Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
For those that missed it, AQ gave an interesting Advanced LVOOP online presentation today. In it he briefly touched on the subject of how persistant classes are able to mutate data from previous versions of the same class. Very few things will break the geneology; however, if the class is renamed the version info is reset and all geneology is lost. As I've been thinking about this I realized this has major repurcussions on my workflow with respect to reuse code. My standard practice is to use regular naming styles in my source code, such as MessageQueue.lvclass or FileIoAdapter.lvclass. During the build process, whether I'm using OpenG Builder or Source Distribution builds, I'll append a major version tag to my class name (MessageQueue__v1.lvclass) so I can have multiple major versions installed on my dev system at the same time. If I'm understanding this correctly, when the build process creates MessageQueue__v1 it discards the geneology information, meaning even though MessageQueue version 1.0.0.4 can successfully convert MessageQueue version 1.0.0.3 persistance data, MessageQueue__v1 version 1.0.0.4 cannot convert MessageQueue__v1 version 1.0.0.3 persistance data. In other words, none of the classes I distribute will be able to convert persistance data from previous versions of the same class. Furthermore, at first I assumed it would only affect those classes data which is designed to be saved to disk. On further reflection this has much more severe, and subtle, implications. Other developers could have any number of reasons for needing to persist the state of my reusable classes. As a reuse code developer I've unknowingly made certain asumptions about how it will be used--namely, that it won't need to be saved to disk. It looks like my development practice and lack of foresight has created a gaping compatibility problem with persisting any of my reuse code. Am I understanding these consequences correctly? If so, is there a way to transfer the geneology information from MessageQueue.lvclass to MessageQueue__v1.lvclass? I assume I cannot simply copy the xml from one lvclass file to the other.
-

Check box when label of that checkbox is clicked
Daklu replied to dblk22vball's topic in User Interface
Couldn't hurt. Maybe it is well known... just 'cause I'm vocal on LAVA doesn't mean I know what I'm talking about! (It's awfully presumptuous to assume I'm a "guy." I could be the cutie on the left in my avatar picture you know. ) -
Check box when label of that checkbox is clicked
Daklu replied to dblk22vball's topic in User Interface
I did not know that. Kudo for you! -
Palette frustrations
Daklu replied to Daklu's topic in Application Builder, Installers and code distribution
Thanks Ton. That helped point me in the right direction. I've posted additional questions over on the Add-On Dev Center. -
I've rarely taken the time to create palettes for reusable code modules. I find it to be a royal pain in the arse and often the only thing I have to show for it is a headache. Call me crazy, but I decided to give it a go again. (Sure enough... now I have a headache.) I'm trying to figure out how to create palettes for my modules without duplicating the whole distribution directory structure in my dev folder or going through the hassle of NI's suggested method for creating palettes. I have a basic text-based mnu file editor I created last year that I've used with some success, but the rules of palette behavior still mystify me. For example, does the .mnu file record absolute paths to the palette items or relative paths? The api help says you can use either with WritePalette; it doesn't say what format it is saved in. Sometimes it seems to be absolute, sometimes it seems to be relative. Some of the tests I've run imply the root project folder is used. Throw symbolic paths in the mix and the number of permutations needed to figure it out starts to get too big. Hitting the mnu file with a hex editor didn't reveal anything useful. Anyone know if there's documentation explaining the mnu file rules?
-
QFT. Being a programmer for someone else's science project is an exercise in frustration.
-
It appears you can simply leave it out without any loss of your rights. From Wikipedia, Reading this post constitutes a binding agreement not to hold the author liable for any lost income or damages resulting from taking legal advice from Wikipedia. Furthermore, the author expressly denies any knowledge of the contents of this post.
-
Any idea why the Controls property from Pane 2 returns an array of 84 subpanels when there's only 8 on the screen?? [Edit] Never mind... I found them. I take it subpanels can't be dynamically created at runtime?

