
Phillip Brooks
-
Posts
911 -
Joined
-
Last visited
-
Days Won
53
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Phillip Brooks
-
-
If not, do you know how to best implement the agile process in LabVIEW?
VI Tester? - http://forums.jki.net/topic/985-vi-tester-home-page/
-
Is there a test in VI Analyzer to look for references passing through 'for' loops without a shift register?
When I said "it's an annoying bug", I meant "It's a behavior that creates an annoying bug in user code that is often hard for them to track down."
Just use marketing speak and call it "a feature"

-
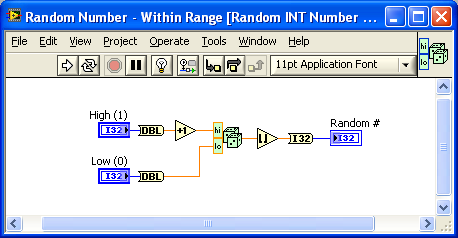
I've renamed the existing function to include DBL, created a polymorphic VI using the original function name and added the INT version. I also added the conversion to/from DBL to avoid the coersion. (see image).
-
 1
1
-
-
Crelf @ well over 13 bits! Better lay off the Vegamite mate!
I guess a lot of my posts were miscounted or lost. I'm at around 580 and I think I've contributed a few more than 65 posts since the recovery. LV_Punk lives on as LAVA 1.0 posts only

-
I vote to add an I32 VI (using Jim's code) and polymorphize the API.
I agree. This extends a useful function and makes good code reuse.

-
I saw a strange case of dirty dots that I attributed to the inplaceness algorithm. I posted an example here.
The gist of the problem had to do with changing the error wire in a subvi from error-in to error out to passing the data through a native function that MIGHT modify the error. The subVI must contain info that allows the inplaceness algorithm to short-circuit the wire. When I changed the low-level vi, all calling VIs indicate they need a save.
Don't know if this is what you are seeing, but it made me crazy for some time.
Inplaceness is synonymous with insidiousness ...
-
1
-
-
This old LAVA post had various examples of what you seem to want.
http://lavag.org/top...robber-example/
Unfortunately, the links are all missing. I tried to find my example on my local disk, but it seems to be gone...
You can use a picture ring. Add an image to a picture ring control by first using the Edit -> Import Picture to Clipboard menu option in LabVIEW. Select your animated gif file from your disk drive. Then right-click on the picture ring and Select "Import Picture After". You can now set the value of the picture ring to zero or one to hide or show your activity indicator.
Use a classic picture ring so you can easily hide the border and set the background for a 'clean' look.
-
Is it better for NI to provide backwards compatible (compat, legacy, oldvers, whatever you want to call them) VIs or to break the code when loading in a new version and requiring the user to understand the change and replace the broken code?
I just spent a day cursing at the computer because of a single NI supplied VI called "Write to XML File". See dark-side post here if you care why...
In my case, the NI function I called contained calls to subVIs labeled as unsupported. Would NI have cleaned this up if the practice of creating compatible VIs was not an option? Is this a failure of NI to use their own tools on their own libraries or a deficiency in the concept of compatible VIs?
It seems to me that a compatible VI should be like deprecating a node in an SNMP tree. Its not supported anymore, but the interface info still needs to be available to allow for selecting a alternate method.
My technique would be to provide a shell VI with all inputs required and a native function with required inputs empty to force the VI to a broken state. I would set the VI description to indicate the function is unsupported and provide suggested solutions and/or a reference to the release notes.
-
Very interesting results from some quick testing. The first time I run the test the Array method is as fast or faster than the for loop. For all subsequent tests the For Loop is much faster (10X). Ctrl-Run then the array wins the first race again.
This sounds like a development environment issue. Might a compiled version behave differently? (still using LV 8.6
) -
I'm not sure, but isn't "GetRawSocketFromConnectionID.vi" found in the TCP_NODELAY.LLB of that KB the the same as "vi.lib\Utility\tcp.llb\TCP Get Raw Net Object.vi"?.
-
A) I definitely would not provide default values for those input terminals. Make them required. I can't believe that the majority use case is going to be coin flipping between zero and 1. If you want to write a specialized "Coin Flip.vi", fine, but give that one a boolean output.
B) What happens if High is less than Low? Perhaps an absolute value node should be added to the subVI?
Since an integer value has no NaN or ±Inf equivalent, some real number is required. The existing function uses defaults of zero and one, so this would be consistent. The fact that an integer zero or one output can be interpreted as a Boolean was simply an observation. (Maybe default input values of 1 and 20 would be in order for the D&D folks
)I would suggest to make the Upper limit required, and check for the min/max (use the native sort 2 number primitive).
And I would make this a polymorphic VI with all the Int/UInts and double.
I like the 'Max and Min' function rather than the absolute value. I think we would have to subtract one from the improperly entered High value (less than low) and then round up in order to get the proper distribution. That would make the function overly complex.
Since the function name contains "in range", should we change the labels for the inputs to 'a' and 'b'? If so, how do you select which one to make required? (Maybe both? Neither?)
Please note that there is fairly complete collection of VIs for various data types and some extensions (like random array elements) located in sourceforge. They were submitted some time ago by dafemec as part of the thread I copied and pasted from.
So; I start a thread about a random array subset vi. A suggestion was made to maybe be a bit more simple and extend the existing random number function. I create an example, the find a nice collection of stuff. This stuff includes datatype specific versions of the function that started the whole discussion.

