silmaril
-
Posts
114 -
Joined
-
Last visited
silmaril's Achievements
")



-
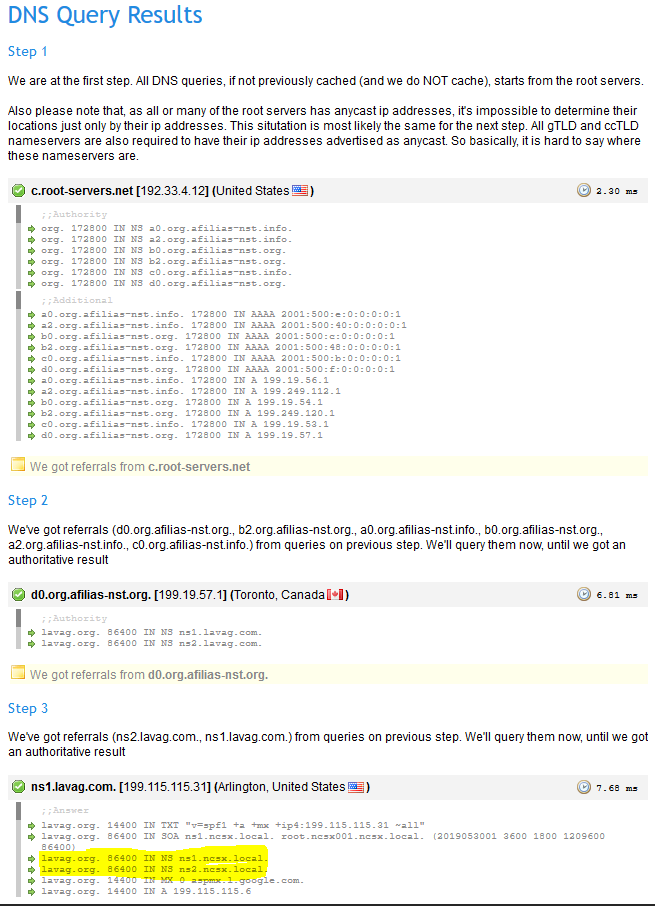
For several months I have been experiencing problems which end in the fact that my PC is not able to resolve the domain lavag.org. If it works or not depends on which DNS servers I configure in my system. I opened a support ticket with our IT department and they responded that the source of the problem lies in invalid DNS records that contain "ns1.ncsx.local" and "ns2.ncsx.local", which cannot be resolved (see attached screenshot). Could you please check your DNS records and fix this so I am able to use this forum with our company's standard DNS settings? Thanks! Rico

-
This looks great! Not just the comment feature - I think this is even more important: Numbers may be IEEE 754 positive infinity, negative infinity, and NaN. This is something I am really missing in JSON when working with LabVIEW floating point numbers.
-
I wasn't aware of this RFC - thanks for the link! One interesting aspect: It uses null-values to delete items, which means we should write our software to behave in the same way for a null-item and for a nonexisting item. In some cases this might leave us with the problem of how to correctly save a NaN value.
-
JSONtext is really a great help in our work - thank you very much, James! I was missing a function to merge JSON objects together recursively (since "Merge into Object.vi" is only considering one level of the data structure), so I wrote a VI that does this (see attached VI). I am sure this isn't the most efficient way to do this, so I am open for suggestions to improve the code. Would you consider adding this functionality to JSONtext? For anyone wondering why one would need this kind of merge function: Our use case is a modular configuration file structure, in which a complex configuration resides in one large JSON object. Each JSON file may contain references to include other JSON files into the current configuration. This enables us to structure the test configuration for about a hundred similar but different items in a reasonable way. Even if wrote "large", the JSON files are still small enough that the performance of the merge function is no issue for us. JSON_Merge_Recursively.vi
-
The primary use case would be read-only, which could be covered perfectly by a strip comments function. The drawback of this is that it makes any programmatic changes to the config files impossible... ok, not really impossible, but changing one item destroys all the comments in the file If there is some elegant way to simply ignore comments and keep them in place when changing values without slowing down the core functionality - that would be great! But I do understand that this is very difficult at least. And I have to admit that I currently don't have any use cases where config file changes have to be written programmatically, so your suggestion sounds like the appropriate solution to this. That depends on the way you look at your file. If it's "JSON with comments", the JavaScript style is appropriate. If it's "the JSON part of YAML with comments", the YAML style is the way to go. I am in favour of supporting all three of them in the additional "fix it up function". As James pointed out, performance is no concern in this use case. To get into the technical details: This would mean we have two kinds of comments: Line comments: start with a marker symbol sequence; end with the next EOL or EOF. Block comments: start with one marker symbol sequence, end with another marker symbol sequence. I think we should add a convention for line comments: They should only be allowed outside of strings, otherwise we could destroy perfectly valid string values or object names. I would also define that the marker must be preceded by some kind of whitespace (space, tab, CR, LF) or be at the beginning of the file.
