Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
If you happen to find one let me know. I need it quite often. At the risk of being struck down by lightning, I don't think I agree with this. If the reference is never used anywhere else, where should it be cached? As long as the vi is a preallocated clone (WaR is) there shouldn't be an issue. Putting WaR inside a shared reentrant vi is (I think) essentially making that instance a shared clone, which is violating the (undocumented) terms under which WaR is expecting to run. What happens if you make your shared clone dynamic dispatch vi a preallocated clone? I'm not saying these aren't bugs. Undoubtedly WaR is leaking implementation details which is never a good thing (though often unavoidable.) I don't know that there's a suitable fix NI can implement. Given that WaR is a preallocated clone, it seems to me the purpose of the shift register is to avoid excessive overhead in loops. I ran some timing tests of the current implementation against your proposed fix where WaR creates and destroys the internal notifier queue with every call. The current implementation averaged ~10us per iteration; without the SR it averaged ~32us per iteration. Not a big deal in most desktop apps. Could be a problem in RT apps. This does highlight an issue I think NI has not adequately addressed. Developers need a multi-layered api to create solutions to the problems we encounter. Labview's high level api is okay if your needs are very simple and specific. It's low level api is pretty good. It's mid-level api, the stuff that would really help promote better software engineering, is sorely lacking.

-
Yeah, all of them unsuccessful so far. I had thought locking was available via scripting. (My 2009 scripting plugin has been broken for a several months.) You're the scripting guru, isn't that property exposed? (Probably ought to be on the idea exchange, eh?)
-
Nice! I hate trying to get the colors to match up. Edit: There are a couple package dependencies you didn't set. OpenG's numeric library JKI's State Machine toolkit
-
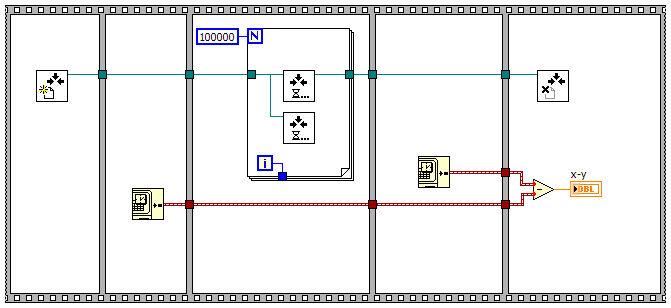
It's a Wait at Rendezvous bug, not a SEQ bug. Wait at Rendezvous, a vi shipped with Labview, does not always run normally in cases where no error occurred before the vi runs. Internally a rendezvous works using notifiers on a queue. Every time WaR executes, it obtains a new notifier and immediately waits on that notifier. When the number of notifiers meets or exceeds the rendezvous size, dummy data is enqueued on all the notifiers, releasing them to continue execution. If one of those internal notifiers happens to be closed, Release Waiting Procs throws an error which in turn prevents the notifiers from being put back on the queue, which then prevents all of the other rendezvous vis from being able to dequeue the notifiers. I haven't yet figured out how Jim was able to invalidate one of the internal notifiers...
-
 Good links Mads. I wasn't aware of the restrictions on the ProgramData folder. After reading through the blog and comments I understand the reasoning behind making it work the way it does. It appears the issue can be resolved by setting proper permissions on the application's folder in ProgramData; however, there is no easy way to do that from within the Labview installer. Kudo for your idea on the exchange.