What do we want to do? Should we load the sourceforge files into this thread?
Links:
-
-
Random Number Sequence - Within Range (I16).vi
-
Random Number Sequence - Within Range (I32).vi
-
Random Number Sequence - Within Range (I8).vi
-
Random Number Sequence - Within Range (U16).vi
-
Random Number Sequence - Within Range (U32).vi
-
Random Number Sequence - Within Range (U8).vi
-
Random Numbers - Within Range (CDB).vi
-
Random Numbers - Within Range (CSG).vi
-
Random Numbers - Within Range (CXT).vi
-
Random Numbers - Within Range (DBL).vi
-
Random Numbers - Within Range (EXT).vi
-
Random Numbers - Within Range (I16).vi
-
Random Numbers - Within Range (I32).vi
-
Random Numbers - Within Range (I8).vi
-
Random Numbers - Within Range (SGL).vi
-
Random Numbers - Within Range (U16).vi
-
Random Numbers - Within Range (U32).vi
-
Random Numbers - Within Range (U8).vi
-
Single Random Number - Within Range (CDB).vi
-
Single Random Number - Within Range (CSG).vi
-
Single Random Number - Within Range (CXT).vi
-
Single Random Number - Within Range (DBL).vi
-
Single Random Number - Within Range (EXT).vi
-
Single Random Number - Within Range (I16).vi
-
Single Random Number - Within Range (I32).vi
-
Single Random Number - Within Range (I8).vi
-
Single Random Number - Within Range (SGL).vi
-
Single Random Number - Within Range (U16).vi
-
Single Random Number - Within Range (U32).vi
-
Single Random Number - Within Range (U8).vi
-
Random Number Sequence - Within Range (I16).vi
-
-
By Jim Kring (Copied from OpenG forums; posted there 21 April 2008 - 05:17 PM)
Proposal
I propose that we add support to the "Random Number - Within Range" for integer values by making it a polymorphic function that outputs a uniform distribution for integer inputs (that includes both the Low and High input values). Behavior for floating point inputs would remain unchanged.
Background
There have been a couple recent discussions about generating random integers with the "Random Number - Within Range" function, shown below:

When using the "Random Number - Within Range" function with integer inputs, most people (incorrectly) assume that the output will have a uniform distribution of integers between High and Low. When, in reality, the High and Low values will have half the rate of occurence than the values between High and Low, as shown in the screenshot and example VI, below:

EXAMPLE___Problem_with_Random_Integer_Generation.vi
Let's look at why this happens. Say we have a range from 1 to 10. Values from 1 to 1.5 will be rounded to 1. Values from 1.5 to 2.5 will be rounded to 2, values from 2.5 to 3.5 will be rounded to 3, ..., ..., .., values from 8.5 to 9.5 will be rounded to 9, and values from 9.5 to 10 will be rounded to 10.
As you can see, the values of 1 and 10 each occur in a range of 0.5 out of 9, whereas the values of 2 through 9 each occur in a range of 1 out of 9. 1 and 10 have half the rate of occurence of 2 through 9.
The solution is to extend the total range to High + 1 and then round the output value down, as shown in the screenshot, below:
With this correction, the distribution is now uniform, as shown below:

