to collect.
4. Objects are as time-consuming to inspect as I want them to be, so to speak. It's probably more important to get large-area objects well-inspected than small-area ones, but I haven't gotten far enough to worry about that yet. It probably is preferable, to a modest degree, to inspect from a position near the centroid of an object - or rather, not too close to the edge.
I've decided that delta-X proximity from the sensors most recent position is not too important. The sensor is fast enough to get where it needs to go, as long as it can settle there for a little while after arriving.
-
Here's a fun fact: if you use LV 8.0 to create an executable and an installer for it, you can install it on a Windows 2000 Server machine, no problem: not even a warning. Even though, according to NI phone support engineers, you're not supposed to do that. I found only one significant problem on the 2000 Server: some file writes were very slow, compared to the speed on WinXP. Otherwise, my apps worked fine.
If you use 8.2.1 to create the installer, you cannot install it on a Windows 2000 Server machine. You are informed that the machine does not meet the requirements. There is no choice, no "Warning: this computer does not meet the requirements; some or all functionality of the program may fail; install anyway?"
I'd rather get a warning, and let me try it at my own risk. Oh well, now I have installed 8.0 onto my WinXP, so that I can "save for previous" and then create executables from 8.0 for distribution to the Server machines.

-
I'm designing an algorithm to tackle my problem, but I have the feeling I'm re-inventing the wheel. Not only that, but my wheel feels kinda square, and I'm hoping there's a round one out there, that you know about.
I've got a moving belt with parts randomly scattered on it. The parts are NOT singulated: if you draw a line across the belt, chances are that you'll find one or two parts there, and occasionally more. Some parts are bigger than others. There is a camera near the feed end of the belt, which identifies the locations of the parts. Further down, a traveling sensor (which travels only across the width of the belt: call this the X-direction in a Cartesian coordinate system) visits the parts for a more detailed inspection. The sensor travels fast enough that there is not much worry about going from one side of the belt to the other. I thought that would be a problem, and asked for advice on it in the past, but it's not a big issue, as long as the sensor is allowed to have some settling time after each jump. However, the sensor can only visit one part at a time. It must divvy up its visiting-time between the various parts that occupy the same line.
I want to optimize the accuracy of the analyses that the sensor gives, and the accuracy is proportional to something like the square root of the amount of time spent on each part. Therefore - I think, correct me if I'm wrong - I want to make the time spent on each part as nearly "fair" (equal) as possible, while of course spending "more than fair" time on a particle if it's the only one around. I don't want the calculation to take much processor time. I've got an idea how to do it, but let me not bias your thinking yet.
Bear in mind that it's possible to encounter clumps of parts, perhaps five or more side by side. It's also possible, and common, for a densely populated area of the belt to go on for some length, so that perhaps 50 parts or so go by before the sensor gets a "breather" (brief empty stretch of belt).
The camera takes data in "frames", which are approximately square areas of belt, and the sensor path calculation is independent for each frame. If a part straddles two frames, the Vision software will pretend that only the larger half exists, so I never need to worry about any stretch of belt longer than a single frame. The camera and Vision software make it natural to mentally divide the belt into a number of thin lines. Approximately one line goes by per millisecond, and we can think of the sensor as being able to occupy any X-location during each millisecond, although it would not be wise to jump around too much from part to part. Each part should be dwelled upon for a while, then go to the next.
-
-
-
Thanks for all the great ideas guys. I wonder, is there any way to make the files not only human-readable but also very user-friendly, for example by putting HTML tags/bookmarks into it so the reader can jump to the parts he considers interesting? Some of my programs have a very large number of settings.
-
When I edit my description after noticing a typo, do I have to re-submit my Zip file even though it hasn't changed? I did so, just to be safe. I noticed that there is a check-mark for "delete old screenshot?" so I just unchecked that and didn't submit a (repeated) screenshot, but I wasn't sure about the Zip file.
-
NI confirms: this is a bug, but they say that it will not happen on the next upgrade. They wrote to me:
QUOTE
Paul:I've investigated the bug report you filed. Please be assured that this is definitely a bug, and one I took very seriously. I want to assure you that the version-to-version support is supposed to be there and should be expected. Here is the situation:
If the file was written by: then:
1) 8.2 Only 8.2 can ever read that file, and sometimes not even
8.2 can read its own files. There was a corruption bug when
writing some types of data.
2) 8.2.1 All versions (8.2, 8.2.1 and 8.5) can read the data.