-
Hi, I woul like to discuss an idea to extend the funcionality of JSONtext. We would like to use JSON as configuration files to replace INI files without the complexity of XML. This works great from the technical point of view. There is only the drawback that JSON does not support comments in the text, which makes it harder for humans to edit the files. The YAML file format supports comments and it claims to be a superset of JSON: http://www.yaml.org/spec/1.2/spec.html#id2759572 I am not asking to build a complete YAML library (even if this would be a great thing, too), but I was asking myself if it made sense to add support for YAML comments into JSONtext. This might have to be optional, since it would not comply with the original JSON specification. If active, all code searching for the different markers inside the JSON string would have to check for "#" characters that follow whitespace and ignore everything up to the following line end (with the exception of "#" inside strings). I am not sure about the implication this would have for code writing to the JSON string (the "Merge ..." VIs). And of course this would lead to the demand for a function that strips the JSON-string of all comments to convert it to valid JSON that can be used with other APIs. What do you think?
-
The real cool feature of Single Element Queues is that you can use them as a kind of global variable! It comes with an integrated semaphore mechanism which helps prevent race conditions (in fact it's the other way round: take a look at LV's semaphore VIs and you will see that they are using Qs internally). And it can help you to minimize data copies! Imagine you have an array of one million double value inside an SEQ and you want to read one element from it. Using the standard dequeue-enqueue mechanism will only make a copy of the extracted element, not of the complete array, since the array buffer can be reused. Reusing the buffer is only possible in Qs, not in notifiers, since in a notifier the data has to stay inside it in case another process wants to read it afterwards. Of course the same is true for "Preview Queue Element", so you should not use this if you only want to read a part of the data inside the SEQ.
-
Many customers want some kind of password protection for their configuration. But at the same time, most of them don't want anything too complex (aka expensive) or bothersome to work with. So we often end up with an application that can be used without logging in and a password to get administrative privileges (or sometimes two levels of passwords). The problem with this: If it's only a password with no connection to individual user names, you can be sure that everyone will know it rather sooner than later. In many cases you will find a post-it with the password on the screen after three days. If each user has his own password, you need to have a user management interface and someone has to create all the users. This might perhaps be done at the initial setup, but after three months, everyone will usually log in as "admin" with the password "1234". The only thing I can image that really works, even in "undisciplined" environments (aka 90% of the industries): Have the user identify himself with his legic chip. The same one that he uses to pay for his coffee from the vending machine and his lunch from the factory canteen. People usually tend not to give those away to others carelessly. It might even be possible to encode the priviliges in the administrative interface in the office that hands out these chips. This way there would be no need to have any user administration on the machine. I've never actually tried this, but I'd really love to.
-
The Lone Ranger LabVIEW programmer is certainly one of the big problems. How are you supposed to get better without the possibility to have frequent discussions about your work with other competent people? One way to help solve this: Consider getting external input. There are companies out there with a lot of expertise in LV programming from which you can buy some consulting / coaching time (eg. NI Allicance Partners). What's important from my point of view is that you don't simply buy an engineer who writes the code of your project, they should commit themselves to transfer knowledge, so you really learn some new concepts. It might be a good idea to go through the design phase of a new project together. If this is done properly, you should be able to do the implementation on your own afterwards (or maybe decide to share the work if the deadline is close). One difficult point with this can be convincing your boss that this is a worthwhile investment in the skills of his employee and that this does not mean you are not good at your job. In contrary: You have reached the limit of what you can learn on your own and the official LV classes can only get you so much further on your way to becoming better and better at your job. Disclaimer: I should admit, that this posting is not totally unbiassed, since my company might profit from people who decide to book some coaching time after reading this.
