Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Those are all just characteristics of the different transport mechanism. My (poorly made) point was that the transport mechanism alone isn't enough (imo) to justify a different pattern name. This is much more in line with my perception of what it means to be a "slave," and as you pointed out, they both fall into that category. Ahh, these are the key points I was missing. The intent of the Master/Slave is to produce more slave loops while the intent of the Producer/Consumer is to create more producer loops. Rereading the context help I see they do mention using multiple slave loops in the M/S documentation. (I trust they cover these in the class that teaches these patterns, because the included documentation doesn't make it very clear.) The other thing that struck me as odd was wiring the dequeue/wait error terminals into the case structure. That seemed rather restrictive as it only allows for a go/no go command. I assume the intent is something along the lines of this: I'll add that I don't think the "Producer/Consumer" name is the best way to describe that pattern. I view producer and consumer as roles each loop plays at different times. Any loop sending information to another loop is a producer and the receiving loop is the consumer. In the code above the loops just happen to never change roles. To be honest I'm not sure what to call it. It's more of a statically defined publish/subscribe.

-
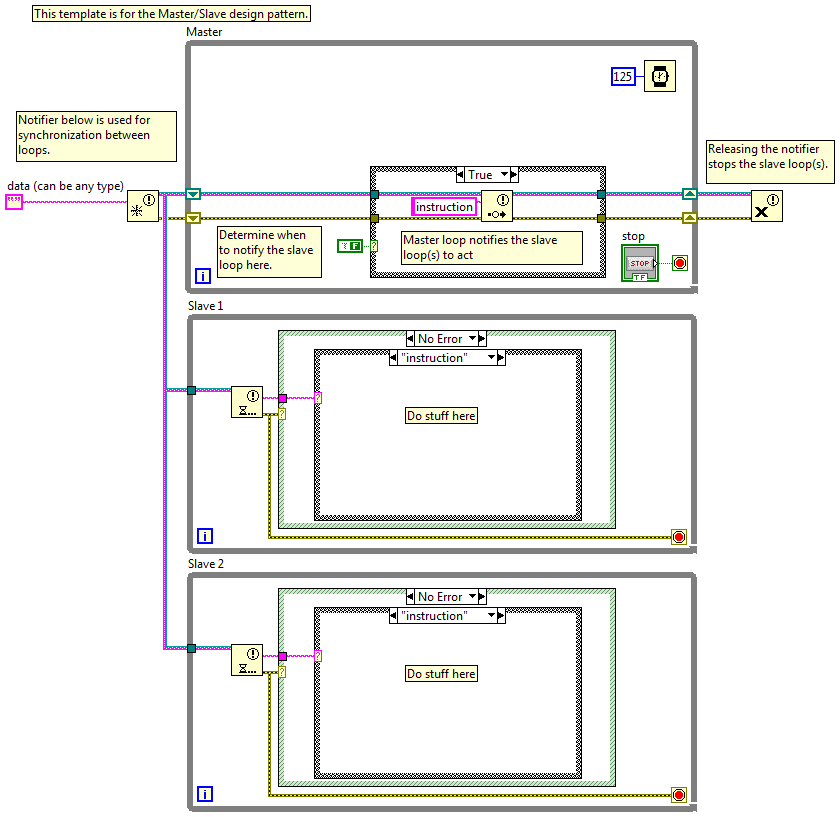
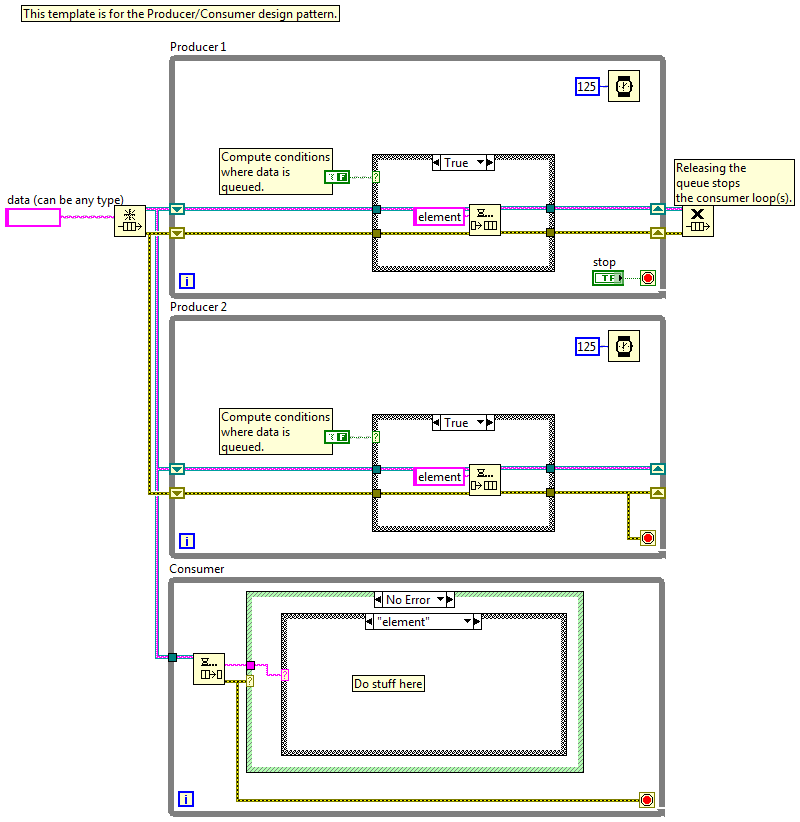
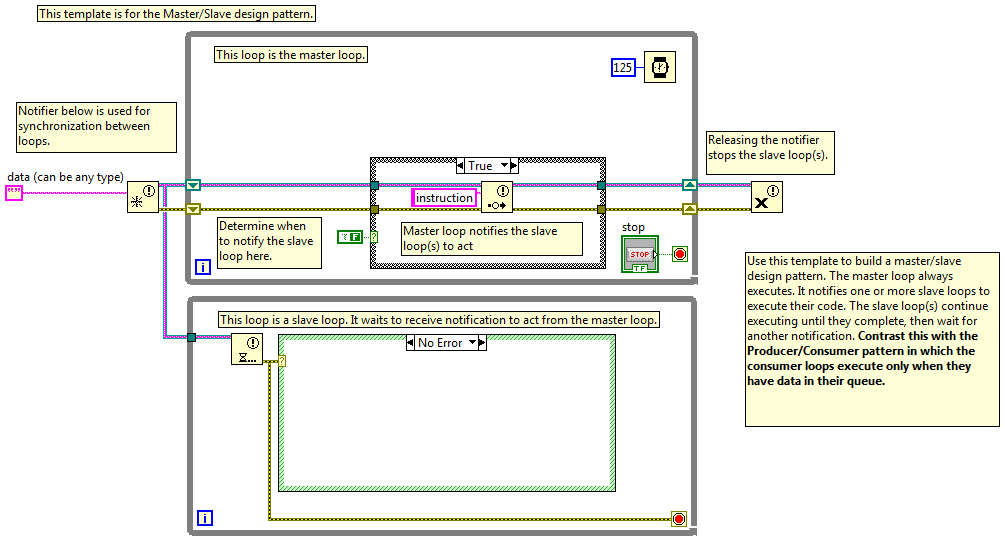
