Mefistotelis
-
Posts
100 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mefistotelis
-
The file @lordexod attached is extracted from 'lvserver.rsc'. And of course, pylabview can extract that as well, to pure XML. ie: <DNmsh> <!-- D. Name Strings List --> <Section Index="1" Name="Class ID" Int5="0x00000000" Format="inline"> <String>ClassID</String> </Section> <Section Index="2" Name="Owner (Deprecated)" Int5="0x00000000" Format="inline"> <String>Owner</String> </Section> <Section Index="3" Name="Owning VI" Int5="0x00000000" Format="inline"> <String>OwningVI</String> </Section> <Section Index="4" Name="Class Name" Int5="0x00000000" Format="inline"> <String>ClassName</String> </Section> <Section Index="5" Name="Modified" Int5="0x00000000" Format="inline"> <String>Modified</String> </Section> <Section Index="6" Name="Is On Block Diagram?" Int5="0x00000000" Format="inline"> <String>IsOnBD?</String> </Section> <Section Index="7" Name="Owner" Int5="0x00000000" Format="inline"> <String>Owner</String> </Section> <Section Index="8" Name="Delete" Int5="0x00000000" Format="inline"> <String>Delete</String> </Section> <Section Index="9" Name="Tag:Set Tag" Int5="0x00000000" Format="inline"> <String>SetTag</String> <String>TagName</String> <String>Value</String> <String>isPersistent</String> <String>OldValue</String> </Section> <Section Index="10" Name="Tag:Remove Tag" Int5="0x00000000" Format="inline"> <String>RemoveTag</String> <String>TagName</String> <String>OldValue</String> </Section> [...]
-
I now know what each value means, but am a bit baffled by the Invariant Offsets. There's quite a few of them: hiliteTableOffset = 1, probeTableOffset = 4, fpdcoTableOfst = 7, clumpQEAllocOffset = 10, viParamTableOffset = 13, extraDCOInfoOffset = 16, localInputConnIdxOffset = 19, nonLocalInputConnIdxOffset = 22, condIndIdxOffset = 24, outputConnIdxOffset = 27, inputConnIdxOffset = 29, syncDisplayIdxOffset = 33, enpdTdOffsetsDso = 37, stepIntoNodeIdxTableOffset = 43, Currently I'm assuming last offset indicates end of the filled space and then going backwards to match other ones. This works for all the files I have, but I'm pretty sure it is not a generic way. How should the offsets be computed? Does the Data Space contain all entries from TM80? or all entries in the entire VCTP? I can see that entries filled by DFDS are not enough. Or maybe there's just a constant-size header before DFDS content which elevated the offsets?
-
Suggestions for open sourcing an application
Mefistotelis replied to Neil Pate's topic in LabVIEW General
It is up to the user to take "reasonable steps" to find the license. Keeping license notice in each file helps, especially when someone uses part of your code to create something else, and files with multiple licenses are mixed. Such situations are good to avoid, but if someone takes the code, he/she should check licensing and provide proper information in the derivative work. This is what you will actually find in GNU FAQ, though they make a big issue out of the derivative works: https://www.gnu.org/licenses/gpl-faq.en.html#NoticeInSourceFile To modify a lot of VIs, you may use pylabview - if you know how to use use python or bash, you can make a batch to extract, modify and re-create any amount of RSRC files with it. You only need to make the script which does the modification, ie. add the documentation to one file, and compare extracted XML before and after the modification to get a patch to be applied to all other files. For the selection - if you don't mind others using it for anything, MIT is a good choice. Though sometimes people say that, and then still feel cheated when someone makes modification to the work and starts making money out of it... if you feel unsure here, you may choose GPL instead. And if you completely don't care about license and want to mock it a bit, there's always DBAD - it's quite popular for underground tools. -
So people are looking into that. That's good. In that case there are probably no vulnerabilities as obvious as I described.
