Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
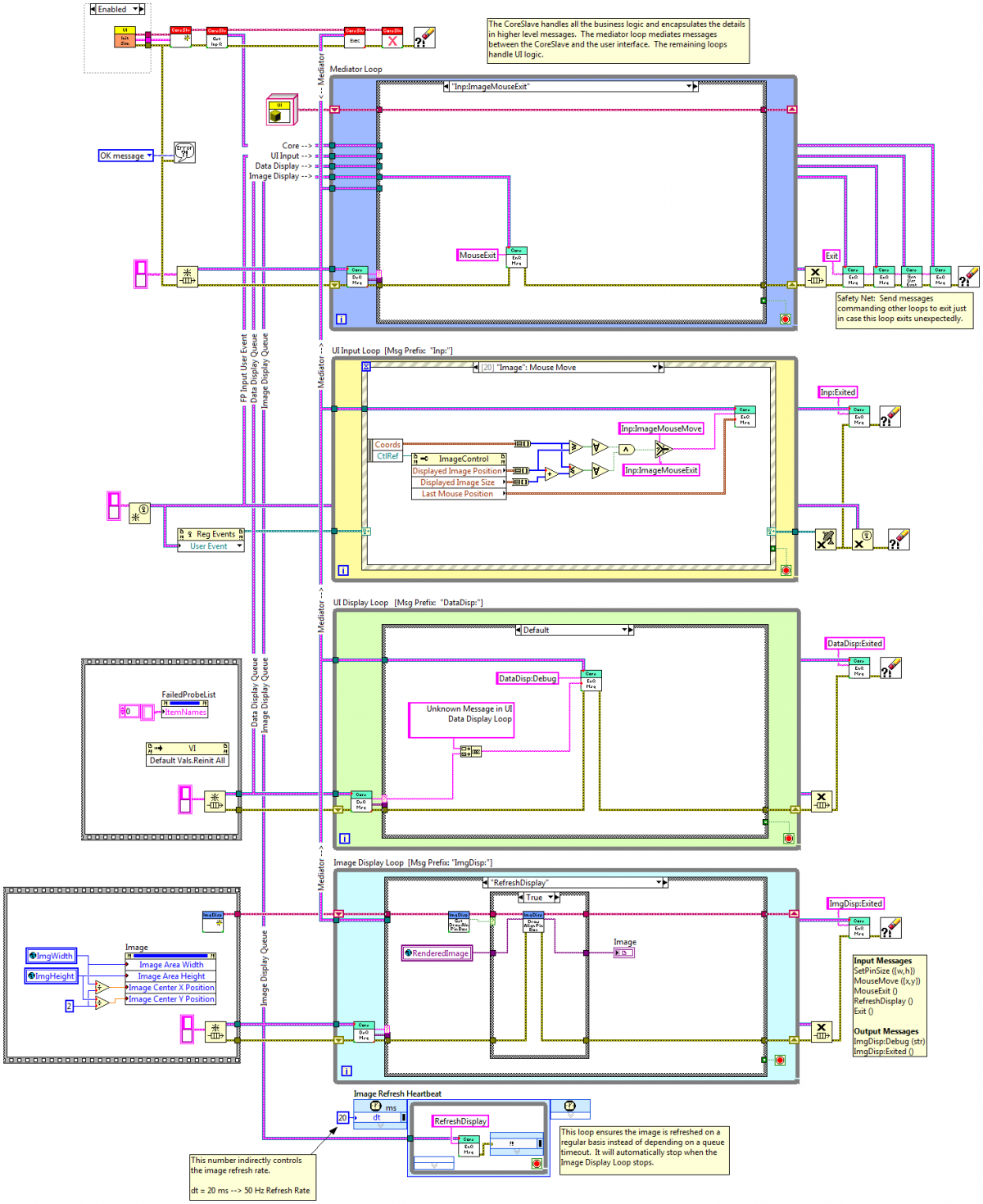
It wasn't obvious to me--primarily because I haven't run into situations where I needed it--but I don't think anything is wrong with it if you need latching commands. I've done that in the past, but in general I try to write my code so it doesn't depend on having the queue timeout. The timeout is unreliable--it resets every time a message is received. Having critical code in the timeout case opens the door for unexpected (and unidentified) bugs. You can write reliable software with critical code in the timeout handler, but you have to always be aware of whether or not the new code is preventing the timeout from firing on schedule. It leaks implementation details and you have to tightly control all the conditions in which messages are sent. Here's what I like to do instead: The is the block diagram from the main UI panel for an app I'm currently working on. Look at the bottom two loops. The ImgDisp loop's main responsibility is to refresh the front panel display with images from a camera. This being a UI, it's pretty critical that it refreshes consistently. Notice there's no timeout. Right below it is a separate loop whose only job is to send "RefreshDisplay" messages to the ImgDisp loop on a regular schedule. Earlier in this project I did have the RefreshDisplay functionality in the ImgDisp loop's timeout handler. The only external message the loop handled was "Exit," so it wasn't a problem. A late feature request came that required a box be drawn on the image under the mouse pointer during certain alignment processes. That required adding new messages to the loop: SetPinSize, MouseMove, and MouseExit. MouseMove messages are going to come fast and would have disrupted the timeout process, so I just moved that functionality from the "QueueTimeout" message handler to the "RefreshDisplay" message handler and added the heartbeat loop. Problem solved. There's a couple things about this loop you might notice. First, I'm operating on an ImgDisp class. This particular class is just a glorified cluster. I'm only using it for the abstraction. I don't expect to ever create a child class for it, but it's way easier for me to understand the code at a glance. The other benefit is it's obvious the functionality encapsulated by the DrawAlignmentPinBox is intended for only this small part of the application. It's kind of a built in aid for project organization. Second, the ImgDisp loop behavior changes based on the DrawAlignmentPinBox flag. *sniff* *sniff* It smells like a state machine, but it's implemented as a message handler. (I've broken my own rules! Oh, the horror!) In this particular case I allow it because the ImgDisp loop is so simple and there's only one flag. In the back of my head I know if I add more functionality to that loop I'll need to refactor it into a state machine. Third, in this example I'm putting the message directly on the ImgDisp queue, which violates the "all messages come from one source" rule of slave loops. I consider the heartbeat loop "attached" to the ImgDisp loop. In other words, if I were to wrap the ImgDisp loop in a slave class the heartbeat loop would go with it. Depending on the situation I might route the heartbeat message through the mediator instead and the heartbeat loop would not be attached to the ImgDisp loop.

-

managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
The Slave Loop post is a little outdated. I've since decided wrapping the input queue in class methods is an optional feature of slave classes. It's best used in special situations where you need to either protect your slave's input queue or need to assure messages are typed correctly. It's kind of tedious having to change them frequently during development. If I'm the sole owner of the code I'll expose the slave's input queue as an output of the creator method. There's nothing inherently wrong with standard string/variant messages. Named queues, on the other hand.... *shudder* A couple easy ways to eliminate the named queue: You can pass the class' input queue as part of its creator/constructor. Or you can create it internally as part of the constructor and wire it to an output terminal on the creator. I prefer passing it out because it reenforces the idea that the slave owns the queue, not the calling vi. Pfft... see? You're already using slaves. Slave classes are just a way to encapsulate a parallel process to help manage the complexity. They have 3 core methods: Create, Execute, and Destroy. Your looping sub vi is the same as my Execute method. I use the Create method to make sure the object has all the information it needs to start executing. (Queues, etc.) Then instead of using a USR for maintaining state you store it as private class data. You already have a queue going from the robot loops to your controller. Why don't you just send it as a message? There's a common perception LapDog.Messaging is really complicated that I don't quite understand. It's almost identical to standard string/variant queues, except the msg/data pair is boxed in an object. (Well, that and the automatic messages I included as part of the Dequeue method.) I guess the confusing part might be the downcasting requirements? That's just an OOP equivalent of a Variant to Data function (in this particular framework.) Out of time... maybe I'll be able to post more later. -
My theory is that is part of the natural process of learning how to program. I know I spent some time over-abstracting the code I was writing while learning how to LVOOP. I've seen indications on other threads that lead me to believe others are doing the same as part of their learning process. Whenever we learn about a great new technique (inheritance, design patterns, abstractions, whatever...) we get excited and start using it everywhere we can. That's generally discouraged in programming circles, but I figure part of learning how to properly use technique x is discovering the consequences of using it. Going overboard is the only way we can find out how much x is the "right" amount. I'd much rather work with someone who makes their decisions because they've actually implemented the available alternatives than work with someone who makes decisions because that's what the book (or forum, or expert) said. (And I'll go so far as to say any programmer worth his salt has thought the exact same thing many times through their career.) I don't either. I used to, but I now believe that's the wrong way to go about it precisely because it leads to too much abstraction. My thought process while coding is more along the lines of yours. "Hmm... this loop is responding to messages but I need it to send a status update every 2 seconds. How should I do that?"
