Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
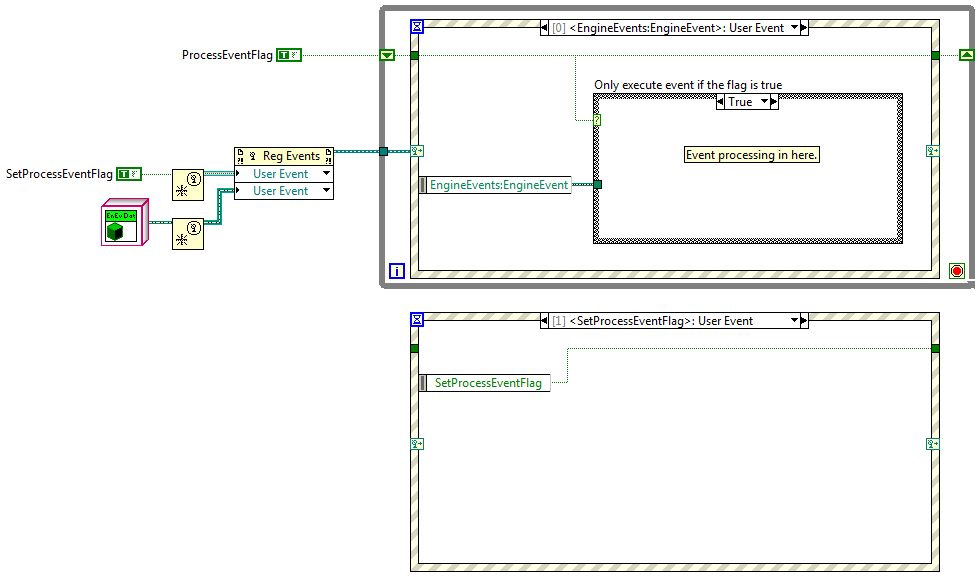
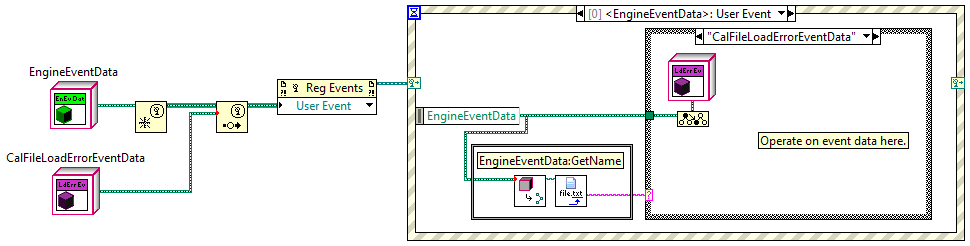
(Three posts in a row by me... apologies to anyone who considers this spamming...) I understand why the registration wire has to be strongly typed. Thinking out loud, is there a reason the strong typing has to propogate back to the user event wire? Wouldn't it be possible to allow the user event wire to be polymorphic and have the Register for Events prim create the registration wire assuming the event data object will always be that type? Obviously the Reg Events prim would have to throw a runtime error if a child object is on the user event wire at runtime, but there are other things I can do with a user event wire that don't include the Reg Events prim. If this were possible I could have single RaiseEvent and Destroy events methods that operate on any event that carries a child of my EventData class. It seems odd that other containers, such as clusters and arrays, can polymorph when they contain classes, but user events cannot. I get why they can't, but it creates an inconsistent programming environment. Are there other user event use cases that would get messed up if the user event wires were polymorphic? [Edit - Hopefully this is a simpler request. Would it be possible for the Reg Events prim to list the user events by name instead of just calling them all "User Event?"]
