Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
I thought that was "deterministic?" How do hygienic functions and deterministic functions differ? There is a concept called monads that I've read about for a number of years but never quite been able to wrap my brain around. Maybe someday...
-
Fair enough. Follow up questions based on that definition... 1. Earlier in this thread I posted examples of using queues that could be refactored into more direct dataflow code. I believe it is safe to say any code that can be refactored in that way is dataflow safe in its original form. Do you know of situations where code cannot be refactored into direct dataflow yet are still dataflow safe? 2. What are the major consequences of breaking dataflow? Is it primarily related to human requirements (readability, complexity, degubability, etc.) or are there significant run-time penalties? I know you've mentioned fewer compiler optimizations when dataflow is broken. Have these been benchmarked at all? I've been wondering if it's possible to concisely describe what it means to "own" a piece of data. I think it's more than just access to the data. Multiple nodes reading the same data shouldn't cause a dataflow problem. Maybe a simultaneous data write operation is required to violate single ownership? I dunno... this line of thought naturally progresses into equating ownership with race conditions, which I'm not sure is helpful when discussing dataflow. Thoughts?
-
I agree I haven't hidden the details. I disagree software abstraction requires that the implementation details are unknown to the user; it merely means the details do not need to be known. Knowledge or ignorance of the implementation details seems like a poor condition to use as the basis for defining "abstraction." I know the details of the LapDog Message Library, but it is still an abstraction of some bit of functionality. If NI unlocked the source code for Labview's queues and I learned that inside and out, I would still consider a queue an abstraction. I agree, there is no polling in your code. (There is polling in the execution path though.) I also agree that when communicating with other developers it isn't very useful to say your code is polling if you haven't explicitly implemented a polling algorithm. But the question isn't about the relative merits of referring to your code as polled or event-based in everyday language. The question is whether using event-based features of a given language is sufficient condition to claim dataflow has been broken. The principle of dataflow transcends any programming language or os implementation. In general terms, dataflow is a way of organizing and scheduling the various steps required to reach a goal by basing it on dependencies rather than on strict sequencing. Of course, goals and scheduling are concepts that stretch beyond the boundaries of Labview, Windows, x86 processors, etc., so dataflow exists outside of that environment. (A Gantt Chart is a common representation of a dataflow-ish system in the world of project management.) We need to look beyond Labview's implementation to determine what "breaking dataflow" means in general before we can even hope to figure out what, if anything, within Labview breaks dataflow. Nope, I waited on dozens of queues and observed Labview's thread count didn't increase, indicating Labview doesn't necessarily put the thread to sleep when a wait is encountered. I didn't look at cpu usage, but I'd be surprised if there was any noticable increase in cpu load. Any polling that is going on (assuming there is polling) is probably happening in low level c code in the LVRTE or the OS and the incremental workload is small enough to be insignificant. It could, but I'd be surprised if it was applied to something as pedestrian as keyboard inputs or UI events. Hardware interrupts are necessary, but the "give me attention NOW" nature of them makes them disruptive and costly. Too many interrupts in the system brings it to a screetching halt. Occasionally my pc gets very lethargic. Almost invariably when I bring up Process Explorer I see 25% or more of my cpu load is being consumed by hardware interrupts. (Likely caused by a faulty driver somewhere.) Users can't tell the difference between a 4 microsecond response and a 20 millisecond response. Better to put keyboard activity in a regular polling loop and avoid the interrupt overhead. Agreed. But polling *is* occurring, which is the point I'm trying to make. When we get a value change event in Labview, somewhere in the execution path that generates that event someone wrote software that is "testing something to detect a state change." Events are nothing more than abstractions created by lower level code as a convenience for programmers. They exist in source code, but not in compiled code. Since dataflow is a run-time activity based on compiled code, events in source code cannot be an indicator of broken dataflow. ---- It seems more complicated than that. I can easily create a vi with n enqueue points and d dequeue points that is still dataflow safe. I can also create a vi using local variables that is dataflow safe. I guess both of these examples illustrate the concept of data "ownership" you referred to. I've had this nagging desire to include time as a necessary component to determining dataflow, but haven't quite been able to wrap my brain around it. "Simultaneous ownership" seems like as good an explanation as any. Quick question... It seems like your definition of dataflow is very closely tied to what you called "local effects" and Labivew's G's by-value data handling. In your opinion, is that an inherent part of dataflow in general or is it important because of how NI has implemented dataflow and the limitations of currect technology?

-
I thought this was an interesting comment. Suppose I created a sub vi like this and used it in an app. Is this polling or is it waiting for a TRUE event to occur? I'll go out on a limb and assume you'll agree this is polling. But wait... I've abstracted away the functionality that is doing the polling into a sub vi. Does that mean the vis that use this sub vi aren't based on polling? Is it fair to consider them event-driven? To save a bit of time I'll step further out on the limb and assume you'll respond with something along the lines of "an OS is different than a sub vi." (Feel free to correct me if my assumption is wrong.) To that I agree--an os is different than a sub vi. An os provides a much more extensive set of services than any single sub vi can hope to provide. They both, however, do so by abstracting away lower-level functionality so the sub vi does meet the requirement of "some layer of abstraction." All software is layer upon layer of abstraction. From high level functions that are part of your application code down to the lowest level assembly routines, it's all an abstraction of some bit of functionality provided by a lower level abstraction. What is it about the abstraction provided by an os that makes it okay to ignore the polling aspect of it while not being able to ignore the polling aspect of the sub vi? Conversely, what changes would we have to make to the sub vi that would make it okay to ignore the polling aspect of it?
