

bbean
-
Posts
264 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by bbean
-
-
I can't imagine why one couldn't call a static method from a .NET assembly from any .NET language. I'm wondering from the questions you ask if the wrapper dll your customers write is a COM wrapper, since no, you can't just register a .NET assembly as a COM object and have it show up through an ActiveX type interface. So maybe they want to call the .NET DLL from an unmanaged context (C++ maybe?).
I think you hit the nail on the head here. After pestering the customer, it turns out they are calling from an unmanaged Hamilton interface
You can, it appears, make your .NET DLL COM Visible (see "Exposing .NET Framework Objects to COM", http://msdn.microsof...y/zsfww439.aspx),Interesting I'll have to check this out
Alternately, you can build a LabVIEW exe as an ActiveX server and that will show up as a registered COM component, but that's a whole 'nuther can of worms. It works, but it ain't pretty.Not going there at this point

Thanks for your help
-
For the project I'm working on we created a LabVIEW build spec to create an interop dll that exports interfaces for several of our VI's. When we give the interop dll to 3rd parties that need to call the dll, they claim that they need to create a "wrapper dll" to call our interop.dll. They indicate that the exported interfaces are "static" and that they can't call the interopdll directly. They were also asking if there a way to make the interfaces of an interop dll created in LabVIEW "COM Visible"?