-
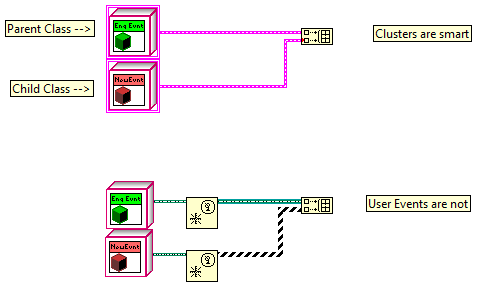
I actually did start out by casing out based on class name as I showed in the first diagram of post #3. The paragraph following that diagram explains why I don't really like using that as a general purpose solution. The main difference between out code is that I'm using events across code module boundaries. The event producer is in one module, the event consumer is in another. The producer doesn't know anything about the consumers that are observing it. I can't include consumer code in the producer without coupling the producer to it, which drastically reduces my ability to reuse the producer. In your code the event classes, which would be in the event producer, contain the code that actually executes when the event fires at runtime. I'm looking for a way that allows the consumers to execute their own arbitrary code at runtime. The event data classes are (currently) nothing more than generic containers for data. By putting the event data in a class and providing getters to the client for retrieving each piece of data, I can add arbitrary data elements to the specific event data class and supply a new getter for it without having to worry about breaking any client code. Since each event the producer exposes has a unique set of data elements I can't put all the getter methods in the parent class and override them in children without really making a mess of the EventData api. The getters have to be unique to each child class, which means the object that pops out of the event structure when the event fires needs to be typed as the correct child class at design time. (Either that or the consumers have to downcast the object at runtime, which I mentioned above.) Yep, it does. Replacing the registration refnum with a constant hadn't occurred to me until I was composing my previous post. Looks like I've been missing the boat on this one.
-
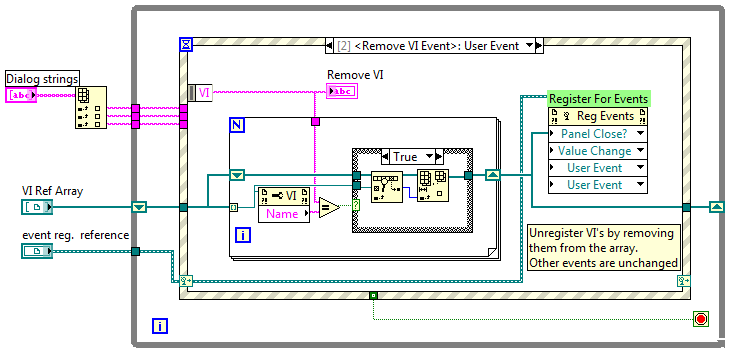
The event would be in the source code and the event structure would have all the code to handle any events it ever expected to receive, it would just be a runtime decision if and when the event structure actually receives those events. In the past I've handled it by maintaining my own flags in the event code; I just wish there were a better way to do it. It feels a little clumsy to have to carry an array of flags through the event loop and enclose all the event processing in a case statement. The dynamic event example included with Labview unregisters for events from specific VIs by removing that vi ref from an array and reregistering the vi ref array. It's not quite the same as what I'd like to be able to do but it might be an avenue worth exploring. Suppose the developer wanted to unregister for one of the user events. Is there a preferred way of doing that? I suppose you could effectively unregister for a user event by registering a dummy event in it's place. I don't think you need to worry about memory leaks from the dummy user event since it's a constant rather than a runtime creation. However, I don't see any way of reregistering that single event when the event consumer is only given the registration wire instead of the user events themselves. Thoughts on this technique? The naming issue is fairly easy to solve by simply relabelling the parent class at the upcast. The side effect is that it isn't clear to the event consumer that they need to downcast the object in the event structure, but what are you going to do? The original purpose of making all the event data object siblings was so I could send any of them through a single event and use a common GetName method. Given that it's more beneficial to give the client each user event independently maybe there's not point in deriving them from a common parent. I'll have to think about this for a while. As always, I appreciate your thoughtful answers and the time you spend responding to users on the forum.

