silmaril
-
Posts
114 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by silmaril
-
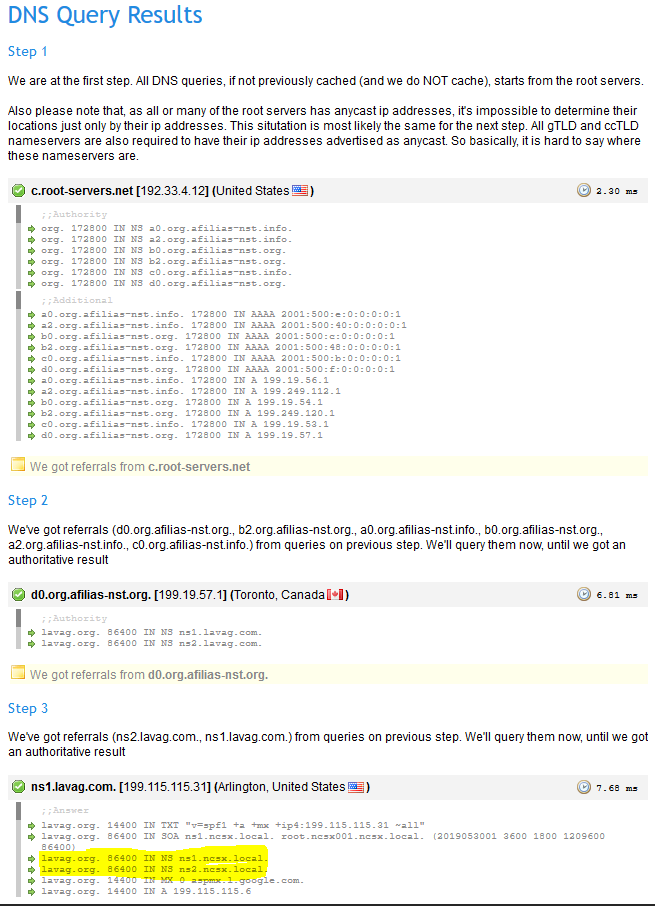
For several months I have been experiencing problems which end in the fact that my PC is not able to resolve the domain lavag.org. If it works or not depends on which DNS servers I configure in my system. I opened a support ticket with our IT department and they responded that the source of the problem lies in invalid DNS records that contain "ns1.ncsx.local" and "ns2.ncsx.local", which cannot be resolved (see attached screenshot). Could you please check your DNS records and fix this so I am able to use this forum with our company's standard DNS settings? Thanks! Rico

-
This looks great! Not just the comment feature - I think this is even more important: Numbers may be IEEE 754 positive infinity, negative infinity, and NaN. This is something I am really missing in JSON when working with LabVIEW floating point numbers.
-
I wasn't aware of this RFC - thanks for the link! One interesting aspect: It uses null-values to delete items, which means we should write our software to behave in the same way for a null-item and for a nonexisting item. In some cases this might leave us with the problem of how to correctly save a NaN value.
-
JSONtext is really a great help in our work - thank you very much, James! I was missing a function to merge JSON objects together recursively (since "Merge into Object.vi" is only considering one level of the data structure), so I wrote a VI that does this (see attached VI). I am sure this isn't the most efficient way to do this, so I am open for suggestions to improve the code. Would you consider adding this functionality to JSONtext? For anyone wondering why one would need this kind of merge function: Our use case is a modular configuration file structure, in which a complex configuration resides in one large JSON object. Each JSON file may contain references to include other JSON files into the current configuration. This enables us to structure the test configuration for about a hundred similar but different items in a reasonable way. Even if wrote "large", the JSON files are still small enough that the performance of the merge function is no issue for us. JSON_Merge_Recursively.vi
-
The primary use case would be read-only, which could be covered perfectly by a strip comments function. The drawback of this is that it makes any programmatic changes to the config files impossible... ok, not really impossible, but changing one item destroys all the comments in the file If there is some elegant way to simply ignore comments and keep them in place when changing values without slowing down the core functionality - that would be great! But I do understand that this is very difficult at least. And I have to admit that I currently don't have any use cases where config file changes have to be written programmatically, so your suggestion sounds like the appropriate solution to this. That depends on the way you look at your file. If it's "JSON with comments", the JavaScript style is appropriate. If it's "the JSON part of YAML with comments", the YAML style is the way to go. I am in favour of supporting all three of them in the additional "fix it up function". As James pointed out, performance is no concern in this use case. To get into the technical details: This would mean we have two kinds of comments: Line comments: start with a marker symbol sequence; end with the next EOL or EOF. Block comments: start with one marker symbol sequence, end with another marker symbol sequence. I think we should add a convention for line comments: They should only be allowed outside of strings, otherwise we could destroy perfectly valid string values or object names. I would also define that the marker must be preceded by some kind of whitespace (space, tab, CR, LF) or be at the beginning of the file.