Good links Mads. I wasn't aware of the restrictions on the ProgramData folder. After reading through the blog and comments I understand the reasoning behind making it work the way it does. It appears the issue can be resolved by setting proper permissions on the application's folder in ProgramData; however, there is no easy way to do that from within the Labview installer. Kudo for your idea on the exchange. -
Designing good error handling systems for applications can be tough. Typically in my apps each layer will handle the errors it can and if it can't it passes the error up to the layer above it. There's a downside to this strategy--it unrolls the call stack. Suppose I have a process executing in a lower layer that needs to execute for 5 minutes. Two minutes into the process an error occurs which that layer doesn't know how to handle, so the call stack unrolls until it finds a vi that does know how to handle the error. There's no good way to continue my process from the 2 minute mark without extensive bookkeeping to keep track of the state of the lower layer when the error occurred. Notifying users of errors is another scenario where I run into this problem. I may want to prompt the user to Continue or Abort on an unhandled low layer error, but I don't want to embed dialog boxes in those lower layers. (Makes reuse harder.) Once the error propogates up the call stack to a higher layer I've lost my state and Continuing is no longer an option. I've had the idea of using the Chain of Responsibility pattern as an error handling strategy bouncing around in my head for a while. Building an error handling Chain of Responsibility essentially creates a separate call stack specifically for errors. Instead of an errors propagating up the call stack until something handles it, errors invoke the error handling chain. This allows higher level layers to handle errors that occurred at lower levels without exiting the lower level vis. In principle I think this could be a powerful technique. In practice I have no idea how well it would work or how much complexity it would add. Has anyone ever tried anything like this? CoR is run time construct so each layer would have to know when to add/remove its error handling routines to/from the chain. I'm not sure if there's a clean way (in terms of both code clarity and run time efficiency) to manage that. Are there other, simpler ways to handle the problem I described above?
-
I've been looking into using a professional installer (InstallAware Studio) for creating installers. It is turning out to be much more complicated that I originally expected, but I believe it will make things like supporting different Windows versions, applying patches, upgrading to new versions, etc. a lot easier to manage.
-
How to make self referencing objects?
Daklu replied to Black Pearl's topic in Object-Oriented Programming
*Phew*... an uninvited critique of someone's code, no matter how well-intentioned, is a good way to make enemies. I almost didn't post at all. Also, I'm posting this in a "these are my thoughts and ideas, what do you think?" way, not a "I know how to do it and you don't" way. I hope it comes across correctly. Over the past year or two, there are three things that have dramatically improved my code: 1. Studying OO design patterns. 2. Focusing on creating modular and layered applications. 3. Designing (or attempting to design) my code modules to have good APIs. The last is, IMO, the hardest to do. Bad APIs in reuse code kills any motivation to reuse it. Bad APIs in applications make the application hard to read and maintain. A while back I read a book titled Practical API Design: Confessions of a Java Framework Architect. (Check it out from the library if you can--I didn't think it was applicable enough to LV to warrant the purchase price.) It had some interesting insight into the issues this architect had in creating the Netbeans framework. Here's a good summary of several API design guidelines. Before reading the book I used to try and include everything a class user might need, figuring the convenience would be helpful. In reality it just confused me when I went back later and tried to use the class. I have since learned a better approach: Step 1: Make the api as small as possible, but no smaller. This means I create all the fundamental methods a user would need to do to perform any foreseeable operation. For a general Tree object, addNode and removeNode are the essential operations. Assuming the node methods are public the user can use these two methods to do anything. Step 2: Make the common things easy while keeping the difficult things possible. This is where the convenience methods are added. The important thing to keep in mind is to your convenience methods should be useful to a majority of your users. Writing convenience methods for a specific subset of users just complicates the api for everyone else. The convenience methods should also be significant, wrapping up frequently needed operations, operations that would otherwise be cumbersome to implement, or operations that would require exposing the implementation. So what are the operations most Tree users will need to do? It's reasonable to expect users will need to retrieve nodes without actually removing them, so copyNode should be in there too. (Though they are getting a reference to the node itself, not a copy of the node, so I would change the name to getNode.) Iterating through the tree is a useful and expected capability. I haven't figured out the best way to iterate through generalized trees, but I suspect it involves an iterator class. Serializing (persisting) the tree could probably be argued either way. In general tree persistence probably isn't all that common, but the convenience of having the method there is worth something and it's unlikely to confuse many users. These methods make up your BaseTree class. Since you want to use a tree for configuration editors, subclass a ConfigurationEditorTree class and add the methods that are common for those particular kinds of trees. Load, Save, DuplicateBranch, etc. Whether or not you include dialog boxes in the Load and Save methods is largely personal preference. As long as ConfigurationEditorTree is application-level code as opposed to reuse-level code there's not really any harm in including them there. I'm not quite sure exactly how you expect your users to use the tree, so I can't offer any additional comments on that. The problem with this is that the nodes are not independent. Any given node may have parent and/or child nodes; therefore any given node could have the structure you want associated with branches. As I understand the api now, users will need to create nodes before adding them to the tree. Users could also create their own branch using the node linking methods. If the nodes are intended to be independent perhaps the methods used for linking nodes should be community scoped? The need for a separate method to add multiple branches could indicate a problem with your implementation. If each node must have an independent ID, are there other ways you could obtain one rather than iterating through through the tree every time? GUIDs are presumably unique. Could you simply have the OS generate one? What about using the DVR refnum? Using the node's tree path? Is a unique ID even necessary? It's not clear to me what it's purpose is. The ElementManager technique above needs the ID to find the correct object in the array when, for example, asking for a parent node. In your by-ref design asking for a node's parent node returns the parent node--so why the ID? -
I'm not a religious man, but I'll pray for you. May the gods of Labview have mercy on your soul. (I hope you at least created a backup before attempting this?)