-
I'm not convinced this will save me a lot of time. As I've learned OOP and applied it to LV over the last several years my classes have gotten smaller and more specialized. Each class is very limited in what it does, often to the point where the functionality a class encapsulates is contained on a single bd. (The LDM MessageQueue class is a prime example of this.) And my custom data types are almost always classes with accessors instead of clusters for reasons I've explained elsewhere. Of course these decisions requires more classes overall, so even though I don't have to fill in all the details of every vi I still have the overhead of creating the classes and all the public methods the class exposes. That's interesting. I wonder if that reflects the LVOOP adoption rate overall among intermediate to advanced developers? It would also be interesting to see how much this number changes over time. The way I develop apps at the architecture level it is all components (typically a lvlib,) where each component's api is made up of several classes that work together to fulfill the component's responsibilities. Probably very similar to what you do with a slightly different project structure. In practice my apps are heavily multi-threaded and message based because I find adapting to changing requirements and reusing code is much easier using this paradigm. Maybe I need to just abandon the messaging architecture for the CLA and use something more direct, even though I wouldn't do that IRL... Yeah, this is another area where I'm having a hard time figuring out how much is enough. There are implementation patterns I use that address the shortcomings I've encountered in many of the common LV patterns. (i.e. I've written at length about the QSM and it's dangers, so I'd never instruct a junior developer to create one.) Unfortunately for me these patterns aren't widely recognized within the LV community and explaining how and why to implement them to a typical over-the-wall Labview developer is difficult, to say the least. Yet some of the implementation details are important from an architectural standpoint, so I have a hard time sweeping them under the rug. For example, when a component reacts to messages sent by a source it doesn't have intimate knowledge of, I don't ever put functional code in a timeout case because the timeout might never expire. Instead I create separate timer loops to regularly enqueue messages which in turn trigger the functionality that needs to execute. That's an important detail if the component is going to be robust, but over-the-wall developers--especially if they are overseas contractors--may not even be aware of the potential issue, much less know how to resolve it. In my hypothetical organization everyone knows how to correctly build a reactive component so I can focus on the interface instead of specifying implementation details. I've mentioned the SlaveLoop in previous threads. I like using it in combination with the LDM because it presents a well-defined interface to a parallel component's functionality without adding the complexity of dynamically spawning clones. It's certainly not a well-known pattern. It doesn't really translate to text languages so I don't get any help from there. As far as I know I'm the only one who uses it. (Well, me and my hypothetical organization.) How much detail do I have to show or explain to get credit on the CLA? (It's a rhetorical question... I don't expect you to answer.) I guess some of my uncertainty is due to a lack of maturity in LVOOP terminology, which is in part due to LVOOP's relative newness. We're all still learning how to apply ideas and terminology from other OO languages to Labview so one person's "factory method" might be another person's "creator method." That is a sensible take on it, but I don't quite see how the exam's current format promotes that. Teaching is an interactive process between teacher and student. The CLA exam doesn't allow that at all. Furthermore, if I'm going to be teaching a junior developer I need to have a good understanding what he knows and what he doesn't know. The CLA guidelines simply say that someone else will implement the details; they don't give any indication about what these other developers know.
-
Agreed on all points. I hope NI continues to expand LVOOP's capabilities to bring it more up to date with other modern languages.
-
For that matter, you could just create a lookup table with each default object as the key and the fully qualified name as the value. You'd have to use Jon's technique to get the FQN the first time a message object is seen but the rest of the time it would be a much faster operation.
-
I really like this idea. (Maybe because I think I would do much better in that kind of test.) I don't know how practical it would be to do in real-life, but it is much more aligned with the skill set I think of when someone talks about an architect. You are of course correct--that is what the CLA is looking for. Much of my original post was misguided, but the one critique I do think is still applicable is the idea that an architecture should be designed and handed off to the dev team. A waterfall development process like that just doesn't work very well in my experience. (Unless you're building something that is a slight variation of something you've built 100 times before.) I don't think I would accept a job where a client wanted me to design a system and then go away while someone else implements it. For me, architecture is a process, not a deliverable. The architecture evolves as the implementation progresses. I'll have a high-level idea of the necessary functional components, their main responsibilities, and how they'll communicate with each other, but I don't bother trying to formally define all the details of each component's api since they will change as new discoveries are made and issues come up during implementation. The architecture is done when the application is done. A couple months ago I discovered a podcast called Software Engineering Radio. This weekend I was listening to Episode 87: Software Components. In it they said something that really struck a chord with me. To paraphrase, "Code is used to implement an architecture; it is not a good way to express an architecture." This is a major obstacle for me. I could explain my design to someone in an hour or two using a whiteboard and a few example vis. In the pre-exam overview I was told not to include paper documentation with the solution. I asked specifically about using hand-drawn state diagrams to illustrate allowable transitions and required transition conditions. The answer was no. In practice I'll often create the state diagram using a uml tool and paste it onto the block diagram. For the exam I'm required to communicate the design to unknown developers so they can implement it, yet the exam conditions eliminate the best way I have of doing that. I'm not sure how to deal with this in a way that results in points being awarded. Maybe I'll create a doc.vi for each component and just put notes and arrows on the block diagram to recreate a state diagram? No, but I'd have to give enough details that an over-the-wall developer could implement it. That means describing the details of the MessageQueue class, the Message class, and the ErrorMessage class. Then I also have to describe how they work together, how to use them in code, and how to create and use custom messages. In the end there's a lot of telling but very little showing. In principle I should be