Mefistotelis
-
Posts
100 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mefistotelis
-
Yes. Extract your file, and paths will be in XML. "LVPath" is actually a class, which is instantiated for many things. So all paths basically have the same structure. I export it to XML as list of strings - this is how it is really stored. Elements in the list are either normal strings, or tags which LV replaces with value from current config. Example: <LIvi> <!-- LinkObj Refs for VI --> <Section Index="0" Format="inline"> <LVIN Unk1="NI_InternetTK_Common_VIs.lvlib:Close Calling VI's Windows.vi" Unk2=""> <!-- VI To Lib Object Ref --> <VILB LinkSaveFlag="2"> <LinkSaveQualName /> <LinkSavePathRef Ident="PTH0" TpVal="0"> <String><vilib></String> <String>addons</String> <String>internet</String> <String>NI_InternetTK_Common_VIs.lvlib</String> </LinkSavePathRef> </VILB> </LVIN> </Section> </LIvi>
-
Thanks @Rolf Kalbermatter, did proper update. Watcom actually had Windows extender, separate to the DOS extender. Also, interesting prediction. Personally, I think Apple overestimates scalability of their phone silicon. But we'll see.
-
Export data from LabVIEW to Excel (.CSV) in real time
Mefistotelis replied to Grv Chy's topic in LabVIEW General
What you want is to flush your output file occasionally. File writes are buffered, and performed only when enough data has gathered, or the file is being closed. In C, flushing is done by fflush(); for LV - someone else will have to answer. -
Thank you! That added some important info to my list: https://github.com/mefistotelis/pylabview/blob/master/LVcode.py#L224 A little below the arch list, there's getVICodeProcName() function where I added mangled names for the dispatch table items which I got from LV for MacOS. Pylabview will now, upon extraction of a VI file, create a MAP file with offsets and names of known symbols within the executable bytecode.
-
Do we have a full list of these architectures somewhere? I've seen: 'i386', 'wx64', 'ux86', 'ux64', 'm386', 'mx64', 'PWNT', 'axwn', 'axlx', 'axdu', 'ARM ' (those are all little endians) I'm not exactly sure what each of these means. Are different OSes counted as separate architectures?
-
I just did. Wow. Now I know I was missing a lot by ignoring Apple. At least from this perspective. Not a single function name is missing, and all names are decorated with types.
-
Yes, that's the table. Surprisingly, it's not just written directly as an array, but instead there's an init function which fills it. Sounds a bit unnecessary. And introduces possible security issues. I hope the function is verified before execution, and executed later than when the VI is opened. Otherwise the ease of modification might be an issue. Besides modifying it, you may just want to look at it, to either debug an issue within LV, or just check how the code works. With the declarations and all structs defined, you could also turn the VI code into COFF; that would make it easier to disasseble, or write a wrapper which executes it. That's the same code you can look at in "Heap Peek", but there you get symbols and labels instead of specific offsets. CINs - I don't know much about these ATM, didn't looked into LabWindows at all. Interesting hint. Thanks.
-
Do we have declarations of these callbacks? Ie. here's one: void __cdecl _InitCodePtrsProc(struct VICodePtrsRec **viCodePtrs); Just to explain what I'm talking about: * VI files and other RSRC files, can contain compiled code stored in VICD resource * VICD consists of the actual assembly, and list of 'patches'; these patches combine function of imports table and relocation table * The actual assembly always has a InitCodePtrsProc() function, which sole purpose is to fill an array of code pointers which it receives as parameter * The code pointers are just references to other functions which exist in the assembly; there are up to 30 such callbacks * executing a VI file means just calling these callbacks, in proper order It's not that hard to figure out the parameters of these callbacks, I'm just wondering if we already have that information. Here's example init function for a very simple VI: void __cdecl _InitCodePtrsProc(struct VICodePtrsRec **viCodePtrs) { struct VICodePtrsRec *ptr; _VINormalInitCProcsHelper(viCodePtrs); // Imported routine, pointed in list of patches ptr = *viCodePtrs; *((_DWORD *)ptr + 5) = _InitProc; *((_DWORD *)ptr + 25) = _CodeDebugProc; *((_DWORD *)ptr + 26) = _CodeErrHandlingProc; *((_DWORD *)ptr + 30) = _RunProc; *((_DWORD *)ptr + 28) = _InitCodePtrsProc; }
-
The options are actually in two places: some are in the LV executable, but most are in RSC files within LV folder. The executable you can open with any RE tool, like Ghidra, or Ida Pro. You could also use 'strings' command to list all text chunks from executable, and guess which of these are ini options. The RSC file you can extract using pylabview, and then you get a list of tokens in XML form, ie. there's part of lvapp.xml: <Section Index="11400" Name="ConfigTokenStrings" Int5="0x00000000" Format="inline"> <String>tmpdir</String> <String>defaultdir</String> <String>viSearchPath</String> <String>panel.background</String> <String>diagram.background</String> <String>diagram.primColor</String> <String>menubar.foreground</String> <String>menubar.background</String> <String>menu.foreground</String> <String>menu.background</String> <String>execPalette.foreground</String> <String>execPalette.background</String> <String>cursor.foreground</String> <String>cursor.background</String> <String>appFont</String> <String>systemFont</String> <String>trackTimeout</String> <String>defPrecision</String> <String>flushDrawing</String> <String>formulaBoxPrecision</String> <String>sparcV8</String> <String>windowSize</String> <String>LVdebugKeys</String> <String>useDebugOutput</String> ... In case of the specific key discussed in this thread: # strings LabVIEW.exe | grep SuperSecretListboxStuff SuperSecretListboxStuff Btw, I remember someone from NI suggesting that there is a hidden option, not visible in the simple strings list. That is not true, at least in LV14. Yes, I checked.