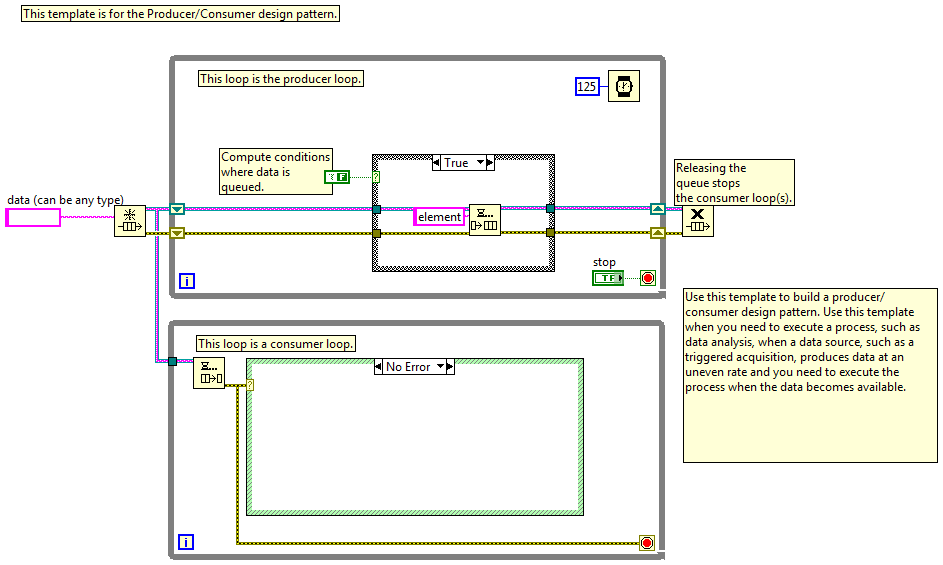
So tonight I gave a presentation on QSMs at the local LUG and it got me thinking about the differences between a "slave" and a "consumer." Thinking I'd get some information by going to the source, I opened the Master/Slave and Producer/Consumer templates included with Labview. I've never taken the classes that cover these patterns, so I have no idea how NI intends for them to be used. But looking at these two block diagrams I see one pattern implemented using two different transport mechanisms. Aside from the transport, how exactly are these patterns different? The slave help text (copied to the bd) implies a functional difference I don't see. What am I missing?
-
Giving it a name (or some sort of identifier) at creation is one solution if you have access to the source code. For clarity I'd code it so it returned <MySlaveName:Response> instead of <SerialDevice:MySlaveName:Response> and give it the name SerialDevice:MySlaveName upon creation. That's just personal preference though... Another option if you don't want to modify your slave class (say, if you have a bunch of tests written for it or have already used it elsewhere and don't want to risk breaking compatibility) is to create an adapter class that wraps the slave. The name property will be part of the adapter class and it will modify all the output message names from the original slave to be uniquely identifiable. Then in your main code you just replace the slave vis with the adapter vis.
-