Are we building the interop dll improperly in LabVIEW? Do we need to embed a manifest file for them to call the interop dll directly?
Is it possible that they cannot call the dll directly because they forgot to include the reference to the NationalInstruments.LabVIEW.Interop.dll?
Sorry for the barrage of questions. This is the first time I've worked with interop dll's in LabVIEW
-
Here is an interesting talk by Bret Victor. He has designed experimental UI concepts for Apple and others. To me its interesting to see how text based languages could catch up to LabVIEW's graphical style and even exceed it with instant visual feedback. Its also interesting to see how the IDE in any language could be improved.
The video goes much deeper than programming languages and delves into life principals. Well worth the watch.
-
 2
2
-
-
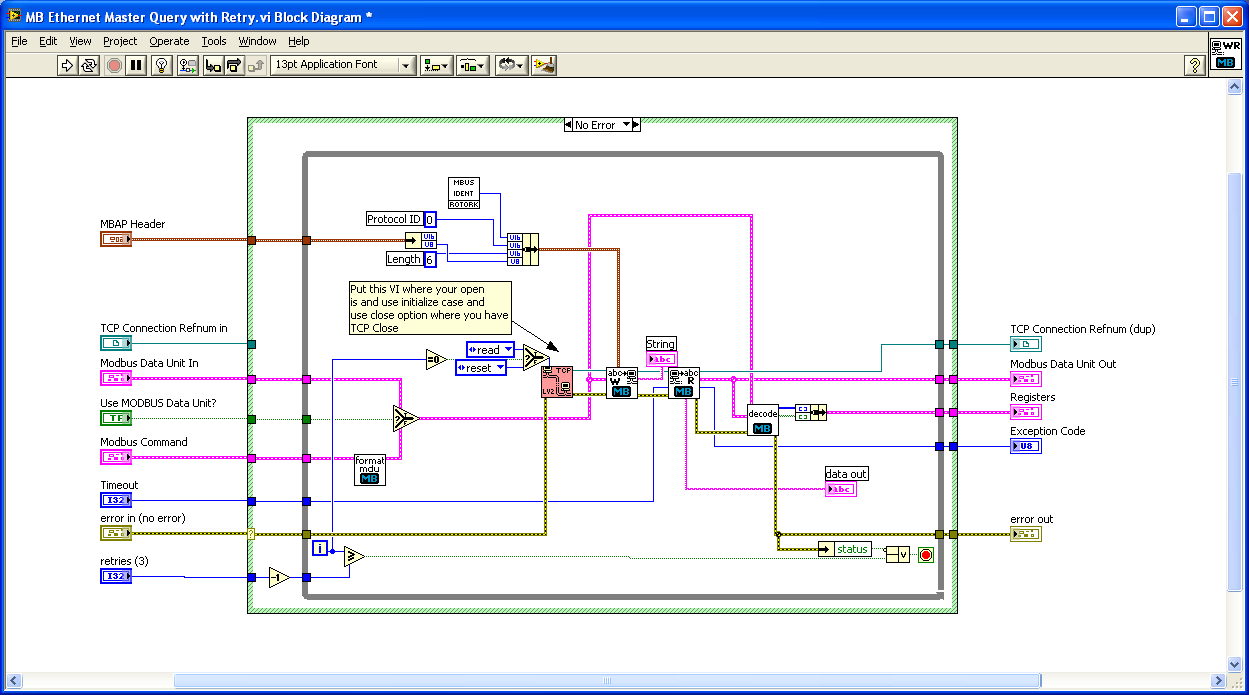
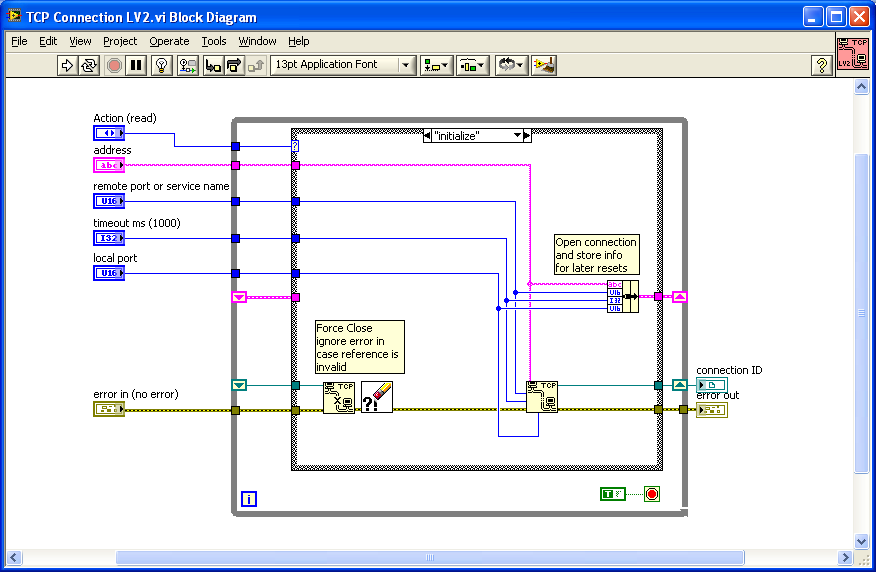
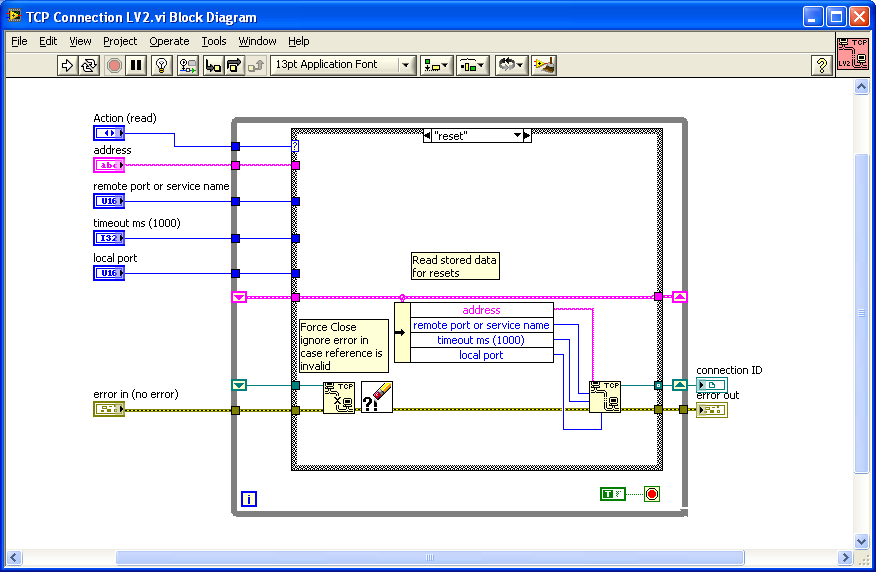
Here's a potential hack to retry the connection if you get an error. If you create a LV2 style global / action engine to store your TCP/IP connection info, you can place that VI inside your MB query and reset the connection if you get an error 66 or 56 or whatever.
