Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
207
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Aristos Queue
-

VI inlining changes error message!?!
Aristos Queue replied to Götz Becker's topic in LabVIEW General
That has been fixed in LV 2011. As you may guess, someone whose name is *not* in that error message decided to use index zero. That someone has been made to apologize deeply.- 1 reply
-
- 3
-

-
Three words: Source Code Control.
-
Nope. Contained class and container class --- when one class has another class as a member of its private data control, the one in the cluster is the contained class and the other one is the container class. Child classes and container classes include in their own flattened data the data of another class -- the parent class and/or the contained class. When a class is renamed, its version number resets to 1.0.0.0. It could then be edited, moving its version number forward. If another class has written down a version number of 1.0.0.1, that version number might be the way the class looked before the rename or after the rename. The child and container classes have a name index recorded in their mutation history that lets them figure out which mutation record of the renamed class is the right one to use. When you rename a class (say rename "Old" to "New"), the only other classes that can take advantage of the mutation are classes that are in memory at the time that the class renames. Child classes and container classes have the renamed class as part of their flattened data. When the renamed class changes name, those classes update their inheritance records or their cluster records to note that they are aware of the rename. They don't actually care about the name at all. All they need to know is that the version number that they wrote down in their flattened data is not a *current* version number, but is instead a version number from before the last reset of the renamed class. For the record, you can always open the .lvclass file in a text editor, find this tag: <Property Name="NI.LVClass.Geneology" Type="Xml"> and delete that tag and everything through the matching </Property> tag. That removes the mutation history entirely and is always safe to do. It's good speculation. When you reset the version number manually, you need to delete the geneology records entirely because there's no way you can update them by hand to account for the rename (which means updating the name index, and modifying all the existing records to note that they are for the previous name).
-
Message Routing Architecture
Aristos Queue replied to Mark Balla's topic in Application Design & Architecture
I talked to Rob... I pointed out that he is the father of the JAMA architecture, and I asked permission, and he said, yes, we can therefore refer to him as "Pa JAMA". -
Looked at from that standard, the child is actually analyzing the situation quite correctly -- it isn't fair that they have to go to bed and you don't. For it to be fair, they would have to factor in that they will get to play under the different rules eventually, but then, even that isn't fair because you were given a head start. I recently heard another variation on this, one from a teenager. His parent was preventing him from going to an event where there was likely to be drinking, which he saw as unfair because he hadn't done anything (yet) for the parent to accuse him of participating in drinking. It was punishment before the crime, from his point of view.
-
Yes, but now you and Daklu are educated users... exactly the sort of folks that I've been hoping for a long time would take my under-the-hood VIs and write some sort of nice editor for manipulating the mutation history. :-)
-
It would also require changing the flattened data format of typedefs (so that the data records a name and a version number instead of just the data). That's a pretty big change. Even if "not in memory" were the only issue, I believe typedefs should behave like typedefs regardless of where the typedef is located in a source project. I don't want people putting typedefs that were unrelated to a given class into the class just to get the mutation as a side-effect. And there are people who like that typedefs do not store the history -- witness the size problems with LV classes that another user on the LAVA forum was having last week. The mutation history is this magical data store that continuously builds up over time. There are many who argue that it was a mistake for classes to add this ability because it is an unbounded resource (although we only unflatten the history if you actually start reading flat strings from earlier class versions). Unless typedefs as a whole change, I would not recommend changing how they behave when owned by a class.
-
There's a fairly key resource maintained on ni.com: http://www.ni.com/LargeApps Lots of good info on that page, but the real gem for me is the link "Read technical series". Anyone writing any significant VI hierarchy should have at least browsed this encyclopedia, just so you know that it exists when you have a specific question.
