

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
I looked at the linked file... there's no mechanism that I see in that demo to change the type of the event. What header do you edit to change the data type?
-
You say "a dynamically called VI". If you called it by using the "Run VI" method, that's a separate VI Hierarchy. If you called it using the Call By Reference node, that's the same VI Hierarchy.
(Note for LV 2011 users: If you use "fire and forget" mode with the Asynch Call By Ref, that's the same as Run VI method and so is a separate VI Hierarchy. If you use "fire and collect" mode, that's the same VI Hierarchy.)
-
To me, this sounds like a problem for User Events and User Events only. All other refnums can be wrapped in classes.
Why would I oppose building something more common for references generally? First of all, you only put a single checkbox in the Library Properties, but just because I have one reference that I want to restrict does not imply I want to restrict all references. Second, you're asking for restricting destroying the reference, but with queues, it is not uncommon to want to restrict either enqueue or dequeue -- any given subset of functionality might be the subset you wish to restrict (I even imagine one case where the *only* thing the outside can do is destroy the queue, which stops the internal producer/consumer loop). Third, you might want to share functionality to some people but not to others.
For all these reasons, I think building a class that exposes the functionality that you want is the more desirable route. Asking for some scripting tools to create those wrappers faster would be reasonable.
The restrictions for DVRs of class types do not fall in the above categories because those are restrictions that apply to the *entire type* of refnum. A type-wide restriction is different than a per-instance restriciton. If you wanted to prevent anyone from ever destroying a "User Event of Subtype X", that would be more viable as a request than the per instance restriction.
As for the User Event, asking for a new node that, given a User Event, outputs a "Registration-Only User Event" gives you something that could still be connected to a Register Event node. With that small adjustment, you could build a refnum class that can register, send, etc.
The *top-level* VI is tracked, but not the specific subVI, and this would need to be on the specific subVI. It would require a new tracking system.but I expect somewhere LabVIEW is aware of where refnums are created, because you can always get bitten by refnums going invalid if the hierarchy that created the refnum returns, for example.
It is the language's job when the restriction is applied to the whole type (like having a private destructor in C++). It's not the language's job when we're talking specific instances of a type.but ultimately I think enforcing such a mechanism is not the job of the language-
 2
2
-
-
This will be fixed in LV 2012. It wasn't deemed high severity enough for LV 2011 SP1.
-
Just FYI, the old "array of int16" type descriptors are all pretty much deprecated as far as LV R&D are concerned. There are many types that those arrays cannot accurately reflect, which is why we use the Variant library that "TheJ" mentioned.
-
Flatten to String can return Out Of Memory.
-
Yes, it would. Insert standard arguments here regarding priorities, resources...Regarding this code fragment, wouldn't a high-performance, flexible, and clearly-readable solution be to add the functionality to the case structure itself? -
I appreciate the effort Stephen goes to to keep us informed and I hope my comments aren't perceived as an attack on him. The fact that he has to explain how to accomplish certain tasks efficiently should be a clue the language is not providing something developers need.
No offense taken, Daklu. The technical feedback is generally valuable.
In this case, I suggest your statement is sometimes true, but not always, and I'm not sure whether it is true in this case, so I'm going to walk through my thought process publicly.
Let's start with this example. The code on either side of the black bar does the same functionality:
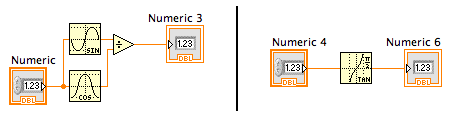
Suppose many users are writing the code on the left, which is less efficient than the code on the right. Is that a deficiency of the language? No. Is it a deficiency of our documentation? I'm not sure... it certainly doesn't seem like it is LabVIEW's job to be documenting all the possible trig identities. Maybe VI Analyzer could detect simple trig substitutions like this one, but it would be hard to teach it all the known interesting identities. So if I saw many customers writing the code on the left and posted "hey, you should use the code on the right", that wouldn't reflect a deficiency in the language.
I believe that the above demonstrates that that the assertion of "efficiency advisory implies language deficiency" is not universally true.
Next thought experiment: Advising users to use the Inplace Element Structure instead of Index Array and Replace Array Subset.
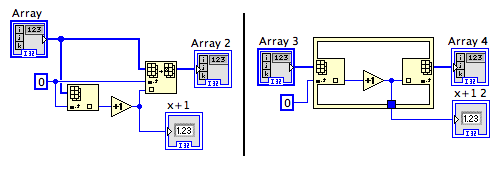
The structure node gives LabVIEW information about your intentions that is hard or impossible (depending upon the exact code you write) to derive otherwise, and the compiler can use that information to make more efficient code. This is an example of, essentially, using exactly the same two nodes, but using them in a specific way. Is the language deficient? No, it provides a way to make your intentions clear to the compiler. Is the compiler deficient? Yes. In much the same way as the trig identity substitution, the compiler is not smart enough to recognize what you're doing. So it is a lack of artificial intelligence. But it does demonstrate that an efficiency advisory to use a node (or pair of nodes) in a particular way is not necessarily a language deficiency.