-
Yep, if it autogenerates a palette for the entire project it would be just as cumbersome... but with the added benefit that I can pin specific palettes and have VIs from different parts of the project at my fingertips at the same time. That may or may not work well in practice; I'd have to try it out. What I would really like is a true dynamic palette--a buffed up Favorites palette that works via drag-and-drop and allows subpalettes. When I drag a vi from my project folder on the palette the vi becomes part of the palette. If I drop a class or library, all subpalettes are automatically created and populated. And if I were really cheeky I'd ask for the palette to be associated with a project and automatically load when the project is opened. Is something like this even possible via scripting? I have not done much scripting and I haven't dug around trying to figure out how the palettes work at all. I'm pretty sure there aren't any hooks available to automatically save and load the project palette with the project itself, so I guess it's a good thing I'm not that cheeky. I had that installed once but never used it. Maybe I'll load it up and try it again. I will say constantly moving my right hand between my mouse and keyboard gets annoying. It's one of the few things that really annoys me about Labview that doesn't have a solution. I think I remember some discussion about that. Did you ever make it public? I didn't see it in the CR, though there is another entry that appears to do something similar.
-
When working on a project I use the project explorer window to drag and drop vis onto the bd I'm working on. If the project is large it can take a lot of scrolling and clicking to get to the VI I need. Has anyone ever implemented a project-specific palette?
-
Tree or ListBox or Array of Strings
Daklu replied to LHarris's topic in Application Design & Architecture
No data, just opinion. Present your data to the user in a way that makes sense to the user. If the user understands the data to be tree structured, put it in a tree control. It will save you grief in the long run, especially if you expect the data set to grow. (Imagine Windows Explorer presenting the folder structure as an array and you can see the headaches it would cause.) Regarding performance concerns, how big is your data set expected to be and how frequently do you have to refresh the data? -
After Paul's comment I just had to take a look, and... I guess you did warn us. If you're planning on doing any more Labview development I recommend learning the state machine design pattern. It's a fairly simple pattern that will go a long ways towards making your code more readable and maintainable. Not a chance. Before I made any changes I'd have to understand it, and to be blunt, your code is far too messy to comprehend in a reasonable amount of time. I had to delete your vi from my computer--I was worried it would be a bad influence on my vis. If it were me, I'd probably implement a buffer and write to disk every couple minutes. If you keep the file open continuously then if LV crashes or your app gets into an undefined state you run the risk of losing all your data by not closing the file. You might need to implement a front buffer and a back buffer so you don't lose any data during the disk write operation.
-
Ahh... sacred cows make the best hamburgers. (Of course, that assumes you survive the lynch mob that forms after you slaughter the sacred cow.)
-
Good site for anyone who needs to call Win32 functions
Daklu replied to John Lokanis's topic in Calling External Code
Rats, I missed the user group meeting. For calling Win32 functions, isn't it generally easier to just use the Call By Ref node? Admittedly I haven't paid that much attention to the issue, but from the discussions I remember wrapping dll calls in another dll is only needed when using callbacks. What other benefits do you get? -
Cons? Well, since I haven't ever had to go back and do anything with the exes or installers from previous builds (other than point people to their location) I haven't run across any cons. What advantage do you get by including the build output as part of the project?
-
[Cross posted on the dark side] When I open a project in the LV dev envrionment that makes calls to a dll via the Call Library Function node, I can control when LV loads the dll by setting or clearing the "Specify path on diagram" option. Setting it loads the dll when the vi executes; clearing it loads the dll when the project is opened (or more specifically when the vi is opened.) Is there a similar way to postpone loading ActiveX or .Net dlls in the dev environment until the vi executes? I suspect not given the interactive nature of those dlls in LV... but what the heck, it never hurts to ask.
-
[Cross posted here.] As I've been exploring the Unit Test Framework, one thing I've been very excited about is the ability to test indicator values that are not part of the connector pane. In reusable instrument class methods where I take the user's inputs and create a string or byte sequence to send to an instrument, my plan was to drop an indicator right before sending the command to the instrument. This lets me test code without having an instrument connected and helps ensure future developers don't accidentally break existing client code. Unfortunately, after attempting to run my unit tests I discovered the UTF can't "Include controls and indicators from front panel" when the VI under test is dynamic dispatch. Two questions: Is this limitation likely to be removed, or is it based on something within Labview that is very hard to change? Are there reasonable work arounds that would provide me with some way to test the commands? (I don't want to put the commands on the connector pane as that exposes internal functionality to the user.) Thanks, Dave
-
I think it's too early and my brain isn't fully switched on--this question isn't compiling. All our software is for internal customers and used to support product development efforts. Our requirements are very different than those of a professional Labview contracting shop, especially when it comes to documentation. Our scc directory structure is typically something like this... <project>\trunk\source - application code <project>\trunk\documents - documents another developer might need, such as instrument manuals, design documents, etc. <project>\trunk\resources - stuff that is related to the project but is not Labview code. I'll put ogb and ogpb files here, as well as icons, config files, report templates, etc. We're looking to get a professional installer creation tool and those files will go here too. We don't store customer-facing documents or project management stuff in source control. We use a Sharepoint server for that. Each project gets its own page on our release server where we post the installer as well as any installation instructions, required 3rd party applications, and user manuals.