-
Another option occurred to me last night. Some scc repositories allow you to set up symbolic links to files in other repository files. If your scc system allows it that would definitely be a less risky option.
-
Not at all. I enjoy learning about Labview's implementation details--especially when it explains why I can't do what I think I should be able to do. I agree there's no good way to resolve the problems of my or Yair's existing persisted data in our use cases. I was thinking about changes that would allow us to deal with those problems in the future. So from what I've seen it looks like unflatten first checks the class name. If those match then it checks the class version. If the class version in memory is greater than the class version on disk, then it goes on to unflatten the data. I think there are still error checks in the unflattening process. If the data on disk is 4 bytes and the class is only expecting 2 bytes LV throws an error. Speaking conceptually, wouldn't it be possible to have flatten/unflatten hooks that replace the class name with a class guid? (FWIW, I wasn't actually proposing having classes hook into the flatten/unflatten prims. I think in the long run having class methods magically hook into an existing LV prim would be very confusing. I'd much rather see NI develop a better OO framework designed specifically for classes.) No doubt... but it's also an insurmountable obstacle when the implementation doesn't fit our needs.
-
You're not stuck still using 8.2 or 8.5 are you? (I know the military is slow to adopt new technology.) If so, I'll just say keep your troubles manageable and leave the code where it is. I've had much better success moving code with 8.6 and 2009.
-
How to make self referencing objects?
Daklu replied to Black Pearl's topic in Object-Oriented Programming
<Apologies to Black Pearl for completely hijacking his thread... > A possible presentation? Was your proposal accepted? If I may be so bold as to offer some feedback... I think some of the functionality in your Tree api is a little disjointed, providing good high level methods for those people who need to do exactly what you provide while possibly leaving other developers with more difficulty in accomplishing what they need. For example: -duplicateBranch.vi creates a new branch and adds it as a sibling of the branch it is copied from. What if I want to copy a branch and add it to a different node? Or what if I want to copy a branch and make a new tree out of it? -readTreeFromFile and writeTreeToFile combine the process of flattening the tree to xml and writing the xml to disk. I (as your api user) want to flatten the tree to xml and store the xml string in memory to support undo actions. -SaveTree and LoadTree each pop up dialog boxes requesting user input. I'm planning on using this api in a remote system where users might not notice a dialog box for days. How can I make it just log an error if the path input isn't correct? -I see a Node class and a Tree class, but some of the Tree vis refer to "Branches" yet have Node inputs and outputs. How is a Branch different from a Node? (The answer, I now realize, is nodes and branches are the same thing. I actually asked myself this question when first looking through the code because I expected different functionality for different terminology.) -graftBranch adds a single branch to a single node. graftBranches adds multiple branches to a single node. Where are the methods to add a single branch to multiple nodes or multiple branch to multiple nodes? (That's a trick question... I really don't want those methods. I think graftBranches is unnecessary.) If your example is intended to be reusable code, I think you'll be better off providing a small set of