-
The worst, but really really rare case, would be for the tool to create damaged binary. But I'm doing a lot of checks to avoid that. And you already stumbled upon some of the checks: The tool does a lot of checks and raises exceptions if anything looks out of the ordinary. The exceptions are then captured and the block which raised them is exported as a binary file, without trying to make it XML. In case of VICD you'll actually always see this, as I didn't published parsing of the data. This means the VICD will just always stay as binary. If you want to be sure the data is identical to source, just go with: ./readRSRC.py -vv -x -i ./lv10/vi.lib/dex/DexPropertyNode.vi ./readRSRC.py -vv -c -m ./DexPropertyNode.xml cmp -l ./lv10/vi.lib/dex/DexPropertyNode.vi ./DexPropertyNode.vi In other words - export the file, then re-create the binary without changes, and compare both binaries. The tool checks whether it can re-create the checksum from your file - after all, it always tries to re-create identical data after export and import. Brute-force scan will happen only on damaged files - where the checksum doesn't match using the usual algorithm. The tool then assumes the issue is in salt. If the tool can't figure out how to re-create the salt used for password, it will export the salt into XML, and won't re-compute it when re-creating binary (unless you modify the XML to re-enable auto-computation). The tool will re-create everything correctly, if only you will modify it in exported form. I could add an option which would make it assume the input file is damaged, and skip that scan. Well, you could use the same code which handles "change password", only replace password work with your fun. But the way to rename blocks using my work model is: 1. Export VI to XML 2. Change the tag name in XML, for example replace "<CLIv>" and "</CLIv>" with "<LIvi>" and "</LIvi>". 3. Re-build the VI from XML Yes, block idents are just the tag names; they are only a bit modified to meet XML standard, ie. "#" are replaced by "sh" and "\0" codes are just skipped; but the tool will re-create the 4-char ident from tag name during import. I see. Yeah, there's no way around that.
-
Well, that's really against what I want to achieve.. my idea is to extract everything to XML and allow users to do all the modifications in XML form. Then you can easily re-create the VI. Note that the re-created VI will, in most cases, be identical to the original (there are few exceptions, as LV uses multiple threads to save the file and is generating names section in pseudo-random order as a result, and in older versions of LV even the section data is ordered randomly). The password option is the only exception to that rule, and I'm thinking about removing it completely. It's untested anyway, so I'm not even sure if it works. For the in-place modifications, you'd have to modify the tool, and make the modifications you want through Python code. All the known checksums are re-calculated when importing from XML. These checksums are not even put into XML, as they're just derivative values which can be re-created. The XML import of a single file takes seconds. Currently I'm testing everything on _all_ RSRC files from 4 versions of LV (6.0, 7.0 10.0 and 14.0), that's over 41 000 of files. Exporting and then importing all of these files takes less than 24 hours. That means export+import of one file takes on average 2 seconds. Did you tried 'Cheat Engine'? It's a tool for cheating in games, which basically means - a tool to edit memory of application. Exactly what you want. And it has a great ability to "find pointer chain" - it allows locating pointers to dynamically allocated memory. If the issue you have is dynamic allocations, and not variable shift within allocated blocks, that might be useful.