-
I don't, but I wouldn't call it "bad practice." I think there are valid reasons why one would check in built code in a distributable format, be it exes, installers, or packages. I do make sure to check in any files associated with building a project. Specifically, OGB and OGPB files are included in my project and checked in to source control. We also have our distributable code hosted on an internal web site with a 14 day backup, so we don't have to rebuild them if somebody needs to reinstall it.
-
FYI, when DVRs were first released there was an example posted by an NI employee and some discussion about the error handling. As I recall the example completely ignored one of the IPE error outputs because it would never generate one in that code. The details (and the a link to the thread) escape me at the moment. I did find this thread with DVR error information from AQ...
-
I just finished a week of reverse engineering the cold class. I didn't find a cure method, but I did run across HackingCough, ClogSinuses, and LoseVoice methods among others. It's a nasty bugger--by the time I discovered it its code was deeply integrated in the client app. The entire time it was loaded in memory the Daklu.FeelLikeCrap property was set to true. I would have given my left arm to revert to a previous scc check-in. Fortunately the cold class appears to have a built-in timeout that self-kills the thread it's running on.
-
Ooooo.... good question. Here's what I do when I'm designing reusable code: 1. Purchase crystal ball 2. Look into it to see how the code will be used in client apps 3. Code the reuse module according to expected use cases 4. Act surprised when somebody (possibly me) uses it in an unforeseen way 5. Use crystal ball for target practice Your question is, I think, a variation of the tradeoff between writing bigger, more complex code that can be used in many different situations and writing smaller, simple code with more limited applicability. (The difference being that this decision adds to debugging complexity rather than code complexity.) It doesn't matter where you draw the line between those competing goals; some users will complain your code is bloated, others will complain it doesn't provide enough functionality. My take-away is I can't write code that is going to fit all future use cases, so I don't bother trying. I write code that meets my immediate needs with some wiggle room for predictable and likely future needs. When I run across a use case that violates the assumptions I based my reuse module on, it's time to write new code. (Could be app-specific code to deal with the special case, a new version of the reuse module, or a completely new reuse module.) This is a round-about way of saying no, I don't automatically make them reentrant. 98% of the time I don't need it. Of the 2% of the time where I do need it, often it is predictable and I can designate that VI as reentrant. For me, the 1% increase in code applicability I'd gain by making everything reentrant doesn't justify the increased hassle in debugging the other 99% of the code. That said, I'll be the first to admit I probably don't think about reentrancy enough. There are a couple places that I need to go back and check that I've set it correctly.
-
Anyone using Mercurial for source code control in LabVIEW?
Daklu replied to Jim Kring's topic in Source Code Control
Keep us posted on what you find. -
Process control architecture
Daklu replied to EricLarsen's topic in Application Design & Architecture
Disclaimer: I've never done Compact Field Point programs, so this is from the perspective of a desktop applications programmer. Still, I think some of the principles would apply to CFP. The two layers you're describing are strictly UI layers; they are not necessarily (and aguably shouldn't be) related to the how the application code is structured. If you tie the app's code structure too tightly to the user interface it becomes much more difficult to make UI changes when the users want to be able to do something different. I can't offer any suggestions for a specific code architecture to use as it is highly dependent on your specific requirements. Instead I'll pose some questions that will hopefully help lead you to your answer. What's your timeframe? If there's enough "play time" in your schedule, you can explore new techniques and architectures. (Be careful though, learning a new architecture can will be a time sink!) On the other hand, if your schedule is fairly tight, stick with techniques you already know even if it produces less than ideal code. How much application design experience do you have in Labview or any other programming language, and what architectures have you used for previous apps? State machines are useful, but aren't the best solution for all applications. What's the expected lifetime of this application? If you know it's going to be used for 3 weeks and then thrown away you can get by with a less-robust solution than one that's expected to be used for 3 years. In general, apps with longer expected lifetimes need more up front design work making sure it is extendable and maintainable. (And that usually means more complicated code.) How much decision-making, either user-based