-
If a VI is compiled for current platform, isn't the initialization code arbitrarly executed when VI is being loaded in LV? Isn't that like, very bad? I mean, I could place a copy of Back Orifice there. The community here is exchanging VIs all the time, it would destroy the trust completely if a bad actor would do that. And NI engineers are loading VIs from users as well, right? For example there is the version conversion forum.. I wonder how many of them have source code on the same computers. That would be a massive leak. Though I must say I didn't checked if it's really executed, that isn't my point of interest. Anyway, I'm near to finishing my involvement with LabVIEW. Will soon decide what to publish (most of what I did is already published).
-
VI file defines types used in FP and BD; but besides that, there are a few other type definitions, for more internal use. One is an array of 51 integers, with initialized values stored within VIs DFDS block. These values are internally accessible in LabVIEW by call of DSInitPtr(). Are these values defined in documentation somewhere? Do we know what each value means? There are some hints here and there, but my list is at the moment full of holes: Example dump of the values: <RepeatedBlock> <I32>2</I32> <I32>0</I32> <I32>0</I32> <I32>2</I32> <I32>806</I32> <I32>11</I32> <I32>2</I32> <I32>824</I32> <I32>14</I32> <I32>0</I32> <I32>-1</I32> <I32>-1</I32> <I32>2</I32> <I32>700</I32> <I32>2</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>15</I32> <I32>1</I32> <I32>976</I32> <I32>0</I32> <I32>0</I32> <I32>1</I32> <I32>0</I32> <I32>980</I32> <I32>1</I32> <I32>984</I32> <I32>2</I32> <I32>3</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>-1</I32> <I32>-1</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>-1</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>0</I32> <I32>-1</I32> <I32>3</I32> <I32>4</I32> <I32>5</I32> </RepeatedBlock> All the "internal" types, stored before the types used in heaps, are called "DCO Info Entries". I'd be interested in info about any of these.
-
I didn't even noticed the "issues" were disabled.. re-enabled them now. No, I didn't looked at anything newer than LV2014. Didn't seen any LEIF resource.
-
Readable names to associate with partID values
Mefistotelis replied to Mefistotelis's topic in Development Environment (IDE)
Never mind, got the list from 'lvstring.rsc'. Range is 0..120 and then 8000..8020. But now I'm not entirely sure whether "NON_COLORABLE_DECAL" is a partID 121 or 8000. -
So within VI files, type of each element visible in Front Panel / Block Diagram is identified by partID. That's just an integer value, in range 1..9000. Do we have any association between these integer values and readable names? Not that it's hard to extract all that from 'lvapp.rsc'; but maybe it's already done?
-
'Comp' turned out to be primitive mask-based compression which skips zeros, was easy to implement. 'ZComp' was just the ZLib-based compression, which in later versions is used without being explicitly marked. 'UnComp' is just as the name suggests - uncompressed data. For some reason it follows the same code path as the other two, but the decompressor just copies input to output. So it trolled me into thinking it does something more.
-
LabVIEW versions prior to 8.0 seem to use 3 compression methods within VI files; these were later replaced by ZLib. The methods are referred to as: Comp, ZComp and UnComp. Are these from any known library, or NIs own and unstandardized solution? Is there any kind of stand-alone compressor for these? I don't really need these for my use, but could add support to pyLabview if it is easy to achieve.
-
I am testing my VI parser by extracting and re-creating all VI files from LV2014. One file is a bit different: vi.lib/addons/_office/_wordsub.llb/Word_Add_Document.vi This one has Block Diagram and Front Panel stored in "c" version of the heap format, which is already unusual for LV14 files. But there's another strange thing - it doesn't seem to have Type Mapping data, but still has Default Fill of Data Space (which normally can be only parsed knowing Type Mapping). It looks like instead there's another VI file stored inside, and Type Mapping comes from that internal one. The internal VI file seem to be referred to as "conglomerate resource" - block ID is CGRS. While it doesn't matter for what I'm doing, I'm wondering what is that - there's only one file in LV14 which looks like this. What is the purpose of storing that VI within another VI, while all other VIs are linked in a way which keeps them all as separate files?