-
@dadreamer if you're often looking at the binary data, you might have some use of "print-map" function of my readRSRC script: ./readRSRC.py --print-map=RSRC -x -i 'test_out/lv10/vi.lib/Utility/Convert RTD Reading (waveform).vi' test_out/lv10/vi.lib/Utility/Convert RTD Reading (waveform).vi: Warning: Block b'PRT ' section 0 size is 152 and does not match parsed size 128 test_out/lv10/vi.lib/Utility/Convert RTD Reading (waveform).vi: Warning: Block b'VICD' section 0 XML export exception: The block is only partially exported as XML. 00000000: RSRCHeader[0] (size:32) 00000020: BlockData (size:13559) 00000020: BlockSectionData[LVSR,0] (size:140) 000000AC: BlockSectionData[RTSG,0] (size:20) 000000C0: BlockSectionData[OBSG,0] (size:20) 000000D4: BlockSectionData[CCSG,0] (size:20) 000000E8: BlockSectionData[LIvi,0] (size:52) 000000EC: Block[LIvi,0].LinkObject[0].NextLinkInfo (size:2) 000000EE: Block[LIvi,0].LinkObject[0].Ident (size:4) 000000F2: Block[LIvi,0].LinkObject[0].Unk1 (size:34) 00000114: Block[LIvi,0].LinkObject[0].Unk2 (size:2) 0000011A: Block[LIvi,0].LinkObject[1].NextLinkInfo (size:2) 0000011C: BlockSectionData[CONP,0] (size:6) 00000124: BlockSectionData[TM80,0] (size:64) 00000164: BlockSectionData[DFDS,0] (size:388) 000002E8: BlockSectionData[LIds,0] (size:52) [...] 00003A44: BlockSectionStart[VCTP,0] (size:20) 00003A58: BlockSectionStart[FTAB,128] (size:20) 00003A6C: NameStrings (size:34) 00003A6C: NameOfSection[LVSR,0] (size:34) When you use "--print-map=RSRC" it prints what is stored at which offset of the RSRC file. Obviously it can't print compressed data this way, so for compressed sections you can map the specific section, ie. "--print-map=DFDS". And to get BIN file which matches this mapping, you can extract the VI with "-d" instead of "-x" - then you will get uncompressed BIN files for all sections, instead of some being converted to XML.
-
Heap Peek and other internal debug tools...
Mefistotelis replied to Daklu's topic in LabVIEW General
You can edit that wiki if you have more info. or write your comments in "Discussion" page if you're unsure about editing it directly. I created a whole category of articles there: https://labviewwiki.org/wiki/Category:LabVIEW_internals -
What do you think of the new NI logo and marketing push?
Mefistotelis replied to Michael Aivaliotis's topic in LAVA Lounge
Well, looks like it's something more than graphics switch. New bugs! I wonder how many "expected" errors happened in the meantime.
-
What do you think of the new NI logo and marketing push?
Mefistotelis replied to Michael Aivaliotis's topic in LAVA Lounge
I wonder what is the reason of the rebranding.. maybe reductions are coming? Not a good look if they now share the logo with a company which makes waste bins.. overpriced ones. -
My intent for 'readRSRC' is to have only two functions: - Extracting RSRC, without changes, with as little raw binary data as possible - Re-creating RSRC from extracted data, creating file identical to the one before extraction So any modifications to the file would have to be in a separate script. Like the one I made for recovering Front Panel - 'modRSRC' (I will probably rename it to fixRSRC at some point). But readRSRC should convert the DATA0 section to XML - that I might do at some point (assuming I will continue to support it long enough).
-
ATM my tool doesn't treat the DATA0 section as VCTP, so it only extracts it to BIN file (it does decompress it already). If you rename the section to VCTP, re-pack and re-extract, it should treat that as VCTP data and if the format is identical to "normal" VCTP, it will get converted to XML. Dividing the section into parts for each VI should be a bit easier in XML form. Also, worth checking if the whole section can be just put inside each VI. I didn't checked if references to individual types within VIs are increased within lvlibp to refer to entries in the DATA0 section; if they are, dividing DATA0 would also require updating all TypeID references.