or code-based, does your app require? Code complexity is directly related to the number of decisions that must be made during execution. More complex requirements need more complex solutions. Assuming your app is on the complex side, will be around for a long time, and you want to make it fairly maintainable, here are some suggestions roughly in the order I would apply them: 1. Break up your application into logical modules. Don't just group all the VI's in a module in the same project folder. Create an lvlib for each module and make use of the private scope to hide the implementation details from the other parts of the program. Model-View-Controller is a powerful high-level architecture that breaks an application into user interface, business logic, and processing modules. You can also break down each of those modules down into sub-modules. (Reporting, File I/O, Valve Control, etc.) Modularity is the most important attribute for making an application extendable. 2. Within each module, use sub-modules to layer your code. Here is an article on using layering to create a Hardware Abstraction Layer. The principle applies to non-hardware functionality too. 3. Consider creating classes for key parts of your application. Note that modularity and layering can be accomplished using "traditional" Labview programming techniques (i.e. Structured Programming.) Using classes correctly can make it much easier to implement changes in the future. (Be warned, using them incorrectly will make your code harder to maintain.) One last thought... be sure to talk to your users to find out what they need to do and how they want to view and interact with the application.- 1 reply
-
- 1
-

-
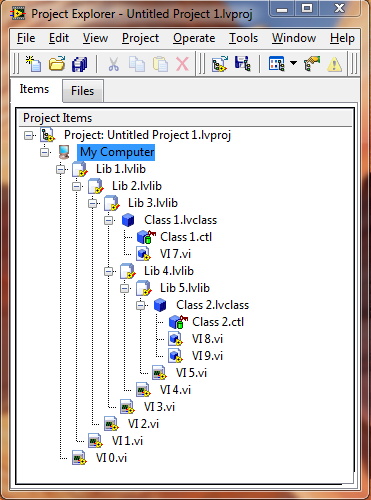
Yeah, except the part about me not remembering a discussion from three days ago. (Actually I thought you were referring to a discussion from many months ago...) I created this example project to explore the behavior and there are still things going on I'm not understanding. I get the impression that each individual decision makes sense but I find the overall behavior rather confusing. After closing the project, if I load any one library then it opens a project window with Lib 1 at the root and all the other libraries correctly listed as children. The VI hierarchy window shows that only the two lvclass files and the two class VIs are loaded. This (along with the comments from George and Stephen) leads me believe the entire library hierarchy is loaded regardless of the library type, but whether or not the VIs are loaded depends on the library type. After closing the project again, if I open VI 8 the entire class is loaded including--according to the VI hierarchy window--the lvclass file. Since an lvclass file is a library, does that load the entire library hierarchy and both classes? Apparently it depends on which app instance it's loaded into. If it's loaded into the Main App Instance then no, the loading appears to stop with that class. If it's loaded into a user app instance then yes, the whole library hierarchy is loaded... unless part of the library hierarchy is already loaded in the main app instance. Here I had loaded up VI 8 in the Main App Instance, then created an empty project file (declined to add the open vi's to the project) and opened one of the libraries. Class 2 is missing from the project, even though it is part of Lib 5. I thought that was odd so I closed that project and opened my original saved project. Both Class 1 and Class 2 were missing from the project! (Not shown.) I understand that VIs can't communicate across app instances, and by not loading another copy of Class 2 into the project context we can save some memory and time, but not showing the class as part of the library is confusing. I can't think of any reason why both classes were missing when I loaded the original project. I will say that even though the classes were missing from the project window Labview appears to handle it reasonably well behind the scenes. I made some modest attempts attempts at messing up the library links and after reopening the saved project everything was in place and the missing classes were back. More radical attempts to screw with Labview resulted in crashes. I also saw inconsistencies while renaming the lvlib files. Try this: Open the project and rename Lib 1. Save when prompted. (Notice only VIs are being saved; no lvlibs.) The project window shows a dirty dot, so Save All. Rename Lib 2. Save when prompted. Notice no dirty dot is on the title bar. Using a text editor, open the (now renamed) Lib 1 and Lib 3. Both should have references to your newly renamed Lib 2, but they still have the old name in place. If you close the project without saving (which should be fine, since there's no dirty dot) you'll have a heck of a time trying to fix the project. I don't know if this is a side effect of the loading behavior of the lvlib files, if it's an unrelated bug, or if I've been misinterpreting what the dirty dot actually means. I appreciate the efforts NI goes to to hide the details from us and have it "just work." Still, I wish we had more information about exactly what is loaded and more control over when it is loaded. Nested Libraries.zip