-
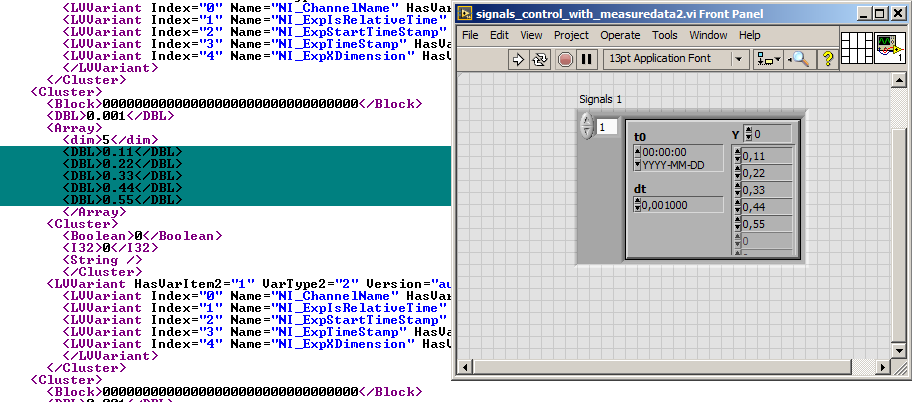
To answer myself here: - VCTP (VI Consolidated Types) ends with an array of "top level" types - the ones which are used in other sections. - The top level type ID of the type which is used for the salt is stored in CPC2. - The TypeID values used in diagrams are mapped through another level - DTHP contains list of top level types for that. Btw, I now have Default Fill of Data Space figured out. Here's LabVIEW on the right, and extracted VI file with the values on the left.

-
What could there be to discuss in Integer formats? There's the 32-bit signed integer, many today applications use only this one and all is ok. Though LV is a programming environment, so it should have more types - 8-bit, 16-bit and 32-bit signed and unsigned variations. And today it would be hard to skip 64-bit, also signed and unsigned. So we have 8 types, and that's it, right? Those are the types allowed for user code; and they are also used by binary formats of LV, but that's definitely not all. Every engineer knows the binary-coded-decimal format - and of course it is used as well. Version numbers are always stored with it, ie 0x1400 means version 14, not 20. What else? Well, imagine you have a software from 16-bit era and want to make it compatible with modern standards. You previously used the minimal amount of bits to store various counts. But today, the 8-bit and 16-bit values may not be enough to store huge multidimensional arrays, counts and sizes. What do you do? You may just replace the values with longer ones, breaking compatibility. But - you may also invent a new, variable size integer format. Even many of them. And here they come: - a 16-bit value, in which if the highest bit is set, then another 16-bit value should be read and the highest bit is toggled off. Nice solution, but we do not get full 32-bit range. - a 16-bit signed value, but if it is -0x8000 - then the real value is stored in following 32-bit area. So it may take 6 bytes, but at least allows full 32-bit range. - a 8-bit value, but if it is 255 - then the real value is stored in following 16-bit area, and if it is 254 - real value follows in 32-bit area. So has either 1, 3 or 5 bytes, and allows full 32-bit range. For some reason, 64-bit values are not supported (at least not in VL14 - I didn't looked at newer versions). There is also signed variation. In total, we now have 13 different ways of storing integer. Now, most of the values are stored in big endian format, but single ones here and there are left in little endian. So we do need to include endianness as well. Though I didn't found any of the variable size values in little endian. Yet. In case you're interested in how exactly the variable size values are stored, here is my implementation of reading and creating these: https://github.com/mefistotelis/pylabview/blob/master/LVmisc.py
-
Is LabVIEW a programming environment, vs Doom
Mefistotelis replied to Mefistotelis's topic in LabVIEW General
Great explanation. Yeah, what you wrote matches my findings and clears the wrong conclusions. So some actions which are performed by the linker in other languages, are performed by the loader in LabVIEW, and LabVIEW has its own loader built into LVRT, skipping OS loader (OS loader is only used to load LVRT). After the initial linking done by the loader, execution is fully native. This also explains why I didn't run across any list of relocations. -
Is LabVIEW a programming environment, vs Doom
Mefistotelis replied to Mefistotelis's topic in LabVIEW General
I got the idea from reverse engineering LV. I can look at it when it works. I can look at the assembly chunks extracted from VI files. Can you share the source of your idea? As I see it, LVRT vs. MS STDC++ is definitely not comparable. Long list of differences. Both are shared libraries, both provide some API which implements some better or worse defined standard, both were compiled in VC++ - and that's all they have in common. For the meme, it is botched. The original was less direct, which was part of the comedy. It is possible that we do have different idea on what virtualization means though. -
Is LabVIEW a programming environment, vs Doom
Mefistotelis replied to Mefistotelis's topic in LabVIEW General