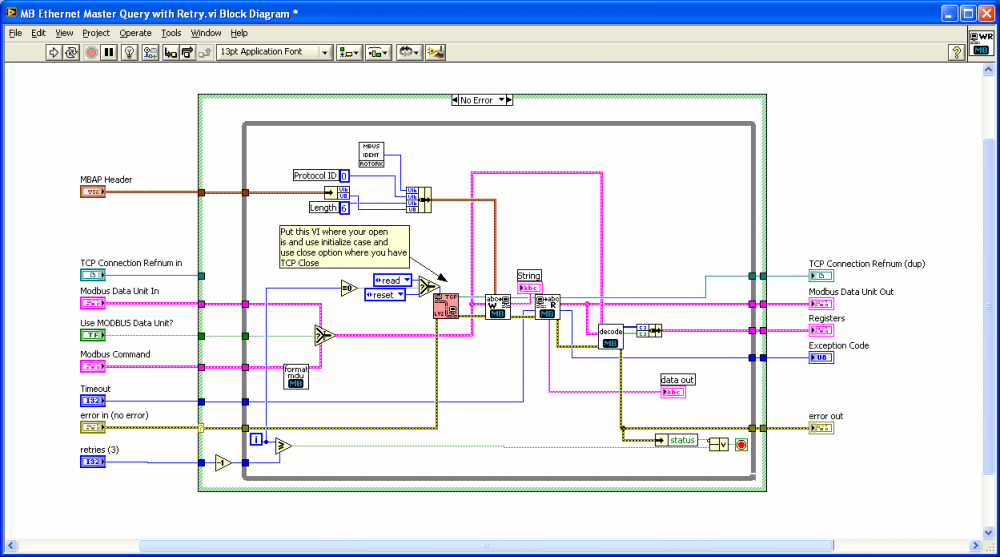
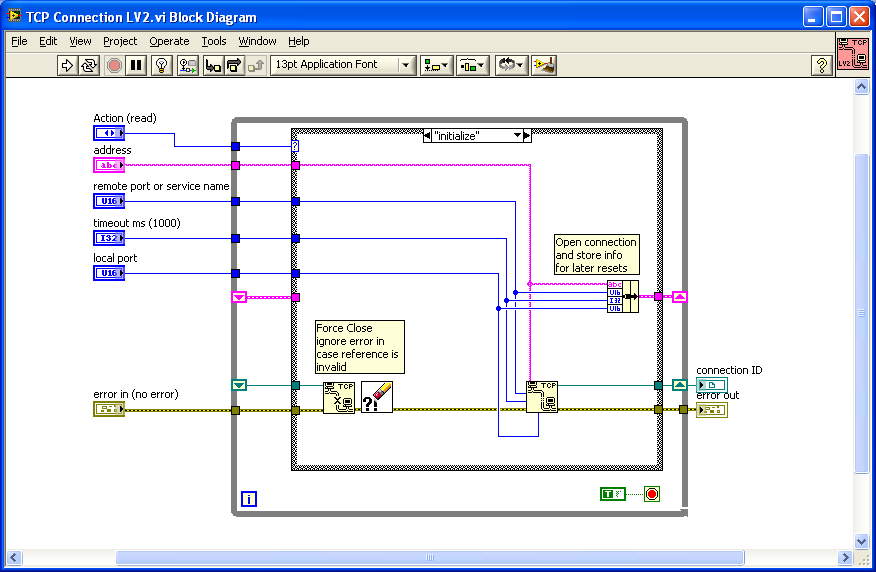
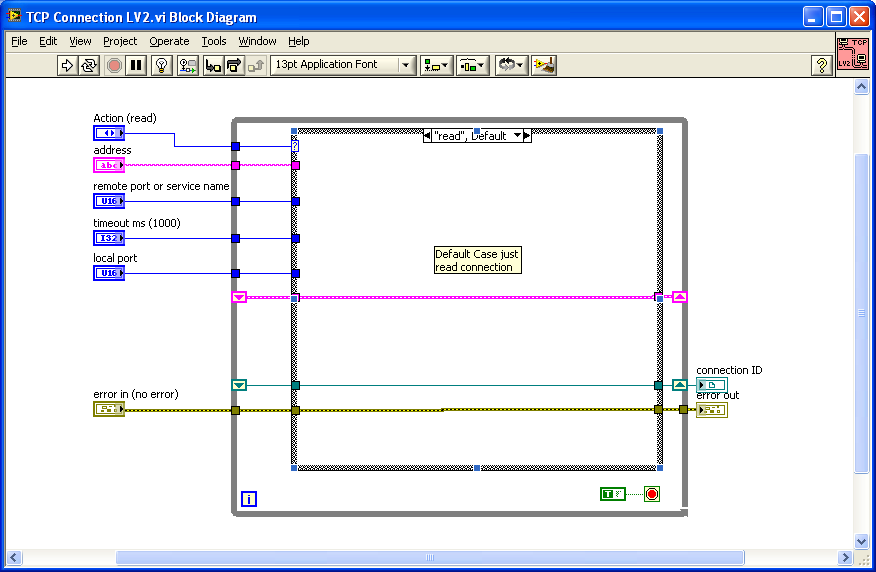
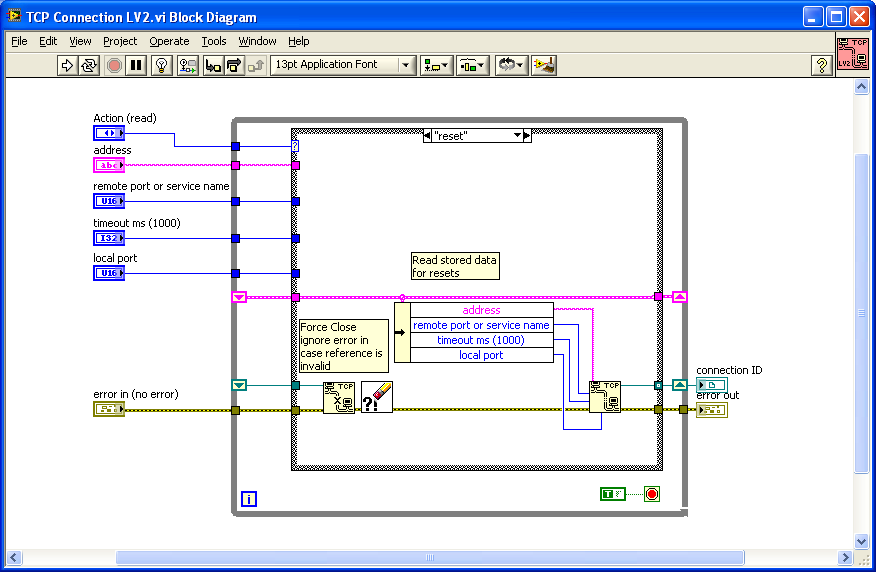
I can't compile it down to 7.1 but included in the zip file as 8.6 if someone else can down convert it.
-
I'm using them both and they work as advertised. I think Subversion on the server and TortoiseSVN on the client side are a little more refined for windows use than Trac. I found that setting up Trac was a bit cumbersome because its mainly command line based. It also has a lot of prequiste software that also needs to be installed (apache,python, etc). But if your comfortable with Python, etc it will be easy.
The one thing I wish trac had was the ability to create tickets with deadlines that could be displayed in a Gantt chart on the web interface. Its great for bug tracking though.
The other experience I had with Trac was on the customer side. When I first installed Trac, I set up customers with access to the web interface and the capability to add bugs etc. Turns out they mostly want to just send emails or right down bugs on a piece of paper and hand it to me to enter into Trac.
-
I have an instrument class that uses serial comm to talk to a single instrument. Lets call it Instr. I created another class that has multiple instances of Instr. Lets call it Group. Each of the methods in Instr is duplicated in Group. I need to execute the methods for each Instr in the Group at roughly the same time in parallel.
Currently all the methods of instument are re-entrant (preallocate) and also some of the subvis like "serial packet send receive.vi", "wait for operation complete.vi",etc . The problem I'm seeing now is that there are hundreds of "serial packet send receive.vi" instances and lots of instances of the method vis.
None of the reentrant VIs maintain state so I'm going to try to switch to shared reentrancy and see if there are any improvements. But I was wondering, does shared reentrancy create a "pool" of instances where it only opens up as many as are needed for parallel execution at one point in time or does an instance get allocated every time the VI is executed.