-
managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
Interesting. I'd love to see what he did. When I started LVOOPing I tried something similar because it seemed like the "right" way to do it. In the long run I found myself fighting against the limitations of inheritance instead of benefitting from it. Unless the instruments are very similar I don't see much point in putting them all in the same class hierarchy, especially if it's intended to be reused across multiple applications. It varies depending on complexity, but I can only keep details of maybe a half dozen block diagrams in my head at once. (Or less than 1 QSM block diagram.) Well-named and well-segregated sub vis are your friend. -
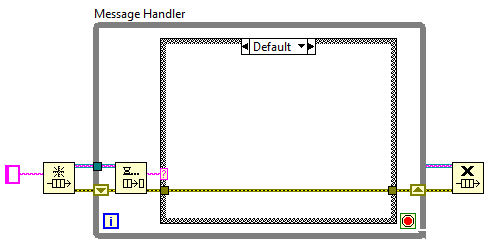
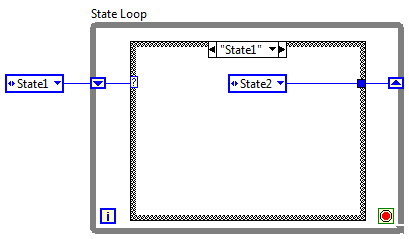
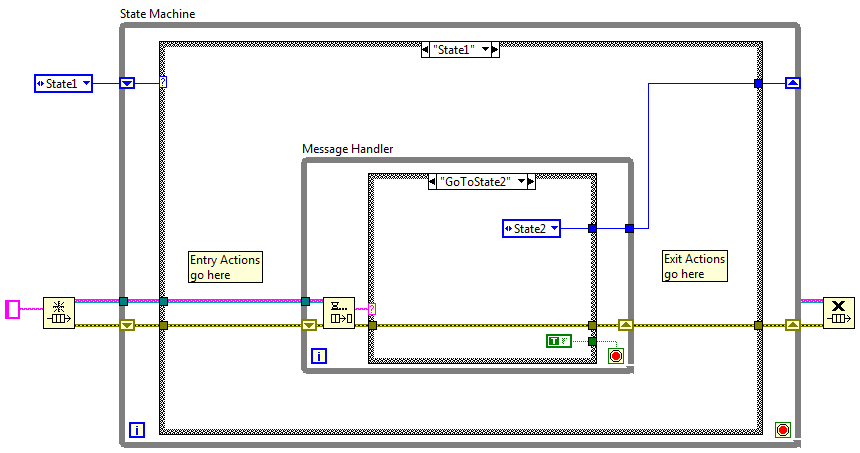
It looks very similar, but the way it's used is entirely different. QSMs are based on commands. You send a command and the loop executes it and waits for the next command. That part is similar. The difference is in expectations and how states are represented. The QSM doesn't have explicit "states," it has commands. People try to emulate states by issuing the same command(s) repetively until it is time to move to a new "state." (I'll call it a "fuzzy state" for reasons that hopefully will become clear.) For simple state machines it can work okay, but it can quickly and easily grow out of control. For example, I can continuously queue up 3 commands, GetData, ProcData, and SendData, and conceptually they are a single CollectingData fuzzy state. I could also have a fuzzy state called StreamingFromDisk that repetively queues LoadData and SendData commands, and another fuzzy state StreamingToDisk that repeats the GetData and SaveData commands. So now you have 5 cases: GetData, ProcData, SendData, LoadData, and SaveData. In QSM terminology these are referred to as "states." I'd be really interested in seeing someone create a state diagram using those five states. (I don't think it can be done, but I'm not a state machine expert.) The three states that do exist, CollectingData, StreamingFromDisk, and StreamingToDisk, aren't shown anywhere in the code. It's up to the developer reading the code to mentally put the pieces together to form an image of the state machine. The states are "fuzzy" because they're not well defined. The lack of definition makes it very easy to break the state machine without realizing it. The slave loop example I posted includes a couple different ideas that probably aren't explained very clearly. (I've been thinking about blogging a series of articles about it...) These aren't new ideas, but I'll define them here for clarity. First, in my terminology a "slave" is a parallel process where all messages to and from the slave are routed through a single master process. A single loop is the smallest component that can be a slave, but there could also be multiple loops in a slave. A slave can be wrapped in a vi or a class, or it can simply be a separate loop on a block diagram. Second is the "message handler," shown below. Most people look at it and think it is a QSM. If you look closely you'll notice I don't extend the queue into the case structure as many QSMs do. I don't allow the message handler to send messages to itself because that's a primary cause of broken QSMs. More importantly, it's a reminder to me that each message must be atomic and momentary. Atomic in that each message is independent and doesn't require any other messages to be processed immediately before or after this message, and momentary in that once the