Leaderboard




Popular Content
Showing content with the highest reputation on 09/13/2010 in all areas
-
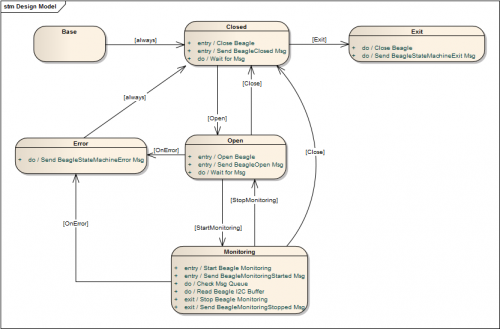
There's been a lot of discussion about state machine patterns the last couple months. Admittedly a good part of it is because I'm so vocal in my dislike for the QSM, but Paul posted an excellent document recently and Justin and Norm pimped the JKI state machine and the TLB state machines respectively at NI Week. Last night I posted a broken example of an object-based state machine. This morning I was feeling guilty about it, so here's a version without the missing libraries. To reiterate from last night's post... ------------------------------ Here's a state machine for a Total Phase Beagle I2C monitor I recently put together using the pattern I described on Paul's other thread and Felix mentioned here. The benefit of having separate sections of code for entry, do/execution, exit, and transition actions can't (IMO) be overstated. It's way easier for me to understand and extend than any flavor of QSM. QSMs are further limited by the restriction of only performing entry actions and must repeatedly exit and reenter the same state. Notes: - Project code is available for LV 2009 or LV 2010. They are otherwise identical. - The project is dependent on the attached vip. Install it using VIPM before opening the project. - The attached vip is currently intended for LapDog developer use. Obviously you are free to use it, but it may not be compatible with future versions. It's an updated version of the library I posted here. (Please pay no mind to the really lame LapDog palette icon. I'm hoping someone comes up with something better.) - I replaced the original Beagle library with a ghost "BeagleApi" library. The vis in the ghost library are there simply for their connector panes--there's nothing in them. - There's not much documentation... I didn't expect to be sharing it yet. - The BeagleStateMachine class is the main public api. It contains the data required for the state machine to operate and shared accessors to that data for the state objects. - Each state is a separate class that derives from BaseState. - TestBeagleStateMachineLibrary is an example of how to use this state machine. Or you can build an Actor class around it. - The state diagram below is also on the bd of BeagleStateMachine:Execute. - If I ever get tempted to use a QSM again for anything non-trivial... please shoot me. The pain isn't worth it. [Edit 9-12] Uploaded a new copy of the 2010 version. The previous version was still attempting to link to a different MessageLibrary. lapdog_lib_message_library-0.7.0.1.vip BeagleStateMachine2009.zip BeagleStateMachine2010.zip
 1 point
1 point -
Darren Nattinger (he of Darren's Nuggets fame) and I need your help. Darren is known for writing useful VI plug-ins for LabVIEW. I've had a history of creating hooks in the C++ code for calling plug-in VIs. He and I both dislike the current behavior of the Create SubVI From Selection feature. It doesn't know about the config token for preferred connector panes, it doesn't put error terminals at the bottom and class/refnum terminals at the top, it sometimes names a control "error out" and an indicator "error in", and the panel isn't laid out as clean as we might like. These are all things that could be fixed in the C++ code, but spare developers are always hard to come by, and Darren already has some G code for doing this work. Thus it made sense for the two of us to work out an interface from C++ to G to improve Create SubVI From Selection. In our spare time, we've found the right place in the C++ code to hook, figured out the data that needs to go across the interface, and gotten the code pretty close to finished. Once we knew it was going to work, we asked for permission to add it as a feature in 2011. That's where we hit a problem we cannot solve alone. As many of you have heard, LabVIEW 2011 is focusing on being a stabilization and performance release. Very few new features are being let in the door. The one gate that new features have is the Idea Exchange. The feature has to be limited in the amount of code it has to touch. It has to avoid performance degradation. And it has to be something customers clearly want. We can show two of those three requirements, but not the third. Without the third, the feature does not meet the goals for LV 2011, so even though Darren and I have the new callback hooks largely ready to go, the code cannot go in. This makes us sad. I mean, it makes perfect sense -- we have to have standards, and limiting the features for this release is important -- but it still makes us sad. "Create SubVI" is an area of LabVIEW that many of you have asked me about over the years, hoping that LV could do a better job. Darren and I really want to see this feature go into LV 2010, and we're pretty sure that there are enough of you out there that would like to see it too. If we could get the Kudos on the idea up so that the idea is in the top 15, we will be able to make the argument that this is a feature that users strongly want. Now, not