Search the Community
Showing results for tags 'slow'.
Found 3 results
-
I have an array of classes, let's call the object TestPass, of size 1 (but it is an array because it can scale out to multiple test passes). In this class, there is one other nested class which is not too complex, then various numeric and string fields to hold some private data. There is also an array of clusters. In this cluster there is a string, two XY pair clusters, and an integer. Not very confusing. This array of clusters gets fairly large, however, upwards of 80-100k elements. What I am finding is when I index the array of pass classes it is crazy slow. On the order of 30 ms. Doesn't seem like much, but we are indexing the array in our method to "Get Current Pass" which is used in various places throughout our code. This is adding potentially hours to our test time over the 80k devices we are testing. So, I started digging. When I flatten the class to a string and get the length, it's 3 mb. But, when I run the function with the profiler is is allocating close to 20 mb of memory! My gut feel was that the string is causing the issues. So I removed the string from the cluster and the index time went to 0 ms. Luckily we can normalize a bit and pull the strings out of the cluster since a lot of them are duplicates. But it makes our data model a bit uglier. Has anyone seen these kind of performance issues before? I saw them in 2013 and 2017.
-
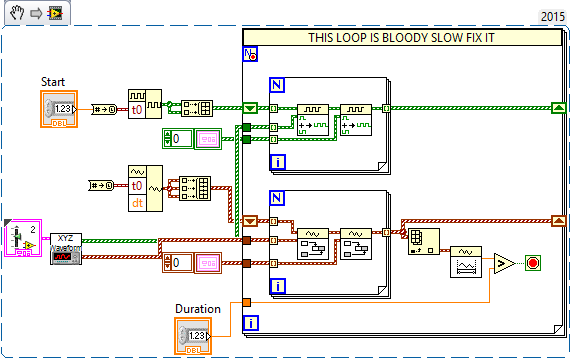
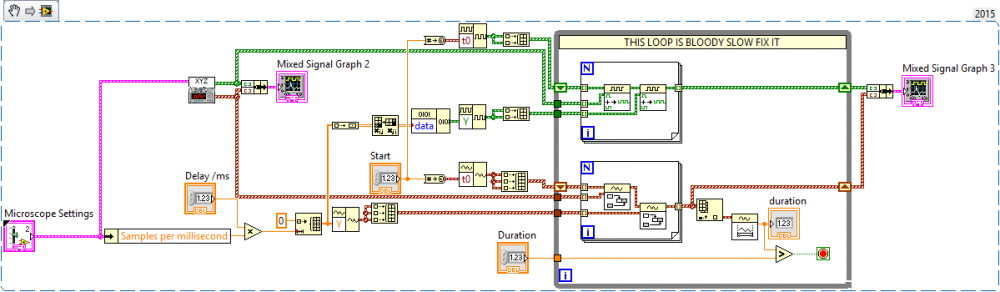
Hi All, I have 3 analogue and 2 digital waveforms that I want to repeat multiple times with a delay between them. I could do this programmatically using a while loop during their playback but ideally I'd like to create a waveform as a delay and concatenate them all so that the resultant waveform is the what will be sent. My current solution is to have a pair of for loops inside a larger for loop. The sub for loops concatenate the waveforms with the shift registered waveforms and then with a waveform of my choosing (the delay waveform). Attached is a snippet of code. However, to produce a waveform that has 200 repeats takes around 20 seconds to build. This is not ideal and considering it is just array manipulation I feel like there is a fast way of doing this using the in place operator, but I don't personally know how. Any advice welcome, Thanks, Craig

-
 I am writing a performance-sensitive application which requires the use of a nearest-neighbor lookup. Originally I used a brute-force method, but unfortunately this gets to be very slow as the data size increases . I have a point cloud of ~100k points in 2D, and need around 50k nearest neighbor lookups per second as a minimum performance requirement. As a solution I wrote a kd-tree in .Net and used LabView to call the .Net dll. However, I discovered that each .Net transaction carries with it about a 0.5ms delay. I've tried bunching the data up into groups, but this only helps so much, as I am using an iterative process. Armed with my new-found kd-tree knowledge, I then wrote the kd-tree in LV-OOP, using DVRs for both subtrees and leaf values. However, my LV implementation is still 100x slower than the .Net implementation, and 20x slower than brute force. And this is with just 10k points. I'm fairly new to LV (about 6 months in an academic environment) and I'm fairly sure I've made a massive blunder somewhere, but I don't have any idea what it might be. http://robowiki.net/...d-tree_Tutorial is the tutorial that I used for writing both trees - note that I've only implemented a 1-NN lookup method, so have no need for the priority queue. Just some notes: I found using in-place data structure unbundle-bundle was much faster than using normal unbundle-bundle for all of the read/writes. The tree started out with pure by-value subtrees and data, so was even slower before I changed to DVRs. The lookup uses a queue as a stack, rather than being recursive. Not sure if this is good or bad. The add element uses recursion. Again, not sure if this is good or bad. I've written speed tests for brute force, .Net and LV lookups with names like with test_...... .vi if you want to compare performance. kd_tree Folder.zip Thanks in advance for any help Julian Kent
I am writing a performance-sensitive application which requires the use of a nearest-neighbor lookup. Originally I used a brute-force method, but unfortunately this gets to be very slow as the data size increases . I have a point cloud of ~100k points in 2D, and need around 50k nearest neighbor lookups per second as a minimum performance requirement. As a solution I wrote a kd-tree in .Net and used LabView to call the .Net dll. However, I discovered that each .Net transaction carries with it about a 0.5ms delay. I've tried bunching the data up into groups, but this only helps so much, as I am using an iterative process. Armed with my new-found kd-tree knowledge, I then wrote the kd-tree in LV-OOP, using DVRs for both subtrees and leaf values. However, my LV implementation is still 100x slower than the .Net implementation, and 20x slower than brute force. And this is with just 10k points. I'm fairly new to LV (about 6 months in an academic environment) and I'm fairly sure I've made a massive blunder somewhere, but I don't have any idea what it might be. http://robowiki.net/...d-tree_Tutorial is the tutorial that I used for writing both trees - note that I've only implemented a 1-NN lookup method, so have no need for the priority queue. Just some notes: I found using in-place data structure unbundle-bundle was much faster than using normal unbundle-bundle for all of the read/writes. The tree started out with pure by-value subtrees and data, so was even slower before I changed to DVRs. The lookup uses a queue as a stack, rather than being recursive. Not sure if this is good or bad. The add element uses recursion. Again, not sure if this is good or bad. I've written speed tests for brute force, .Net and LV lookups with names like with test_...... .vi if you want to compare performance. kd_tree Folder.zip Thanks in advance for any help Julian Kent