message is processed it is discarded. It's not needed anymore. (Tim and mje do the same thing I think.) The third is the "simple state loop." It's been around near enough to forever that everyone should be aware of it. NI includes a "Standard State Machine" template with Labview. When I'm coding a new loop usually starts life as a message handler. Sometimes as the project progresses I discover the loop needs states, so I add a simple state loop around the message handler as shown below to create a state machine. How do I know if I need states? It's kind of intuitive for me, but a good clue that you're transitioning from message handler to state machine is needing a shift register (or feedback loop) to maintain flags or other information about itself. State machines and message handlers serve very different purposes. The QSM looks like it was created in an attempt to add stateful information to message handlers as requirements changed. I hold a minority opinion, but personally I don't think they are a very good solution. There are other reasons why the QSM is a poor substitute for state machines, but that's a different discussion.
-
managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
I'm not quite sure what you mean by "where to keep the class wires." Are you using the instruments in the tests and simulation at the same time? There's nothing particularly difficult with writing auto reconnect code, though it isn't something I'd put directly in the instrument class. Just give the class a way to report the connection has been dropped and let the calling vis be responsible for monitoring the connection and reestablishing it when you want. There are two basic ways you can handle connection monitoring: Inline or as a parallel process. Inline--meaning the connection is checked as part of retrieving a data point--is easier to implement, but if a connection is dropped you won't know it until you try to get a data point. Doing the reconnect operations directly in your data processing loops may cause unacceptable delays depending on the project specifics. Parallel process connection monitoring is just a separate loop dedicated to the instrument that periodically checks to see if the connection is still valid even if you're not actively collecting data. When it discovers the connection has been dropped it will attempt to reestablish it. That way the reconnection process doesn't cause your data processing loop to hang. You might be able to use a by-ref class if the instrument's device driver supports it. Personally I prefer to stick with by-val classes and just route all data exchanges with the instrument through that loop.- 22 replies
-
- 2
-

-
- multiple drivers
- driver management
- (and 3 more)
-
My mistake then; I apologize. I thought you were asserting notifiers and lossy communication are inherent parts of the general M/S pattern instead of just components of that particular implementation. The older I get the more I find defining the vocabulary up front saves a lot of misunderstanding down the road. (Though hopefully I'll never get to the point where I ask someone to define 'is' for me.) I've seen a reasonable amount of talk about master/slave patterns, but I've never taken that to mean they used this template as a starting point. I don't hang out on the dark side much... maybe they talk about it over there? I took a quick look, but to be honest I know very little about creating or modifying xnodes. I'd love to explore using them for collections... so many things to do... *sigh* (It appears I don't have the correct license for working on xnodes anyway...)
