

jgcode
-
Posts
2,397 -
Joined
-
Last visited
-
Days Won
66
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jgcode
-
-
I tried running the open VI ref with only the VI names placing inside the main VI folder- there is no problem in execution.... ...will there be any advantage in terms of memory usage if I use only the VI name for Open VI ref?
Sorry I do not follow 100% - do you mean you are wiring in the VI Name as a String or Path (as you have mentioned folder hierarchy and we are talking dynamic)?
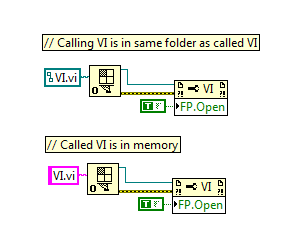
-
Yer, these could be nice to have in OpenG.
*I think* this is the CRC16 I have used in the past.
-
I don't think you are comparing like-with-like there.
I believe I am, because I am comparing robustness which means creating the AE with wrapper VIs for the Methods.
The "lot less code" piccy would equate to a single frame in the AE (or as I usually do, a case statement before the main frames) and would look identical to the class version except it would have the cluster instead of the class blob (without the for loop of course).Yes and no - that image is equivalent to both a AE frame and it's Method Wrapper - as it has the same level of robustness (IMHO), but contains a lot less boilerplate code.
The only difference (in reality) between a class and an AE is that an AE uses case frames to select the operation and a class uses voodoo VIs . An AE will be 1 VI with a load of frames and a typedef to select, whereas a class will be a load of VIs with more VIs to read/write the info and selection will be what object you put on the wire. (Just because you have a wizard to generate them doesn't mean less code). In this respect by wrapping the AE in a poly, you are merely replicating the accessor behaviour (figuratively speaking-in reality you are filtering) of a class and (should) incur the same amount of code writing as writing class accessors. But you will end up with 1 VI with n accessors (for an AE) rather than m VIs with n accessors (for a class).I think you are getting hung up on the fact it has a Class in it?
Like I said this could be e.g. a cluster, the benefits/how-the-framework-works in based solely on the DVR and the IPE (as opposed to a Class).
FWIW here are my stats comparing the two (either one could have a polyVI so that is ignored):
In this example I have the exact same API, where each has the exact same number of Methods (n).
AE/MFVI with n Methods
- 1 x Main VI
- n x Methods VIs
- 1 x Enum TypeDef
- 2n x Method Cluster TypeDefs
- 3 x (Input, Output, Local/State) Cluster TypeDefs
LV2009 Singleton with n Methods
- 1 x Main VI (FGV)
- n x Method VIs
- 1 x State Class/Cluster TypeDef
The LV2009 code is definitely light-weight compared to the AE not only in stats but how it is coded.
Of course all this is all based on my definition of AE robustness - like I said in previous post, you could use an AE with the enum exposed and have either:
- A variant interface
- A cluster interface - CP never changes but you have to do the bundling on the caller's BD
- Or no standard interface - where you could run out of CP inputs/outputs
But all the above means the user does not know what the inputs/outputs are of that method, so they need to have intimate knowledge of the Module's design (plus coupling is higher).
Of course, you don't HAVE to have the accessors for an AE, it's just icing on the cake
And yes, if you coded the module using 1 of these 3 approaches then the stats would be different.
But IMHO I don't think either approach is that robust - so to me it was never icing on the cake, it was how I implemented a Module (AE).
- 1 x Main VI
-
I'd prefer that functional globals (actually any USR) died a slow death.
Try writing a logging function without a singleton.
I have built applications in the past made up entirely of AE's - which I am sure a lot of people did too before they had any OOP options available in LabVIEW - and I am sure they got it to work.
IMHO being able to use the latest techniques is an assumption - are you coding LabVIEW RT on a brick running <=8.6? - I guarantee I will be using an architecture made up of AEs if you want some form of encapsulation.
Nowdays I personally prefer LVOOP based implementations but on a module-to-module basis however, I think everything has it's place and it's up to the developer to decide what is appropriate for what use case.
So as the OP is about robustness I just wanted to post different ways of achieving the implementation of (what I consider) a robust AE.
the "typical" usage of an action engine is to use it as a SINGLETON and that the AE itself IS the API used (have fun scoping that without another abstraction layer.)... ...the only alternative at this point is to make the input/output a variant to get around the octopus connector that results, performing to/from variant.Personally, I have never like the use of variants as the inputs and outputs to a AE as it means the developer has to know what data to supply to what method without any edit time checks. Additionally I do not like using the AE as the API as it means coupling the enum on the BD of the calling VIs - I like using wrappers around the methods (which is a call to the AE with an Enum constant). And then like ShaunR - a polyVI for the API.
