Leaderboard



Popular Content
Showing content with the highest reputation on 03/29/2011 in all areas
-
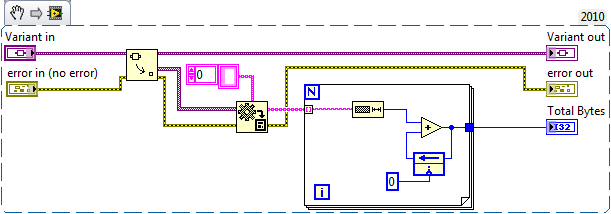
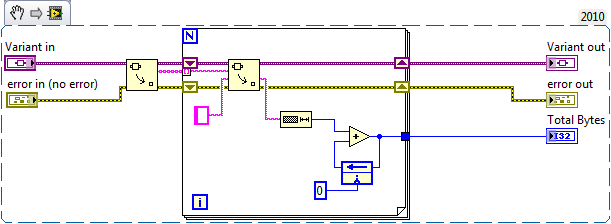
I use variant attributes quite a bit when I have a list of data which is both large (be it element size or number of elements) and dynamic (regularly adding/removing elements). This is ideal if access is primarily random, where I access some arbitrary elements at any given time. From time to time though, I must use sequential access where I need to enumerate every element. There is no native way to index variant attributes, so as far as I can tell we're left with one of two ways to do the enumeration. One: This is a bad way of doing it, as it involves returning an array of all objects as variants, converting it to the proper type, then operating on each element. Memory consumption becomes dominated by the size of data contained in the attributes. When running the VI with 100 MB of data (1000 attributes each 100 kB in size), the VI uses just over 100 MB of memory. Two: This is a much better way of doing it, involving accessing each element individually. Reduces memory consumption since we're not operating on the large values array, the footprint is dominated by the size of the largest element. Running the same case as above shows memory consumption of just over 100 kB. Nice. Turns out it also runs faster than the previous code as well (about 2/3 the time). But there's still a problem here. We're allocating an entire array of names. This can be verified if we redo the tests using large name strings as well. Using the same as above, 1000 attributes each with 100 kB values, but this time each name is also 100 kB in size, the memory footprints change to approximately 200 and 100 MB respectively. That is the second method still requires a lot of memory by virtue of the array of names it must use to operate. While the above situation is largely academic (screw 128-bit GUIDs, I'm going with 819200-bit ones!), it can come into play if your lists are large by virtue of the number of elements (opposed to the size of elements). In this case method "One" might prove the better way of doing it. I guess what I'm really going for is it would be good if there were a way to index variant attributes. YES, I know if you regularly need to enumerate your attributes you're doing it wrong, but there are some uses which you can't get away from. Serialization comes to mind. Any thoughts on this? I'll probably take this over to the idea exchange in a bit, just wanted to seed some discussion first. Attached is some code I played with to get the numbers above. Includes the two snippet VIs above, and a third one which generates variants for them to operate on. WARNING: running the test with the "Long Names" method continuously while collecting metrics can make the IDE unstable due to memory spikes if the default values are used. Close out your "real" work first! Regards, -michael AttributeEnumeration.zip
 1 point
1 point -
Ignoring heroics and the whole discussion, there seems to be at least one flaw here. In the beginning of the article, he says: His analysis of the soldier's action is based on the second definition, but he does not seem to account for the first definition, i.e. that the soldier jumped on the grenade to save the others because he was concerned for their welfare, despite the certain fatal damage to himself.1 point
-
Ok, I've got another rebuild that installs cleanly (for me anyway) on LV2010 64bit. Unfortunately the Code Repository file uploader is being funny and not letting me upload the file right now. Edit: Code Repository playing ball now. Version updated. Any reports problems installing on LabVIEW 2010 or 2009 happily accepted.1 point