That brings us to the current case of the To More Specific node. Does it add anything to the language to have a different node that does the type testing? Functionally it would be absolutely the same as the existing To More Specific node, but missing the "object out" terminal. Let's call it the "Is More Specific" node... and I'll refer to them as "Is" and "To" for short. If we have "To", there's no need, functionally, for "Is", as long as people know how to use it. In other words, adding the "Is" node would still leave us with the same problem of teaching people when to use "Is" vs. when to use "To". On the flip side, if we had "Is" in the palettes, it might make people ask the question, "Why do I need this other node when I already have this first node?" That's the effect today with the Inplace Element Structure -- just have the IPE struct makes people question, "When would I ever use this if I have the direct nodes?" So although the "Is" would be noise from a "does it do anything new" perspective, that extra static might make people question, thus aiding with the education problem. On the other hand, if people could always use the IPE, I suspect we would remove the individual nodes from the palettes and send everyone to the IPE always. But there are times when you only want one half of the pair, so the individual nodes stay. In this case, we have a situation where the "To" node would *always* suffice for the "Is" node.
Overall, we are talking about avoiding one object copy. Yes, that might be critical in some domains, I grant, but this is hardly the most exotic tool in the "hide the dots" toolbox. Is it really worth the extra node? I don't know. I'm inclined to say "no", but I suspect some part of me is saying that just because I'd have to take on the work of actually creating that node, which would be a relatively boring task to undertake compared to other things I could be working on, so in this instance, my objectivity is compromised (providing new functionality is almost always more interesting than rehashing existing functionality... I'm sure most of you, as programmers, have experienced that... unless it is someone else's code originally that totally sucks and you get to have great fun ripping out the ugliness).
So, that's my arguments for/against the "Is" node.
Roughly speaking, the text equivalent of the sample Stephen posted is:obj response; response = ToMoreSpecific(Parent,Child); if isNotError(response) { response = ToMoreSpecific(Parent,Child); response.setValue(54); }; [/CODE]I'd say a better equivalent is this:
[CODE] Error err = ToMoreSpecific(object, targetType, NULL); if (err == noError) { Child *child; ToMoreSpecific(object, targetType, &child); child.setValue(54); }[/CODE]-
1
-
-
Read all the documentation about "inplaceness"
My mistake. I thought they were both that way. Thanks, Greg.Before someone times this and realizes it is not true. Although we have some internal support that could someday allow reverse string to be constant time, it is not. Reverse string will actually swap all the characters in the string. Reverse array on the other hand is a constant time operation.
-
Option 1, the sentinel value, is having an input that is a uInt32, where 0 means "never set" and all positive numbers are valid input. There are variations on this theme, like using -1 to mean "infinite timeout" on various primitives in LabVIEW.
Option 2, clustering the data with a boolean, can be done just as well with a LabVIEW class and provides a better enforcement mechanism: Suppose you create a private data cluster of an integer and a boolean where the boolean means "Initialized", which defaults to False. The "Write Numeric.vi" could assign the integer and turn on the boolean. The "Read Numeric.vi" could return an error if the boolean was never set. With a plain cluster, you have the possibility of someone not checking the boolean and going straight to unbundling the integer.
For those of you who believe in the Tooth Fairy and other mythical creatures, an Option 4 would be to write an XNode, which can script different behavior if a terminal is unwired. But like all unreleased features, a certain amount of faith is needed to believe in that solution.
-
Yes, and this feature was discussed... and rejected since inlining doesn't prevent a VI from being used with the Call By Reference node. Also, very large VIs should not be inlined, and there's a real probability of people turning on inlining on something big just to get a feature like this that could still be better achieved by making it part of the function's signature or making a new type that has sentinel capacity (i.e., a class that has a boolean for "is initialized" and then the rest of the data).We have Inline subVIs now

-
LabVIEW strings are not immutable. The compiler does consolidate and modify. What have I repeatedly said? "Buffer allocation dot is not the same as a copy". A buffer allocation is a place where we can *hold onto* a string. Two string buffer allocations would mean that there are two strings, but we can modify one of them and just swap it into the next position, without making a copy.
All LV data types are mutable and subject to this inplaceness analysis.
For the special case of "reverse a string", we just set a flag on the string that says "this string should be traversed in reverse", so it is a constant time operation.
-
I found some commentary online, unrelated to LabVIEW, suggesting that Symantec doesn't like being locked out -- it might be a program trying to avoid detection. I wonder if the Timed Loop could be causing Symantec to think it is being locked out.
-
- Popular Post
- Popular Post
That's a super neat thing to know. But it leads me to the quesiton: how can I do that in *my* code?Write your own compiler.
-
4
-
because the first thing I did was open it and turn them off, which led me to examine other options.