-
Solution for propagate latched boolean between loops
Daklu replied to Bobillier's topic in LabVIEW General
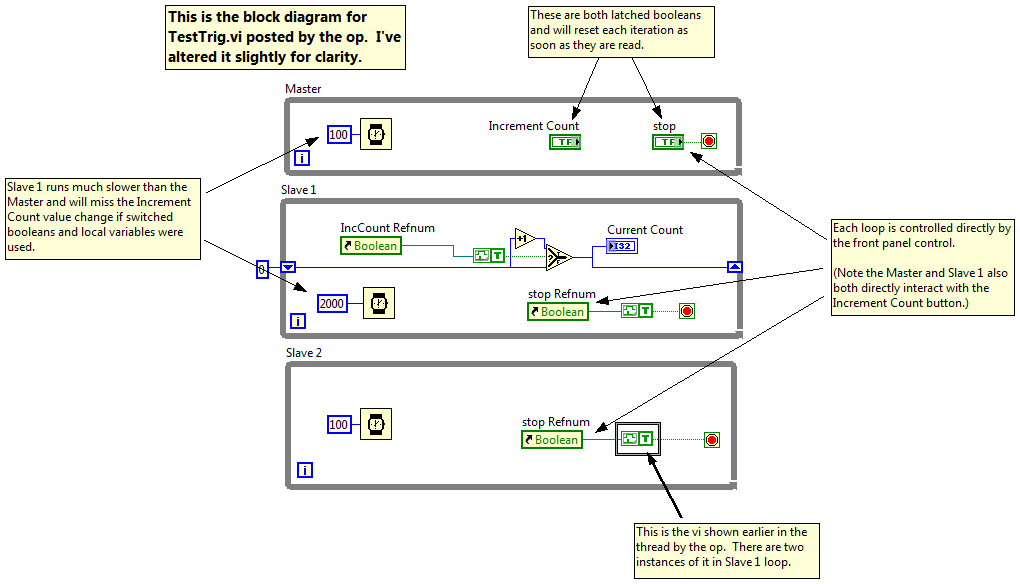
Here's the block diagram of Eric's example of how to use the vi posted above. He's definitely wanting to read the front panel controls in multiple loops. The Stop button could be replaced with a switched boolean instead of a latched boolean, like Saverio said, but the Increment Count button would be harder to implement as a switched boolean. (A switched Increment Count button would also have slightly different behavior, remaining pressed until both the Master and Slave 1 finished reading it.) There is one non-obvious side effect to doing this instead of passing messages. In the snippet above you can see the event is unregistered when the first value change event comes through. That means any additional value change events in the event queue are discarded and the slaves may lose clicks if they are sent before the slave loops again and reregisters for the events. Still, it's an interesting solution to a problem I know a lot of people have struggled with--including me, before I changed my approach. I might use this on prototype (i.e. throwaway) code but in general I prefer restricting control reads to a single loop and having it send the data to the other loops that need it. I don't know if one solution is inherently better than another. Depends on your needs for the specific application. Registering only once would prevent the missed button clicks I noticed. No, there are no bad effects I'm aware of if you don't unregister a dynamic event. [ for cleverness and ease of use, even though it encourages less optimal code separation.]
-
Solution for propagate latched boolean between loops
Daklu replied to Bobillier's topic in LabVIEW General
From the original post: "(for example to propagate latch action between few parallels loops)" and "But it's not all. With this trick, If you modify Latch boolean ref input by another kind of ref type and/or modify the kind of registration, you can easily propagate any kind of action." I may be misunderstanding the op, but I interpret his comments as meaning he wants the boolean value available to multiple loops. On the other hand, I didn't test his code and I haven't spent enough time looking at it to fully understand what he's doing, so maybe I'm wrong. -
I don't think there's anything inherently wrong with it. It's a clever improvement over QSM implementations I've seen where the default case has an internal case structure to handle the many different "continue doing the same thing until told otherwise" situations. IMO, what you have is definitely an improvement but--as the bolded text indicates--you're still using a QSM. Some people swear by them. Personally I find them more trouble than they're worth. [Even though I don't use and (still) don't like QSMs, that seems to be enough of an improvement to deserve a .]
-
Solution for propagate latched boolean between loops
Daklu replied to Bobillier's topic in LabVIEW General
Yes, but you can't reset the boolean until all the loops have had a chance to read the value. That means you have to add a global checklist of who has read it and who has not and have each loop mark the checklist when it has read the boolean. Then you need code that either polls the checklist to reset the boolean or have each loop check to see if it's the last one to read the boolean. When parallel loops are reading the same control it's not simply a matter of wiring a constant into a local variable. Can you do it that way? Sure, but it's error-prone, doesn't scale well, and there are better ways to do it. -
managing multiple instrument drivers - best architecture?