able to just create the public vis with the appropriate connector pane terminals and write a short note on the bd describing its behavior. In the case of the LapDog Message Library, describing it takes almost the same amount of time as fully implementing it. (Except for the Dequeue method; that would take a couple extra minutes to implement.) Almost all of the methods in the library are very thin wrappers or getters/setters. The value (imo) of the LDM stems from its structural organization and the collaboration of the classes, not any code magic inside it. I don't see any reasonable way to use it without recreating all the vis that are used. Unfortunately, creating the classes, methods, icons, descriptions, and inheritance hierarchy takes a pretty big chunk of time, and when I finally finish that task I haven't even covered a single requirement. Giving a specific reference to the library might help... I dunno. I know we can't have pre-built code. I assumed that also means we can't specify pre-built code in our solution. (IIRC, for this submission I actually created an LDM "lite," which was a few MessageQueue methods (Dequeue included, since that is a key part of the whole thing) built around a string-variant message type. I remember a couple times being frustrated with it and wishing I had the real library.) ------ Assuming anyone is bothering to continue reading this thread, don't take any of this to mean I'm opposed to certification. I doubt NI views training and certification as a primary revenue stream. I suspect it is driven by business needs. Customers want some indication of whether a consultant is worth his salt or blowing smoke, so NI created certification. I'm not particularly fond of the way the CLA is structured, but perhaps that is driven by customers too. If customers are asking for architects to do designs so they can be implemented by lower cost labor elsewhere, then maybe that's what NI should give them. Personally I think the customer will be much happier at the end of the day when the architect and developers are working together closely. If customers *are* asking NI for ivory tower architects I'd prefer they push back a little and educate customers about good software dev processes instead of enabling the customer to head down a path littered with failed projects.
-
Resolution: I had a phone conference with the grader, an in-house expert, and our local sales rep. They spent time before the call reviewing my solution and the grade that was given. The outcome wasn't changed, but I do have a much better idea of why the points were deducted. Using an object-oriented design was not an issue in grading. Neither was the (alleged) lack of technical ability on the part of the grader. I think my biggest issue (and Zaki can chime in if he wants to) is lack of sufficient documentation on implementation details. In some cases I figured the implementation details were self-evident. In other cases I thought the details were irrelevant from an architectural standpoint. And of course there were cases where I thought I put in more details than I actually had. Whatever the cause, my solution didn't include enough detail to satisfy NI's requirements. I haven't decided if I will resit for the exam. Being unable to use the LapDog Messaging Library is a huge disadvantage for me, as it is a central component in my desktop architectures. I can't afford to spend a quarter of my time (or more) recreating it from scratch. I'll probably work through the sample exam some more and see how much I can get done in four hours. The ironic thing is I failed high school english--twice--because I couldn't get my writing assignments turned in. (Plus most of the grammar taught seems largely pointless.) Then in my first year of college I scored well enough they asked me to work in the writing help center for credit instead of taking the usual composition class. I failed that too for the same reason. Go figure... Oh yes, writing and I have had a very rocky relationship. (Though I do have a slightly better relationship with her less glamorous sister, technical writing.) Heh... there's not enough time in the history of the universe for me to write a book. It's not unusual for me to spend 8-12 hours on a longer post, which maybe translates into 3 pages on a book. (I have been considering archiving a collection of essays though...) And less time to do things like... you know... earn money.
-
If you have a good relationship with your NI sales rep I'd start there. They can sometimes pull magic levers that aren't available to the average user.
-
Sometime you can get the course manuals for the classes for significantly less. Is that an option with those courses? Be sure to let us know what you think of the exam. As you've discovered, there's precious little information about it.
-
This thread attracted much more attention than I expected and I need to make a couple more comments: First, I was frustrated when I started this thread and the emotional part of my brain was preventing the rational part of my brain from getting a word in edgewise. Rereading it now there are things I said that were out of line and unjustified. Specifically, I questioned the technical abilities of the exam graders. I have never met any of the graders, much less looked at their code or talked to them about design issues. I have absolutely nothing upon which to make that claim. I have seen how NI constantly tries to improve their processes, from the Idea Exchange, to completely reworking the OOP courses, to revisiting exam format and content. I honestly believe NI is a company that seeks excellence in more than just the profit and loss column, and I'm sure the certification department is the same. As Zack said, there are many possible reasons why I failed the exam. Most of them have to do with me and my solution. Others could be related to the grading standards. Given that at least two graders review every solution and typically come up with very similar scores, it is unreasonable for me to claim I failed because of their technical ability. My comment was unnecessary, uncalled for, and very unprofessional. I am truly sorry. Second, I have been extremely impressed at how NI has handled the issue. (Much better than I did.) The email with my exam results included the phrase, "exam results are final." When I responded to the email asking about an appeal process I fully expected to have them say, "nope, exam results are final." Instead, they forwarded my request to the grader who has scheduled a conference call to discuss my solution and is including people who are well-versed in OOP principles. Regardless of the outcome of the appeal, NI has far exceeded my expectations in how they have handled the issue. (I shouldn't be surprised; NI always comes across to me as a very customer-focused company.) You ever have that experience where everyone is telling you how great a movie is and you just *have* to go see it, and then when you do finally see it you think, "eh... I'm not sure what all the fuss was about." I'm the movie and I can assure you I'm no shoe in for a "Best Picture" Academy Award and far from making the "best movies of all time" list. My achilles heel for the exams is speed. Some people can bang out code very quickly--my strengths lie elsewhere. I really appreciate the vote of confidence. Sure it would be a nice ego boost to get the highest score ever (I'd be more surprised at that than I was at failing) but if I do resit for the exam I'll be content with the minimum passing score.