-
Hi, I woul like to discuss an idea to extend the funcionality of JSONtext. We would like to use JSON as configuration files to replace INI files without the complexity of XML. This works great from the technical point of view. There is only the drawback that JSON does not support comments in the text, which makes it harder for humans to edit the files. The YAML file format supports comments and it claims to be a superset of JSON: http://www.yaml.org/spec/1.2/spec.html#id2759572 I am not asking to build a complete YAML library (even if this would be a great thing, too), but I was asking myself if it made sense to add support for YAML comments into JSONtext. This might have to be optional, since it would not comply with the original JSON specification. If active, all code searching for the different markers inside the JSON string would have to check for "#" characters that follow whitespace and ignore everything up to the following line end (with the exception of "#" inside strings). I am not sure about the implication this would have for code writing to the JSON string (the "Merge ..." VIs). And of course this would lead to the demand for a function that strips the JSON-string of all comments to convert it to valid JSON that can be used with other APIs. What do you think?
-
The real cool feature of Single Element Queues is that you can use them as a kind of global variable! It comes with an integrated semaphore mechanism which helps prevent race conditions (in fact it's the other way round: take a look at LV's semaphore VIs and you will see that they are using Qs internally). And it can help you to minimize data copies! Imagine you have an array of one million double value inside an SEQ and you want to read one element from it. Using the standard dequeue-enqueue mechanism will only make a copy of the extracted element, not of the complete array, since the array buffer can be reused. Reusing the buffer is only possible in Qs, not in notifiers, since in a notifier the data has to stay inside it in case another process wants to read it afterwards. Of course the same is true for "Preview Queue Element", so you should not use this if you only want to read a part of the data inside the SEQ.
-
Many customers want some kind of password protection for their configuration. But at the same time, most of them don't want anything too complex (aka expensive) or bothersome to work with. So we often end up with an application that can be used without logging in and a password to get administrative privileges (or sometimes two levels of passwords). The problem with this: If it's only a password with no connection to individual user names, you can be sure that everyone will know it rather sooner than later. In many cases you will find a post-it with the password on the screen after three days. If each user has his own password, you need to have a user management interface and someone has to create all the users. This might perhaps be done at the initial setup, but after three months, everyone will usually log in as "admin" with the password "1234". The only thing I can image that really works, even in "undisciplined" environments (aka 90% of the industries): Have the user identify himself with his legic chip. The same one that he uses to pay for his coffee from the vending machine and his lunch from the factory canteen. People usually tend not to give those away to others carelessly. It might even be possible to encode the priviliges in the administrative interface in the office that hands out these chips. This way there would be no need to have any user administration on the machine. I've never actually tried this, but I'd really love to.
-
The Lone Ranger LabVIEW programmer is certainly one of the big problems. How are you supposed to get better without the possibility to have frequent discussions about your work with other competent people? One way to help solve this: Consider getting external input. There are companies out there with a lot of expertise in LV programming from which you can buy some consulting / coaching time (eg. NI Allicance Partners). What's important from my point of view is that you don't simply buy an engineer who writes the code of your project, they should commit themselves to transfer knowledge, so you really learn some new concepts. It might be a good idea to go through the design phase of a new project together. If this is done properly, you should be able to do the implementation on your own afterwards (or maybe decide to share the work if the deadline is close). One difficult point with this can be convincing your boss that this is a worthwhile investment in the skills of his employee and that this does not mean you are not good at your job. In contrary: You have reached the limit of what you can learn on your own and the official LV classes can only get you so much further on your way to becoming better and better at your job. Disclaimer: I should admit, that this posting is not totally unbiassed, since my company might profit from people who decide to book some coaching time after reading this.