My thoughts on hygienic functions code blocks is based solely on the definition AQ supplied. I'd never heard the term before then and I don't know anything about the classic definition of hygienic programming. With that in mind, here's my take on it. A hygienic block is one that outputs the same values for a given set of inputs regardless of when the block is executed. Blocks that take a reference as an input are non-hygienic. The refnum, not the data it represents, is the input. And as asbo said, anything with time dependent behavior is also non-hygienic. I agree. A purely hygienic language (i.e. does not allow non-hygienic code) would be next to worthless I think, though I freely admit I have no experience with functional languages. Actually what I was saying is if you accept dataflow and hygiene as synonyms, then LV cannot be considered a pure dataflow language. Like I said above, defining dataflow=hygiene doesn't make sense to me--it confounds unrelated ideas--so in my head I can call G a pure* dataflow language while at the same time agree it is not purely hygienic. (*"Pure" in this context anyway. It could be that a theoretically pure ("super pure?") dataflow language would allow each output to propagate as soon as it is ready rather than waiting for all outputs to be ready.) ---------------- One interesting aspect of hygiene is it is not necessarily a compounded property. In other words, it is entirely possible for me to construct a hygienic code block in G using parts that are not hygienic. I'm not yet sure how useful that is... it's another way to look at programming I'll have to think about.