-

Confusion with Data Handling while using Objects
Daklu replied to Mirash's topic in Object-Oriented Programming
Good question. (And very fair, imo.) In general I'd use an adapter if the Clock class were already created and modifying the code is unfeasable, either because I don't have access to the source or the class is part of a reuse library and I can't change the api. For the application I'm hypothetically working on using an adapter doesn't save me much. I still have to go modify the app source code everywhere the class is used and replace the Clock class with the adapter class. It's pretty much the same amount of effort to rework the Clock method parameters directly. But I think Yair's question refers to how I would have originally designed the class. It really depends on what role I expect the class to play and what the objects are interfacing with: the UI, an external database, internet time server, etc. (If the classes were entirely internal to my app it'd make more sense to just use LV's native timestamp and skip the child class.) Most likely if it were a UI class I'd use a string (assuming I didn't want to use the timestamp controls on the UI) and if it were a data interface class I'd use one of the integer or floating point standards based on the number of seconds since some date. Also, sometimes I'll give a class multiple create methods for different styles of possible inputs. So for a UI Clock class I might have Create Clock(String), Create Clock(Int1904), and things like that. The output would always be a string though, since the purpose of the class in this situation is to represent the time for the user interface. -
Do you still have it? It would be very interesting to read. Good insight... I honestly think the CLA is mis-named. I don't know what it should be called, but there is so much stuff architects should know that isn't covered by the exam that I have a hard time believing a CLA is equivalent to an architect in other languages. The CLA seems to focus on leading a small group of developers implementing a feature rather than designing a suitable architecture for a large application. Maybe "Lead Developer," or "Feature Lead," or even "Small App Architect," or something like that? I'm also not sure there is a realistic way to test and certify what I think of as an architect. Yeah, I read that. I'm not there yet. While I think I am qualified for the CLA title, even if all my LV knowledge were transferred to another language I wouldn't consider myself an architect in that language. I don't think differentiating between a CLOOPA and a CLA is a good idea. The fact of the matter is LV supports OOP now. More and more people are exploring it and using it to develop applications. An architect should have the breadth of knowledge to understand how to develop procedurally or develop using OOP, and understand the tradeoffs of using one versus the other.
-
Thank you all for the encouragement. I really appreciate it. I had actually responded to the email requesting an appeal (with more details about what I thought was wrong) before posting here. My request was forwarded to the grader, who sent me an email today. We're trying to set up a phone call to talk about it on Wednesday, but at the very least he'll review my solution based on my comments and send me an email. I have no idea if it will change the results, but at least I'll get a chance to explain the architecture I used. Yeah, and it's arguably the one where the specific answer (in this case the code) matters the least. Thank you, but in fairness I should point out that I'm really not one of the more experienced LV devs. I'm a relative babe in LV-land--I only started using it 5 years ago. There are LOTS of people here who have far more experience than me and whom I still learn from every day. I agree the exam is not the time to try clever new stuff--I didn't think I was being clever. I just used the same principles and ideas I use in most of my desktop apps. OOP is so ingrained in the way I think about problems trying to do things the 'old school' way is a sure path to failure. I can't speak to the training as I've never taken any NI courses, but I agree there are many aspects of LV programming standards that seem to be stuck in 1987. You mum is very wise. I often have the same problem you had. In this case I guess I thought they wanted what they asked for. AQ's success with an OO solution to the CLD a while back led me to believe they would be more open to non-procedural solutions. --- I haven't decided if I'll retake the exam if the appeal isn't successful. I know the architecture I used is valid and I certainly won't change the way I program just to pass the exam. I guess I'll consider resitting if I feel like I get enough specific information on what was missing so I feel like I can submit a correct solution using the same basic patterns.
-
Perhaps some of our disagreement is related to our backgrounds. I spent a year writing microcontroller code in assembly and loved it. (I still dig out my stuff for fun on rare occasions.) When you're working that close to the metal software events don't exist. In your opinion, what is polling? What characteristics are required to call something polling? Based on your comments I'm guessing that it needs to be based on a real-world time interval instead of an arbitrary event that may or may not happen regularly? [Edit] You're right that windows doesn't poll the keyboard directly. But unless you're using a computer circa 1992 the keyboard doesn't generate interrupts either. The polling is done by the USB controller chip. USB is a host-driven communication protocol. Every so often the usb host sends out signals to the connected devices to see if they have any new information to report. If so, the host sends another message asking for the report. For mice the default polling interval is 8ms. Since mice only report the position delta from the last report, if you could move a mouse and return it to its original position before 8 ms has passed windows would never know the mouse had moved. You couldn't do that with an event-based mouse. USB Keyboards operate essentially the same way, except they probably use a buffer to store the keystrokes and pass them all to the host when the next request comes along to avoid missing keystrokes. [/end Edit] Ugh... your linked document in ancient! Try something a little more up to date. (It's been a while since I've read over it but I do keep it around in my reference library.) My guess is LV uses a hybrid approach as described in section 4 of the link. Specifically, I think they are using a Large-Grain Dataflow approach. Maybe "pure" dataflow is conceptual. Everything that can execute in parallel does. Every node has a single output that propogates as soon as the node finishes operating. Every node executes as soons as its inputs are satisfied. (I think the article refers to this as fine-grained dataflow.) The delay between when the inputs are satisfied and when the node is fired is due to the threading model of modern computer processors. In other words, variable execution time isn't a property of dataflow, it's a side-effect of implementing dataflow on the von-Neumann architecture. That raises the question... what about writing LV code for an FPGA? They can run many more (albeit much shorter) parallel "threads" than a pc cpu. I would think FPGA programming would benefit a lot from writing code in "pure" form.