Therefore in order to add robustness to the AE I found myself creating a lot of wrapper code. This was worth it IMHO as the code was less coupled, more readable, easier to make changes etc... but the extra work was a PITA and I didn't have any other options at the time.
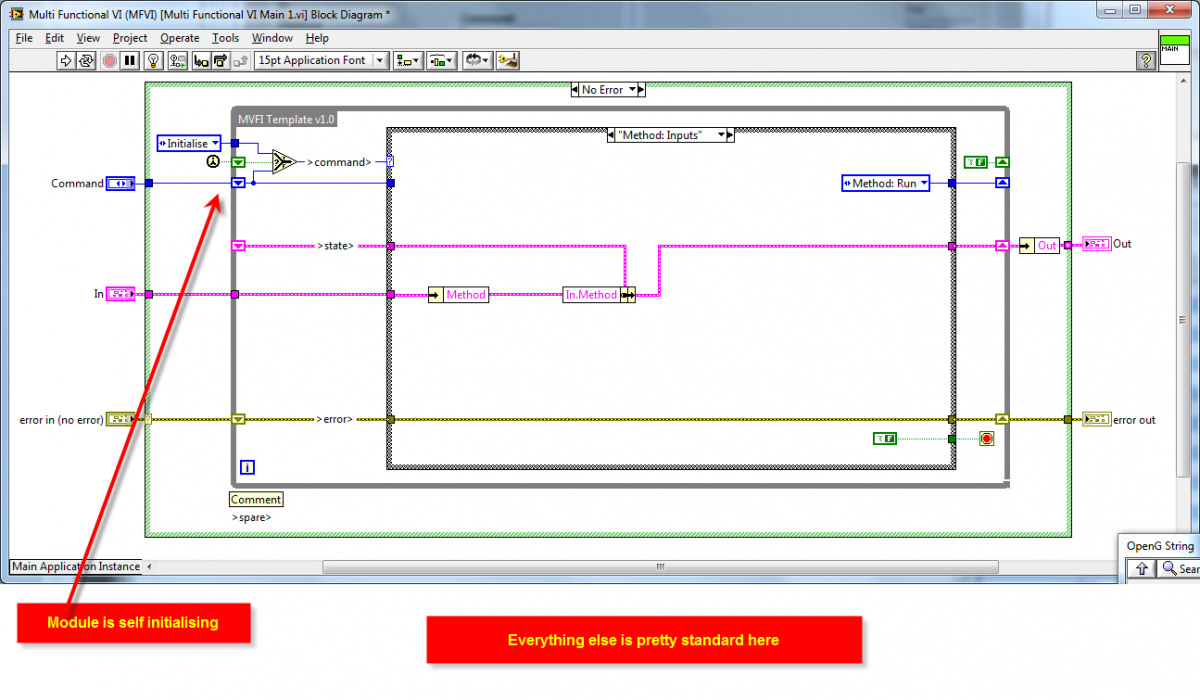
AE/FGV/MFVI/VIG -or whatever you call it (This is how I used to do it)
This example is just a template so there is not much meat to it.
I use the term private below but I never enforced it literally e.g. with a LabVIEW Project Library - it was just a coding convention.