Open Issues
Convert to Poly VI or create a new, seperate VI for integers?
25]The Polymorphic VI can be named "Random Number - Within Range.vi__ogtk.vi", so that replaces existing instances of the DBL implementation in users' code. For users' existing code that is inputting floating point values into this function, the DBL poly instance will be used and thier code will remain unchanged. For users' existing code that is inputing integer values into this function, the new integer implementation instances will be used. This choice relies on the assumption that the new integer behavior is desired whenever integers are wired into this function. An alternate approach would be to simply add a new, seperate VI for the integer types --e.g., we might call thisRandom Integer.-
1
-
-
This OpenG Review is closed.
Based on Jim's suggestion in my post Select Random Array Indices, I submit this VI: 'Random Int Number - Within range'.
The existing OpenG Random Number VI would presumably be renamed and added to a polymorphic VI.
I chose I32 data types for compatibility with array indexing functions. The default values of one and zero allow this to be used with 'Not Equal to Zero?' to simulate a coin toss.
Discuss.
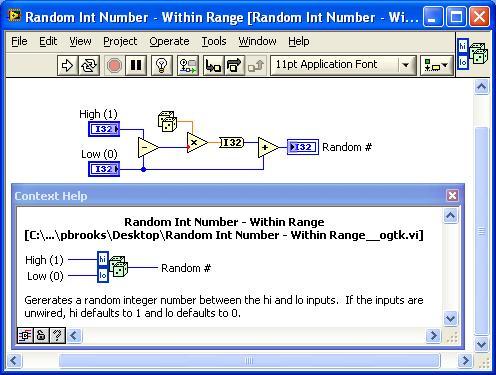
Random Int Number - Within Range__ogtk.vi
UPDATE:
I was going to provide a link to the existing OpenG 'Random Number' documentation. A Google search found that Jim already submitted something similar to the old OpenG forums, see here. Jim mentions that the high and low are negatively biased and solves this by adding one to the high value and then rounding down.
I think his is better. Rather than duplicate Jim's post and test code, is there a way we can import the discussion from the OpenG board to the LAVA board?
-
2
-
-
Btw anyone any thoughts about the note in the OP?
The only use case I can think of might be related to unicode or multi-byte char sets, but that brings byte order into play, and I think this dark side community doc has some functions that can do this already...
-
On my OpenG Comparison Tools palette, there is one item (Data Changed).
I would suggest that since there are no 'typical' nodes that we could standardize on a the larger 'Select' triangle along with a 5-3-3-5 pattern.
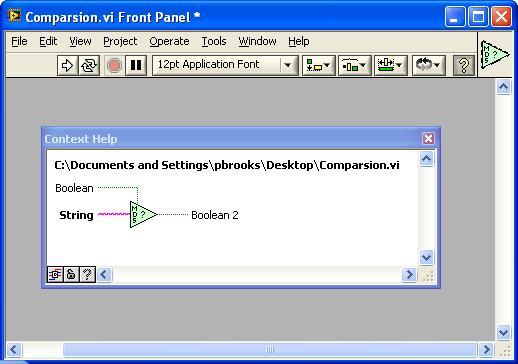
Rationale:
OpenG comparison functions will be extensions of existing functions and require additional inputs/outputs.
5-3-3-5 allows us more choices for the inputs and outputs.
The larger node provides additional room for text inside and differentiates the node from the native node.
We could also make it an Express VI
-
Code is in LabVIEW 2009.
Personally, I don't think this looks 100% right where the argument is - what do you guys think?
Also, it would helpful if you guys could post code of this VI with the CP's you want.
It does look a bit odd.
Sorry, I'm on 8.6 with no time or resources to have 2009 around.
-
If I recall correctly, the code in the disabled structures is treated the same as a comment in text based langauges. It does not get included in the built executable.
LabVIEW does allow you to build a 'debug' exe. I don't know if the disabled code would be included or not...
-
I've got on (little) thing:
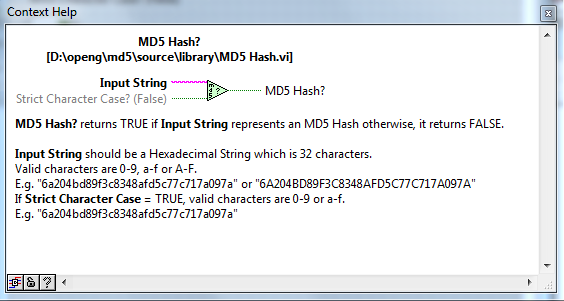
This shows that the primary input (the string) is not in the center of the Left hand Side of the Icon.
For programming style where this is in a wire, this gives odd layouts.
All of the basic LabVIEW =xxxx (ref, 0, >0, >=0, <0, <=0, NaN etc) the primary input is inline with the primary output.