-
The links are very good. Thanks for posting them. I don't think you are understanding what I am trying to say. I'm talking about the entire software stack... user application, Labview runtime, operating system, etc., whereas you are (I think) just talking about the user app and LV runtime. Unless the procedure is directly invoked by the hardware interrupt, there must be some form of polling going on in software. Take the timer object in the multimedia timer link you provided. How do those work? "When the clock interrupt fires, Windows performs two main actions; it updates the timer tick count if a full tick has elapsed, and checks to see if a scheduled timer object has expired." (Emphasis mine.) There's either a list of timer object the OS iterates through to see if any have expiered, or each timer object registers itself on a list of expired timer objects then the OS then checks. Either way that checking is a kind of polling. Something--a flag, a list, a register--needs to be checked to see if it's time to trigger the event handling routine. The operating system encapsulates the polling so developers don't have to worry about it, but it's still there. How is it relevant to our discussion? You said dequeue functions break dataflow because they are "event-driven." I'm saying "event-driven" is an artificial distinction since software events are simply higher level abstractions of lower level polling. What about the discussion where AQ said the queues don't poll? Under certain circumstances--the number of parallel nodes is equal to or less than the number of threads in the execution system--the execution system may not do any polling. (Though the OS could on behalf of the execution system.) However, he also said this: "If the number of parallel nodes exceeds the number of threads, the threads will use cooperative multitasking, meaning that a thread occassionally stops work on one section of the diagram and starts work on another section to avoid starvation of any parallel branch." (Emphasis mine.) Windows uses pre-emptive multitasking to decide when to execute threads. The application, or in this case the Labview RTE, decides what is going to be executed on each thread. The cooperative multitasking has to be implemented in the Labview RTE. I ran a quick check and spawned 50 different queues each wired into a dequeue function with infinite timeout, then used Process Explorer to monitor Labview's threads. As expected, LV didn't spawn new threads for each sleeping queue, so it's safe to say the os thread doesn't necessarily sleep on a waiting dequeue. According to that discussion LV8.6 apparently uses a strategy similar to what I described above in wild speculation #2. The dequeue prim defines the start of a new clump. That clump stays in the waiting area until all it's inputs are satisfied. Assuming all the clump's other inputs have been satisfied, when the enqueue function executes the queued data is mapped to the dequeue clump's input, which is then moved to the run queue. What happens if the clump's other inputs have not been satisfied? That clump stays in the waiting room. How does LV know if the clump's inputs have been satisfied? It has to maintain a list or something that keeps track of which inputs are satisfied and which inputs are not, and then check that list (poll) to see if it's okay to move it to the run queue. Having said all that, whether or not the dequeue function polls (and what definition we should use for "poll") isn't bearing any fruit and seems to have become a sideshow to more productive topics. (You are of course free to respond to any of the above. Please don't be offended if I let the topic drop.) No, but the operating system does. I assume you're referring to an os thread here? In LV8.6 it looks like that was true. In one of the threads AQ went on to say, "All of the above is true through LV 8.6. The next version of LV this will all be mostly true, but we're making some architecture changes... they will be mildly beneficial to performance in the next LV version... and they open sooooo many intriguing doors..." and we know they made a lot of improvements for 2010, so the clumping rules may not require that anymore. My understanding is the clumping *is* the optimization. But your comment raises a very good point... In a dataflow language if the clumps are too big parallelism suffers and performance degrades. If the clumps are too small a disproportionate amount of time is spent managing the clumps and performance degrades. The best thing we can do (from an efficiency standpoint) as developers is let Labview make all the decisions on where and how to clump the code. (That means don't enforce more serialization than is necessary and don't write code that requires clump breaks.) As computer hardware and compiler technology improve through yearly Labview releases, recompiling the app will automatically create clumps that are the "best" size. So maybe when AQ talks about "breaking" dataflow, he is talking about stuff that forces a clump boundary? (Edit - Hmm... that doesn't seem quite right either.) It's applicable whenever a queue only has a single enqueue point and a single dequeue point. There are other cases where depending on how it has been coded it could be resolved with multiple enqueue points. In principle there are lots of places where a queue could be factored out completely. If the dynamically loaded vi is included as part of the executable build, then the compiler would know that it cannot replace the global. I admit I don't know what would happen if the dynamic vi were not included in the executable, loaded during runtime, and tried to write to the global variable in the executable--I've never tried it. Assuming it works, then constant-source obviously isn't the right way to determine if dataflow is broken. ------------- [Edit] Excellent point Ben. Maybe we need to make a sharper distinction between edit time dataflow and run time dataflow?
-
These Kudos belong to Aristos Queue. He's the one that shared that tip with the forum.