-
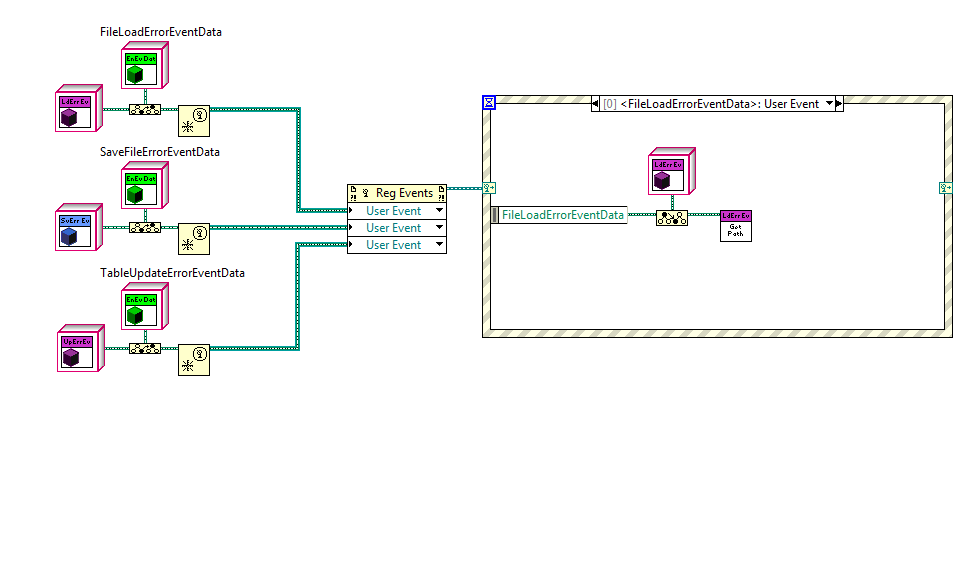
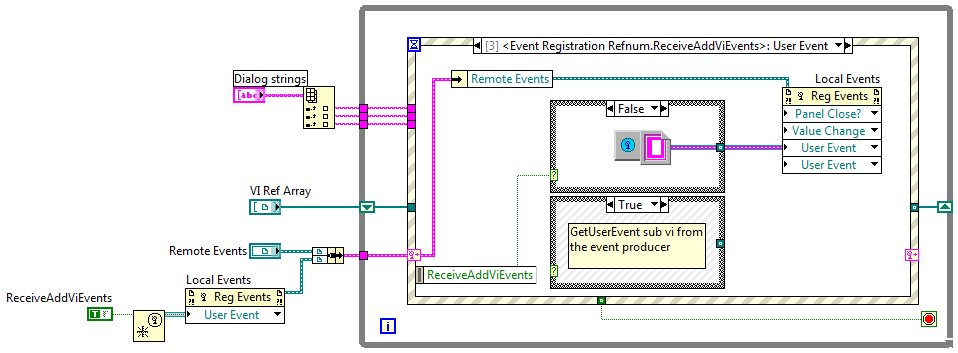
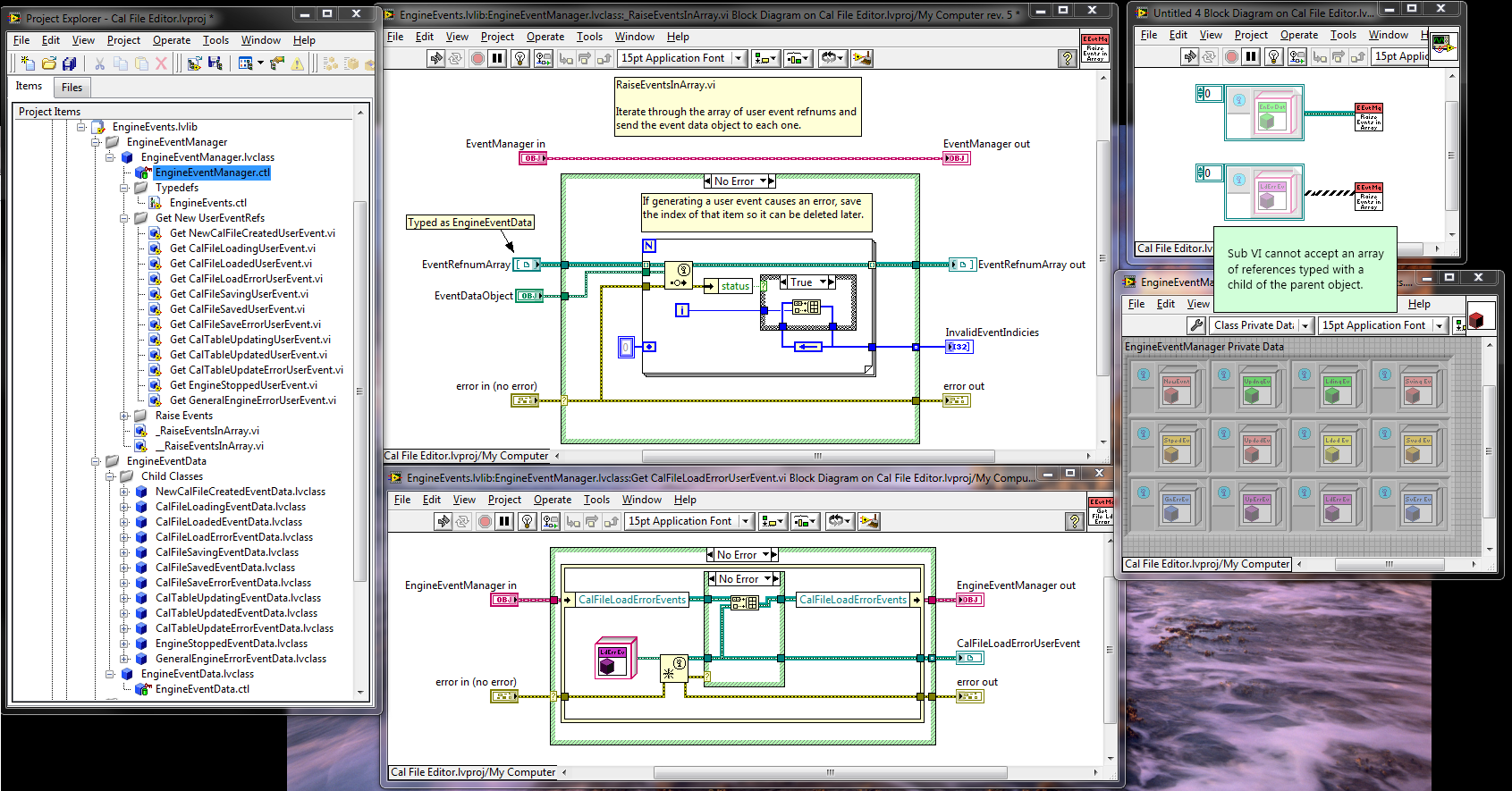
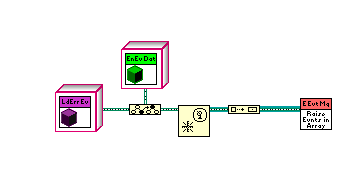
I wasn't actually trying to put different events in the same array. That was just a quick test I threw together when I realized what I was trying to do wasn't working. This is probably way more information than you want, but since you suggested it might be possible to add the functionality I figured I better explain exactly what I was doing. (BTW, this is in 8.6.1) I'm building an application using the Model-View-Controller architecture. I'm creating the app engine (Model) as an active object. (I'll be doing it with the UI too, but I'm not at that point yet.) The engine exposes user events to notify clients of what's going on. I'm not sure exactly what events the engine will need to expose or what data each event should include, so I wanted to make it as easy as possible to add new events or modify the data in existing events, preferably without breaking client code. This led me to try encapsulating all the event data in classes. My first cut was for the engine have a single event of the parent EventData class type. I passed the appropriate child EventData object into the Generate User Event prim. Client code called EventData:GetName to return a unique string and had to case out the event data based on that. This is okay and probably would have worked for my immediate requirements. I'm not real happy with it though because casing out on a string is a runtime bughole I'd prefer to keep closed. As a general purpose technique it also doesn't allow clients to selectively register/unregister for events at runtime. The client has to decide at design time which events will be handled. At runtime the only choice is to either handle all of those events or none of them. That led me to exposing each user event refnum so the client can pick and choose. However, if the client code destroys the user event it will cause errors in the active object and cause any other clients registered for that same event to quit responding to it. So I figured I'd try creating a new user event every time a GetUserEventRefnum method is called. This gives each client a unique user event. The engine stores the new user event in an array with all the other refnums for that same user event. The engine class has an EventRefnumArray for each unique user event it supports. When it needs to raise an event it iterates through the array sending the same EventData object to each event. I figured raising an event is a pretty common activity so I tried putting that functionality in a sub vi to avoid all that duplicate code. This is where I ran into the trouble. The top center vi is my sub vi for raising all the events in the array. At the top right is a simple example of trying to send an array of user event refnums typed with a child class into the sub vi. I'm not sure if my example in the original post is effectively the same under the hood as what I really tried to do. I think they are, but...? Getting back to your suggestions, upcasting