-
In alphabetical order (all of these are non fiction): Closer To The Machine by Ellen Ullman [out of print; may be able to find used] Computer Ethics by Deborah G. Johnson Godel, Escher, Bach by Douglas R. Hofstadter [Pulitzer prize winner] The Programmer's Stone (only available online HERE ) by Alan Carter None of these mentions LabVIEW. None of these includes any algorithms or code snippets. All of them address the deeper rules of the game for software engineering, from why we do what we do, to how to interact with non-engineers, to how to get your mind to think like a computer without losing your humanity. I also recommend that all programmers read Alice in Wonderland and Through The Lookingglass because whether your like the stories or not, there are a LOT of allusions to those texts in computer science literature; those books provide some useful terms and settings that can be used for analogies from time to time (i.e. "the red queen's race", to describe spending large amounts of energy just to maintain the status quo).
-
Variant attribute list always sorted?
Aristos Queue replied to Götz Becker's topic in LabVIEW General
The list should always be sorted. I have filed CAR 308287 to update the documentation accordingly. -
Your post here prompted me to take another look... I'm now inclined to call this a bug. I'm never sure how to read feedback nodes that are initialized... To my eyes, when the loop executes each iteration, that variant constant is going to generate something and send it to the initializer node. The fact that the initializer chooses to do nothing with it is its problem. It's one of the reasons that I don't like feedback nodes at all, especially inside loops. In LV2010, I know we got new optimizations to improve dead code elimination and loop unrolling, so I figured this was covered by those optimizations. But I tried a couple of other feedback nodes in a loop and didn't see the same slowdown, so maybe it is a bug that is variant specific.
-
Not quite fair to call it a bug in LV2009. We added new features to the compiler to do deeper optimizations in LV2010, which gave us better performance than we've had before. A bug would be something that got slower in a later version. This is just new research giving us new powers.
-
No, it doesn't. And neither does the...
-
Or, rather, the typedef is treated as a single element by the class. Since the class may or may not be in memory when the typedef is edited, the class can only know "this version of the typedef changed to this version" and it does the same "attempt to maintain value" that you get on a block diagram constant -- which sometimes means resetting to the default value.Except for enums, I pretty much avoid mixing typedefs into private data controls these days. It wasn't something I avoided when classes first entered LV, but these days, I find it easier to avoid them.
-
Allow me to introduce you to LabVIEW 2011. It... huh? Oh... I can't talk about that yet? Seventeen more days? Well, ok... but you're not going to keep a secret like the Asynch Call By Reference node quiet for ever. ... anyway, there's help coming. I have. In the Actor Framework that I posted as part of my NI Week 2010 presentation. That's why we've made changes to the framework using LV 2011, where we have the Asynch *mmmffph mmmph oooph argh* No, really, I'll stop talking about it. I promise. Really. Just stop the beatings. I can wait 17 days...
-
The emphasis on architecture choice is more in the CLA, not the CLD. The CLD focuses on getting the app working and documenting what you did so clearly that someone else can pick up your app and figure out what you did. If two engineers reviewing the code missed the core of your app, I gotta say that does suggest some weakness in the documentation department. On the other hand, I've had days where I "just can't see the Matrix" and no amount of staring at the code makes it make sense. ;-)
-
It does change, regularly. But then we bring in a new crop of interns and new hires, and the process of untraining them from their C++/C#/JAVA faith and indoctrinating them with dataflow begins anew. Some never learn; others do. :-)
-
Just write an empty array to clear the mutation history. But the version number is never allowed to be set backwards because even with the version number wiped out, there could still be data out there of the earlier version number, and that needs to return a "this data is too old to be inflated" error. Only "Save As >> Rename" sets the version number back to 1.0.0.0.
-
I strongly hope not, because the more it moves away from wires the less optimal and the more failure prone applications written in the language become. Your time table here is a bit messed up, but I understand your point. I don't think that bundling and dynamic dispatch belong in your list, however. There's a difference between representing the wire in an alternate form (bundle is several wires all routed together; dynamic dispatch is equivalent to a case structure around a number of subVI calls) and abandoning the dataflow syntax entirely (I'm looking at you, Shared Variable). And, more important than all of that... my whole reason for asking for this thread to start in the first place... is that I think any drift away from wires is unnecessary, but it is seen by many as necessary because of the architectures we favor today. Those architectures are the problem that I'm wanting us to address. Whether or not you can successfully use variables and DVRs is irrelevant to this conversation, IMHO, because I believe you can use wires equally as well or better if we structure them correctly and I know that the compilers, debuggers, and analyzers can definitely handle wires better, so it behooves us to prevent as much drift as possible.