-
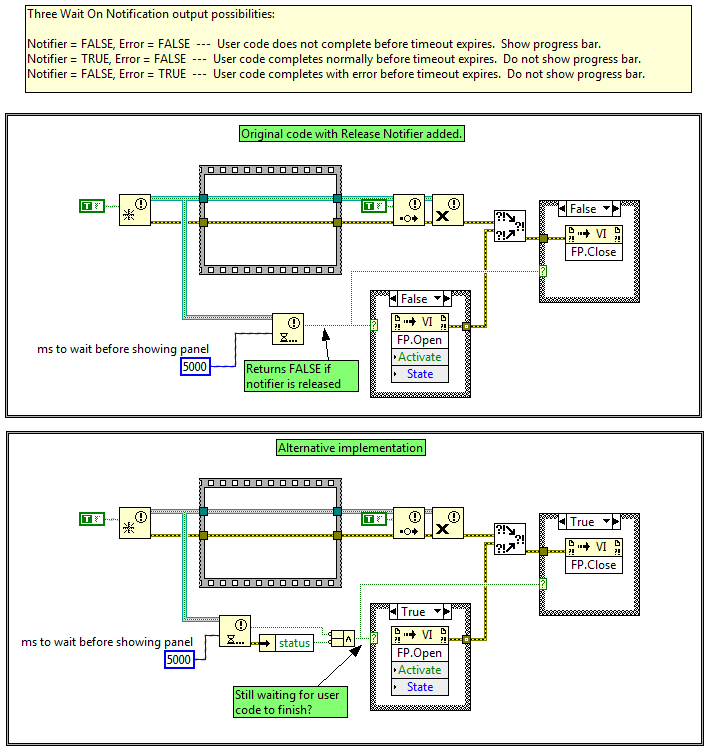
 Nice catch! (And another illustration of how the common practice of connecting all the error terminals can introduce subtle bugs.) To extend your thought, if he follows your first suggestion and adds a Release Notifier function, which I think he said he would do, the effects of an error are a little different. (See top bd.) Releasing the notifier cancels the Wait On Notification function and returns an error. Unfortunately it also returns False, meaning the progress bar will open and immediately close. It's possible to add logic to eliminate that effect (bottom bd) but overall I like your implementation better. I think it more clearly communicates the intent of the code.
Nice catch! (And another illustration of how the common practice of connecting all the error terminals can introduce subtle bugs.) To extend your thought, if he follows your first suggestion and adds a Release Notifier function, which I think he said he would do, the effects of an error are a little different. (See top bd.) Releasing the notifier cancels the Wait On Notification function and returns an error. Unfortunately it also returns False, meaning the progress bar will open and immediately close. It's possible to add logic to eliminate that effect (bottom bd) but overall I like your implementation better. I think it more clearly communicates the intent of the code.
-
I agree. The market for LV developers started changing the day LVOOP was released. It's been slow to catch on, but the mindshare is growing. Not learning it reduces your future marketability and opportunities.
-
There. Now I agree. Whether or not G follows "pure" dataflow is--as far as I can tell--still an open question because "dataflow" itself may not be well defined. The academic CS community defines it as meaning all effects are local. AQ borrowed the term "hygienic" from functional languages: "A VI should be considered clean if, when executed, for any set of input parameters, the output values are always the same. In other words, if you have a function that takes two integers and produces a string output, if those two integers are 3 and 5 and the output is "abc" the first time you call the function, it should ALWAYS be "abc" every time you call the function with 3 and 5. The term for such functions in other languages is "hygienic functions." It's a term I'd heard before but never thought to apply back to LabVIEW." By that definition I would think a pure dataflow language would not allow any non-hygienic functions. Clearly it is possible to create non-hygienic functions in G; therefore it is not pure. It makes much more sense to me for "dataflow" and "hygienic" to be orthogonal ideas rather than synonyms. (I dare challange acadamia? *gasp*) In my head "dataflow" refers to how code is sequenced at runtime while "hygiene" refers to the function's input/output predictability. Dataflow allows us to easily write multithreaded applications. Hygienic functions allows us to easily verify it's behavior. By this definition G is pure dataflow but not purely hygienic. Put on your thick skin; he can be really snarky.