-
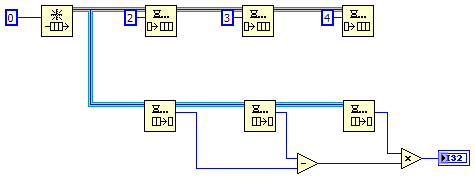
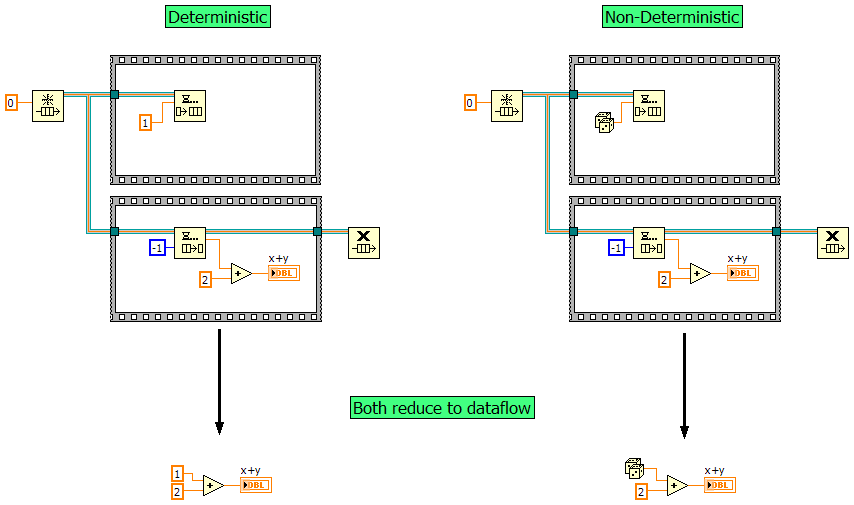
Something occurred to me this weekend while puzzling over these questions. Earlier I suggested the compiler needed deterministic code to be able to reduce it to explicit dataflow. I don't think deterministic is the right word to use. As this diagram illustrates, non-deterministic code can be reduced just as easily. What allows the reduction is that the code is robust against variations in timing. Regardless of which branch (the enqueue branch or the dequeue branch) starts executing first or the amount of time that passes between when they start, there is only one possible data source the add function's upper terminal map to--the constant 1 or the random function. Perhaps that is what AQ is referring to as "dataflow." That gives us three different kinds of dataflow. I think all are valid, they just view it from slightly different perspectives. [Note: I'm defining "source node" as something that generates a value. Examples of source nodes are constants and the random function. Examples that are not source nodes are the dequeue and switch function outputs, although these outputs may map back to a single source node depending on how the source code is constructed.] Explicit Dataflow - (Jason's interpretation.) Data always travels on visible wires from the source node to the destination. Maintaining explicit dataflow promotes code transparency and clarity, but explicit dataflow is not required by Labview. Breaking explicit dataflow may or may not change how the program executes at runtime. Constant-Source Dataflow - (My interpretation of AQ's interpretation.) Every input terminal maps to a single source node. Maintaining constant-source dataflow allows the compiler to do more optimization, resulting in more efficient code execution. Breaking constant-source dataflow requires run-time checks, which limit the compiler's ability to optimize compiled code. Execution Dataflow - (My interpretation.) At runtime nothing executes until is has all the data it needs. This refers to how the execution environment determines which clumps are ready to run and is what makes Labview a dataflow language. It is impossible to "break" execution dataflow in Labview. I'm waffling a bit on the naming of Constant-Source Dataflow. I considered "Temporally Robust Dataflow" as a way to communicate how variations in timing don't affect the outcome, but I didn't really like the wording and it puts a slightly different emphasis on what to focus on. It may turn out that constant source dataflow and temporally robust dataflow mean the same thing... I'll have to think about that for a while. Oh gawd. I think my brain has been taken over by NI... I am unable to differentiate between "queue" and "cue." (I kept looking at that thinking something doesn't seem right...)
-
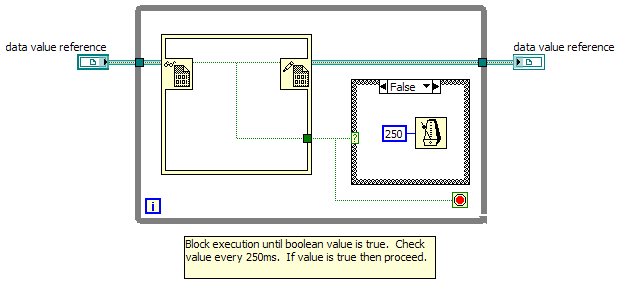
First, apologies to Steve for totally hijacking his thread. But notice it doesn't stop me from continuing... Ooooo... "explicit dataflow." I like that. It emphasizes visible dataflow for the programmer without undermining what dataflow really is. And instead of queues, etc. "breaking dataflow," they simply use "implicit dataflow." I don't claim any special knowledge either--just what I've picked up from various sources. I think you are mostly right, but let me try to describe my understanding... Labview has 26 different "execution systems." There are 6 named systems: UI, standard, instrument i/o, data acquisition, other 1, and other 2. UI is a single execution system. The other five named systems are actually groups of 5 different execution systems, one for each priority level. So there are independent execution systems named standard-high, standard-normal, standard-background, etc. Unless users explicitly assign a vi to a different execution system, the code runs in standard-normal, so from here on out I'm referring to that execution system. The execution system is assigned some number of operating system threads--some literature says two threads per cpu core, other sources say four. There are a couple places where I think you're slightly off mark. First, there is a single clump queue for each execution system, not for each thread. Clumps are added to the queue (by Labview's scheduler?) when all inputs are satisfied. The execution system assigns clump at the front of the queue to the next thread that become available. Second, when the dequeue prim is waiting for data, the thread is not put to sleep. If that happened then two (or four) dequeues waiting for data would block the entire execution system and nothing else would execute. There are a few things I can think of that might happen: <wild speculation> 1. The clump containing the dequeue prim signals the execution system that it is waiting for data. The execution system pulls it off the thread and puts it at the back of the queue. When it gets back to the front of the queue the execution system gives it to a thread and the dequeue prim checks the queue again to see if there is any data ready. So while the dequeue does "sleep," it also is woken up periodically to check (poll) the queue. One way to look at this is to imagine the queue refnum is a clump input and the data returned is a clump output. 