fundamental capabilities and let the users combine those fundamentals into higher level functionality that makes sense to them. Really all the tree needs is three core functions: addNode, removeNode, and copyNode. Duplicate and relocate are easy enough to implement from those three methods. If you want to support persistence add flattenToXml and unflattenFromXml. Leave it to the class user to decide how the objects will be persisted. (Disk, memory, audio file of morse code...) On the other hand... if it's an example of one way to implement a bi-directional tree, you can ignore everything I just said. -------------- There are a couple things I haven't figured out yet. First, what's the purpose of storing subnode Class names? How is it intended to be used? Second, the Tree api operations need a NodeID. Is the api user supposed to assign IDs to nodes when the nodes are created? When I graft a branch I created, the NodeIDs are potentially reset. How am I expected to retrieve my nodes if they have been changed? -
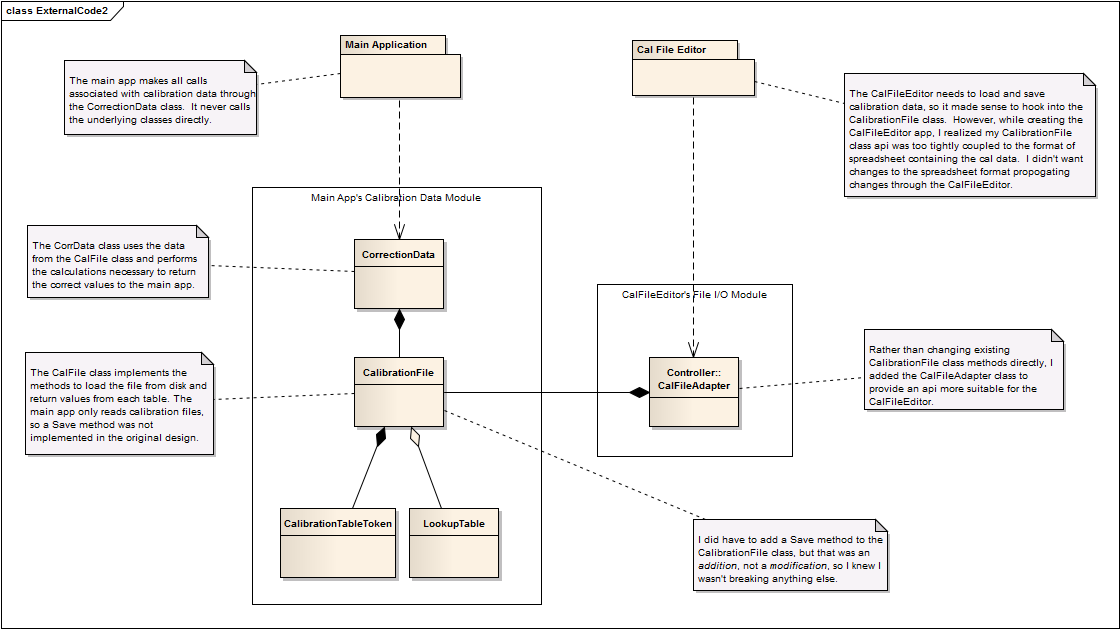
Short answer: Yes. Long answer: My reuse code covers relatively large units of functionality. I don't deploy anything smaller than a class and most of my reuse modules are multiple classes contained in an lvlib. I don't bother keeping a set of independent utility vis as part of my reuse library. If there's a handy utility vi I could use from a different project, I'll create a new vi in the current project and copy the code. I never have source vis from a separate, independent project show up anywhere in my current project's project window. Your problem is a little bit of a special case in that the two projects aren't completely independent. I have a similar situation right now where I have been writing a helper app to create calibration data that will be used in our main application. In this case I created a folder for my sub-project in the scc tree of our main app, started a new project there, and including the new project in the main project. My CalFileEditor links directly to the other code, but since it's all in the same scc node the chances of conflicting changes is lessened. I've also tried to insert abstraction layers to protect the CalFileEditor from changes to the main app source code. (See below for one example.) If the code I need somewhere else is expected to be generally reusable, I'll extract it, generalize it, and deploy it to my reuse library. More specific reusable code stays in the projects. If you're going to have applications with overlapping functionality and you want to reuse source code, the single most important thing is to make sure you manage the dependencies of your reusable code. Nothing's worse than dropping in a class you think is reusable, only to see it import another 2000 vis from an application written last year. Assuming you've done that correctly and you expect there to be more apps to follow, I would probably create a single parent directory containing directories for each of the individual applications that make up the system. I'd also add a Shared directory for code used by multiple apps. When you find something in one app you want to use in another app, extract it from that project directory and put it in your Shared directory. (Be careful not to break the links in your original app!) Then, once you've moved the code to the shared directory, remove it from your original app's project to indicate that app no longer "owns" that code. Better to recognize the potential trouble now than after the damage is done. Nope, I don't use passwords at all. I do lock the libraries, but no passwords. Nothing I distribute to users contains confidential IP they are not allowed to see. If a user wants to get in and muck around with the code... that's on them. I can't protect them from their own stupidity. If the time comes when I do need to use passwords, I would likely start with random passwords. If someone needs to see a block diagram I can always rebuild that module with a specific password for that user. Lucky dog cat!