For instance, say in my Instr class i have a method called "eject" (set as reentrant shared) and in the Group "eject" method the vi executes 8 instrument "ejects" in parallel. If i also call the Group "eject" in multiple places is:
# of Inst "eject" instances = 8
or
# of Inst "eject" instances = n x Group "eject"s x 8
Is there a better way to do this. I really only need one "serial packet send receive.vi" per Instr since all communication is executed serially. One thought I had was to open a reference to the "serial packet send receive.vi" and store the reference in the class, then just call this referenced VI every time. The other thought i had would be to move all of the method executions into the process vi for the class.
thanks for any help.
-
People have been going through the code found in the hacked files and have found numerous examples of "tricks" to manipulate the data. Granted the people looking over the files are climate change "deniers" but if you look at the examples they present from a programming standpoint something smells fishy.
http://www.americant...mategate_r.html
Example 2
In two other programs, briffa_Sep98_d.pro and briffa_Sep98_e.pro, the "correction" is bolder by far. The programmer (Keith Briffa?) entitled the "adjustment" routine “Apply a VERY ARTIFICAL correction for decline!!” And he or she wasn't kidding. Now IDL is not a native language of mine, but its syntax is similar enough to others I'm familiar with, so please bear with me while I get a tad techie on you. Here's the "fudge factor" (notice the brash SOB actually called it that in his REM statement):
yrloc=[1400,findgen(19)*5.+1904]valadj=[0.,0.,0.,0.,0.,-0.1,-0.25,-0.3,0.,-0.1,0.3,0.8,1.2,1.7,2.5,2.6,2.6,2.6,2.6,2.6]*0.75 ; fudge factorThese two lines of code establish a twenty-element array (yrloc) comprising the year 1400 (base year, but not sure why needed here) and nineteen years between 1904 and 1994 in half-decade increments. Then the corresponding "fudge factor" (from the valadj matrix) is applied to each interval. As you can see, not only are temperatures biased to the upside later in the century (though certainly prior to 1960), but a few mid-century intervals are being biased slightly lower. That, coupled with the post-1930 restatement we encountered earlier, would imply that in addition to an embarrassing false decline experienced with their MXD after 1960 (or earlier), CRU's "divergence problem" also includes a minor false incline after 1930. And the former apparently wasn't a particularly well-guarded secret, although the actual adjustment period remained buried beneath the surface.
Plotting programs such as data4alps.pro print this reminder to the user prior to rendering the chart:
IMPORTANT NOTE:The data after 1960 should not be used. The tree-ring density records tend to show a decline after 1960 relative to the summer temperature in many high-latitude locations. In this data set this "decline" has been artificially removed in an ad-hoc way, and this means that data after 1960 no longer represent tree-ring density variations, but have been modified to look more like the observed temperatures.Others, such as mxdgrid2ascii.pro, issue this warning:
NOTE: recent decline in tree-ring density has been ARTIFICIALLY REMOVED to facilitate calibration. THEREFORE, post-1960 values will be much closer to observed temperatures then (sic) they should be which will incorrectly imply the reconstruction is more skilful than it actually is. See Osborn et al. (2004).-
1
-
-
GA_googleFillSlot("news_story_left_sidebar"); LONDON (AP) - Britain's University of East Anglia says the director of its prestigious Climatic Research Unit is stepping down pending an investigation into allegations that he overstated the case for man-made climate change.
http://www.breitbart.com/article.php?id=D9CAM0VG0&show_article=1
-
QUOTE (postformac @ Apr 7 2009, 06:28 PM)
For example if I want to write a hex number 0x05 (which would be interpreted in ASCII as an ENQ) it gets sent out as ASCII "5" (ie. 35 in hex). My hardware is looking for a hex value of 0x05 to come in the serial port which it then never gets (as obviously it receives 0x35 instead). Is there any way to get my LV serial write to just write a specific byte without applying the ASCII conversion?Thanks
Right click on the string constant you are using and select "display as hex" then type 05. If you are using "scan from string" do the same thing on the format string.
-
-
QUOTE (Neville D @ Aug 6 2008, 06:50 PM)
Interesting. Thanks for the tip. I wonder what the command line uses. I guess I could check it out with wireshark. I'm getting a little over 300ms but thats much better than before and acceptable for a user interface.