the child EventData object into the parent EventData object lets me wire it up. I suppose I could require clients to downcast back into the correct data object since each event always sends the same subclass. Not as clean as keeping the type info, but probably better than my proposed solution. (Too bad I implemented all those event refnum wrappers before reading your post.) I'm pretty sure I'll be able to maintain EventData object type information using EventRefnum wrappers and overriding EventRefnum:RaiseError in each specific event subclass. Better for the client... PITA for me. Converting the user events to variants doesn't solve the fundamental issue I was trying to avoid, which is identical copies of the raise event vi that differ only in the specific class the event refnum array is typed as. Exposing the registration number instead of the user event takes me back where I started. Your comment about it being like a cluster rather than an array may shed some light on why I've had such a hard time figuring out dynamic events. What started me on this little adventure was the idea of giving users to access to each event so they could choose when to register and unregister for each of them individually rather than treating them as a whole. In truth, I haven't figured out how to do that myself, though I had always assumed it was possible. For example, my engine exposes 12 events. Suppose a client initially registers for the six load and save events. But there are certain situation where the client wants to temporarily receive the GeneralEngineErrorEvent and other situations where the client wants to temporarily stop receiving the CalFileLoadErrorEvent and CalFileSaveErrorEvent. I've often wondered why I haven't been able to add or remove user events that are registered to an event structure. If the Register for Events prim behaves similarly to the Bundle (not Bundle by Name) prim, then that explains a lot. I still wish there were a built-in way to filter user events at runtime, but at least I have (I think) a better understanding of the current behavior.
-
I've been playing around with defining classes as the data type for user events so I can add additional capabilities/data to the user event without breaking client code. I've created an abstract UserEventData parent and all the user events my module exposes are typed as children of the parent class. I thought wiring a user event defined with a child class into a terminal of the parent class user event would be fine, but apparently User Events are really particular about what types they accept. The only solution I can think of is to wrap each user event in another class and give each of them unique static Get/Set methods. This is a lot of extra code for only a little benefit. Is there a better solution to this problem?
-
I use projects a little differently than Chris. I prefer to keep any file I consider "editable" as part of the project. That way I can organize them in virtual folders in a way that makes sense. The code in dependencies is typically from user.lib, vi.lib, and those kinds of places. In other words, it's reuse code that has built and distributed. If I see reuse code in dependencies that isn't in user.lib, it usually means I've accidentally linked to the source code and I need to fix it.