every idea with high kudos is automatically blessed in the 2011 release, but with enough Kudos, we think we can get permission to proceed. There are 3 ideas on the idea exchange that are all affected by this idea, but let's focus on the one that has the highest kudos already: Create a proper connector pane when doing Edit -> Create subVI As of right now, that's got 79 kudos. To make it into the top 15, we need 160 kudos, or almost exactly double what it has right now. I think this is an idea whose time has come. If you agree, please contact your friends. Make peace with your enemies. Call your mother. Encourage them all to take a moment to go vote for this idea. If you're super ambitious, there are two other related ideas that would also be aided by our feature. You could go vote for them too. But focus on the big one first! Provide a way to define the default connector pane Edit >> Create SubVI: Tweaks Help make Mercer and Nattinger unsad! Help improve Create SubVI! Vote now!1 point
-
Stability and performance are great, but do they have to come at the price of features? Many of the suggestions in the exchange are relatively simple ones and I assume NI could say "OK, we want LV 2011 to be mainly more stable, but we also want it to have some features, so we're going to invest N developer time on doing some of the more simple requests". I assume NI is already using this logic, but N does NOT have to be a small number. If N is large enough, then this feature should be able to make it in relatively easily (and without knowing internal details or looking through the exchange too closely, I still contend that N could probably be high enough to implement at least 20 of the relatively simple ideas there without endangering the overall stability goal, including this one, although I could obviously be completely wrong). Also, you can probably count the kudos for the two ideas together. I assume there's some overlap, but you don't have to tell the managers that.1 point
-
Inheritance and Dependencies are not Associations. If I remember correctly, they both are decendants of 'relationship', while the Association is a Classifier itself. Also note, that associations connecting properties (so not methods or parameters). Because they are connecting properties and properties can be stored in the classes private data (if the properties belong to the class), it is always necessary to have the type cast in LV for bidirectional associations. It was clear to me that you can have bidirectional associations with by-ref implementations (also requiring the type casts). I was questioning if the same is possible with by-val design, which you showed is practical code. Yes, that was my point. From the formal point, the state machine should contain the 'alphabet', the states, the transitions, the initial state and the final states (Σ,S,s0,δ,F). But I'm not sure if this really would lead to a 'better' code. Doing it all the way as 'correct uml' with region->vertex->state seems like an overkill to me at the moment. I was actually looking at the mathematical model. I'm ok with an implementation compromise. I was thinking more about this. From a 'formal point of view' where I just look at the abstract state machine, it is very clear to me that states (executing code fragments) should be seperate from transitions (defining the order the code fragments are executed). I think this seperation is even more functional than Entry/Do/Exit. This is one of the big questions: to what extend should code reflect the uml meta-model, how concrete (or strict) should be the uml syntax. Felix1 point
-
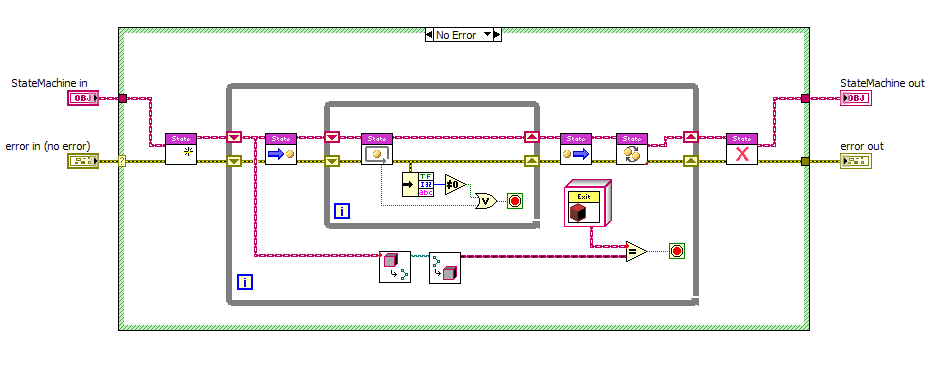
[Copied Paul's question from another thread to try and keep discussion contained.] Just to make sure we're all on the same page, here's how I use the various terms: Entry Action - Executes one time every time the state is entered, regardless of the previous state. Execution* Action - Executes continuously until the state decides it's done. Exit Action - Executes one time every time the state is exited, regardless of the next state. Transition Action - Executes after exiting one state but before entering the next state. Each transition action is associated with one arrow on the state diagram. (*Also known as "Do Actions" or "Input Actions," depending on the literature.) You're thinking in QSM terms where each case is a state. That's a flawed approach. It requires you to repeatedly exit and re-enter the state so you can monitor the queue for new messages. As you said, you have to somehow keep track of whether we're re-entering this state or entering it from another state to be able to handle entry actions. I skip all that confusion and use separate vis for EntryActions, ExecutionActions, ExitActions, and StateTransition methods. The action sequencing is done by the StateMachine:Execute method, as shown below. The outer loop executes only one time for each state. The inner loop continues executing the state's ExecutionActions method until the state receives a combination of input signals the state understands as a trigger to transition to a new state.
