

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
- Popular Post
- Popular Post
LAVA: Where heated debate produces violent eruption of new ideas.
LAVA: Spewing new ideas, shaking up old ones
-
 3
3
-
A lot of people seem to miss the fact that adding a default case WILL NOT make the VI behave the way Justin wanted it to work. A default case would mean an event fired, which would mean the timeout case would not fire. Making the timeout and the default case be the same case would mean that the timeout case would fire far more frequently than it should. The conversation about possible changes to this behavior appears to think that adding a default case would fix this issue. It wouldn't. Adding a default case just makes it clearer what is going on with the event structure... it does not give the behavior Justin tried for.
With regard to the default case, Fabiola, you argue against changing the behavior because it would break older VIs. If you read my post again, you'll note that I included "mutate older VIs to add the default case", so they wouldn't change behavior at all.
-
In that case you just close the refnum after you make the start async call. I believe passing off a secondary reference to the asynchronous VI is handled automatically, I have at least confirmed closing the refnum you have access to does not cause the VI to return.
I discussed this point further with JCase: The behavior of the Start Asynch Call By Ref node is identical to the Run VI method when you pass true for the "autodispose reference" parameter, with one minor exception. With Run VI, if you proactively call Close Reference, then the other VI will quit unless the VI has some other reason to stay in memory (another reference has been created or the panel is open). With SACBR, if you close the reference, it has no effect on the running VI.
-
Here's a list of ideas that just appeared on the Idea Exchange... they're all from a user "jcase", whose name is in blue, meaning he's an NI employee. JCase is the main developer of the new ACBR feature. As you might guess from the list of ideas, he sees a lot of ways that the ACBR could be extended in the future...
Allow Remote Asynchronous Calls
Allow Asynchronous Call By Reference with Strict, Static VI Reference
Add Asynchronous Call By Reference to Call Setup Dialog
Typeless Call By Reference and Asynchronous Call By Reference
Add Timeout Input to Wait On Asynchronous Call Node
Integrate Asynchronous Call By Reference with Event Structure
-
1
-
-
- 0x80 -- Target VI lifetime independendent of the calling VI.
ie: Closing the reference will not abort the target VI. The target VI will stay in memory until it finishes.
I assume the caller should close the VI RefNum after calling Start so that the launched VI doesn't stay open. Yes?
- 0x80 -- Target VI lifetime independendent of the calling VI.
-
Hm... In this case, I'm a user as much as you are, and I didn't see that note, so I just assumed the 0x108 would work... and it seems to do so.

I will see if I can get one of the developers to chime in.
-
Both systems -- to wait for a specific clone or to wait for any arbitrary clone -- are possible. Here's how to do the "wait for a specific clone." Save both of these VIs to the same directory, then run Caller2.vi. That will launch three copies of the async VI. No matter which order you click stop on those three copies, you'll always get the result "0, 1, 2" in the final array because they're collected in order. Note that this example uses the 0x8 flag -- you were wondering why there was a new flag... it's to support the other use case where you don't care about the order.
I've got to say I really don't understand the decision to have the methods work like this.The case when you don't care which instance you get back is when the output of the instance tells you what position in the final output that instance has. Think of an autoindexing output tunnel on the parallel For Loop -- it runs a whole bunch of frames in order, and then puts the outputs into a single array. Each parallel instance knows where in the final array to end up, so it doesn't matter which one finishes first and copies its results into the final array. There are many use cases where that's useful with spawning multiple copies of the Asynch Call By Ref node and then catching them in whatever order they finish.
-
Sorry for been a nitpicker... but is the non propagating errorcluster implemented on purpose?
Functionally irrelevant to propagate or not since it is guaranteed to be "no error" in that case. But connecting it through will sometimes give LV the opportunity to use a single allocation of the error cluster all the way through the app, which cuts down on the size of the VI in memory (by a few bytes), so I usually do wire it.