-
We are using Perforce with LabVIEW (and other languages) for almost seven years now. It turned out to be a very reliable SCC solution. There is one more thing you should consider at an early stage: Which file types are treated as binary files and which as text files? And which files should be locked automatically when they are checked out? I recommend taking the time to read about the Perforce Typemap and then setting up your own typemap that will apply to any new files on the server. Here are the lines dealing with typical LabVIEW file types from our server (please ignore syntax highlighting): binary+l //....vi binary+l //....vit binary+l //....ctl binary+l //....ctt text+l //....lvproj text+l //....lvlib text+l //....lvclass text+l //....xctl text+l //....xnode Yes we are quite conservative when it comes to parallel editing of XML files, because merging them usually is a pain in the butt. So we lock them automatically on checkout.
-
If you are worried about performance and memory usage, why add an unneeded sort? I don't know which sorting algorithm "Sort 1D Array" uses, but I think I've heard it's Quicksort. This algorithm needs an especially large number of iterations, if the input array is already sorted. We wouldn't want to waste CPU time and memory on sorting a few thousand strings that are already in the correct order, just because of incomplete documentation. AQ: Thank you very much for your reply! You are really succeeding in optimizing the quotient helpfullness / number of characters in answer.
-
Does this only happen in the "Program Files (x86)" directory? Was this file created newly? This is a long shot, but maybe it has something to do with access privileges and the way Windows virtualizes writes to directories that you should not write to? Maybe for some reason, DIR shows the virtual directory content, but LV sees what's really there, because it used the wrong file API functions? Can you see this file in Windows Explorer? Can you see it when you log in as another user?
-
I think it's great to have those functions that "convert" between a class path and a class object. That's all we need for plugin architectures. What I don't understand is why there are no functions to help us use classes and their names in the same way they are addressed inside LV. If I want to open a VI reference, I can chose between two ways: use the VIs path on disc (plugin) or use the VI name to get a reference to a VI that's already in memory. Once I have the VIRef, there are properties to get both name and path. Why is there no way to do similar things with classes? I'd really like to have a function to get the FQN from an object. In addition, it would help a lot to have it the other way round: Create an object with it's default value from it's FQN. I really don't understand why I have to meddle with a path on disc, when dealing with a class that's already been loaded into memory.
-
It's good to see that the essence of your solution is the same as mine, even if you chose quite a different way for the actual decoding algorithm. So there are at least two people who would like to have this functionality in LV. I'm wondering if this is enough for NI to include this feature in a future LV version?
-
We couldn't find a VI or primative in LV that gives us the Full Qualified Name (FQN) for a given LVOOP object, so we came up with our own function to do this (see attachment, LV2010 SP1). What I mean by Full Qualified Name: This is the name of the class including it's complete namespace hierarchy, for example if the class "MyClass.lvclass" is inside "MyLib.lvlib", which itself is part of "BigLibrary.lvlib", the FQDN for the class would be "BigLibrary.lvlib:MyLib.lvlib:MyClass.lvclass". Problems I see with the current solution: It was created by reverse engineering. There might still be some special cases in which it doesn't work correctly or it might stop working in future LV versions. The implementation creates a temporary copy of the object. This might slow down the application, especially when using objects that contain large data sets. This should not be necessary just to get the object's name. Any ideas for improvements? I am sure this functionality is already implemented inside LV, since we can see the FQN string in several places already (Variant display, object probes, ...). Is there really no way to call this internal functionality from a LV application? Our use case for this is a complex object oriented messaging architecture, in which we want a debug module to be able to show the difference between "Module1.lvlib:Init.lvclass" and "Module2.lvlib:Init.lvclass". Get_LVObject_FullQualifiedName.vi