1 point
-
An association (as I understand it) is a more general link betweeen classes on the UML diagram. It could be composition, dependency, delegation, inheritance, etc. I can have an association between two classes without either class definition containing an instance of the other. For example, if ClassA:Method1 has a ClassB input terminal, ClassA is dependent on ClassB without necessarily containing ClassB. At the same time ClassB:Method2 can have ClassA as an input terminal. This is a bi-directional association and allowed in Labview. Labview disallows bi-directional composition of classes. No cycles allowed in class definitions. That's where LVObject (or some other parent class) comes into play. Yes, you are reading the code correctly. Since the BaseState definition contains the BeagleStateMachine class, the BeagleStateMachine definition cannot contain BaseSate in the NextState field, so I used LVObject. Note the BeagleStateMachine's NextState accessor methods do use BaseState as input/output terminals, so there is a bi-directional dependency between the two classes. Yep, functionally it is a more well-defined variation of the Standard State Machine template provided with LV. My intent has been to find a better alternative to the QSM, not necessarily a more defined variation of the Standard State Machine template. That that's what I ended up with speaks to NI's foresight in including that template in the first place. Too bad it's not more widely used. In my experience OO programs are almost always harder to understand than procedural programs by just reading the code. It takes a lot of work to understand the relationships and responsibilities of the objects. However, once you understand those relationships OO code is easier to understand and easier to modify. I've done a lot of UML modelling on whiteboards. I also use pencil and paper when a whiteboard isn't handy. The primary goal of my modelling is to figure out a design that will meet the requirements, not create a complete, formally-accurate UML representation of the program. I try to include enough documentation to help others understand the relationships. Usually that means a class diagram and some sequence diagrams for the more complex operations. Recently I've taken a suggestion from Ben and started including documentation bitmaps on the block diagrams. This is one of the key differences between a state machine and the QSM. A QSM has a command queue; a state machine does not. In a QSM the queue controls state sequencing. In a state machine the state machine controls sequencing. In "real" state machines the machine monitors input signals and acts based on those input signals. Nothing tells the machine to make a transition; it decides when to make the transition based on the input signals. In earlier implementations of this pattern I used a DVR of a boolean cluster to represent the state machine's input signals. In this implementation I switched over to a message queue for transmitting input signals since all my input signals are essentially requests to go to a new state. In a nutshell this is one of the major problems of the QSM. The queue in a QSM is issuing commands the state loop must follow. In this model the queue is for issuing requests to switch states. It is a subtle difference, but the consequences are huge. [Edit] On re-reading I think you're saying the state machine should have access to the input signals, but the states should not. Is that correct? This was an implementation compromise. I've considered a more pure model where the state object would invoke a transition object, which in turn would execute its actions and prepare the next state object. I haven't run across a state machine where I needed a lot of independent transition actions, so the additional complexity isn't worth it. If actions need to be performed on a specific transition when exiting a state, you can override the StateTransition method, query NextState to determine which transition is taking place, and drop the transition code in a case structure. As I understand it, UML specs define model behavior not implementation details. The modelling rules and objects may or may not translate directly into code. I'd have to see a very clear benefit to justify the additional complexity of an implementation that matches UML behavior. (That's not to say it isn't there... just that I don't see enough payback yet.) Dunno yet. Probably, but I'd want to let the design age a while first. Yep. Imagine the code in the Test vi (but written for a different state machine) being in one of the of the state's Execute method. Yep. I wrapped the above state machine in AQ's Actor Framework so it will spawn a parallel thread. As long as the state machines are written with the appropriate input and output signals there's no reason it can't be done.1 point
-