2. Labview's clumping algorithm essentially divides the dequeue prim's functionality into separate pieces--the waiting and the fetching. When the compiler reaches a dequeue prim that has to wait for a future action it says, "I can't clump effectively beyond this point, so I'll stop here." The wait clump has the queue refnum as an input but no data output. (I think it would have to have send some sort of sequencing signal to the fetch clump to maintain sequencing though.) During execution the wait clump finishes executing even if the dequeue is waiting, so there is no need to put it back on an active thread and check to see if there's data available. The fetching clump includes the operations downstream from the dequeue prim and has two inputs, the sequence signal from the wait clump and the data input from the enqueue prim's clump. Since it hasn't received data from the enqueue clump, the fetching clump sits in the waiting room, that area reserved from clumps that are not ready to execute. Option 2 is potentially more efficient since it doesn't require repetively putting the same clump back on an active thread to check the queue for data. (There is still "polling" though, it has just been pushed off to some function--using a different thread altogether--checking all the clumps in the waiting room.) Option 2 is also way more complicated and I haven't been able to figure out how that kind of implementation would exhibit the behavior we see when two or more dequeues are working on the same queue. </wild speculation> I'd be really surprised if an OS passes access to the system timer interrupt through to Labview. First, no operating system in the world is going to allow user level code to be injected into the system timer's interrupt service routine. (Queue Yair linking to one... ) ISRs need to be as short and fast as possible so the cpu can get back to doing what it's supposed to be doing. Second, since the OS uses the system timer for things like scheduling threads it would be a huge security hole if application code were allowed in the ISR. The OS kernal abstracts away the interrupt and provides timing services that may (or may not) be based on the interrupt. Suppose my system timer interrupts every 10 ms and I want to wait for 100 ms. Somewhere, either in the kernal code or in the application code, the number of interrupts that have occurred since the waiting started needs to be counted and compared to an exit condition. That's a kind of polling. Here's more evidence the Get Tick Count and Wait (ms) prims don't map to the system timer interrupt. Execute this vi a couple times. Try changing the wait time. It works about as expected, right? The system timer interrupt on windows typically fires every 10-15 ms. If these prims used the system timer interrupt we wouldn't be able to get resolution less than 10-15 ms. There are ways to get higher resolution times, but they are tied to other sources and don't use hardware interrupts. I'll be around. Post a message if you have questions. (I might see it quicker if you send me a pm too.)
-
Well, I finally got my CLA exam results and it turns out I didn't pass. Yeah, I'm more than a little surprised and disappointed, but for what it's worth here are some of my lessons learned from the process. Maybe they'll be useful to others preparing to sit for the exam. Or maybe I'm just venting... 1. Don't use object-oriented design patterns. Before the exam our local sales rep hosted a call with an exam grader, and he indicated using LVOOP (or GOOP) was acceptable. I can only assume that means they don't reject it out of hand. I used facades, mediators, and an object-based state machine, all of which are common in other languages, yet apparently are unrecognizable to the graders and/or grading rubric. 2. Be careful how you break the app into components. For example, in the sample exam there are a couple security requirements listed. I was dinged hard on several items for what would be equivalent to "Security module not designed." Notice there is no requirement listed for a "security module," there are only security requirements. That my design satisfied the listed requirements is irrelevant--no security module, no points. This one really rubs me the wrong way. One of the primary things an architect does is figure out how to break the requirements into functional components. Forget about balancing the tradeoffs between different options; the only right way is NI's way. 3. Assume your design will be thrown "over the wall" to developers who have been outsourced. I'll set aside the fact that the "ivory tower architect" scenario is a failed development process and just accept that I don't get to explain any details to the developers. That is sort of implied in the exam requirements. However, even though in the exam's hypothetical architecture scenario I'm handing the design off to our developers, apparently it's a mistake to assume they might have become familiar with some of the patterns we've been using in our time together. In fact, it appears the requirement is that design can be handed to any random developer and he'll know what to do with it. (I guess NI expects architects to micromanage the implementation details.) Sour grapes? Yeah, probably a bit. Disillusioned with the certification process? Oh yeah. Disappointed that I won't be able to attend the architectural summit next year? Definitely. That's been my entire motivation for pursuing certification. Oh well, life goes on... [Edit - After reflecting on the issue for a couple days I posted some thoughts on this post here.]