-
The most useful and practical stuff I've learned is geared around designing applications to make them easier to understand and maintain. One of the biggest lessons I've learned is that I must manage (i.e. limit) the dependencies between code modules. If I don't pay attention to the dependencies my application devolves into a big ball of mud. Managing dependencies correctly results in good encapsulation, which in turn gives you better applications. You mentioned a software background, so I'll assume you are familiar with OOP. There are a couple things I suggest to improve your skills: Get a couple OOP design pattern books. The two I have are Head First Design Patterns and Design Patterns by the GoF. The first is written for Java but I have no Java background and had no trouble understanding it. It is very approachable and an excellent book to introduce you to many common design patterns. The second is the first encyclopedia of design patterns. It offers more concise explanations of them and has more patterns than the first. Write code in your spare time. Lots of it. Figure out how you would implement a design pattern in Labview, then do it. Differences in programming languages mean not all patterns apply to all languages. If there are multiple ways to implement a solution to a problem, spend some time implementing all the different solutions and building mock applications around them to see what works well and what doesn't. I spent a about a month and a half of nights and weekends just experimenting with different ways of using user events. I certainly don't know everything about them, but I have a much better understanding of when they should be used and when they shouldn't. Build a basic 2-player checkers game in Labview. Then try to extend it. What if the players want to be able to select the color of their pieces? What if they want to play on a 10x10 board? What if they wanted to have optional rules like the requirement to jump an opponent? What if they want to play Fox and Hounds instead of checkers? What if they want to play chess? What if they wanted to play against a computer player? How easy would it be to extend your original code to meet these new requirements? What obstacles did you run into? How could you have designed your original application to make it easier to extend? Of course, this is the kind of knowledge that helps me write better applications, not pass the certification exams.
-
Personally I'm not a fan of using events to issue commands to other modules. Technically you can do it but I don't think it's good design. User events are best used as a way for a module to send information out, not take information in. Use regular VIs to have the module expose commands the controlling vi can issue to it. These VIs simply append the user's data to a pre-defined message and put the message/data package directly on your module's internal message queue.