-
How to make self referencing objects?
Daklu replied to Black Pearl's topic in Object-Oriented Programming
Is the bi-directional tree your design? Nice job. The core implementation is similar to what I had imagined for an in-memory tree, though I hadn't gotten around to actually writing any code yet. I think the design can be simplified a bit by replacing TreeObj with Labview Object. I'd also consider changing the design to allow tree operations be performed on nodes. Making node a subclass of tree is the most obvious way; I'm not sure it's the best though. DVRs of objects containing DVRs of objects containing DVRs of objects, etc... it get a bit dizzying trying to sort through it all! -
Rats... good point. Maybe I should move on up to sidewalk chalk. (And I so liked the sparkly glue...)
-
OGB vs. LVSD (Labview Source Distribution) is very similar to OGPB vs. VIPM. The former offer more flexibility but can be quirky. The latter are much easier to use and have better fit and finish. I did a user group presentation a year ago titled Using Freeware Tools to Manage Reuse Code. (You can get it here*.) Slide 11 summarizes the main differences between OGB v2 and LVSD 8.6. (See attached pdf.) *Some of the information in the Code Management Best (Pretty Good) Practices section is no longer valid and needs to be updated. I do the same thing with the minor exception that I put them in vi.lib rather than vi.lib\addons. Jim was kind enough to post an example of how they do it in response to a bug I posted here. Looking back on that thread I think I set up my relative paths incorrectly--classic example of a user ID-10t error. I've been having a fairly in-depth discussion with Bob Des Rosier of NI about the Palette API. Getting the mnu files set up correctly represents a pretty good chunk of that 200+ hours. I used to have the problem of unintentionally modifying the code in my reuse library... now I make all my reuse code read-only while building it. Problem solved. (You do keep your reuse source code separate from the reuse code you use in your applications don't you?) OGB v2 vs LVSD 8-6.pdf
-
So, given that someone editing a reuse class can unintentionally screw up LV's ability to unflatten previously saved class instances, what's the best way to create a unit test to make sure that doesn't happen? Is it to create an instance with non-default data, save it to disk, and make sure that all subsequent class versions can correctly recover the data? If so, I presume I'd need to create a new saved object for unit testing every time LV bumps the version number? I take back that suggestion. The more I think about it the more I believe the issues with the mutation history isn't the problem, it's a symptom of the problem. The problem as I see it is: 1. NI's recommended way of persisting an object is to flatten it, and 2. NI hasn't provided class developers with a way to hook into and override the flatten prim. I can't fault NI for removing the requirement to write mutation code from LVOOP. That could have easily become an obstacle preventing the adoption of classes by the community. However, in hiding the code mutation capabilities behind the curtain they have also removed the ability for developers to write their own mutation code. That decision leaves developers with more complex use cases unable resolve them. Huh... a poet and a cartoonist. I'm more of a sparkly glue and dry macaroni kind of coder myself...