-
We are using Perforce with LabVIEW (and other languages) for almost seven years now. It turned out to be a very reliable SCC solution. There is one more thing you should consider at an early stage: Which file types are treated as binary files and which as text files? And which files should be locked automatically when they are checked out? I recommend taking the time to read about the Perforce Typemap and then setting up your own typemap that will apply to any new files on the server. Here are the lines dealing with typical LabVIEW file types from our server (please ignore syntax highlighting): binary+l //....vi binary+l //....vit binary+l //....ctl binary+l //....ctt text+l //....lvproj text+l //....lvlib text+l //....lvclass text+l //....xctl text+l //....xnode Yes we are quite conservative when it comes to parallel editing of XML files, because merging them usually is a pain in the butt. So we lock them automatically on checkout.
-
If you are worried about performance and memory usage, why add an unneeded sort? I don't know which sorting algorithm "Sort 1D Array" uses, but I think I've heard it's Quicksort. This algorithm needs an especially large number of iterations, if the input array is already sorted. We wouldn't want to waste CPU time and memory on sorting a few thousand strings that are already in the correct order, just because of incomplete documentation. AQ: Thank you very much for your reply! You are really succeeding in optimizing the quotient helpfullness / number of characters in answer.
-
Does this only happen in the "Program Files (x86)" directory? Was this file created newly? This is a long shot, but maybe it has something to do with access privileges and the way Windows virtualizes writes to directories that you should not write to? Maybe for some reason, DIR shows the virtual directory content, but LV sees what's really there, because it used the wrong file API functions? Can you see this file in Windows Explorer? Can you see it when you log in as another user?
-
I think it's great to have those functions that "convert" between a class path and a class object. That's all we need for plugin architectures. What I don't understand is why there are no functions to help us use classes and their names in the same way they are addressed inside LV. If I want to open a VI reference, I can chose between two ways: use the VIs path on disc (plugin) or use the VI name to get a reference to a VI that's already in memory. Once I have the VIRef, there are properties to get both name and path. Why is there no way to do similar things with classes? I'd really like to have a function to get the FQN from an object. In addition, it would help a lot to have it the other way round: Create an object with it's default value from it's FQN. I really don't understand why I have to meddle with a path on disc, when dealing with a class that's already been loaded into memory.
-
It's good to see that the essence of your solution is the same as mine, even if you chose quite a different way for the actual decoding algorithm. So there are at least two people who would like to have this functionality in LV. I'm wondering if this is enough for NI to include this feature in a future LV version?