-
I'm glad you found it helpful. (At the risk of dislocating my shoulder patting myself on the back, out of all the posts I've made that is one of my favorites.) I agree it's not the behavior one would expect coming from a more traditional language. My confusion came from the "reference" part of Data Value Reference and the ambiguity between "pointers" and "references" in common programming languages. Mentally I now think of DVRs as a form of boxing/unboxing. Depends on what programming role you're playing at the moment. For the "business data flow designer," yes. For the "application optimizer," maybe not. But I agree most of the time every wire branch should be viewed as a copy. Isn't a reference simply another piece of data? It's not business data (stuff the end user cares about,) but it is information that needs to be managed within the application. That's how I look at it anyway. *shrug*
-
LapDog Messaging and Actor Framework
Daklu replied to SteveChandler's topic in Application Design & Architecture
How did you get information to your PID controlled if you weren't passing it "messages?" I broadly define a message (in the context of Labview) as any data passed between parallel loops. The way the data gets there seems to me to be irrelevant. Functional globals, global variables, local variables, DVRs, etc. are all (imo) different ways to pass messages to a running loop. Is "no shared memory" a requirement for something to be a "message?" My messages are almost always by value data copies, but there is nothing stopping someone from packing up a by-ref object in LapDog and sending that to a recipient. Does doing that mean that "message" is no longer a message and the receiver is no longer an Actor? -
LapDog Messaging and Actor Framework
Daklu replied to SteveChandler's topic in Application Design & Architecture
Yeah, me too. *sigh* I'm not very satisfied with that definition. I mean, it's fine as far as it goes, but it's defining the model, not the implementation. It's not at all clear to me how the implementations for an Actor, Active Object, and Agent (to throw another construct into the mix) differ. What attributes does an object require to be considered one of those? For example, in one Java actor framework actors encapsulate the message transport. Is that an inherent feature of an actor or is it just an implementation detail? I don't know... (Encapsulating the transport is optional for Slaves. Doing so is safer in that it protects the queue from other components, or you can skip it if you want easier decoupling.) On page the second page the author goes on to say, implying Actor Objects and Active Objects are one and the same. Yet further down he adds in the concept of "futures." Again, is this a required feature for Actor and/or Active objects or is it implementation specifc? Stephen introduced Actors in an early thread about Active Objects. Using different terminology suggests he believes there's a difference between the two. I hesitate to consider a Slave Object an Actor until I have a better understanding of Stephen's definition of "Actor." Unfortunately he's been silent on the issue so far. -
hierarchical component system states and dependencies
Daklu replied to PaulL's topic in Application Design & Architecture
I doubt this will be much help... I can tell you what I do, but my apps are designed to be event-driven and heavily message based rather than state driven. It sounds like you have designed Component A to respond directly to state transitions in B or C, and my patterns may not work well in that paradigm. Typically in my app a component will only enter an error state if it has an internal error. In C's error state I do whatever I need to do to manage the error. If I can self-recover I'll do that. If not I'll report the error and return to some other predefined state, such as 'standby.' Using your example, A doesn't have an internal error, so it doesn't report that it has faulted. Component A does have message handlers to respond to error messages from sub components. Different error messages will trigger different responses. Sometimes it will shut down the entire system. Other times it will just notify the user and continue. Wow... that's vague enough to make a CIA censor smile. Are the two solutions you're considering 1) propogating the fault state up through the component hierarchy, and 2) not propogating the fault state up through the component hierarchy? -
Over the past couple years I've tried unit testing in various projects. Sometimes successful, sometimes not. Even on those rare occasions when I've been successful I usually felt like I was going in circles with my tests, trying to figure out how to best build and organize them. Unit testing was more of a brawl than a ballet. Several months ago I picked up what is now my second favorite book recommendation (right after Head First Design Patterns,) a gem called xUnit Test Patterns. If you're doing OOP, understand patterns, and want to improve your ability to deliver good software, this is the book to get. (There's even lots of information on the website if you don't want to purchase the book.) The book is written for xUnit frameworks so it is a natural fit for JKI's VI Tester. There are a few minor things VI Tester currently doesn't let you do, such as inherit from a test class, but 96+% of the book is directly applicable to your Labview projects.