-
I like it because it's easy to use and I can focus on the software design rather than fighting the diagram like I do with Visio. Code generation isn't my goal; I'm looking for speed and simplicity. StarUML, though quirky in some areas, fits those requirements pretty well. It definitely expects that you know what you want to do with UML. The sparse documentation tells you how to do things, but not when or why you would want to do them. I think that's on purpose. UML is a language. How you apply the language to your problem is up to you. To figure that out you need to look into the various software design processes that use UML and see how they use the different diagrams. (Here's a link to a good overview of the main diagrams as used by the Rational process, and another link to more in depth documentation.) UML provides very generalized pieces for you to build your software model in a way that makes sense to you. Not all of the abilities of each piece provided by StarUML need to be used. Some of them have properties that do not show up on diagrams. (I assume they're for code generation.) Since I'm only using StarUML for the diagrams I don't bother with any of those properties. I think the important thing to remember is to avoid the urge to model your software in exquisite detail. For example, I no longer fill in all inputs and outputs for each method in a class. That made the diagrams more confusing and created a lot of work trying to keep the classifiers updated. Now I enter that information only when it is needed to clarify a relationship or the purpose of a method. Most of my class methods (operations, in StarUML) simply define the name and scope. Taking a step back from that I also focus on just a few types of diagrams. I use class diagrams all the time to model the static relationships between my classes and sequence diagrams to model complex sequences between objects at runtime. I have used use case diagrams but haven't found them very useful as an analysis tool. Their main value is documenting what the use cases are so I don't forget any. Working up a user interface activity diagram last week with an Operator swimlane and a System swimlane played a key role in uncovering use cases the customer expected to work but had not articulated. Activity diagrams with swimlanes are also very helpful in figuring out what messages and data needs to be passed between parallel loops. I like using the collaboration diagram for a high level view of the information flow in my app. This is very important if using StarUML since it's development appears to have stopped several years ago. From what little I've read, UML tools all implement their own flavor of XMI, much like what occurred during the browser wars of a decade ago. Is there any chance of you exporting a StarUML file to XMI and seeing how well it complies to the standard? I installed it several weeks ago and fiddled with it for a few minutes. It seemed like overkill for what I needed and I really didn't have time to learn a new UML tool, so I dropped it.
-
Just curious, can you save any part of it as a sub vi or as a snippet?
-

OO solution accepted for Certified LV Developer exam!
Daklu replied to Aristos Queue's topic in Object-Oriented Programming
Congratulations Ben! I've started working on solutions to the CLD practice exams using pure LVOOP a couple times, but I always get distracted by some interesting OO design problem and 8 hours later I'm not even half finished. -
Shift registers (or any design that maintains data flow) execute more efficiently than globals. More importantly, when using globals all over your code it gets very complicated and difficult to debug. The data is too accessable. For example, your Read File vi depends on a 'Current Line' global. There's nothing preventing a different VI in your application from changing that value, which would cause incorrect results from this vi. You are correct that removing the sequence structure from your existing code would allow Labview to parallelize most of the execution however it wants. That's another side effect of using globals; it's harder to make operations sequential. Stacked sequence structures really become problems when trying to pass data from one frame to the next. Since you're not doing that I personally think it's fine. However, if you decide to ditch the globals you will be passing data between frames (Recorded Data Array) and it would be better to replace it with something else. Here's one way to go about making the Read File vi data dependent. (I'm guessing as to the use of some of the global variables, so use this as an example not as actual code that is functionally equivalent to yours.) Personally I would break it down even more. I'd eliminate the Recorded Data Array Updated and Recorded Data Array inputs as well as the Joystick Data outputs, and make the Read File.vi do nothing other than read the data from the file and return it as an array. Extract the correct Joystick Data from the array in another sub vi or in a higher level vi. Trying to do too much in a sub vi often leads to confusing code. (Like having to include a Recorded Data Array Updated boolean flag to decide whether or not to actually read the data from the file.) ---------------- Regarding your original question, I noticed you've wired a cluster control in each of the VIs to define the type information for the read/write data primitives. Do those derive from a common typedef or are they independent controls on each vi? If they are independent, make sure any numbers inside those clusters have the same representation and all the elements of the cluster are in the same order. (Better yet, define a typedef for your ARDS Data cluster and use that instead.) For instance, if one of the numbers in your Read File.vi ARDS Data cluster was an I32 instead of a DBL, that would throw things out of whack.