QUOTE (Phillip Brooks @ Aug 7 2008, 08:21 AM)
Here is an example of what I use. I wanted to be able to test the ability to connect to the FTP server independent of LabVIEW, so I created a wrapper for the function "FTP Put Multiple Files and Buffers.vi"that parses an RFC-1738 FTP URL.I can check for access to the server using the exact same string from IE or FireFox. If it doesn't work from those, then I might have a firewall or proxy problem.(LV7.0)Interesting. I shouldn't have any security issues because its just a local machine going to cRIO. I'll check out your example. Thanks for the link
-
Hi all is there a way to get a quick directory listing from an ftp path. Tried the FTP VIs in the Internet toolkit and it took around 2 - 3 seconds to return a directory. That seems a little slow.
Using the windows command line, I can speed it up a bit (see attached LV8.5 example), but that is kind of a cheezy/non Native LabVIEW way to do it. Was wondering if there was a way with Datasocket or something else I'm missing.
B
-
QUOTE (Aristos Queue @ Jun 27 2008, 09:30 PM)
Most benchmarks have found that the variant attribute (like the one you implemented here) is a fairly efficient lookup table mechanism in LV8.2 and later (it was dog slow before that). I'm surprised if the array version was able to keep up. I can say that the variant attribute model will get a further speed improvement in the next version of LV -- not much, but a bit. You might retry benchmarks when that becomes available.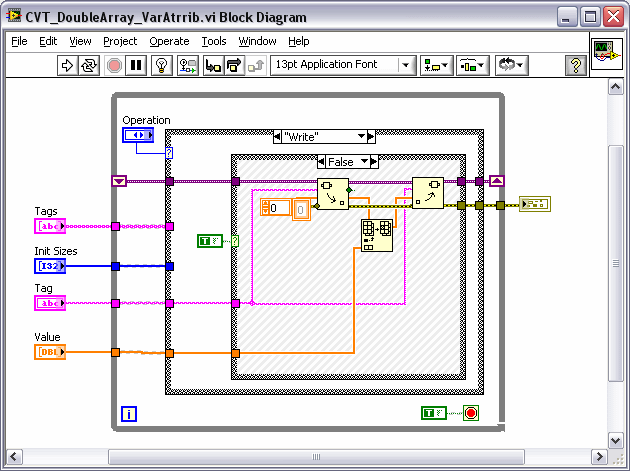
-
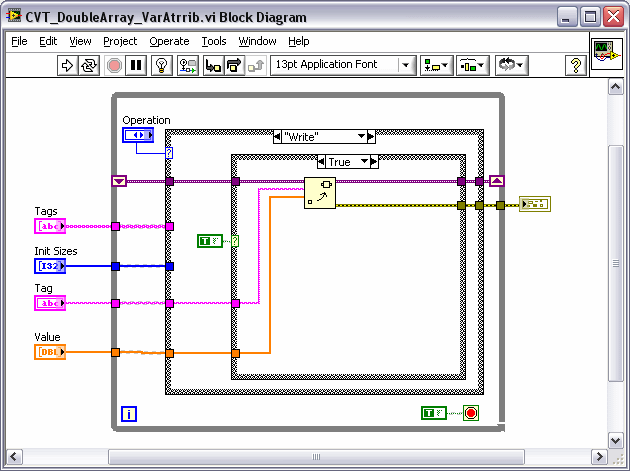
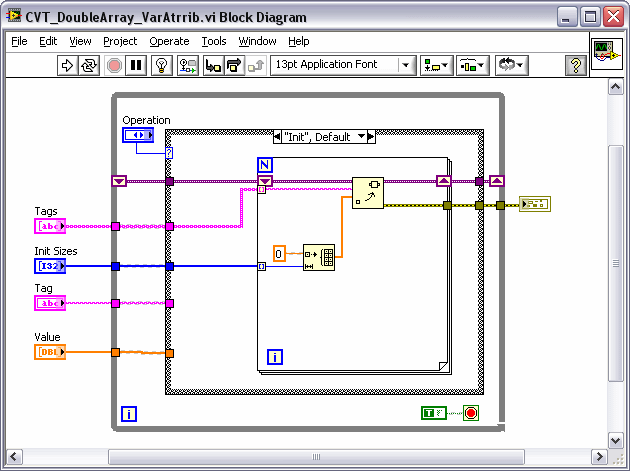
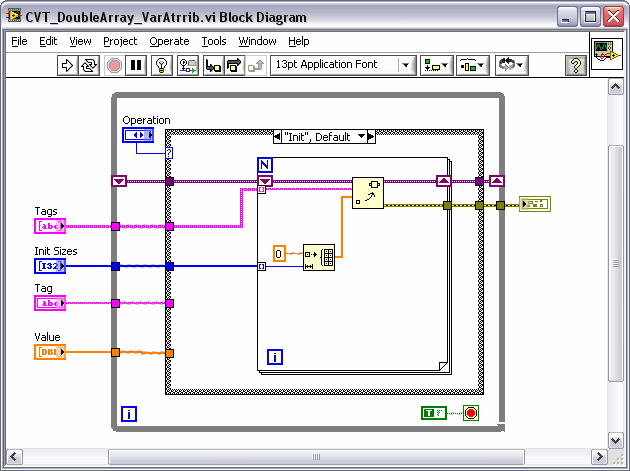
I found the design pattern for a LV RT Local Machine on the website that looks promising (although its a b@#$h to get set up because they don't provide all the links / dependencies on one page). Part of the design pattern uses a Current Value Table (CVT) that facilitates storing, tagging and passing different type data points between the RT target and the host. Essentially you set up all your variables for the application with another NI tool called the Tag Configuration Editor (TCE) and save them to a .tcf file. The RT Target and Host read this file to set everything up. The attached CVT Double shows how the data is stored for single point double tags.
However, the TCE currently doesn't look like it has support for arrays of each data type. Under the hood in the LabVIEW code the Tag Configuration cluster has a flag for array and an array size integer, but tagged arrays aren't implemented anywhere else.
