Leaderboard




Popular Content
Showing content with the highest reputation on 04/30/2014 in all areas
-
Wow. Lots to respond to here. You can also pass in floating point numbers, but be careful: LabVIEW uses the IEEE 754 round-to-nearest even integer rule when rounding numbers that end in .5. 102.5 rounds to 102. 70.5 rounds to 70. 71.5 rounds to 72. Also, the behavior changed in LabVIEW 2010. To Upper Case, To Lower Case, Octal Digit?, Decimal Digit?, Hexadecimal Digit?, White Space? and Printable? all allow you to wire in a numeric. According to their documentation, those nodes evaluate the numeric as the ASCII character corresponding to the numeric value and in all other cases return FALSE. In LV 2009, they return false for any value over 256. In LV 2010 and later they return true for some values -- corresponding to the proper return value for the lowest 8 bits. E.g. LV 2009's White Space? primitive returns true for Int32(10) -- the line feed character -- and false for Int32(266). In LV 2010 it returns true for both. I'm usually the loudest complainer about people treating strings as a byte arrays. In most programming languages, strings are not bytes arrays. In some languages, for legacy reasons you can treat them as byte arrays. In LabVIEW they are byte arrays. That results in interesting things with Multibyte Character Sets. I don't have any of the Asian localized LabVIEWs installed, but I think strings in those languages will have a string length reported as twice the number of characters that are actually there. When you have the unicode INI token set, this is definitely the case. Arguably that's wrong, but there's no way to go back and change it now. I couldn't agree more to your first three paragraphs, but I've got to disagree about the difficulties. The platforms which are supported is entirely related to the language and compiler for that language. Any time -- absolutely any time -- strings move from one memory space to another (shared memory, pipes, network, files on disk) the encoding of the text needs to be taken into account. If you know the encoding the other application is expecting, you can usually convert the text to that encoding. There are common methods for handling that text that doesn't convert (the source has a character that the destination doesn't have), but they're not perfect. The good thing is that it'd be extremely rare since just about everything NI produces right now "talks" ASCII or Windows-1252, so it's easy to make existing things keep working. What you're talking about is how the characters are represented internally in common languages. In C/C++/C# on Windows they're UTF-16. In C/C# on Unix systems they're UTF-32. As long as you're in the same memory space you don't need to worry. There is no nightmare. Think of your strings as sequences of characters and it's a lot easier. As soon as you cross a memory boundary you need to be concerned. If you know what encoding the destination is expecting you encode your text into that. If/when LabVIEW gets Unicode support, that will be essential. Existing APIs will be modified to do as much of that for you as possible. Where it's not clear, you'll have the option and it'll default to Windows-1252 to mimic old behavior. Any modern protocol has its text encoding defined or the protocol allows using different encodings.2 points
-
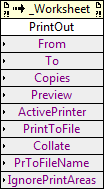
Ok, it's been several years now, but here's what I remember. There's some bug with the PrintOut method of the _Worksheet class, which is called by Excel_Print.vi in the Report Gen API: Let's say I save a VI with this method on its diagram in LabVIEW 2012. Then I give you the VI. If you're also running LabVIEW 2012, the VI will not be recompiled because we're using the same LabVIEW version. But if the ActiveX components for this Excel library are a different version (mostly likely because we're running different Office versions), then the method will be broken on your system. If you were running LabVIEW 2013, though, the VI would be recompiled because of the LV version difference, and the method would not be broken. Through our investigations, we found that this method was the *only* one in the entire Report Gen Toolkit API that exhibited this behavior...every single other property/method that we call in our VIs would detect the ActiveX component version difference just fine and force a recompile of the VI, even if the LabVIEW versions were the same. To my recollection, we found that there was a bug in the implementation of the PrintOut method itself that was causing us to not see the version difference on VI load. So, the best workaround we could come up with on our end was to force a recompile of the Excel_Print.vi on every installed system by installing a version saved in an older LabVIEW. We figured requiring a save of the VI was less of a burden on users that requiring an edit of the diagram (deselecting and reselecting the method).
 1 point
1 point -
I see this as a typical thing with LabVIEW Toolkits. It is common that thought you download and install LabVIEW Toolkit 'whatever' for LabVIEW version 'whichever', it does not mean that ALL the VI's in the said Toolkit have been saved to that specific version of LabVIEW and when you first open or use some VI's from that Toolkit you then need to save those VI when they or the VI using them are closed. This is because the VI's open have been compiled to the new LabVIEW version. Then when you move your code onto a new PC with the same toolkit you need to do it again as the VI from that toolkit on that PC also need to compile for the new version of LabVIEW. You could by habit use the mass compile tool to all newly installed toolkits or each PC or just accept the fact and save the changes, once save this should not occur again. If NI toolkits ever ship with 'separate compile code' enabled this problem would go away, or if NI mass compiled all their toolkits and then you would download a specific version of toolkit for each LabVIEW version. To be honest I just live with it, it does not bother me that much1 point
-
My bad, I already forgot it had to be 64 columns each page... I've tested again and hit the same limitation on the 32-bit environment (with Excel using up to ~1.7GB of memory according to the Task Manager). Your system is more than sufficient for that operation (unless as rolfk correctly pointed out, you use the 32-bit environment). This is absolutely right. There is however one thing: Excel runs in a seperate process and owns a seperate virtual memory of 2GB while in 32-bit mode. So you can only create a workbook of that amount, if there is no memory leak in the LabVIEW application. In my case LabVIEW will take up to 500MB of memory, while Excel takes 1.7GB at the same time. If the references are not closed properly, you'll hit the limit much earlier, because LabVIEW itself runs out of memory. In my case the ActiveX node will throw an exception without anything running out of memory (well Excel is out of memory, but the application would not fail if I would handle the error). I have never tried to connect Excel over .NET... Worth a shot? jatinpatel1489: as already said a couple of posts ago: Make use of a database to keep that amout of data. If the data represents a large amount of measurement data, TDMS files are a way to go (I've tested with a single group + channel, with a file size ~7.5GB containing 1Billion values -> milliard for the european friends ). You can import portions of the data in Excel (or use a system like NI Diadem.. I've never used it though). If it must be Excel, there are other ways like linking Excel to the database (using a database connection). Last but not least you could switch to 64bit LabVIEW + 64bit Excel in order to unleash the full power of your system.1 point