-
Unless I'm missing something, these are pretty fundamentally different patterns. The Symbio one focuses on method calls to by-reference objects [aka synchronous messages] while the Active Object focuses on message passing and announcements [aka asynchronous messages]. Although the two can be mixed, there's a huge amount of distinction in how to build up an application from scratch depending upon which one you're relying upon. I would not call these the same thing at all.I just update an Active Object/Design Pattern video showing how I implemented Active Object in Symbios's DVR class.
http://goop.endevo.n...DesignPatterns/
//Mike
Am I correct in my analysis here?
-
Yet Another Messaging System...
In my NI Week presentation on "Trends in LabVIEW Object Oriented Programming", one of the trends is the development of object-based communications schemes that modify the traditional queue-based-state-machine architecture. I'm mentioning Actor Framework, JAMA, and LapDog. Are there others that need mentioning?
-
Move Australia closer.Yer, that sounds like a great idea. It's just a long way coming from Australia.

-
1
-
-
I agree with the first reply: Make it a strict typedef.
-
I will be there, and I've talked a few other members of LV R&D to come along, including a couple of new faces. These are folks who aren't loaded to the gills already with projects and features they already support, so they're a good target for your lobbying efforts.
-
You also need to configure the VI Properties >> Appearance page to be a floating window if you want the "don't take key focus when interacted with" behavior that the LV palettes have.
-
1
-
-
I theorized that it would be beneficial for backing out edits. I make an edit to the class that removes a field. I save the class. I realize, oops, I want that back. Add it back in. But to the mutation code, this looks like "delete the data and add a new field with default values." Editing the mutation history would let you address changes like that so that the middle step you record as having no real changes (assuming you don't actually have any flattened data saved at that middle step).So that leaves my other question unanswered. Other than deleting records to reduce the class file size, are there any use cases where editing the mutation history would be beneficial? -
- Popular Post
- Popular Post
That has been fixed in LV 2011. As you may guess, someone whose name is *not* in that error message decided to use index zero. That someone has been made to apologize deeply.Hi,
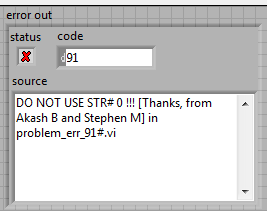
I was trying to track down a strange error in a library function and got the following:
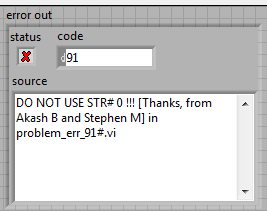
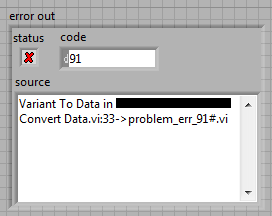
For debugging I had to disable VI inlining and the error changed in something more meaningful:
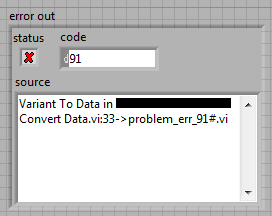
Basically the problem was a parse error resulting in a wrong variant to data conversion (path to i16).
I wonder who is "Akash B" and "Stephen M". About the latter I have a guess
 .
.
-
3
-
Three words: Source Code Control.What I'd like to do is create a tool that helps the developer recreate class C so the persisted data is not lost forever. -
Nope.Isn't the actual former name necessary information in the mutation history?Contained class and container class --- when one class has another class as a member of its private data control, the one in the cluster is the contained class and the other one is the container class.
Child classes and container classes include in their own flattened data the data of another class -- the parent class and/or the contained class. When a class is renamed, its version number resets to 1.0.0.0. It could then be edited, moving its version number forward. If another class has written down a version number of 1.0.0.1, that version number might be the way the class looked before the rename or after the rename. The child and container classes have a name index recorded in their mutation history that lets them figure out which mutation record of the renamed class is the right one to use.
When you rename a class (say rename "Old" to "New"), the only other classes that can take advantage of the mutation are classes that are in memory at the time that the class renames. Child classes and container classes have the renamed class as part of their flattened data. When the renamed class changes name, those classes update their inheritance records or their cluster records to note that they are aware of the rename. They don't actually care about the name at all. All they need to know is that the version number that they wrote down in their flattened data is not a *current* version number, but is instead a version number from before the last reset of the renamed class.