So... I was going to create an current value table for arrays of data. I would like to keep the CVT for arrays generic so that I can store all tags that have an array data type in one shift register (even if they are different sized arrays). I thought of using a shift register with an array of variants. Each variant in the array would hold an array of say doubles as shown in the attached method 1. The thing I'm worried about is memory allocation in RT on the "read" since the Variant to array conversion won't be able to use the replace array and have a preallocated array size.

So the only thing I can think of is to use method 3 and build a specific shift LV2 style VI for EACH tag that has an array data type. This does not seem very flexible though. I would prefer to use Method 2. Any suggestions?
-
-
QUOTE (Yen @ Jun 19 2008, 02:38 PM)
I'm not sure how the RT memory manager works when allocating strings, but I would suggest having a constant size for all strings and then replacing inside the string. You can do this by initializing the string to N null chars and then using replace substring. If you want to save time on writing a circular buffer, you can use this one.Thanks for the link. I guess thats what I was wondering, are strings just like arrays in terms of replacing vs building in LV RT. In other words can you preallocate them to a fixed length and then use the replace substring like you said to avoid memory allocation everytime you update.
QUOTE (neB @ Jun 19 2008, 09:03 AM)
-
QUOTE (Neville D @ Jun 18 2008, 06:26 PM)
You could use shared variables to write info to a Host PC, and then display any kind of history you want.You could also use shared variables to write values to controls on the remote RT application.
there are a number of such examples on the NI site zone.ni.com.
Neville.
I guess I'm lazy and would like to avoid writing a client LV app if we could use a web browser. Don't know if I'm trying to fit a round peg into a square hole, but wanted to get feedback from others. Wouldn't I have some of the same issues with memory/buffer allocations using a shared variable string? I realize they would help with "keeping it real time" because they have a lower priority.
thanks
-
QUOTE (neB @ Jun 18 2008, 04:04 PM)
I and my customers have been burned by strings in RT apps running of FP units.Try to avoid strings completely. If you have code that always returns the same string, concider using an enum to display those strings.
I have used LV2's set-up as round-robin buffers to do what you are attempting.
AS you are developing watch your memory usage over extended periods of time. THe run out of memory issue will sneak up on you if you don't.
Ben
Thanks Ben. Good to know about your experience with strings. I'm using cRIO. Not sure if that makes a difference one way or another.