You seem to have quoted wrong line - this one does not relate to virtualization nor any of what you wrote. No, VC++ programs are not virtualized - neither in CPU architecture area, nor in program flow area. So you are right with your VC++ characterization, but how exactly is that an argument here? If you're going after testing my definition: Then in VC++, you write main() function yourself. You call sub-functions yourself. These calls are compiled into native code and executed directly by assembly "call" command (or equivalent, depending on architecture). Your code, compiled to native assembly, controls the execution. In LabView, you still run it on real CPU, which has "call" instructions - but there are no "call" lines in the compiled part. These are simple blocks which process input into output, and the program flow is completely not there. It is controlled by LVRT, and LabVIEW "pretends" for you, that the CPU works differently - it creates threads, and calls your small chunks based on some conditions, like existence of input data. It creates an environment where the architecture seem to mimic what we currently have in graphics cards - hence the initial post (though I know, it was originally mimicking PLL logic, complex GPUs came later). This is not how CPUs normally work. In other words, it VIRTUALIZES the program flow, detaching it from native architecture. -
Is LabVIEW a programming environment, vs Doom
Mefistotelis replied to Mefistotelis's topic in LabVIEW General
There are similarities between Labview and Java, but there are also considerable differences: - Labview compiles to native machine code, Java compiles to universal platform-independent Java Bytecode - or in other words, LabVIEW is not virtualized - In Java, program flow is completely within the bytecode, while in LabVIEW the LVRT does most of the work, only calling small sub-routines from user data I guess the threads being created and data transferred by LVRT instead of user code can be considered another level of virtualization? On some level what Java does is similar - it translates chunks of bytecode to something which can be executed natively, and JRE merges such "chunks". Maybe the right way to phrase it is - LabVIEW has virtualized program flow but native user code execution, while Java just provides a Virtual Machine and gives complete control to the user code inside. -
I've seen traces of very old discussions about how to classify LabVIEW, so I assume the subject is well known and opinions are strong. Though I didn't really find any comprehensive discussion, which is a bit surprising. The discussion seem to always lean towards whether there is really a compiler in LabVIEW - and yes there is, though it prepares only small chunks of code linked together by the LVRT. Today I looked at the trailer of Doom Ethernal and that made me notice interesting thing - if LabVIEW is a programming environment, maybe Doom should be classified as one too? Graphics cards are the most powerful processors in today PCs. They can do a lot of multi-threaded computations, very fast and with large emphasis on concurrency. Do do that, they prepare a small programs, ie. in a C-like shader language if the graphics API is OpenGL (we call them shaders as originally they were used for shades and simple effects; but now they're full fledged programs which handle geometry, collisions and other aspects of the game). Then, a user mode library commonly known as Graphics Driver, compiles that code into ISA assembly for specific card model, and sends to Execution Units of the graphics card. Some shaders are static, others are dynamic - generated during gameplay and modified on the go. So, in Doom, like in LabVIEW: - You influence the code by interacting with a graphics environment using mouse and keyboard - There is a compiler which prepares machine code under the hood, and it's based on LLVM (at least one of major GFX card manufacturers uses LLVM in their drivers) - There is a huge OS-dependent shared library which does the processing of the code (LVRT or 3D driver) - The code gets compiled in real time as you go - There is large emphasis on concurrent programming, the code is compiled into small chunks which work in separate threads You could argue that the user actions in Doom might not allow to prepare all elements of the real programming language - but we really don't know. Maybe they do. Maybe you can ie. force a loop added to the code by a specific movement at specific place. I often read that many arguments against LabVIEW are caused by people don't really understanding the G Language, having little experience with programming in it. Maybe it's the same with Doom - if you master it in a proper way, you can generate any code clause you want. Like LabVIEW, Doom is a closed source software with no documented formats.