The optional input (strict Character case) can be connected at te bottom or top (I prefer top).
I was going to suggest the same thing, but after years and years of working for managers who all have their own style (beauty is in the eye of the beholder) I was going to let it go. As a natural extension of functions, I think it should be consistent with the other comparison palette functions (in line).
I would suggest the Boolean 'strict' option be shown similar to other NI functions such as Array of Strings to Path and labeled 'strict case'.
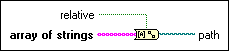
-
1
-
-
It disables the Nagel algorithm in win 7. It seems to have improved things significantly.
If you look carefully at some of the LabVIEW posts regarding Nagle's Algorithm, you can find references to (or actual) VIs that you can use to toggle Nagling on a PER CONNECTION BASIS within your LabVIEW code. You certainly can make changes in Windows (via the registry) but this will affect all apps.
-
1
-
-
There must be a LabVIEW.ini key that let's you create these.
SuperSercretFunkyBlackWireThatDoesWhateverYouWant = TRUE[/CODE]
[/font]
-
I don't know, but there IS on on the OpenG Variant palette...
-
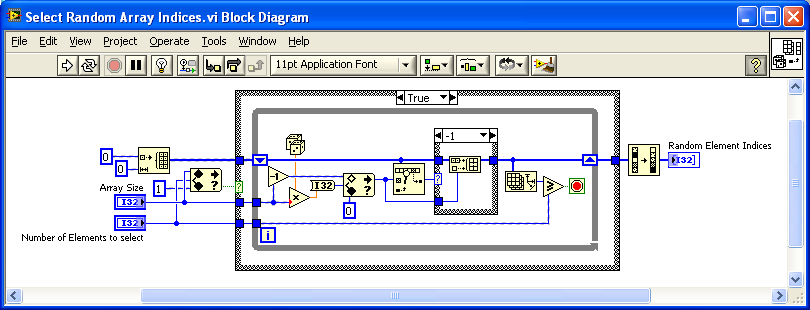
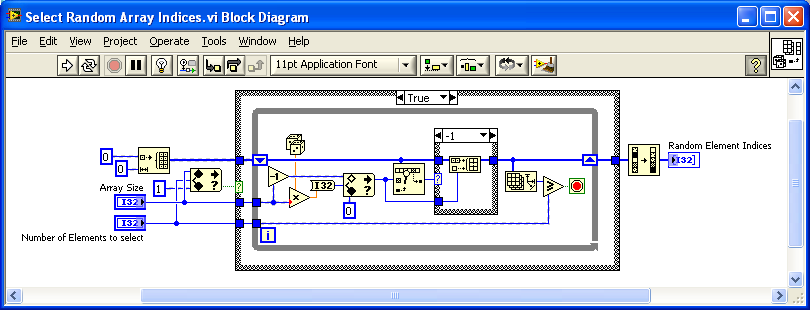
I looked at some of the riffle posts on the dark side and noticed that riffle seems to be part of the FDS. Base folks wouldn't have this function to use.
The other thing is that the array to be riffled is modified and must by an array of DBL, CDB or I32. My example does not use the data array as an input, only the size and number of elements to select. It would work for an array of clusters etc...
Maybe an OpenG riffle function for base users and arrays of other types is useful?
-
My use case was for product sampling. We receive lots/batches of serialized products that we test for performance and prgramming. The sample size depends upon the previous lot/batch success rate. I perform the selection in Labview and update a database on pass/fail.
We also have a device that is characterized by a polynomial. A lookup table for every step setting was in excess of our storage capacity. We collect a series of points, perform a fit, and then randomly test a couple of points against the polynomial for accuracy.
Wouldn't this work like the Riffle function in LabVIEW (where your code takes the first n outputs)Ton
When I took this random elements code (really badly done) and rewrote it, I remembered an NI forum post about randomizing a deck of cards and couldn't remember the name of the function. I guess riffle used with array subset would be the ' NI' way to do it.
Thanks for reminding me!
-
I was recently cleaning up some awful code and extracted this piece as a general purpose function.
I have problems with using VI Package manager at work and also still run LabVIEW 8.6.1, so I don't know if a recent OpenG function similar to this exists.
Timestamp support for Format into String & Scan Variant From String (String Package)
in OpenG Developers
Posted
After a few dark side and twitter posts cursing date and time formatting, I have to say I STRONGLY support using ISO 8601 compliant strings. Be aware that the format specifiers for the "Format Date/Time" primitive are NOT always interchangeable with ISO 8601.
I posted an ISO-8601 example on the dark side that supports extended and basic formats as well as ordinal dates.
https://decibel.ni.c...t/docs/DOC-7199
I've attached a copy here.
8601 UTC Date-Time String.vi