*laugh* Can I add that to the list of advantages from large icons for new users? :-)
-
1
-
-
There are two sources for this error. The most probable is a bug in LabVIEW of some sort. The less probable, but worth checking, is a Call Library Node in your own code that is calling a poorly written DLL or a poorly configured Call Library Node that doesn't match what the underlying DLL is doing. The memory manager can be messed up if a DLL modifies a piece of memory that LV did not expect it to modify.
If you aren't using DLL calls or if you already checked them for correctness, then it's probably an issue inside LV. The correct action at that point is to contact an NI Application Engineer (through the forums or by phone if you have a support contract) and see if they can debug what's going on. They can escalate a CAR and may be able to provide a workaround.
-
1
-
-
- Popular Post
- Popular Post
I posted a small tidbit of useful info over on ni.com for those of you who like to squeeze every drop of performance out of your LV code. This tidbit involves avoiding data copies when doing type testing on objects:
-
3
-
It's kind of true thanks to the way objects are encoded. When designing the flattened data format of LV classes, I really didn't give any consideration to someone deliberately mucking about with the string. That could have meant a serious problem that all objects would have a backdoor way of setting their values. But -- as several determined hackers have griped at me -- I also tried to minimize the size of the flattened string. As a result, the format of the flattened object shifts to three different forms, default fields are not written into the data at all, and there are various size checks that all must be preserved. All of this means that in many cases, it is tricky to reach into the flattened string -- even using the XML format -- and make changes.As an aside: is this really true? LabVIEW objects can easily be flattened to a string, allowing the external code to manipulate the string, and then unflattened back to an object. So it's no safer than a variant or flattened data. And, hey, Shaun has an encryption package, so he could provide an encrypted, flattened string, which is more protected than a LabVIEW object.
Honestly, I made a big mistake in making the Flatten To String and Flatten to XML primitives work on objects by default. The other major programming languages of the world all require classes to opt-in to such abilities. They are not serializable (meaning "can go to/from string") by default. The only ones that are serializable are the ones that programmers declare that way deliberately, and then they have code in the unserialize method to check for tampering, if the class has critical internal data relationships that must be maintained. We lack any such hooks in LabVIEW. It's one of the few areas of LV classes that I wish I could retroactively redesign.
-
This appeared on the Idea Exchange last week.
Pause on first Error - option for debugging
http://forums.ni.com...g/idi-p/1751590
Why only 10 kudos? The page has had more views than that. When I saw this, I immediately thought of all the times I had tried after the fact to decipher a call chain or gone into a VI and deliberately deleted all my error wires just so that Automatic Error Handling would trap my error on the spot. If this worked like an Execution Highlighting button on the button bar, I think it would be great. Thus, I'm posting this idea here on LAVA to give it a second chance at exposure.
-
I read both Atlas Shrugged and the Fountainhead soon after I started my business.
May I suggest you find a book called "Beggars in Spain". It is, like Atlas Shrugged, fiction wrapping philosophy, and it is both a counter and an evolution to the Rand ideas.
-
Yes. Pantomime is far more important as a skill. Trust me: knowing the right gestures helps communication between LabVIEW architects.Don't get too hung-up on terminology. It's a graphical language after all.
-
1
-
-
One thing the page does not mention: TestStand cannot directly invoke dynamic dispatch VIs. You must create a static dispatch VI as a wrapper for the dynamic dispatch call. This limitation is expected to be eliminated in the next version of TestStand.
-
> is this functionality exported in any way that we can take advantage of it in classes?
Not currently. Those are marks on properties of C++ classes. The LV classes have no such designation. Not a bad suggestion. I'm guessing this would be a property you would set on the Property Folder, not on the VIs themselves. It would be up to you to still recolor the icons of the VIs if they were being used somewhere directly instead of through the property node. We could do it on the VIs, I suppose, but at that point, I'd want a much broader feature for deprecating VIs generally that had nothing to do with classes.
Hmm... would you ever want to deprecate only the read or only the write half of a property? If that's a use case, it might be better to be on the VIs themselves.
Anyway, think about it, and then throw it on the Idea Exchange. It's a worthy suggestion but not one I've contemplated before. I'll ping Mr. Mike on this topic... he is the member of my team that owns the property node interfaces.
-
2
-
-
Could you just draw the image in a Picture Control and then change what you're drawing there? Or are you actually needing to edit a whole bunch of VIs to change one image for another (like, say, a corporate logo changing) ?
Intercepting slide range change
in LabVIEW General
Posted
Another variation that works for almost all similar situations is to have a separate loop that just polls every 100ms or so, comparing the last known value (in shift register) to the current value. If it detects a change in the value, then it fires a User Event. This allows your main event loop to not have to have the shift register logic inside of it, making it easier to add/remove the handling for additional scales or other run-time-changeable properties. Yes, it is a polling loop that is continuously running, but in the vast majority of VIs intended for the user to actually see, it has no human-noticeable impact on the responsiveness of the UI.