-
As I said before:
-
Neither have I. *pointed look at all of you*:-)
-
Yes. Each Event Structure has its own events queue, and it dequeues from that queue in the thread that it is executing that section of the VI. The default is "whatever execution thread happens to be available at the time", but the VI Properties can be set to pick a specific thread to execute the VI, and the Event Structure executes in that thread. The "Generate User Events" node follows the same rules -- it runs in whatever thread is running that part of the VI. UI events are generated in the UI thread, obviously, but they're handled at the Event Structure. A good prejudice to have, generally. But I have to ask... why wouldn't you use the same event structure to handle both? The Event Structure was certainly intended to mix dynamic user events and static UI events handling, and it works really well for keeping that behavior straight. And if the two event structures are handling completely disjoint sets of user events, that's one of the times when the prejudice can be relaxed without worry. Not that I've ever seen a reason to do this, but it would be ok.
-
No, they don't.
-
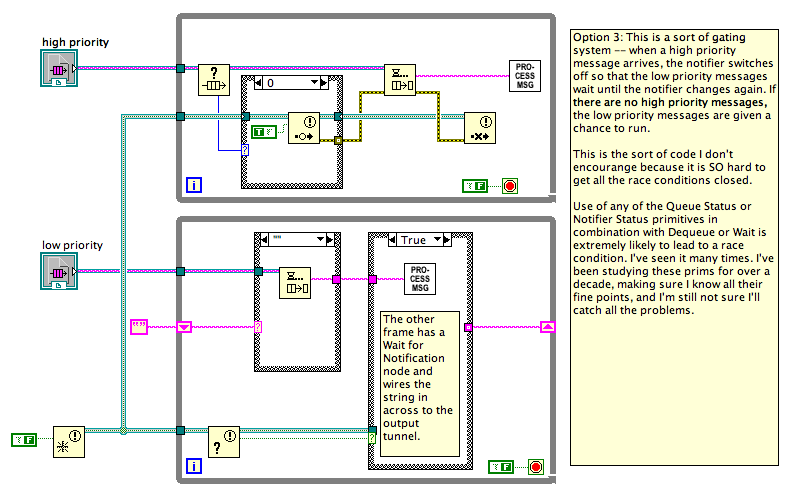
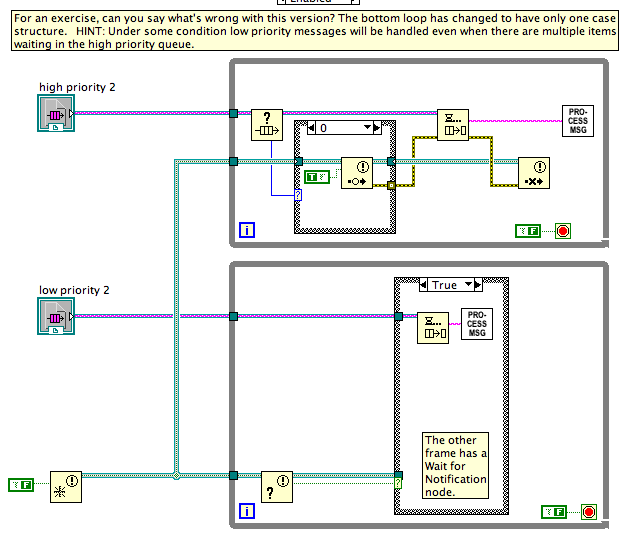
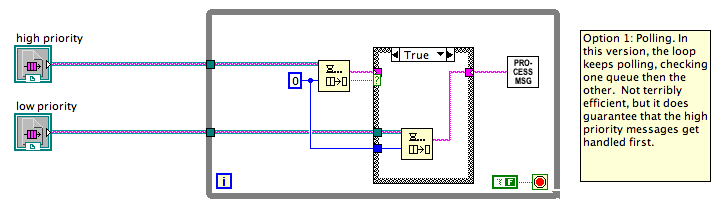
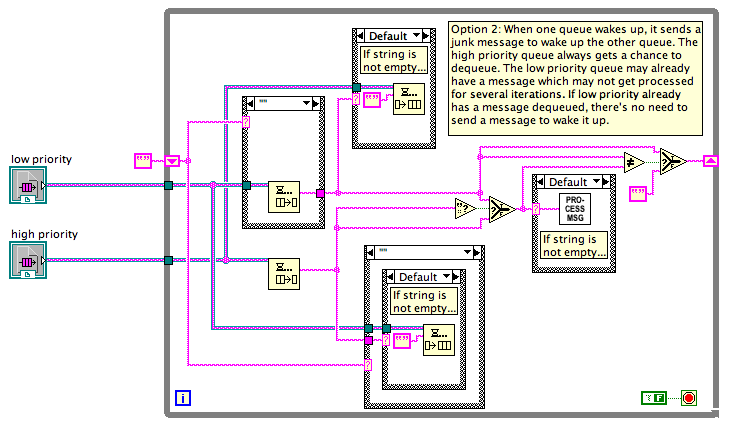
The question originally came up because it's hard to teach Notifiers to beginning LV programmers. It's a lot simpler to teach local variables, which do often work for stopping two loops on the same diagram, albeit with some difficulty around a button's mechanical action. Surely there must be a quick-to-program, easy-to-understand way to stop two parallel loops? It's a question I've asked myself for years, but only recently undertaken trying to identify why it is so frigging hard (compared with the expected level of difficulty) to see if a better pattern could be found. Ten points and a bowl of gruel to Shaun for hitting on the core point!Here are three possible solutions to what Beta.vi could look like: All solutions I've seen to this problem are either extremely messy or extremely inefficient (because they poll instead of sleep). In my experience, this sort of mess crops up whenever you try to mix multiple communications channels -- either you end up polling all of them, you end up having some complex "wake everyone up when one wakes up" scheme, or