Leaderboard




Popular Content
Showing content with the highest reputation on 05/30/2013 in all areas
-
To follow up some of my earlier questions for future readers: I used to keep copies of all VIs under both targets, but it was a pain keeping them synchronized. On top of that the classes would end up locked because it was being loaded on multiple targets. Now I keep all the RT code under one target and copy the top level VIs to the other target when I need to run the code on that target. It seems to be working quite well. Currently I have my entire FPGA code fully listed under both targets, but I'm pretty much done with that and just haven't bothered cleaning it up. It doesn't have the same problem with locking VIs so there's no motivation to mess with it right now. I suspect I could just copy the top level FPGA VIs to each target and it would work fine. Each FPGA target does maintain its own project-defined resources and build specs. I had thought all symbols were defined in the project and the built-in symbols did some magic behind the scenes. Turns out it is much simpler than that. I discovered each RT and FPGA target has its own list of conditional disable symbols. Setting symbols for each target means I don't have to remember to switch symbol values every time I run the code on a different target. The FPGA_TARGET_CLASS symbol lists the platform model, such as CRIO_9074 and SBRIO_9636. Very handy.1 point
-
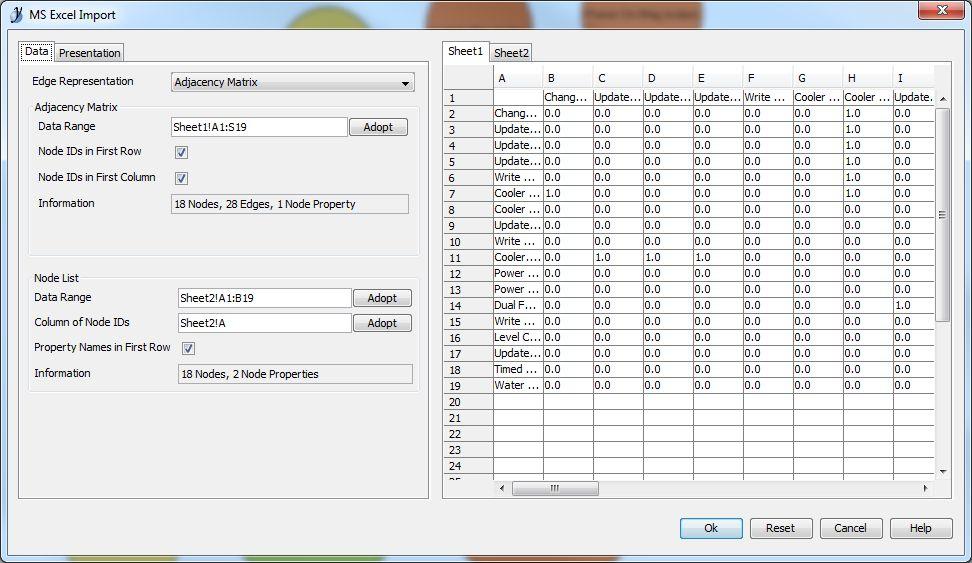
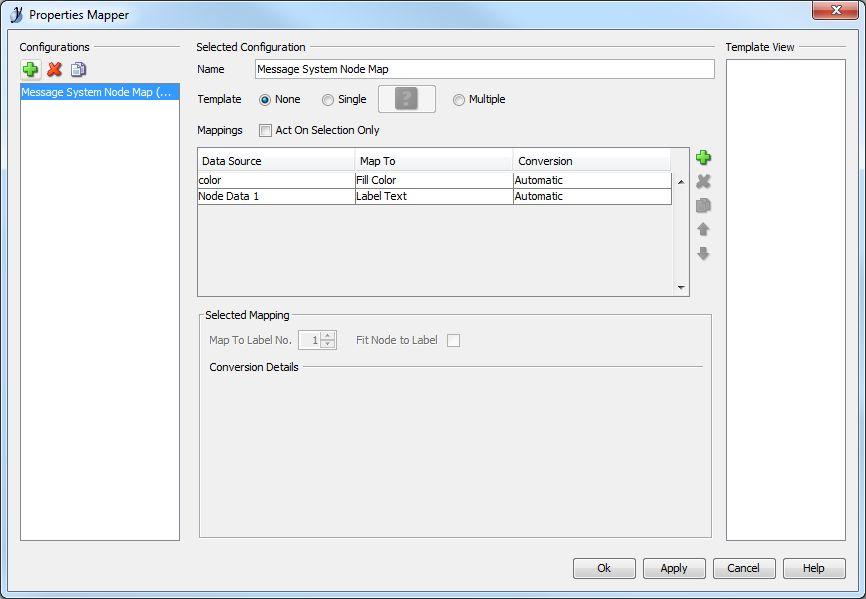
Due to the overwhelming response I put together a solution using some free online tools. First, you will need a tool called yEd. (http://www.yworks.com/en/products_yed_about.html) This is a very nice free tool for generating various graphs and charts. Next you will need Excel because that is the file type yEd uses to import an adjacency matrix. Last, you will need some LV code to generate an adjacency matrix and node property list from a project. Here is one I made for Actor Framework. Please excuse the poor code layout as I hacked this together quickly. Generate AF Node Map Data.vi (Note: this can easily be adapted to other message systems. The only change would be the mapping for the color properties to the appropriate parent classes. Open the VI, choose your target project and your destination xlsx file and run it! You will get a file like this: AF Demo node list.zip (zipped for your protection. ) Next you need to open this file in yEd. When you do, you need to set the data ranges correctly, like this: and choose a presentation configuration like this: which I created earlier using this: The end result, after a few cosmetic tweaks results in this: Pretty cool, eh? (Well, I think it is useful. I always prefer to visualize my applications. Complex apps using messaging architectures can get pretty hard to follow without good documentation.) I hope others find this useful. -John
 1 point
1 point -
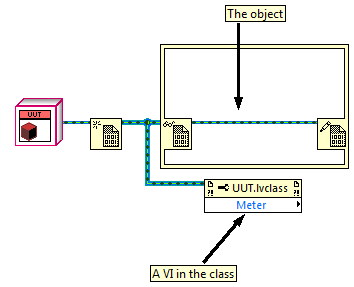
You'll be happy to hear that people have thought of similar things before (for instance - http://forums.ni.com/t5/LabVIEW/LV2OO-Style-Global-VIs-from-NI-Week-2007-presentation/td-p/562527) and that LV has a much simpler mechanism for doing this - create a regular class, then create a data value reference to an object of that class. The DVR allows you to access the object using the reference. If you create property folders for the class, then the property node can even accept a DVR and get the object out of it automatically. A simple example:
1 point
-
If you think for a few seconds about it you will recognize that this is true. When a path is passed in, LabVIEW has at every call to verify that the path has not changed in respect to the last call. That is not a lot of CPU cycles for a single call but can add up if you call many Call Library Nodes like that especially in loops. So if the dll name doesn't really change, it's a lot better to use the library name in the configuration dialog, as there LabVIEW only will evaluate the path once at load time and afterwards never again. If it wouldn't do this check the performance of the Call Library node would be abominable bad, since loading and unloading of DLLs is really a performance killer, where this code comparison is just a micro delay in comparison. If I would have to have a guess, using a not changing diagram path adds up maybe 100us, maybe a bit more, but compare that to the overhead of the Call Library node itself which is in the range of single us. Comparison of paths on equality is the most expensive comparison operation, as you only can determine equality if you have compared every single element and character in them. Unequality has on average half the execution time, since you can break out of the comparison at the first occurrence of a difference.1 point