Daklu replied to automationtx's topic in LabVIEW General
I doubt this is the kind of suggestion you're looking for, but I recommend hiring a consultant for a week or so. The questions you're asking can't really be answered without a much better understanding of the requirements and constraints. -
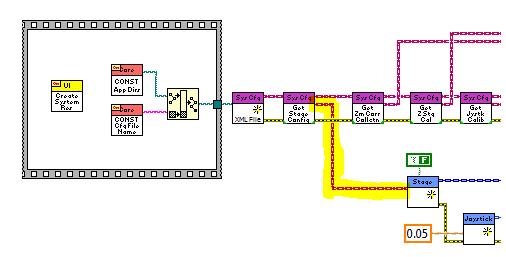
I can't post the source code, but here's part of the initialization routine for an app I'm working on now. My SystemConfig creator takes a path to an xml file as its input and loads/parses all the configuration data for the entire system. The "Get StageConfig" method returns the configuration data specific to the motion control system as a StageConfig object. That object is passed to the "Create Stage" method as an input. You can see I also extract other config information from the SystemConfig object for other aspects of the system.
-
If I know at edit-time exactly which object I need I stick with a static creator. If I won't know until run-time then I'll use a config object like Jon suggested for single objects or a factory for more complex setup processes aggregate several other objects. I don't typically have the instrument class load configuration info directly from disk. That's a detail I don't want in that class. Instead I put the load/save functionality in the config object.
-
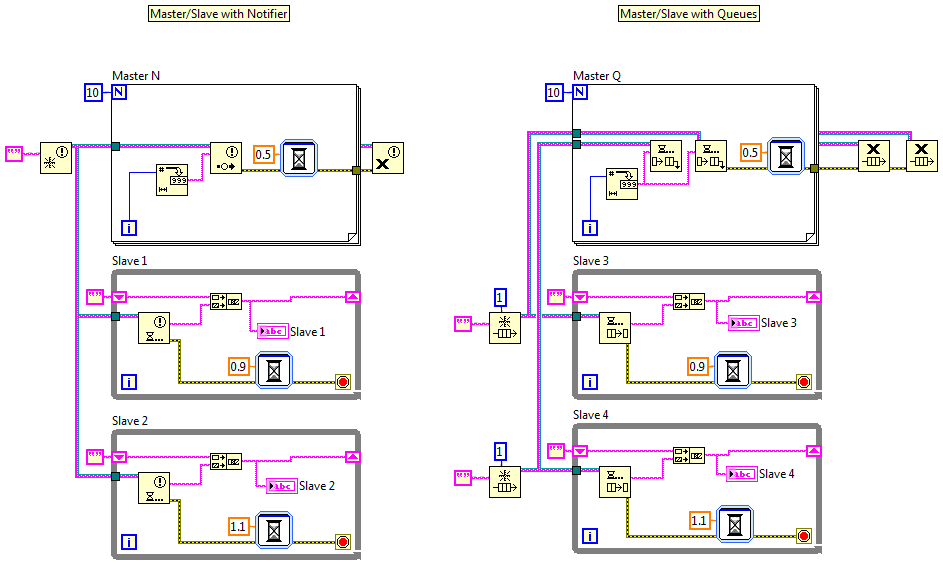
Hmm... I'm not quite sure how to interpret this statement. Are you saying NI's template defines the what the master/slave pattern is, or are you saying your comments have been directed at that particular implementation of the pattern? The context of your posts suggests the former, so I'll assume that is what you mean, but to be honest it's not clear to me. Let me know if I've misunderstood you. Did you see the part where I said each slave loop gets its own queue? This is what I'm talking about. Now I thought I understood the differences between queues and notifiers, but maybe there's something I'm missing. As far as I know these two master/slave implementations are functionally equivalent. Is there an edge condition I'm not aware of that makes them behave differently? I agree it appears to be pretty limited. I suspect it's designed for beginners and those who are using Labview as a data collection tool rather than as an application development tool. Ahh... at least one person agrees with me on what it means to be a slave. (Maybe we can brainwash convince the others. ) Your description of p/c doesn't quite make sense to me, but that's another discussion. Jon is right. Preview leaves the message on the queue, so if a slave is running faster than the incoming messages it will preview a message it already acted on. Master-Slave Comparison.vi
-
Would you care to take a stab at enumerating your understanding of those differences?
-
I fully agree with you there, and as developers we need to understand the tradeoffs when deciding on what transport mechanism to use between two loops. I just don't think the specific transport matters because it is rather easy to duplicate one-to-many relationships between loops using queues. It's a little more work to scale functionality to multiple threads when using queues to transport, but they do scale perfectly well. Just have a unique queue for each slave and send the message to all of them. Actually you can. Set the queue size to one and use the lossy enqueue function. And if the notifier is an inherent part of the M/S pattern, it also means all the slaves operate on the same set of messages and on the identical copies of the data which, as you pointed out earlier, turns it into a solution looking for a problem. Master/Slave, Producer/Consumer, Observer/Observable, Publisher/Subscriber, etc. describe the relationships between parallel processes, not the implementation. The transport mechanism is an implementation detail and entirely incidental to the relationship. No doubt it is a very important detail, but it doesn't affect the overall relationship between the processes.