-
Confusion with Data Handling while using Objects
Daklu replied to Mirash's topic in Object-Oriented Programming
Yep, which is one of the reasons why the solution works for you. To reiterate and make absolutely clear to anyone bothering to read this, I'm not claiming your solution is wrong or inferior to any other solution. I'm not claiming there are insurmountable obstacles that can't be resolved with your solution. I'm just pointing out potential consequences of the various designs to the OP, who as a Labview user just starting in LVOOP, probably doesn't have any idea how much these early decisions can affect future changes. (I know I didn't.) It significantly limits my ability to meaningfully override the method in a child class, because the custom type defined by the parent class' method often does not match the custom type I need for the child class' method. For example, let's say I make a Clock class with a SetTime method. To make it "easy" for end users I gave the SetTime method an input cluster with 3 integers representing hour, minute, and second, and an am/pm enum. Then suppose for some reason I need to create a MilitaryClock child class that only publically supports 24 hr time representation. What are my options? -Assuming I have access to Clock's source code I could edit the am/pm enum and add a third option, "24hr." Except now I have a parent class method for which only two of the three options are valid and a child class method for which only one of the three options is valid. Why would a MilitaryClock.SetTime method, which handles time representations in 24 hr format, have an option to enter it in 12 hr format? -Another option is to create a new method in the child class, Set24HrTime, and duplicate the input cluster without the am/pm enum. This makes that particular method call more straightforward, but the overall api isn't much better. The end user still has the option to call Clock:SetTime (using 12hr format) on a MilitaryClock object, which according to the business rules shouldn't be possible. Now I'm stuck overriding the Clock:SetTime method and throwing an error, which enforces the business rules but makes the api even uglier. Neither option is very satisfying. I don't think there is a really clean way to implement the MilitaryClock class without eliminating the cluster from the parent's SetTime method. That's the kind of stuff I meant when I said I often end up with poorly constructed code when I use clusters as part of a class' public api. Clusters are a user-defined type, and when I use them I tend to define them for the specific use case I am working on at that moment... you know, so they're "easier" to use. (Again, your approach isn't wrong, it just contains a different set of tradeoffs.) ------- By the way, in your Compensator.init method above you have errors generated within that vi overwriting errors coming in on the input terminal. Is there a specific reason you do that? I usually prioritize all input errors over errors generated within the vi itself (or within its sub vis) simply because the current vi might be failing because of an error that occurred previously, and I want to know about the first error, not the last error. Of course, this vi doesn't have any other inputs so it doesn't really matter that much, but I was just curious... -
Confusion with Data Handling while using Objects
Daklu replied to Mirash's topic in Object-Oriented Programming
Yeah, that's what I was thinking about when I responded. I'm not questioning that it's a good solution given your requirements and use case, it just make certain kinds of functional extension a little more difficult. For example, maybe the configuration parameters need to be adjustable by the end user at runtime through a dialog box or something. Ideally that could be implemented without changing the DataAcquisition class since nothing about the data acquisition instrument or data collection has changed. This gets back to the separation of concerns and the idea that a class should only have one reason to change. The revision update issue is one reason. Using a cluster on the conpane also significantly limits my ability to meaningfully override the method in a child class. But I have also found that when I use clusters as method parameters I tend to design my code for specific situations instead of thinking about it in more general terms. I end up with poorly constructed code and confusing class apis. Sometimes I've constructed classes similar to superclusters where only part of the data has any meaning. That could be a big reason it is working out so well for you. -
I'll take your word for that since its not something I've ever tried. However, if the dynamic vi is part of the project being built then the compiler will know about it and won't be able to perform that reduction. I'm not trying to say the reduction can always be done, only that it can sometimes be done, (which I think is clearly illustrated by examples 1 and 2.) If the reduction can be done sometimes, then using a queue cannot be sufficient reason to claim dataflow has been broken. Yep, you're right. I was thinking the queues would be released when the sub vis exited. That what I get for mixing programming languages... Let me try to explain it a little differently... "Dataflow" is something that occurs in Labview's execution environment. Defining "dataflow" in terms of visible wires on the block diagram doesn't make any sense because there is no "wire" construct in the execution environment. What we see as wires on the block diagram are simply graphical representations of assigning memory pointers. When we hook up a wire we're declaring, I am assigning the memory address for the data in output terminal x to the memory pointer defined by input terminal y. How can Labview be a dataflow language if we define dataflow to be something that doesn't exist? I agree with you that we should favor visible wires over "invisible" data propogation when possible--it helps tremendously with code clarity. I'm just saying that interpretation doesn't seem to accurately describe what dataflow is. I was thinking about cpu operations when I made the original comment. ("Somewhere down in compiled code...") Application events don't map to cpu interrupts. Somewhere down the line a form of polling has to occur. Labview abstracts away all that low level polling and thread management, but it still happens. The point being, from the perspective of low level code there is little difference between a vi waiting for something to be put on a queue and a vi waiting for some amount of time to expire. I can't argue with you there. I just can't help but think we can come up with better terminology that doesn't overload the meaning of "dataflow." ("By-value construction" doesn't really accurately describe what you're talking about either. Maybe "directly connected?" "Referenceless?" "Visible construction?" ) Aww... don't go away. I learn a lot from these discussions.
-
Confusion with Data Handling while using Objects
Daklu replied to Mirash's topic in Object-Oriented Programming
We can't answer that question. There are many solutions that work, each with advantages and disadvantages. The "best" solution depends on what your exact goals are. dpga's suggestion make the measurement instead of the data acquisition device a principal object in your application. Advantage - it might be easier to replace the hardware at a future date. Disadvantage - taking multiple measurements from the same device could be a little more confusing. Paul's suggestion works too. Advantages - simple to understand and fast to implement. Disadvantages - it couples the config file (and schema) to the daq object, which may make it harder to add flexibility later on. If you need to decouple the config info from the daq device in source code (meaning neither class is dependent on the other) then you should define an interface for the config class that returns all the config info using only native Labview types. One way I've done this in the past is by adding a Config:GetConfiguration method that returns a 2d string array containing keys and values for every config option. You could pass that into a Daq:SetConfig method that looks up the values for the keys it's interested in. Advantages - no dependencies, making it easier to reuse or vary either class independently. Disadvantages - overkill if reuse and flexibility are not primary goals. Personally, I try to make sure none of my class method parameters are clusters. Using clusters that way usually results in bad code smells for me.