-
Yeah, I'm a little slow... That does include time spent figuring out OpenG Builder too. VIPM encapsulates the build/packaging process while OpenG has separate tools for them. A good chunk of the time was spent fighting with NI's mnu files. VIPM's palette building tool is my favorite part of the software. (If only I could yank that out and use it in my own workflow.) Are you referring to a top level dynamic palette?
-
How to make self referencing objects?
Daklu replied to Black Pearl's topic in Object-Oriented Programming
You're getting an error because you're trying to cast a parent object (ElementParent) into a child object (Element). You can't do that... if the child class has some extra data or methods associated with it the parent object doesn't have any way of handling them. I made the same mistake not too long ago and AQ was kind enough to explain why it doesn't work. For your design I don't think the ElementParent class is necessary. It just makes your design harder. Labview's by-val nature makes two-way knowledge of the parent-child relationship a little harder to implement. There are a couple ways I can think of doing it; using an ElementManager class and setting up your hierarchy in memory directly as you are trying to do. (I think the recursion should work once you quit trying recurse into a different object's method. ) Conceptually I think the ElementManager is a little easier to understand since it creates a clear distinction between element behavior and element relationship behavior. For the ElementManager technique, create an Element class with the following properties and methods: Class Element Properties -string GUID // all objects must have a guid -string ElementOwner // is empty if root node -string[] OwnedElements // is empty if leaf node Methods -string GetQualifiedName -(Also add getters & setters for the class data as needed) The idea is that when an object is created at run time it generates a GUID you can use to identify it. Instead of each element storing its parents and children directly, it stores the GUID of its parent and children. Each element is completely independent and has no real knowledge of the other elements other than their GUID. To manage the relationships between the different elements, create a helper ElementManager class with the following properties and methods: Class ElementManager Properties -element[] AllElements // array to hold all element objects Methods -element GetElementByGuid(string GUID) // returns an element object Given a guid, the ElementManager will search through it's array to find the element with that guid and return that to the caller. Of course if you're going to have very large data sets you can change from an array to binary tree or any other mechanism for storing data. The array implementation is entirely private and can be changed without affecting the callers. I like to have higher level methods in my manager classes and keep GetElementByGuid private. This makes it easier to use and completely encapsulates the guid from class users. A few to consider are: -element GetParentElement(element ChildElement) // returns parent element -element[] GetChildElements(element ParentElement) // returns array of child elements -bool IsParentChildRelationship(element Parent, element Child) // returns true if Parent is a parent of Child -void AddChildElement(element Parent, element Child) // Adds Child as a child of Parent element -element[] GetElementAncestry(element Element) // Returns an array of elements from the root to the parent of this element -
The only Greek I know is "Gyro."
-
You don't manage user.lib -- you manage your reuse library. NI has moved away from advising people to put their reuse code in user.lib and instead recommends vi.lib. (See here.) I agree with Chris, your reuse library is best managed by VIPM. Note that you only need to purchase licenses for developers who are creating packages. You can use the freeware edition to manage the packages on each computer. (Though the Pro edition does have the added benefit of being able to create package configurations, something that is useful for all developers.) If management is still unwilling to spend money on VIPM Pro, you can use OpenG Package Builder to build packages instead of VIPM. I guarantee* it will cost you more figuring out how to do everything using OGPB than it would cost to purchase a $1k VIPM Pro package. OGPB is more flexible than VIPM however, so if VIPM doesn't create the packages you need AND you have time to burn, OGPB will likely provide you with a solution. *To put some rough numbers to it, over the past 1.5 years I've spent well over 200 hours figuring out how to build my packages using OGPB. (Granted, some of the things I've been trying to do fall outside the norm.) If your management values your time at less than $5/hr, OGPB makes perfect economic sense.