-
[Warning: Blatent idea promotion ahead] And if you're overriding the parent method just so it is easily available from the child class (i.e. not changing the functionality,) then you may be interested in this idea.
-
Solution for propagate latched boolean between loops
Daklu replied to Bobillier's topic in LabVIEW General
Unless the boolean needs to be reset without exiting and restarting the program. Latched booleans are simply modified switched booleans that automatically reset as soon as the value is read. They are a convenience for us as programmers so we don't have to write reset code in those situations where we're just doing a single read and reset. It's not intended to be used as a general replacement for all button reset code. The fact that you're trying to do something latched booleans cannot do--have parallel loops read the latch--is a strong indication that something is wrong with your approach. The problem is you have too many loops reacting directly to the state of your front panel controls. You'll have a much easier time if you restrict all front panel control reads to a single loop with an event structure, and have that loop send messages to the other loops to let them know the button was pressed. -
It's not the only thing they have in common. In both of them all messages to a specific slave loop comes from a single place. That, more than anything else, is what defines a slave in my mind. I don't think lossy vs. lossless is one of the defining characteristics of slaves or consumers. I suspect the template uses notifiers simply because they allow easy 1-to-many communication. I use queues instead because most of the time I want lossless master/slave communication. Possibly, but I don't believe they would have put it in there unless someone had found it useful. The template is just a starting point. It's obvious there are ways NI intends it to be used, it's just not obvious what they are. Maybe they consider it okay to replace the notifier with queues? I do agree the M/S template doesn't seem to map very well to code I've encountered in the wild.
-
How To Resolve LVOOP Locked Library When Only One Instance Open?
Daklu replied to lvb's topic in Object-Oriented Programming
I had that problem with some CRIO work I was doing, though I don't remember what I did to resolve it. Maybe you can help isolate the problem by removing the other targets from your project? -
That was intentional because I was basing it off of AQ's original code with only the release function added. Personally I still prefer your ealier implementation. I think explicitly sending the notification requires less thinking than boolean combinations of the WoN outputs.
-
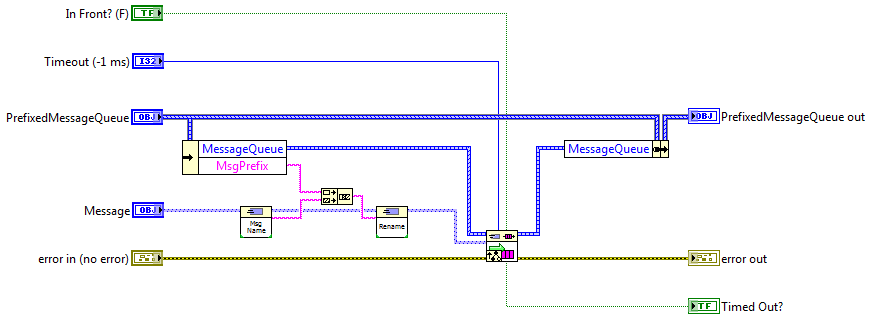
Oooo.... I like that. I did run into a bit of trouble when I went to implement an example. I didn't create protected accessors to the MessageQueue's private data. This means the PrefixedMessageQueue class has to contain an instance of its parent and you have to override every method to unbundle the parent object. Seems kind of wasteful and unnecessary... Here's an example of the EnqueueMessage override: And here's an example of how it would be used: (I'll have to think about releasing a LapDog.Messaging minor update that includes protected accessors. That would allow you to only override the enqueue methods instead of all of them, but I need to ponder it for a bit.) ------------ It's hard to follow what you're describing. Can you post code? PrefixMessageQueue.zip
-
Fair concern. My intent isn't to create more confusion, it's to create more clarity. When somebody says they're using producer/consumer, all that tells me is some sort of information is going from the producer loop to the consumer loop. Anything beyond that is a guess unless I see their code. So what are the critical characteristics of a producer/consumer pattern in your opinion? Is it multiple senders to a single loop? The template has only a single producer and a single consumer, yet it is producer/consumer. Does it require that information always flow in a single direction, from the dedicated producer loop to the dedicated consumer loop? That's how the template shows it, but one way communication seems to me to limit its usefulness. If the consumer is sending information back to a producer, is it no longer producer/consumer? If not, what is it?