-
We couldn't find a VI or primative in LV that gives us the Full Qualified Name (FQN) for a given LVOOP object, so we came up with our own function to do this (see attachment, LV2010 SP1). What I mean by Full Qualified Name: This is the name of the class including it's complete namespace hierarchy, for example if the class "MyClass.lvclass" is inside "MyLib.lvlib", which itself is part of "BigLibrary.lvlib", the FQDN for the class would be "BigLibrary.lvlib:MyLib.lvlib:MyClass.lvclass". Problems I see with the current solution: It was created by reverse engineering. There might still be some special cases in which it doesn't work correctly or it might stop working in future LV versions. The implementation creates a temporary copy of the object. This might slow down the application, especially when using objects that contain large data sets. This should not be necessary just to get the object's name. Any ideas for improvements? I am sure this functionality is already implemented inside LV, since we can see the FQN string in several places already (Variant display, object probes, ...). Is there really no way to call this internal functionality from a LV application? Our use case for this is a complex object oriented messaging architecture, in which we want a debug module to be able to show the difference between "Module1.lvlib:Init.lvclass" and "Module2.lvlib:Init.lvclass". Get_LVObject_FullQualifiedName.vi
-
Maybe a simple Variant Attribute Map is the wrong structure for this type of application? I assume you will be packing this inside some kind of library anyway, so you can use simple accessor VIs with an internal stucture that is a bit more complicated. What about this idea: All items go into a 1D-array (either of Variant or of a certain data type that fits your application). There is also a Variant with attributes. The attribute names are used as the identifiers, the attribute values are simple i32 array indices that point to the correct locations in the 1D-array. This would work fine as long as you don't have to delete any elements from the list. If deleting is necessary, you would have to think about some creative way to handle this. I could think about: Only the Variant attribute is removed. The array item is replaced by an empty Variant (or similar). Easy to implement but it's a memory leak that could bring you into trouble if the application runs a very long time. Once an element is deleted, all indices are corrected. This really means a lot of work and CPU load. I wouldn't want to do this. Elements are removed as described in the first idea, but you also keep a list of the "empty" indices. If a new element is added, those indices are reused before new ones are created. I think this is the most elegant way to solve this. With this kind of structure you could easily access your items using their names or indices, whatever fits better.
-
It seems to me that detecting the "Bitness" of the OS has to be OS dependant. So you would have to write individual code for each OS (eg. using a CDS). As long as NI does not provide such a property, your VI looks like a very usefull way to get this information (assuming we are on Windows, which is true in 100% of *my* use cases ). BTW: You are talking about "Application.TargetOS". I think "OS.DetailedName" is much closer to what you are looking for (but still not close enough, since it does not talk about Bitness).
-

Unexpected Event Structure Non-Timeout Behavior
silmaril replied to Justin Goeres's topic in LabVIEW Bugs
This really is a very interesting topic! After reading through the discussion, I think the current behaviour is absolutely correct. But I'm glad I understand it now :-) I absolutely agree with Justin Goeres: There should be tools to monitor and influence event queues! They could be similar to "Get Queue Status" and "Flush Queue". More important, I think we really need a Timer Event similar to the Timer in LabWindows/CVI. I know how to programm something like this in LabVIEW, but I really think this should be a standard functionality that works out of the box. People should be encouraged to use this instead of the Timeout case, because from my experience I can say that in most cases a novice LabVIEW programmer uses the Timeout case, what he really wants is a timer that fires every T ms. One very simple implementation (from the user's point of view) that comes to my mind would look like this: You can chose either a Timeout or a Timer event case (but not both in the same event structure). The Timeout behaves just like the current Timeout. The Timer event is triggered every T ms, no matter what happens. I could also think about much more complex APIs with Timer Object References etc. This could bring us a load of flexibility, but it might be to complex to be used by novices. In an ideal world we would have both: The simple Timer value that is connected directly to the event structure and Timer Objects that can be registered using "Register For Events" and manipulated using Property Nodes (change timer value, activate, deactivate). -
Consequences of unreliable run method
silmaril replied to Mads's topic in Application Design & Architecture