-
Ok, here's what I did: I found a lvlibp file in my LV14 installation, and extracted it: $ file lv_icon.lvlibp lv_icon.lvlibp: PE32 executable (DLL) (GUI) Intel 80386, for MS Windows $ wrestool -x --raw lv_icon.lvlibp -o ./ $ ls -l lv_icon* -rwxr-xr-x 1 mefisto None 5377536 2014-06-25 lv_icon.lvlibp -rw-r--r-- 1 mefisto None 5375712 06-10 12:47 lv_icon.lvlibp_10_2_0 -rw-r--r-- 1 mefisto None 704 06-10 12:47 lv_icon.lvlibp_16_1 Then checked the RSRC file from inside: $ file lv_icon.lvlibp_10_2_0 lv_icon.lvlibp_10_2_0: National Instruments, $ ./readRSRC.py -x -i 'lv_icon.lvlibp' Error: [Errno RSRC {:d} Header sanity check failed.] 0 So, I never tried that before, and my tool doesn't currently support these files. But it should be an easy fix, so I will patch it and get back to you with more info. For fixing 'tampered with password' message - what I do is just removing the file from library when in extracted form (can't remember exactly, but I think 3 changes are required, one of them is removal of the LIBN which you mentioned). Btw, NI is inconsistent here - they say the password is just 'unintended modification' avoidance, but the 'tampered' message suggests the intent for creating that functionality was to provide some impression of security. EDIT: Fixed it! Now I'm getting: $ ./readRSRC.py -vv -x -i 'lv_icon.lvlibp_10_2_0' lv_icon.lvlibp_10_2_0: Starting file parse for RSRC extraction lv_icon.lvlibp_10_2_0: Block 'LVzp' index 0 recognized lv_icon.lvlibp_10_2_0: Block b'LVzp' max data size set to 5273600 bytes lv_icon.lvlibp_10_2_0: Block b'DATA' max data size set to 5375472 bytes lv_icon.lvlibp_10_2_0: Writing block b'LVzp' lv_icon.lvlibp_10_2_0: Storing block b'LVzp' section 0 binary in 'lv_icon_LVzp.bin' lv_icon.lvlibp_10_2_0: Writing block b'DATA' lv_icon.lvlibp_10_2_0: Storing block b'DATA' section 0 binary in 'lv_icon_DATA0.bin' lv_icon.lvlibp_10_2_0: Storing block b'DATA' section 1 binary in 'lv_icon_DATA1.bin' lv_icon.lvlibp_10_2_0: Storing block b'DATA' section 2 binary in 'lv_icon_DATA2.bin' lv_icon.lvlibp_10_2_0: Storing block b'DATA' section 3 binary in 'lv_icon_DATA3.bin' lv_icon.lvlibp_10_2_0: Storing block b'DATA' section 4 binary in 'lv_icon_DATA4.bin' lv_icon.xml: Writing binding XML The ZIP is auto-decrypted, so we can now extract it: $ file lv_icon_LVzp.bin lv_icon_LVzp.bin: Zip archive data, at least v2.0 to extract # unzip lv_icon_LVzp.bin Archive: lv_icon_LVzp.bin extracting: NI_Embedded_Library.xml extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Read Boolean.vi extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Read Color.vi extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Read String.vi extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Write Boolean.vi extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Write Color.vi extracting: 1abvi3w/resource/dialog/lvconfig.llb/LV Config Write String.vi [...] Will update after I look at the files I got. EDIT2: Looked at the files: The only real issue is lack of VCTP section. The rest of removing the VI from library is trivial, if you check how the file looks before and after compiling the library. VCTP sections from all files seem to be merged together (after all it stands for VI Consolidated Types), and stored in DATA resource of index 0. That resource is then compressed with ZLIB. Looks like DATA0 is zlib'ed, while DATA1+ are not. I will have to update the tools to handle a situation where the same resource ID has compressed and uncompressed sections. ps. If anyone wonders about the strange shortcuts we're using, I've made a wiki page on this: https://labviewwiki.org/wiki/Resource_Container
-
I'd understand if you wanted to hide your application, but hidding LV itself? Is there even a command line interface to LV? Isn't LV unusable in that state? I'd just binary patch LV binary to create its window with some strange config. That would only remove the window though. To remove a process from all lists, more complex changes would be required. For modifying such properties of an app on Windows without changing the binary, people usually use AutoHotKey. Nice tool, has a lot of uses. I'm using it to disable windows keys when children play games on the computer, or to make any window stay on top. Using it, you can hide the app from screen and from Task Manager.
-
Heap Peek and other internal debug tools...
Mefistotelis replied to Daklu's topic in LabVIEW General
A perfect moment to dig out a thread , just a few days before its 10th birthday. I made dis: https://labviewwiki.org/wiki/Heap_Peek And happy birthday, thread! -
I'm seeing A LOT of these when re-creating Block Diagrams. It's like LV has no error support at all. If you enable 'dprintf' options in 'LabVIEW.ini', you can at least get some information about reason of the failure.