-
The problem isn't with dynamic dispatching. If the child classes aren't showing up in the parent class project's class hierarchy, that means your child classes aren't being loaded into that application context. In other words, your parent class project doesn't have any child objects to take advantage of dynamic dispatching.
-
LapDog Messaging and Actor Framework
Daklu replied to SteveChandler's topic in Application Design & Architecture
Good questions Steve. I haven't used the Actor framework nor talked to AQ about it in depth, so if I misspeak hopefully somebody will correct me. You are correct in that they are both techniques to encapsulate an arbitrary unit of functionality running in one or more separate threads. The most obvious difference is AF provides more built-in functionality. Slave objects are simply a pattern you need to implement yourself. Each has its advantages. The AF requires (I believe) you to use the included command-based messaging system. Slaves can built using whatever messaging infrastructure you have. I like the command pattern for certain situations but I'm not fond of it as a general purpose messaging system. It feels too restrictive. YMMV. On the other hand, ideal OOP replaces case structures with dynamic dispatching, so command-based messaging is arguably more pure. AF's built-in messaging may make it harder to introduce Actors into existing code. I assume you could write an adapter to fit each actor into an existing messaging system, but like I said I've never used the framework. I know people have been successful using it as a springboard for designing new systems. Personally I try to follow the Agile principles of implementing only what is necessary, growing the software organically (rather than doing a lot of design up front,) and continuous refactoring. That means I need small steps of increasing functionality and encapsulation. A typical progression for me as functionality increases might look like this: [Note - While classes provide the basic unit of functionality, loops provide the basic unit of execution. It's just as important to manage the interface exposed by a loop (the messages it handles) as it is to manage the interface exposed by a class or any other api.] 1. Classes A & B collaborating in a single loop (loop 1.) 2. Class B needs to run concurrently so I move it to a separate loop (loop 2) on the same block diagram and use messages to transfer information. 3. Class B's functionality has increased and become less cohesive, so I refactor it into B, C, & D, all running in loop 2. The messages and arguments exposed by loop 2 change very little, if at all, in this step. 4. Class D needs to run concurrently so I move it to loop 3 on the same bd. Loop 3 is a subset of the functionality provided by loop 2. Loops 1 and 3 have no knowledge of each other. Any messages loop 2 receives intended for class D are forwarded to loop 3. After a few iterations the block diagram starts to get confusing, so I'll break off a branch of functionality (loops 2 and 3 in this case) and wrap it in a SlaveB object. Nothing changes in loop 1; I've simply made a small refactoring that balances the level of abstraction on the original block diagram and improves readability. At this point I can instatiate multiple instances of SlaveB by dropping more Creators on a block diagram. I don't use dynamic launching unless I need a large or unknown number of instances. However, it's easy to add a Launch method to a Slave and turn it into an Active Object. I believe it's also relatively easy to wrap a Slave in an observable object, upgrading it to Publish-Subscribe. Changing from a parallel loop to an Actor object feels like a big jump to me. There are probably logical intermediate steps between them, but without any experience using it I don't know what they are. Maybe Stephen will weigh in. I've considered adding LapDog libraries for things like Active Objects, Observables, etc. One of the reasons I haven't is they would have a dependency on the messaging system, which violates my original intention for all LapDog packages to be independent. I may just bite the bullet and do it anyway. (After I release Collections, which is only... oh... 13 months late.) I don't think so. A Slave object is an intermediate step between a parallel loop on a block diagram and an Active Object, Observable, or other higher level functionality. I'm not sure what Stephen's intent is but the literature I've been able to find on Actors seems to indicate different architectural considerations. That said, I haven't heard what *he* thinks the differences between and Actor/ActiveObject/Slave are. I could be completely off base. -
Not likely, since NI already provides a nice set of queue and notifier functions that fit my needs. (Although it would be an interesting exercise... I wonder if reimplementing queues for LapDog would give a performance increase?)
-
Traits - An alternative to interfaces, mixins, etc.