3) 8.5 All versions (8.2, 8.2.1 and 8.5) can read the data
The next version will have the backward compatibility that you sought.
I gave up on my old files; they weren't all that vital. Like you, I wasn't far from the beginning of my project.
-
Hey ragglefrock, it was worth it, you taught me an important lesson. Namely, if performance really counts, and a VI will be called many times, make it a subroutine. Good to remember.
-
QUOTE(ragglefrock @ Feb 13 2007, 04:59 AM)
If all your decimation factors happen to be powers of 2, then it will be much cheaper for you to use bit shifting instead of the Quotient & Remainder function for dividing. Keep in mind that dividing an unsigned integer by 2^x is the same as shifting the integer x bits to the right without carrying (wrapping around). If you want the remainder, then subtract the result of the bitshift times the power of 2 and subtract it from the original.Something along the lines of the following, though you could perhaps optimize it further.
After making a better version of my idea for the Code Repository, I tried out your suggestion, and found that the native Quotient & Remainder function is faster. Attached, my slightly modified version of your VI, plus the test VI.
-
QUOTE(crelf @ Jun 7 2007, 08:30 PM)
That's me. I'm back, for more trouble.

QUOTE(lavezza @ Jun 8 2007, 04:02 AM)
Some coworkers and I went to the Developer Education Day here in Phoenix. I didn't stay for the "Performance Optimization for Embedded LabVIEW Applications" discussion, but they did say that required inputs can reduce memory allocations. [...]Exactly what I was told.
QUOTE(yen @ Jun 8 2007, 08:43 AM)
.Now you've got me curious how the required-terminal and inside/outside-of-structure variations interact. Can you get a good performance with a terminal-inside-the-structure as long as it's a required terminal on the connector pane? Or do you have to do it right both ways?
At this rate, I'll need to take about 2 weeks to go back and fix all my subvi's.
-
I'm getting error 1401 when trying to read datalogs that I created in 8.20. These datalogs were fine until I upgraded to 8.2.1 and mass-compiled.
"Error 1401 occurred at Read Datalog in SG.lvlib:toplevel_read_datalog.vi
Possible reason(s):
LabVIEW: Attempted to read flattened data of a LabVIEW class. The version of the class currently in memory is older than the version of the data. You must find a newer version of the class to load this data."
Note, I am always running my VIs from the development environment, both when creating datalogs and when reading them. When I create new datalogs I can read them; it's just the older datalogs that Labview thinks contain a newer version of the class. :headbang:
Any workarounds? Can I brute-force an uptick in the version number of my class, by going to its properties and just typing in a new version number, and if so do you think that would help? Should I change the data in my class in some subtle harmless way (I32 to U32?) to cause a version number increase? I'm a total GOOP novice, and I don't want to f mess things up any more than they already are.
-
QUOTE(Aristos Queue @ Jun 6 2007, 04:31 PM)
I never built an application, I worked from the development environment in 8.20, and again in 8.2.1. But I'll take your advice and move the question to the GOOP forum. Edit: the new thread is http://forums.lavag.org/index.php?showtopic=8397' target="_blank">here.
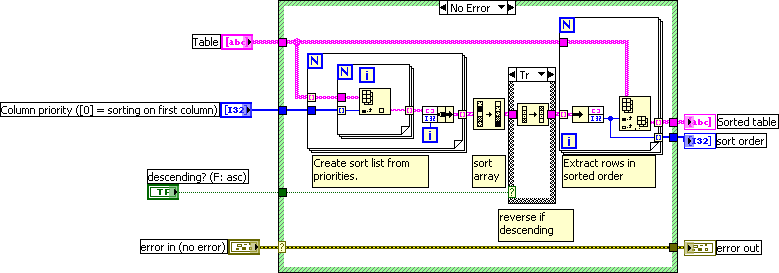
Boxcar (running) average for 1D array
in LabVIEW General
Posted
Excellent, bazookazuz.
I personally prefer to use exponentially weighted moving averages for most applications. The formula for it is EWMA(i+1) = EWMA(i)*(1-lambda) + latestDataPt*lambda. It's even simpler to compute, and does a nice job of smoothing. The only problem case I've ever seen where you wouldn't want EWMA is where machine error occasionally gives you wild numbers in the (usually negative, for some reason) billions while your real data is order ~ 1. In that case, boxcar moving average is better, because it comes back to sanity faster.