What has your experience been with Remote Front Panels (RFPs)?
I guess I'm trying to avoid making a custom client application to communicate with the cRIO app. I'd like to keep the architecture simple if possible. And since RFPs handle all the dirty work of connection management and display, I thought it be easiest to use them. But the event log (and data log) presents a memory / keeping it Real...Time issue.
I guess another option would be to do a LV client app with a RFP on the front panel of the diagram for the user to change setpoints/monitor current analog values and additional charts, graphs, strings to display RT unfriendly data. These indicators would then be populated, by reading the log / data files on the cRIO filesystem via FTP.
-
I have to provide a list of events that have occurred during execution of my run-time application to the user. The user will access the RT app via Remote Front Panels. The events are described by a timestamp and a string. And don't occur that frequently (once a minute) For example:
10:30:04 - TEMP ALARM - ZONE 1 - TEMPC = 30
10:31:04 - POSITION MOVE - 33 mm
etc
etc
I'm trying to determine the best method to store and display the data in LV RT. Here are the options I've thought of:
Datatype / Storage Method / Display Method
1) string / FIFO string buffer of 100 lines LV2 global / string indicator on FP (limited to 100 lines) (I know there really isn't a front panel in LV RT)
2) Cluster of timestamp & string / 100 element queue / array of datatype on front panel
3) string / event file / string indicator on FP (limited to 100 lines)
If I use 1 and (a string indicator), I'm worried about it sucking up CPU resources and memory to limit the size of the string to 100 lines.
For option 3, I thought I would read the last 100 lines into the string indicator on the FP everytime a new event occurred (it has to be written to the file anyway).
Any suggestions?
-
QUOTE (achates @ Jun 17 2008, 06:16 AM)
As per your suggestions, I am reattaching the code. In the code, the samples are being compressed with the last sample being written to the file. My question ultimately boils down to ' how can we write dynamic data values after compression along with the date and time at which each was sampled in the same xl file'?here's one way to do it.
-
I know this is probably a long shot but....Does anyone developed a LabVIEW driver for a REX F900 digital controllers from RKC instrument Inc?
I checked on ni.com but all I found was an OPC server for Win XP. http://www.ni.com/opc/opcservers.htm
The application I will be developing is targeted for LabVIEW RT.
-
Is your problem that you do not know what the data ready message is? You could try running a USB sniffer like:
http://benoit.papillault.free.fr/usbsnoop/doc.php.en
while the vendor software is running to find out what the message is?
-
QUOTE(Aristos Queue @ Dec 12 2007, 12:51 PM)
An element is an independent item and gets copied out of the array. If the output of the first Index Array was an array data type, we could have a subarray of a single element, but it isn't an array output -- it is an element.Thanks for the description.
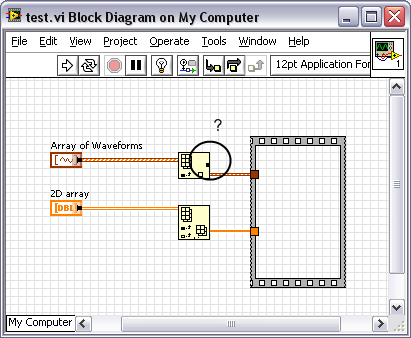
Whats the point of using the waveform datatype (when you have multiple channels) then? If everytime you need to look at the data for an individual channel, a copy of the data is made (even if you are not altering the data). The LabVIEW compiler isn't smart enough to deal with this issue? :thumbdown:
Does anyone have tricks for using waveform arrays or should I go and convert all my DAQ code to 2D arrays?

-
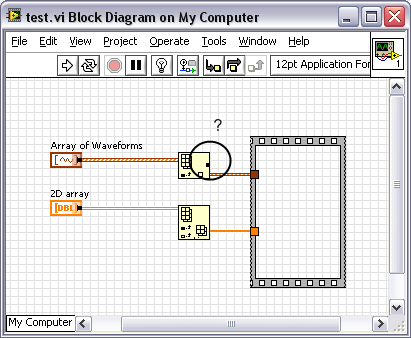
Why does indexing an array of waveforms create a buffer allocation, but indexing a 2d array does not?



Corrupt topic
in Site Feedback & Support
Posted
I'm still having this problem.