Daklu replied to Daklu's topic in Object-Oriented Programming
I'll take that as a request to move the discussion over there, which is probably a good idea. [Would a moderator be so kind as to lock this thread?] -
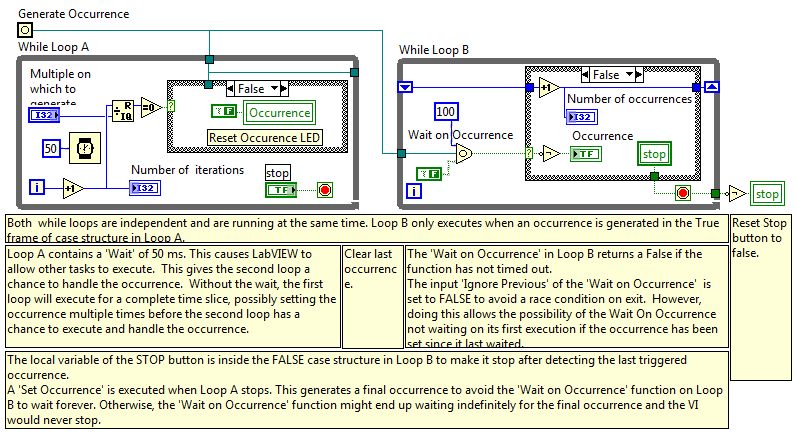
<*Spoken in a slow, southern, drawl...> What we have he'ya is a fail'yer to communicate. I wanted to eliminate the extra occurrence that was set during execution, not the extra Set Occurrence function.
-
I understand now... I think my brain is on autopilot. That does eliminate the trailing Set Sequence, but the functionality doesn't change--it still makes loop B execute one "extra" time.
-
Maybe I misunderstand. OR'ing =0 with STOP in loop A terminates that loop on the first occurrence. (The purpose of this example to demonstrate how to issue continuous occurrences.) Weren't you ever a boyscout? Leave it better than you found it! That works too if you don't mind bringing in a sequence structure again. It's even a little cleaner than a seq struct at the end because you just have to wrap it around the Generate Occurence function.
-
Traits - An alternative to interfaces, mixins, etc.
Daklu replied to Daklu's topic in Object-Oriented Programming
Heh, I'm thinking I need at least a half dozen rereads sprinkled with several helpings of Squeak. I don't think that's right. On page 8 they show code for the trait TDrawing. The refreshOn method is implemented in the trait and uses the required methods bounds and drawOn. A little further down they show a diagram of a Circle class which uses both TDrawing and TCircle. TDrawing requires bounds and drawOn, but Circle only implements drawOn. Bounds is implemented by TCircle. There's no glue code specifying that in the class body, so I'm guessing the compiler does linking for required methods automatically based on signature (name and connector pane in LV.) I suppose it's possible that's just the default behavior and we can create alternative links if desired, but I don't see that specified in the paper. The aliasing example on p.13 is dealing with provided methods, not required methods. I don't think this works in LV--at least not the way I'd like it to work. If all the trait defined of the required method was a conpane you have a few options: 1. Initialize a trait with vi references to the methods providing the required services. (Can't do that; traits are stateless.) 2. Include the required vi references on the trait's method conpane. (Yuck.) 3. Require the class using the trait to provide a wrapper method. (I don't see much point in this. We can create trait-like stateless classes in Labview and use them in "real" classes via delegation today.) 4. Invent a new trait table where classes record the mapping. (Nooooo... I want to consolodate information, not spread it out more.) Or... if we just require the class to implement a method with the same name and conpane as the trait's required methods we can avoid all that hassle. I dream of extending my shortcuts idea to traits. Instant functionality. Not that it doesn't have it's own issues. For example, what happens if we compose a class with mutually dependent traits? - TraitA provides Rock and requires Scissors. - TraitB provides Scissors and requires Paper. - TraitC provides Paper and requires Rock. Calling any one of them enters an infinite loop. I guess you'd have to override eclipse at least one of the trait methods with a class implementation. Working out that kind of issue might be tricky unless we can manually map required trait methods to a class implementation. How would we go about using a required method in methods the trait provided? Maybe something like a call by reference node, except it has a string input for the required method's name and a class input that tells it where to look for the method? -
