Leaderboard



Popular Content
Showing content with the highest reputation on 02/16/2022 in all areas
-
I skirted the edge of what I'm allowed to say in my last statement. I'm obviously not at liberty to share any numbers, nor can I speak officially for NI on that front, but I personally had no qualms about returning to the LV team based on the data I've seen, at least for now. The future is not as bright as I'd like, but it's good enough for me to keep working. The decline on LAVA is worrisome. I've also noticed the reduction. It might be indicative that all of our new user growth is in experienced groups buying more seats for legacy systems without onboarding more new hires. I worry about that. But there's several other factors that could explain it also: The annual refresh of users from NIWeek/NIConnect has not happened for two years. The forums on ni.com are significantly improved (not as nice as LAVA in my opinion, but good enough to not drive people away like they used to). User groups went virtual during pandemic, which means there are now many more places to go for expert input regardless of geography. The number of other support venues has blossomed -- Stack Overflow is now available to LV in a way that it wasn't just a couple years ago; internal support groups exist at far more large companies than in the past. And the LV population has diversified into non-English countries. So am I worried about the future? Yes. But do I think we are currently in a bad spot? No.2 points
-
Ahhh well! Yes that was a choice I made at that point. Without a predefined length I have to loop with ever increasing (doubling every time) buffer sizes to try to inflate the string. But each time I try with a longer buffer, the ZLIB decoder will start filling the buffer until it runs out of buffer space. Then I have to increase the space and try again. The comment is actually wrong. It ends up looping 8 times which results in a buffer that will be 256 times as large as the input. That should still work with a buffer that has been compressed with over 99.6% actually! The only thing I could think of is to increase the buffer even more aggressively than 2^(x+1), maybe 4^(x+1)? That would with the current 8 iterations offer an up to 65536 times as big inflated buffer for an input buffer. In each iteration the ZLIB stream decoder will work on more and more bytes and then if it is to small, all will be thrown away and started over again. A real performance intense operation and I also do not want to loop indefinitely, as there is always the chance that corrupted bits in the stream might throw the decoder off in a way that it never will terminate and then your application will be looping until it runs eventually out of memory which is a pretty hard crash in LabVIEW. So if you know that your data is going to be very compressible, you have to do your own calculation and specify a starting buffer size that is big enough. If you do this over network I would anyhow recommend to prepend the uncompressed size to the stream. That really will help to not destroy the performance gain that you tried to achieve with the ZLIB compression in the first place.1 point
-
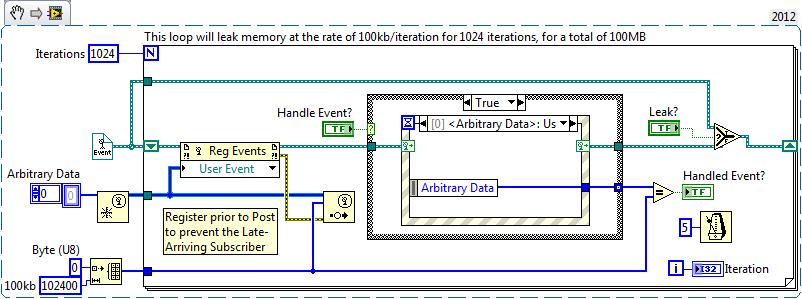
Glad you found the source of the problem! Just to dive in and explore further to this statement above -- it's perfectly acceptable to register inside the loop prior to binding the registration to the Event Handler Structure -- though perhaps not typical. I'm guessing that the memory leak you found was due to the registration not being shifted in a Shift Register inside the loop code. This would cause a memory leak, since each iteration a new Event Registration Queue is formed. Though, if it's shifted, only one Event Registration is created, and then modified each subsequent iteration. Check out the snippet below, which simulates the difference between shifting and not shifting an event registration. The two Boolean controls -- Leak? and Handle Event? -- allow you to run the example in four modes: Handle Event == TRUE and Leak == FALSE - Though it remains atypical to re-register each iteration, this is the only of the four combinations that does not produce a memory leak. Handle Event == TRUE and Leak == TRUE - This is an interesting scenario that causes a leak of 100kb/iteration, even though the data is consumed (handled). This indicates that Event Registrations, like Queues, maintain a high-water mark as an optimization technique. (Thoric, I'm guessing this unintentional scenario was the bug in your code) Handle Event == FALSE and Leak == FALSE - This scenario might be used to pre-load a work queue, which would then later be bound to a single handler. This technique is useful if the computation-to-memory ratio is high, and time needed to calculate the work to be done is relative quick compared to the amount of time needed to do the work. (I wish that LabVIEW's Event Registration binding to an Event Handler had the same semantics as a Queue, with 1:N capabilities. Then, we could dynamically launch a pool of workers bound to the same work queue, and have the Piranha Brigade munch away at the work in concurrently and asynchronous from each other) Handle Event == FALSE and Leak == TRUE - This scenario is useless and almost certainly a bug, unless the Shift Register was replaced by an Auto-Indexing output, to which the array of registrations were later each bound to handlers. (Though even with the output array of registrations, this technique is not quite as desirable as the Piranha Brigade above, especially when the amount of time to perform each job is variable.)
 1 point
1 point