-
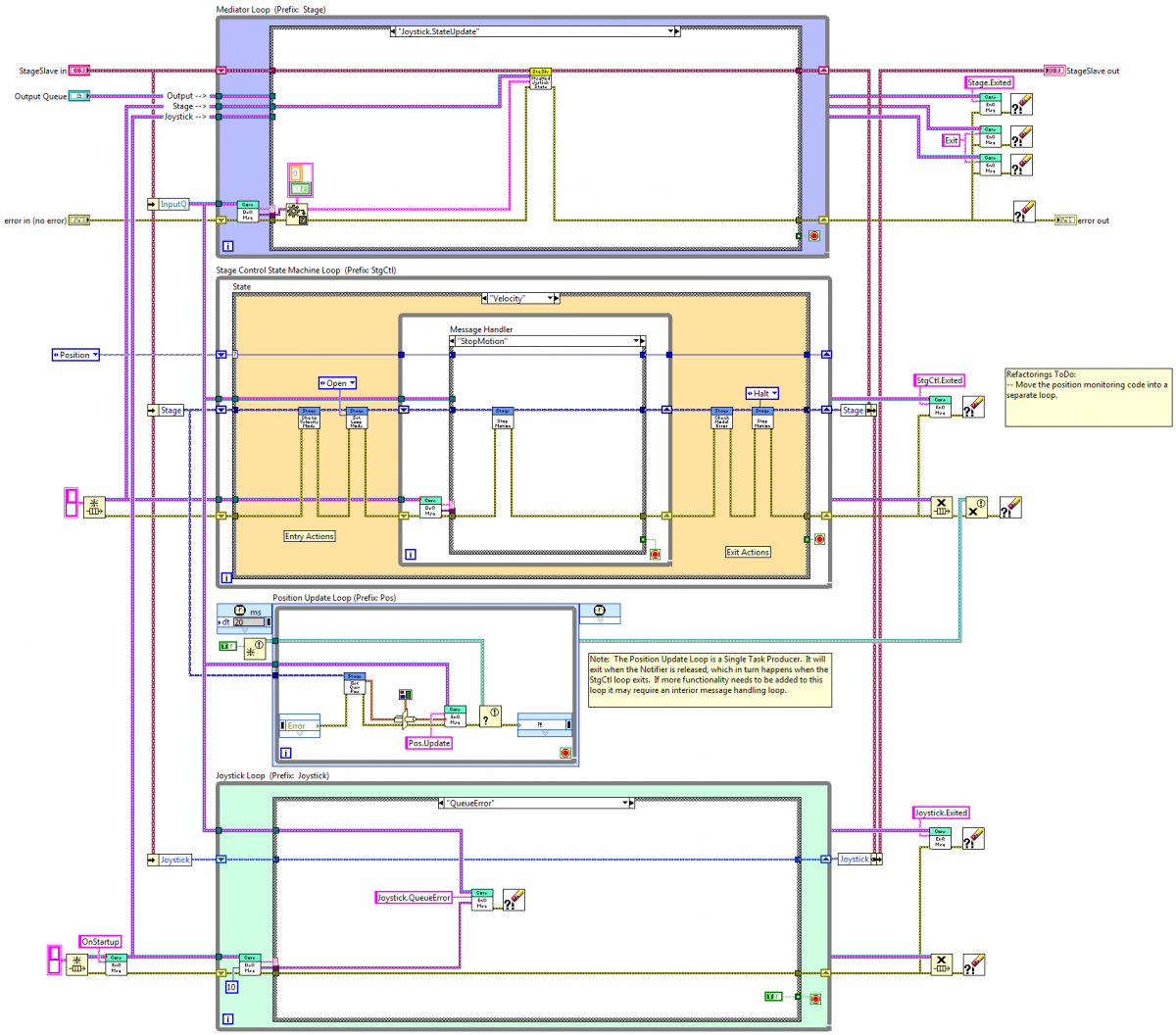
I use master/slave all the time. Granted I don't use them with notifiers, but I consider them slaves because all their messages come from a single source, their master. In this example the Mediator loop is the master and the StgCtl and Joystick loops are slaves.