Leaderboard




Popular Content
Showing content with the highest reputation on 04/20/2020 in all areas
-
Hey LAVA friends. I'm going to be doing a live-stream on Youtube next Tuesday April 28, (10AM Pacific) to go over LabVIEW Community Edition. I'd love to see you guys there. It'll be interactive with chat for your questions, and I will be making an attempt to talk to a Raspberry Pi and Arduino. If you're curious about low-cost hardware or just want to find out what's new in the latest LabVIEW. Join me here: https://youtu.be/4HLVqYXpxIo. Edit: If any of you have done any projects with the supported hardware. Let me know and I can mention you or pull you into the discussion. - Thanks.2 points
-
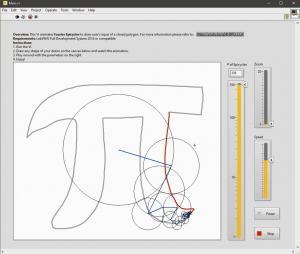
Version 1.0.0
106 downloads
This VI program implements the Discrete Fourier Transform (DFT) to draw any drawn shape outline with epicycles as demonstrated in this video. For more information on the mathematical principles, please watch this video by Mathologer. How to Use: 1.Unzip the attached zip file. 2.Open Main.vi file. 3.Run the VI. 4.Draw a shape. 4.Enjoy animation!1 point -
A programming language exists in any Turing complete environment. Magic:The Gathering has now published enough cards to become Turing complete. You can watch such a computer be executed by a well-formed program. People might not like programming in any given language. That's fine -- every language has its tradeoffs, and the ones we've chosen for G might not be a given person's cup of tea. But to claim G isn't a language is factually false. G has the facility to express all known models of computation. QED.1 point
-
The main difference between LabVIEW and a C compiled file is that the compiled code of each VI is contained in that VI and then the LabVIEW Runtime links together these code junks when it loads the VIs. In C the code junks are per C source file, put into object files, and all those object files are then linked together when building the final LIB, DLL or EXE. Such an executable image still has relocation tables that the loader will have to adjust when the code is loaded into a different memory address than what its prefered memory address was defined to be at link time. But that is a pretty simple step. The LabVIEW runtime linker has to do a bit more of work, that the linker part of the C compiler has mostly already done. For the rest the LabVIEW execution of code is much more like a C compiled executable than any Virtual Machine language like Java or .Net's IL bytecode, as the compiled code in the VIs is fully native machine code. Also the bytecode is by nature address independent defined while machine code while possible to use location independent addresses, usually has some absolute addresses in there. It's very easy to jump to conclusions from looking at a bit of assembly code in the LabVIEW runtime engine but that does not usually mean that those conclusions are correct. In this case the code junks in each VI are real compiled machine code directly targetted for the CPU. In the past this was done through a proprietary compiler engine that created in several stages the final machine code. It already included the seperation where the diagram was first translated into a directed graph that then was optimized in several steps and the final result was then put through a target specific compiler stage that created the actual machine code. This was however done in such a way that it wasn't to easy to switch the target specific compiler stage on the fly initially so that cross compiling wasn't very easy to add when they developed the Real-Time addition to LabVIEW. They eventually improved that with an unified API to the compiler stages so that they could be switched on the fly to allow cross compilation for the real-time targets which eventually appeared in LabVIEW 7. LabVIEW 2009 finally introduced the DFIR (Dataflow Intermediate Representation) by formalizing the directed graph representation further so that more optimizations could be performed on it and it could eventually be used for LabVIEW 2010 as an input to the LLVM (Low-Level Virtual Machine) compiler infrastructure. While this would theoreticaly allow to leave the code in an intermediate language form that only is evaluated on the actual target at runtime, this is not what NI choose to do in LabVIEW for several reason. The LLVM creates fully compiled machine code for the target which is then stored (in the VI for a build executable or if code seperation is not enabled, otherwise in the compile cache). When you load a VI hierarchy into memory all the code junks for each VI are loaded into memory and based on linker information created at compile time and also stored in the VI, the linker in the LabVIEW runtime makes several modifications to the code junk to make it executable at the location it is loaded and calling into the correct other code junks that each VI consists of. This is indeed a bit more than what the PE loader in Windows needs to do when loading an EXE or DLL, but it isn't really very much different. The only real difference is that the linking of the COFF object modules into one bigger image has already been done by the C compiler when compiling the executable image and that LabVIEW isn't really using COFF or OMF to store its executables as it does all the loading and linking of the compiled code itself and doesn't need to rely on an OS specific binary image loader.1 point