you have sentinel values to give time to each one (this last not being an option if all channels are equal priority). A good architecture rule appears to be "Between any two parallel loops Alpha and Beta, there should be one and only one communication channel from Alpha to Beta (there's a separate conversation to be had about whether communication from Beta to Alpha should use the same or a separate communications channel). The rule "there should be only one communications channel from Alpha to Beta" implies that the right way to stop two loops is not a fixed answer. If you say, "Use notifiers to stop the loops", that would imply you should only ever use notifiers to communicate between loops, which is daft. Instead, the right way to stop two loops is to use whatever communication scheme you've already got between the two loops. If there isn't any then, yes, Notifiers are probably the simplest to set up and get right for all use cases (including the quite tricky "stop both loops and then restart the sender loop but only after you're sure that both loops stopped"). But if you have an existing queue/event/network stream/etc, then use that. Using the same channel does not necessarily mean tainting your data with a sentinel value for stop. The pattern of "producer calls Release Queue and the consumer stops on error" is an example of using the channel. Complete and total tangent: Option 3, as I say in my comments, is the sort of code I generally discourage people from trying to write. Mixing the Status functions with the Wait functions (meaning Dequeue, Wait for Notifier, Event Structure, etc) is a perfect storm for race conditions and missed signals because the Status check and starting the Wait are not atomic operations. Here's a slight variant of Option 3, but this variant doesn't work... there are times when a low priority message will be handled even when there are multiple high priority messages waiting in the queue. This is my diagram, but it is based on some other code I've been shown that tried to do this, and it looked right to the author.

-
iPhone like password string XControl
Aristos Queue replied to Antoine Chalons's topic in Code In-Development
Use the example I provided a few years back for the Scrolling LED XControl. That gives you a pattern for forcing an update of an XControl based on timing. https://decibel.ni.com/content/docs/DOC-1180