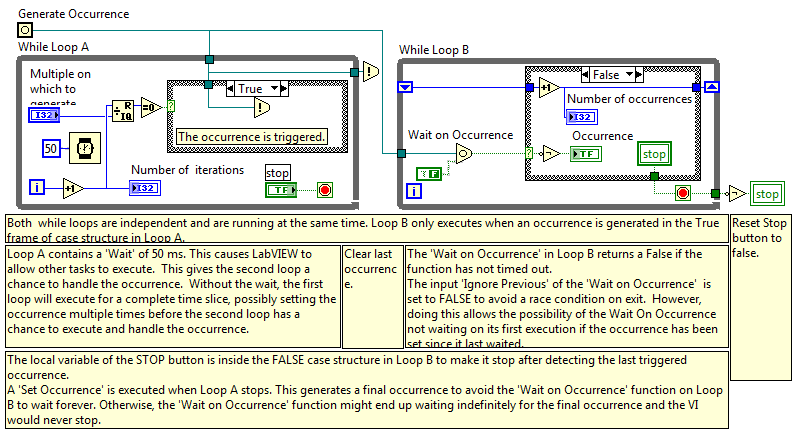
Thanks Rolf. As always, your knowledge of the lesser known aspects of Labview leave me slack-jawed. (I had never heard of "Labview Manager" and had to Google it.) Here's the "Continuously Generate Occurrences" example that ships with 2009. Every 10th iteration of loop A generates an occurrence and causes loop B to execute. I thought it was interesting to see a Set Occurrence after loop A exits. I understand why it's needed, it's just not the first route I would have tried. (But as you can see from my earlier posts I have very little understanding of this construct.) This causes loop B to get an extra iteration when you exit loop A. I started wondering how to prevent the extra occurrence, so I added a timeout and removed the tailing Set Occurrence. On the surface it seems like that should work, but there's a subtle race condition. Because the WoO has a timeout it is possible for loop B to read the stop button, exit, and reset before loop A has an opportunity to read it. With an infinite timeout that will never happen. I suppose you could put the button reset in a sequence structure and wire outputs from both loop A and B to it, but that feels kind of klunky to me. The other alternative is to set the timeout longer than the time between occurrences, so it will only timeout once the occurrences have stopped being generated. That doesn't seem like a very robust solution. I guess I'm left thinking they're okay for simple cases--such as Tim posted--where the occurrence will only fire once telling the receiving loop to stop. But at the same time I can't think of any reason (outside of interacting with external code) I'd want to bother with them. Notifiers and queues have the same functionality, provide more options for expansion, and the overhead is insignificant.
-
This may be a stupid question--like I said I don't use them and I don't have LV in front of me atm to test it out... I thought setting Ignore Previous to false would allow the second pass through loop 2 to execute normally, because it's not ignoring the occurrence that was previously generated. I take it when WoO detects an occurrence it effectively "clears" any pending occurrences? Given WoO does have a timeout, the sample code will execute to completion, it'll just take one full timeout period longer than the time it takes to for the occurrence to fire. Is the timeout user configurable? mje, do you have an example where an occurrence's static refnum "feature" is an advantage over a regular notifier? I'm having a hard time thinking of a use case.
-
Care to elaborate? (I've never used occurences and I'm finding it a bit confusing.)
-
hierarchical component system states and dependencies
Daklu replied to PaulL's topic in Application Design & Architecture
No help on the references, but I don't think you can answer that question for the general case. It depends on your system. For example, in a Car component if the Radio component faults (stops working) should the Car fault too? Conversely, if the Car's Accelerator component faults (sticks on), it might be a good idea to stop the Car as well. [Edit - Curious, why are you revisiting the question?] -
Extend class representation in project explorer (Wow, it's almost to double digit kudos. That's a record for me!)