-
I second the suggestion to use a single development line with locking. Merging branches in Labview is a real pain. Suppose two people change different VIs that are independent of each other, but each change required several common sub VIs to be recompiled. When trying to merge the branches all those sub VIs are flagged as needing to be merged, even though they have not changed functionality. I've had hundreds of VIs flagged when a co-working recompiled the project--not fun. Also, Labview doesn't offer a way to merge .lvproj, .lvlib, or .lvclass files. Simultaneous edits of those files can be very difficult to resolve, especially the .lvclass files. Often you have to throw out one branch and recreate the changes after the other branch has been merged. IMO, the single best thing you can do to avoid conflicting changes is to design your application to be as modular as possible and assign owners to each module. (i.e. RF Receiver, Propulsion, Vision, Chainsaw Controller, etc.) Create the rule that nobody except the owner can change a module's VIs. Define the interfaces (input and output VIs) for each module that allows it to send and receive whatever information it needs. Libraries (.lvlib or .lvclass) are very helpful for this kind of modular programming as you can set the interface VIs to be public and everything else to be private. If you set your application up right you'll save yourself tons of time down the road when crunch time comes.
-
Adding a new child class to a parent in a built exe
Daklu replied to crelf's topic in Object-Oriented Programming
Chris, I'm a little confused about your original question. I thought you were asking about creating a new class in the dev environment that inherits from a parent that has been compiled into an arbitrary .exe, something you might want to do if you didn't have the original source code. Did I misunderstand? The responses appear to require source code access, either to inherit from the parent directly, or to implement an abstract plug-in layer that external code can inherit from. -
I don't think the .Net ToString() method is meant to be used to save objects to disk. ToString() can be overridden in classes to output whatever the class designer wants. On top of that it returns culture-sensitive strings, such as 1,00 instead of 1.00. For persisting data you would use serialization. I read through the help a bit and C# requires an object to have the [serializable] attribute in order to use the language's built-in data persistence methods. I guess that's a vote in favor of restricting the flatten prims when used with classes. It's been almost 20 years since I've done anything in c++, but I thought there was some way to pipe arbitrary data to disk? Most likely I'm just confused...
-
Thanks for the explanation. Decisions that on the surface appear odd almost always have valid reasons behind them. Favoring speed and size I think was the correct decision. If a class developer needs more advanced behavior they can implement it themselves. This is an issue I've run into while developing the memento interface. The whole point of the memento is to allow third parties (caretakers) to store an object's state without allowing the caretaker access to any of the state data. Flattening the memento to a string allows the third party to see and manipulate what's inside. I concluded that if that kind of security is required the object would need to encrypt it's state information before storing it in the memento. Not a great solution. On the other hand, being unable to save an object to disk because the class designer didn't include SaveToDisk or FlattenToString method could be a huge obstacle when creating applications. What happens when I try to save an object that is composed of several other objects, one of which disallows flattening? My first reaction was, "No, it's not too late. Please fix it." My second reaction is, "I'm not sure it's a mistake." How do other OO languages handle persisting objects to disk? Isn't manipulating the binary string or xml data essentially the same as, say, saving a c++ object to disk and manipulating the binary file?
-
Heh... you just wait... Yeah... too often for my liking. But that's not the real problem. Once the application framework is put in place it's nearly impossible to convince anyone who is not directly involved in coding that it needs to be restructured. I need to start with something flexible enough to adapt to different change requests because I'm sure not going to have time to add the flexibility later.
-
One that has a user menu item that says "Show block diagram." I believe it was put it to help debugging. No, and... no. Sorry.
-
And they haven't quit yet? Kudos to them... My biggest issue with both the QSM and the AE is that you are coding yourself into a dead end that is time consuming and difficult to get out of. I maintain that the AE is an anti-pattern because a better (IMO) solution exists. I'm not sure if there's an adequate alternative to the QSM so until one is found it escapes the scarlet A. (Secretly I know it's guilty and I'll continue to give it the evil eye whenever I see it.) I hope the new courses don't teach that. Or at least teach the limitations of the QSM. So what do you do when your QMH starts to get too big to manage? Stop and rebuild it with a different architecture? Is there another architecture you could have started with that is nearly as easy to implement and scales better or is easier to refactor when the need arises?