-
Chalk it up to users adjusting to a new paradigm. Do you still receive those complaints? And looking back, don't you think *not* renaming folders or moving vis on disk was the right decision? Well it's generally not a good idea to change the default behavior of operations, so although I'd much rather have the Save As and Rename operations preserve the geneology it's probably better to leave them alone. Perhaps new options for "Save As and Preserve" and "Rename and Preserve?" Or adding a "Preserve Geneology" checkbox to the Save As dialog box? The only time I have to recreate a missing class I've purposely deleted is when LV won't let me remove the missing class from a library that for one reason or another didn't get the message the class is being deleted. This seems like an overrestrictive UI issue, not a real use case. It sounds like the class file name is the first level type check... if the file name embedded with the data doesn't match the unflattening class file name all other operations are skipped and an error is raised. What happens if I save an object of A.lvclass to disk, replace A's geneology with B.lvclass' geneology, and try to unflatten the data from disk? My original thought was to insert additional error checking during the unflatten process, then I realized you're probably not saving any type information other than the class name itself and another layer of error checking isn't possible. So given that flatten to string is a very low level function... maybe we need a higher level api for certain class behaviors. Since LV doesn't have Interfaces, perhaps Labview Object could have some default methods (such as Flatten/Unflatten Strings) added to it. Developers using the class level api gain the benefit of more flexibility, such as being able to unflatten class data of a different name (as long as the GUIDs match) and overriding the Flatten/Unflatten methods to make it possible to recreate dynamic resources (queues, etc.) at runtime. Obviously I'm not a code poet -- this crashes my parser. I'm pretty sure the concepts of refactoring and well-documented code weren't around while Prometheus was watching his liver get eaten.
-
Yeah, I was pretty sure renaming the class cleared the geneology; I just hadn't realized the impact renaming the class during the build process has on the ability to reuse my code in applications. There are a couple reasons I didn't make the connection: 1. I've always assumed the LV builds automatically compensate for changes made during the build. Preserving geneology seems like a pretty basic expectation if I'm creating a source distribution. (Recent attempts at renaming mnu files in my reuse modules during the build clued me in that the builder isn't quite what I expected.) 2. I don't typically persist classes data to disk, so I don't think about it that much. Designing reuse code requires thinking about what other developers will do with my code, and I hadn't properly considered they might want to persist my classes to disk. Lesson learned. I agree. Descriptive naming really helps readability. I frequently rename classes, libraries, and vis as their functionality changes over time. I do wish LV better supported refactoring.
-
My use case is actually a little different. In source I create A.lvclass ver 1.0.0.3 and during the source distribution build rename it to B.lvclass ver 1.0.0.3. The class is deployed and lots of data is saved as B.lvclass. Back in source I modify A and save it as A.lvclass ver 1.0.0.4. During the build I rename it to B.lvclass ver 1.0.0.4 and deploy it as such. A.lvclass ver 1.0.0.4 contains the correct geneology data, but doesn't work because it has the wrong name. B.lvclass ver 1.0.0.4 has the right name, but is missing the geneology information. That's exactly what I am needing. From a practical standpoint I'm not at all comfortable including that as part of my deployment process. It's far too fragile. You mentioned a mutation history api in your presentation but I didn't catch it's location. Would that provide a more robust way to transfer geneology? This could be the issue that forces me to abandon major version suffixes. (We may come kicking and screaming into the 21st century, but we'll get there eventually.) Why have I continued to use suffixes? Convenience primarily. While developing reuse code I often need to have the source code, built code, and deployed code open all at the same time. I have not gotten into the habit of opening a new project before double clicking on the code in windows explorer. That means when I do open other code it uses either the default app instance or the top most user app instance. I frequently end up with unintentional linking. Maybe I just need to adopt better habits. If I had the choice I'd set up LV to automatically open a new app instance when interacting through windows explorer. (wink, wink, nudge, nudge) Ultimately what you're talking about is namespaces. I know I've harped on LV's relatively primitive namespacing functionality in the past--I'll spare you the agony this time around. I'll just say I would absolutely love to see more robust and flexible namespacing in Labview, (moreso than Interfaces, for those that remember that soapbox) but I'm not holding my breath.