-
Isn't that common knowledge in our field? When I attended Technical University, that was one of mandatory classes. In case of LabVIEW, the compiler is LLVM. Meaning anyone who looked into clang also looked into that. The amount of developers who looked into CLang or GCC isn't as small as you suggest. This is actually quite common, if a job requires that. I used LLVM as well at some point, ie. I worked on optimizations performed on Intermediate Language tree. And it so happens that in "Heap Peek", you can look at that IL for any VI.
-
Are you completely sure about narrowing what is 'productive' in this way? That excludes a lot. I have specific goals in my research, though this is side project of a side project now. Knowing exactly how LV works should be one of a main goals of healthy community around the project. Unless there is no real community, and everyone is here only due to business ties.
-
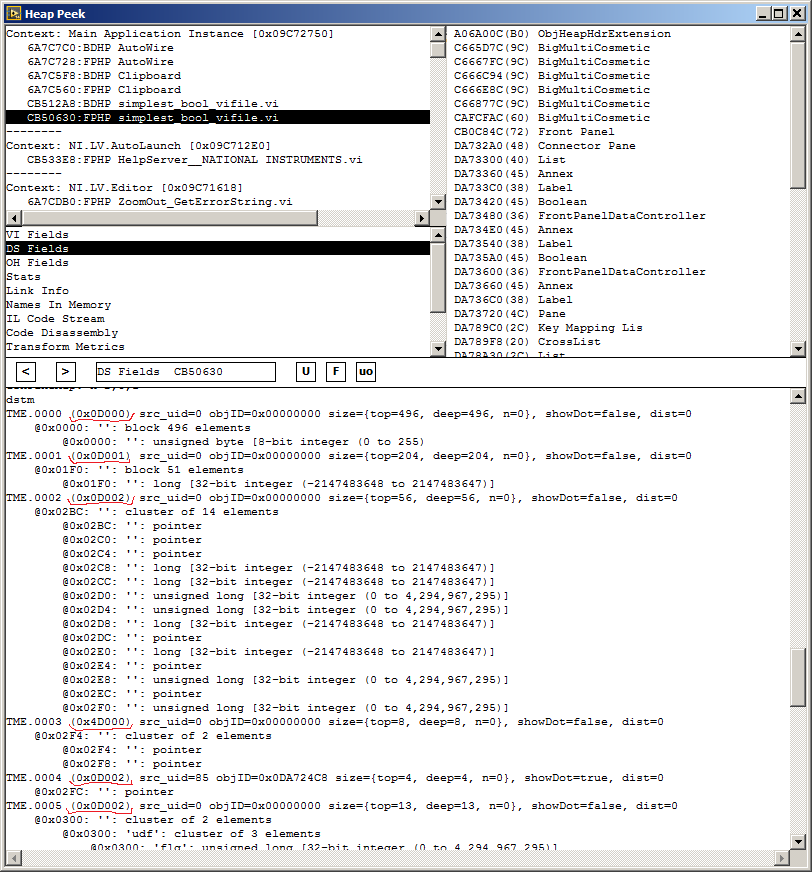
Oh, I see. From the knowledge I've seen shared, I assumed devs are here. So to explain my road to here: Many parts of the VI file revolve around definitions of Data Types, called TypeDesc or TD in code. TypeDesc defines kind of each type (can be Cluster, RepeatedBlock, various types of ints and floats, etc.) and any additional properties of the type (ie. Array has dimensions, and RepeatedBlock has number of repeats). The TypeDescs in LV>7 are stored in VCTP (VI Consolidated Types) block, then subset of the types creates Data Space - this subset is defined and given flags (tmFlags) by TM80 block. In older versions of LV, there is DSTM (Data Space Type Map) block instead of TM80, and TypeDescs are defined directly there instead of pointing to VCTP. So it looks like types were consolidated in LV8 - before, each type was defined in the place where it was needed; after - all types were moved to VCTP, and other places just point to specific TypeId in consolidated list. Now for the Data Space - part of it is filled by values stored is DFDS (Default Fill of Data Space), the rest is just initialized by default values, ie. zeros. But in DFDS, the values are serialized (LV calls this Flattened), so they don't exactly match the look they have in the final Data Space created when the VI is being loaded. Actually, the structure of the Data Space when it's loaded is such that offset of data for each TypeDesc is invariant - so if there is any data of dynamic size (meaning it can change size without TypeDesc change), the Data Space stores it as a pointer. And this is how we come to the Offsets I was asking about - these are Invariant Offsets (because they don't move as long as TypeDescs doesn't change) pointing to where the items are in the unflattened Data Space. To visualize all that, this is how the Data Space looks in Heap Peek; marked values are tmFlags:
-
I figured out how the offsets work. I seriously hope the lack of answers is not due to me getting close to some corpse in the closet.