-
pylabview could do it, but it looks like there are differences in "Virtual Instrument Tag Strings" section, and the parser can't read that section ATM: So - only NI can help you, unless you are willing to help in development of pylabview.
-
Front Panel is now proper XML (though I only support "FPHb" now, older Labview has FPHP instead, and latest ones use FPHc - those are not parsed, as I don't really need them for my use). Block Diagram is stored in exactly the same way, so I got "BDHb" support for free. I used the same general format LabVIEWs NED uses for XML panels. I can now either work to read "DFDS" section as well - it's quite complex as it isn't stand-alone section, meaning it needs data from other sections to parse. Or I can ignore default data, and start working on Front Panel re-creation without that.
-
Working on Front Panel now. This is what pylabview generates: <?xml version='1.0' encoding='utf-8'?> <SL__rootObject ScopeInfo="0" class="oHExt" uid="1"> <root ScopeInfo="0" class="supC" uid="10"> <objFlags ScopeInfo="1">010000</objFlags> <bounds ScopeInfo="1">0000000000000000</bounds> <MouseWheelSupport ScopeInfo="1">00</MouseWheelSupport> <ddoList ScopeInfo="0" elements="61"> <SL__arrayElement ScopeInfo="1" uid="64" /> <SL__arrayElement ScopeInfo="1" uid="96" /> And this is the same part generated by NED within LabView: <SL__rootObject class="oHExt" uid="1"> <root class="supC" uid="10"> <objFlags>65536</objFlags> <bounds>(0, 0, 0, 0)</bounds> <MouseWheelSupport>0</MouseWheelSupport> <ddoList elements="61"> <SL__arrayElement uid="64"/> <SL__arrayElement uid="96"/>
-
While I'm still working on parsers for all types of VI connectors, I also noticed the VICD block. Some old articles on its content: https://web.archive.org/web/20110101230244/http://zone.ni.com/devzone/cda/tut/p/id/5315 https://web.archive.org/web/20120115152126/http://www.ni.com/devzone/lvzone/dr_vi_archived6.htm Not sure if I'll be decoding that section further though - I believe the connectors block and default data block will be the only ones required to re-create front panel. The binary format of Front Panel should be easy to figure out by comparing binary data to the XML representation which can be generated in newer LV versions; anybody tried that?
-
I need some example files to test my tool. I am running it on all the LV14 standard VIs, but it looks like these are not using all possible features of the VI format. In particular, I am not seeing use of some Refnum connectors. For example the type which 'Vi Explorer' calls "queue". Anyone knows what to click in LabVIEW to get such connector within the VI file? EDIT: Forced myself to read LabView help, now I know how the Queue works. Still didn't found some refnums in documentation, ie. Device Refnum.
-
Finding dll dependencies
Mefistotelis replied to FixedWire's topic in Application Builder, Installers and code distribution
On linux, you may just use ldd: $ ldd my_binary Or if the loader refuses to run it on current platform, but you still need to know: $ readelf -d my_binary For Windows - there are tons of "PE Viewers" and "PE Explorers" which lets you look at import table.