For the record, you can always open the .lvclass file in a text editor, find this tag:
<Property Name="NI.LVClass.Geneology" Type="Xml">
and delete that tag and everything through the matching
</Property>
tag. That removes the mutation history entirely and is always safe to do.
It's good speculation. When you reset the version number manually, you need to delete the geneology records entirely because there's no way you can update them by hand to account for the rename (which means updating the name index, and modifying all the existing records to note that they are for the previous name).This is pure speculation, but my guess is manually forcing the version to 1.0.0.0 has created a conflict. If there are relatively few classes, I'd try doing a Save As on all your classes so LV sets them back to 1.0.0.0 itself.
-
I talked to Rob... I pointed out that he is the father of the JAMA architecture, and I asked permission, and he said, yes, we can therefore refer to him as "Pa JAMA".
-
1
-
 1
1
-
-
Looked at from that standard, the child is actually analyzing the situation quite correctly -- it isn't fair that they have to go to bed and you don't. For it to be fair, they would have to factor in that they will get to play under the different rules eventually, but then, even that isn't fair because you were given a head start.Adults and children operate under a different set of rules; therefore, the microcosm of parent-child interaction is indeed unfair.I recently heard another variation on this, one from a teenager. His parent was preventing him from going to an event where there was likely to be drinking, which he saw as unfair because he hadn't done anything (yet) for the parent to accuse him of participating in drinking. It was punishment before the crime, from his point of view.
-
Yes, but now you and Daklu are educated users... exactly the sort of folks that I've been hoping for a long time would take my under-the-hood VIs and write some sort of nice editor for manipulating the mutation history. :-)Hitting "apply" after I have made any typedef/class changes terrifies me at the moment as it seems so easy to nuke everything. -
It would also require changing the flattened data format of typedefs (so that the data records a name and a version number instead of just the data). That's a pretty big change.That would definitely be interesting... if the only reason why typedefs don't carry a mutation history is because the class isn't always loaded as you change it, then it would be good to implement it for typedefs that are part of a class, indeed.Even if "not in memory" were the only issue, I believe typedefs should behave like typedefs regardless of where the typedef is located in a source project. I don't want people putting typedefs that were unrelated to a given class into the class just to get the mutation as a side-effect. And there are people who like that typedefs do not store the history -- witness the size problems with LV classes that another user on the LAVA forum was having last week. The mutation history is this magical data store that continuously builds up over time. There are many who argue that it was a mistake for classes to add this ability because it is an unbounded resource (although we only unflatten the history if you actually start reading flat strings from earlier class versions).
Unless typedefs as a whole change, I would not recommend changing how they behave when owned by a class.
-
There's a fairly key resource maintained on ni.com:
Lots of good info on that page, but the real gem for me is the link "Read technical series". Anyone writing any significant VI hierarchy should have at least browsed this encyclopedia, just so you know that it exists when you have a specific question.
-
1
-
-
In alphabetical order (all of these are non fiction):
Closer To The Machine by Ellen Ullman [out of print; may be able to find used]
Computer Ethics by Deborah G. Johnson
Godel, Escher, Bach by Douglas R. Hofstadter [Pulitzer prize winner]
The Programmer's Stone (only available online HERE ) by Alan Carter
None of these mentions LabVIEW. None of these includes any algorithms or code snippets. All of them address the deeper rules of the game for software engineering, from why we do what we do, to how to interact with non-engineers, to how to get your mind to think like a computer without losing your humanity. I also recommend that all programmers read Alice in Wonderland and Through The Lookingglass because whether your like the stories or not, there are a LOT of allusions to those texts in computer science literature; those books provide some useful terms and settings that can be used for analogies from time to time (i.e. "the red queen's race", to describe spending large amounts of energy just to maintain the status quo).
-
1
-
[Article]What are you working on today?
in LabVIEW General
Posted
I've mostly been working for a research group that studies new types of scintillators for radiation detectors. My most recent finished project was adding the capability of measuring "Thermoluminescence" to an experimental setup previously used just for another type of measurement (pulsed X-ray luminescence). Part of that was adding Thermoluminescence-data display to a database viewing program that wrote earlier to allow the researchers to look at all the various measurements held in the database:
View attachment: CsI.png
-- James
Click here to view the article