-
I can't do that. The vi is password protected and although I can view the block diagram I can't switch it into edit mode. I was thinking there might be SuperSecret ini switches that opened up different events or maybe some way to add "native" event to an event structure using scripting? This is in LV2009.
-
Nope, you're not missing anything. I was. (A good dose of "how to do this.") I ended up removing the flatten to string after I posted the message. Wha..? You mean you have one too!? Oh, I see yours is from I prefer mine... This is exactly the confirmation I was looking for. My original test setup must have been wrong; I think I forgot to destroy the run-time resources. If you flatten the class to a string you end up with the same data that is written to disk when you wire the object directly to the Write to Binary prim. However, when you write the flattened string to disk using the Write to Binary prim it prepends four bytes indicating the string length to the data. If you flatten the object to a string, save it as a binary file, and try to read from the binary file directly into the object it will fail. You have to read it as a string then unflatten it. (Or use the simpler route and skip the flatten to string altogether.)
-
Well I'm either drunk or stupid, and since I don't drink that pretty much eliminates one possibility. My original tests must have been invalid. For the life of me I haven't been able to recreate the situation where a class' run-time resources (queue, DVR, notifier, etc.) are automatically recreated when unflattened from a string. Reading the help leads me to believe it *shouldn't* do that, but I saw it work. Persisting objects to disk is something I have not had to do in my own applications so I don't have a good feel for what is and is not possible. My sandboxing has been inconclusive. I know AQ(?) and others have suggested using Flatten to String to store objects, but I don't think I've seen any mention of whether or not it is supposed to create queues, etc. automatically when the object is unflattened. Does anyone with more experience in this area know? If I'm lucky... sometimes I just get confused.
-
I've been digging through some code the last couple days and I ran across an event structure that included the events "Selection Change" and "Window Opened?" I don't think I've ever seen these events before and I haven't been able to figure out if the events are tied to specific fp controls. Any ideas?
-
It's apparent lots of people don't like using the QSM because of the same problem I ran into. Personally I'm leaning towards calling the QSM an oxymoron. It's not a state machine at all; it's a mislabelled Queued Message Handler. (I thought the QSM was one of the design templates included in Labview, but it's not. The QMH is though.) Some might consider this a minor semantics issue. I do not. If I'm working on a "state machine" I expect certain behaviors and I write my code around those expectations. A QMH has a different set of expected behaviors. Calling it a "state machine" is confusing and leads to disjointed code. [Thinking out loud...] I think any QSM can be refactored into a standard SM with many of the QSM states turned into sub vis. The refactored application should be easier to maintain. Many apps will require more than just the SM to replicate the original behavior, and I'm not sure how much additional framework will be required. For example, in my DequeueState sub vi I often have checks for specific errors that need unique handling. Maybe the SM should continue the process, maybe it should abort, maybe it should restart. Handling mulitple options within a standard SM could be difficult. Something else I've come to realize after thinking about GoGators' and harbenger's posts is that the QSM couples the message receiving code and the state transition code into a single loop. Given a queue reference, other processes can put arbitrary states on the queue. The same queue is used for internal states to queue up the next states. This makes it impossible to enforce specific calling sequences within the QSM loop. Looking at it this way I'm more inclined than ever to believe the way we are using the QSM in this application is bad, bad, bad. The internal state transitions need to be handled separately from the external transition requests. (Maybe this is what jzollier meant by using a "batching mechanism?") The only way the SM can work reliably is if you enforce where (on the state diagram) external actions can trigger new states and what states external actions are allowed to trigger. Failing to enforce either of these opens the door for particularly nasty bugs. A QSM with an event structure in an idle state addresses the first constraint as long as no parallel processes have a reference to the queue. New states are only added from the idle state. It does not prevent the second. To enforce the second you would have to create states only for the idle case and to respond to external actions. If my app responds to a 'Load' command and an 'Exit' command, there are only three states in my diagram: Load, Exit, and Idle. Any utility or intermediate states need to be made into sub vis instead. What you end up with is a star diagram like GoGaters mentioned. I dunno... the more I think about it the less I like the QSM. Personally I'm about ready to file it under anti-pattern, right next to action-engine. I might consider it for prototyping something or a quick and dirty tool, but I wouldn't want to base an application on it.
-
LAVA turns into more of a ghost town than work... I'm so wonewy.