Looks really cool. Did take me some time to follow the cycle from Paul's big paper through the other threads, and I certainly miss some of the discussions. A lot of half finished thoughts from my side, but I just throw them in the debate as fuel for all of you: Bidirectional Association of by-val classes This has kept me thinking for some time when studying the association meta-class of uml for my latest post on my blog. At first I was convinced that by-val design only allows uniderctional associations of classes. But theoretical thinking told me, that if class A contains class B, I can place class A in a LVObject in class Bs private data (inside the Get method). Later I then can retrieve class A back from B with a type cast and update the values of B inside A. If I read the code correctly, this is implemented between StateMachine and State. If so, thanks for the proof. Dynamic dispatch instead of enum/case This was discussed on the NI forum recently (I don't remember the thread). Basically, the traditional enum shift register and case structure design is completly replaced by dynamic dispatching. Again, if I understand this correctly, thanks for the demonstration. Readability of the design This is dating back to my first analysis of state machines. I did browse some text-based implementations of state machines. I think they used a very similar design. At that time, I felt the case/enum SMs in LV very superiour as they directly present me the code instead of the general state machine design. This is nothing if I have an up-to-date documentation in uml as presented. But getting to the concrete code takes me a couple of clicks more than when I use the traditional non-OOP approach. I would list this as a big con because I have to do a lot of 'cowboy coding' on customers site and neither have the uml tools available there nor the time for proper modelling. But I see that I have the possibility to attack a task by at least two ways: EITHER going through the state machine and accessing the concrete dynamic dispatch vi of Enty, DoActiitiy or Exit OR going through the class of the states and having in the PE for every class access to all three Activities. Now comes the theoretical stuff: state machine theory I: transisitons I checked the wikipedia entry on state machines. The mathematical modell suggests that a state machine has states, transisitions and an alphabet. From this, the state classes should not have access to the command queues (alphabet). Also they should not contain the transitions, tranisition logic and TransisitionActivity. state machine theory II: Entry state The initial state is also part of the state machine definition. So the private data cluster of the stateMachine class should contain a set (array) of state classes and an initial state (which is 'listed inside'/ 'an element of' the set of states (can you force this?). uml I: transisitions I just did have a very brief look at the state machines in the uml specs. Transisitons are seperate from States. The transitions are performed by the state machine meta-class and not the state meta-class. This is a bit tricky in the implementation, but described in the specs: If the states DoActivity finishes execution, it's generating an event/trigger. If a trigger is received by the SM, the DoActivity is aborted Certain triggers can be deffered as an attribute (?) of the state. I didn't get all of this in my head at first reading, so propably anyone who mights try to improve the design be adjusting it to uml: Superstructure Chapter 15; Tranisitions 15.3.14; 15.3.11; current spec. uml II: pseudostates To get even more out of such a state machine design, we could target the list of pseudo-states. I consider all parallel process options to be really cool in LV, so fork and join could be nice to have. Even more I'm struggling with the concepts of Deep and Shallow History. uml III: orthogonal regins, sub-statemachines Now I'm really leaving my LV knownledg and completely focus on uml state machines. Is it possible to have a general (reusable) state machine class (and each specific state machine is inherited from this with it's own set of states)? Can we do a nesting of state machines (the top SM contains a state that contains another SM)? Can we find a deign to have two and more SM's running in parallel as 'orthogonal states', including proper mechanism to stop the others in case of severe errors in one of them? Ok, enough of theory. Hope this hobby of mine helps you to get projects out and is not just a waste of time. My professional work is completly non-OOP, non-uml. Felix1 point
-
Paul, Would the MathScript contours function (legacy name contourc) meet your needs? It returns the same data that contour uses but without popping up a plot window, so it is supported in the Runtime Engine. Greg, You'll be happy to hear that we are working to bring many MathScript algorithms into the LabVIEW palettes. All of the ones you mentioned are currently on our road map. If you have any other requests, please let us know! And just a general comment about using the MathScript internal VIs on your diagrams. I can't think of any major harm in doing this, besides the risk that the API will change between versions. For example between LabVIEW 8.6 and 2009 all of the built-in function internal VIs were refactored and renamed. If you do ever use these VIs in your application, I'd recommend making a copy of the entire hierarchy to avoid being bitten by changes like this. JesseA LabVIEW MathScript R&D1 point