Thanks for bringing this to my attention! I played around a bit and generated a nutshell project in LV 2010 to demonstrate this problem. You can see cleary that the Run VI method does not start while any menu is open (this may be a context menu or a VI window's menu). The Get/Set Control Value methods are executed correctly even while a menu is open. I think if this is reported to NI, the first answer will be "Expected behaviour", which is of course correct. But it doesn't change the fact that this is a very bad trap to run into. It can really render a very powerful design pattern unusable. So, what can be done about this? I think there are two options how NI could improve this in future versions of LV: The Run VI method could be improved so that it may be executed even while the UI thread is busy (or there might be a new method to do this). The code that handles the menu could be improved so that it does not block the UI thread all the time (it's not doing much anyway, so why does it have to block this thread?). But even if we manage to convince NI of this, we will still have to wait a while unitl a LV version becomes available that fixes this. So let's think about what we can use as a workaround until then. My idea : Put the asynchronous VI together with it's startup code (especially the Run VI invoke node) into a DLL and call this DLL in your application. I haven't tested this yet, but I think this should work, because the DLL is running in another application instance. Test_UILock.zip -
I'm the one who voted "intendet behaviour" (it's only one right now). Let me explain, why I don't think this is a bug: We are talking about a simple string control. There is no method to append data to the end of the string. If there was such a method, I would agree, that the formatting of the existing text should not be changed when something is appended. But this is not what we are doing here. In this example we are reading the value from the control (which is the complete string without any formatting, because strings don't carry this kind of information). After this, another string is appended (still without any format info). This new string is written back to the control (did I mention it doesn't carry any format info?). From the control's point of view, this new string has nothing to do with it's current value. So in most cases the old formatting instructions (based on character indices) will be outright wrong. I think setting all characters to a common format is the only sensible thing to do here. What you are talking about here is a special case. I can see clearly, why you would like to have a simple way to keep your format definitions, but I don't think this should work automatically when setting the complete control value. The next thing would be to check if the beginning of the new string is identical to the old string... In most cases this would just use lots of CPU without a benefit. Instead I would suggest introducing an additional string control method "Insert String". This would have a string input as well as an index input. The new string would be inserted into the current string at the specified position. All "old" characters would keep their format (both before and after the inserted string). The new part would take it's format from the character after which is was inserted. The index input should be optional with a default value of -1, meaning the string is appended to the end.
-
Register Event Callback - VI type
silmaril replied to silmaril's topic in Development Environment (IDE)
Thank you very much for helping the blind! -
Another victim: http://lavag.org/top...llback-vi-type/ The HTML source code is very clear in this aspect: the image is sized to 500x1000 pixels: <a class='resized_img' rel='lightbox[74494]' id='ipb-attach-url-2273-1274272465-42' href="http://lavag.org/ind...;attach_id=2273" title="Register_Events_Problem.png - Size: 14.95K, Downloads: 5"><img src="http://lavag.org/upl...31269_thumb.png" id='ipb-attach-img-2273-1274272465-42' style='width:500;height:1000' class='attach' width="500" height="1000" alt="Attached Image" /></a> Ergo: This behaviour is definitively caused by the forum software, not by the browser.
-
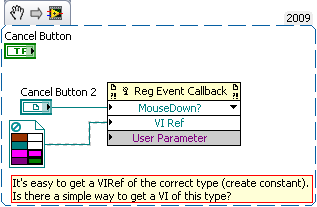
Event Callback VIs are a great way to handle events. Registering them is quite simple, if you have a callback VI of the correct type. This type depends on the event you want to capture. There is a very easy way to get a VI refnum of the correct type: just click "create constant" on the VI Ref input. But this doesn't give you the VI, it only gives you the correct type of reference. Is there any simple way to get a VI of the correct type, if you have this reference? I know one way, but it's quite awkward: Connect this constant to a Call By Reference Node. Now you've got all the inputs and outputs to create controls and inidicators of the correct type. Once you've got those, connect them to the appropriate connectors (don't forget to select the correct pattern) and make shure they are recommended. Now you can delete everything but the controls and indicators and start coding. There must be an easier way to achieve this! What am I missing? Edit: Sorry for the huge pictures. I have no idea what happened to scale them in that strange way...
-
A customer would like us to write an application with LabVIEW that writes data to a MySQL data base. No problem at all, as long as we are talking about Windows - you just have to chose which one of all the DB toolkits you want to use. But this project is supposed to run on a Mac. Does anyone know a LabVIEW DB toolkit for MacOS? In case it matters: The MySQL DB itself will also run on a Mac, but on a different computer. Thanks in advance for all suggestions!
-
FP:Open only tells you if the front panel is open anywhere. This may be enough, if you only want to distinguish the two states "closed" and "open in subpanel". But what if you'd like to distinguish (1) "closed", (2) "open as separate window" and (3) "open in subpanel"? I just found a very interesting private VI property: Front Panel Window:OS window. This property returns 0 if there is no OS window for this VI (which is the cases for (1) and (3)). If the VI has it's own window, this property returns a number >0 (case (2)). In combination with FP:Open, this enables you to tell exactly what the state of the panel really is.