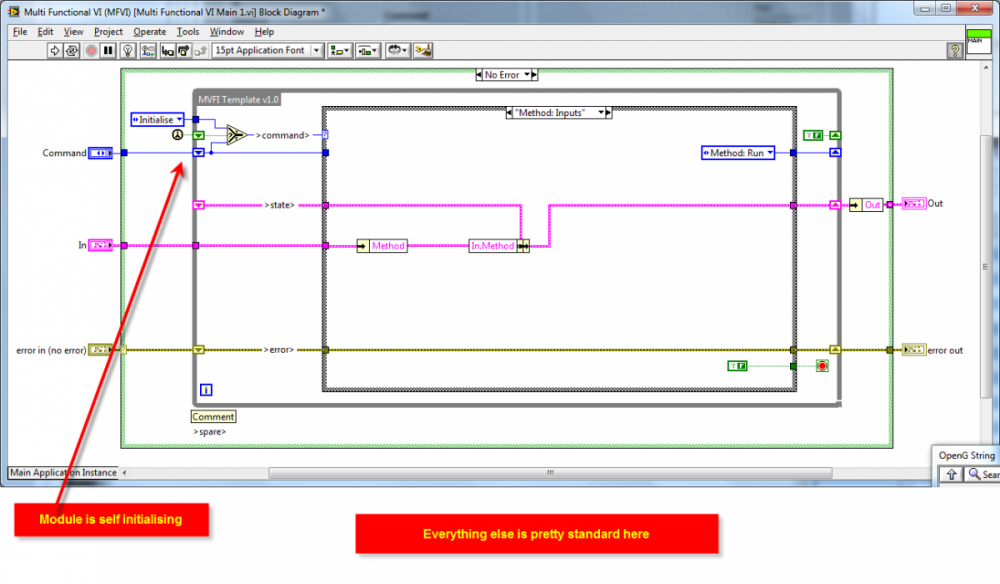
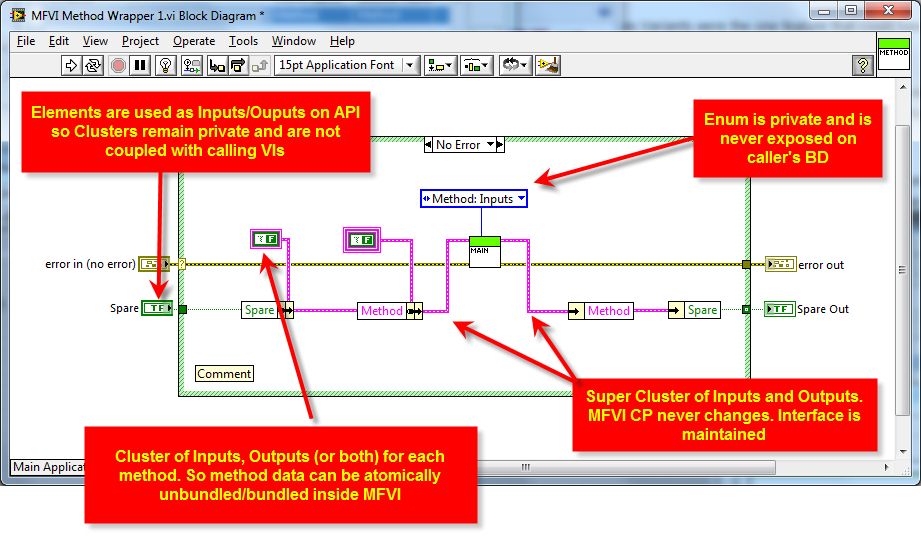
Also an end-user knows exactly what inputs to use for the method they are calling as and inputs can be marked required, recommended, or optional as needed:
I believe this solution is more elegant - it does require LV2009 as it uses DVR's but there is a lot less code.
LV2009 Singleton (This is how I saw AQ do it)
This uses a Class in this example - but it doesn't have to be (I just prefer it).
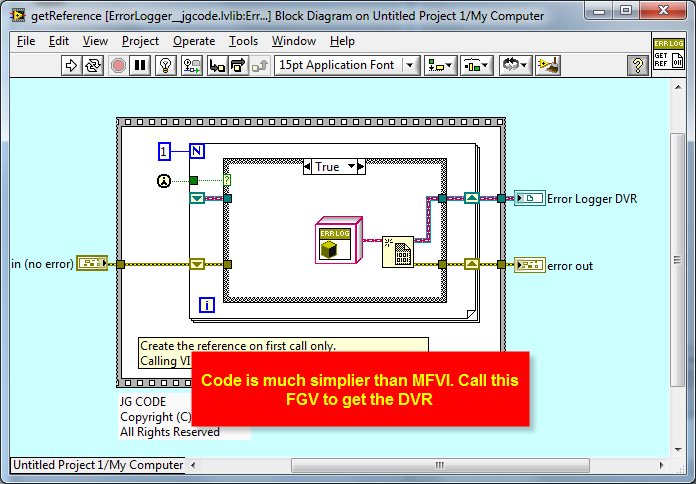
-
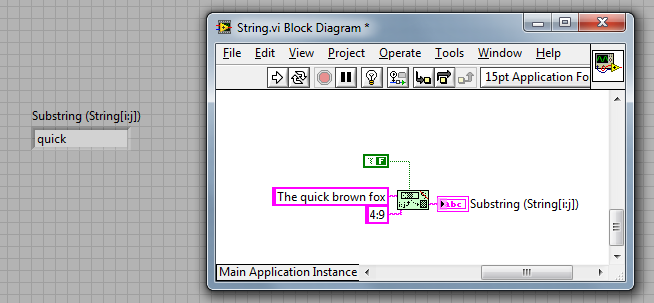
The slice string should in my opinion by revised. Currently it is not doing as the name implies it thus. Because it only fetches the subset of a string, which can already be done by the "string subset" function in LabVIEW, the only thing it really does is calculating the length. Because one gives 2 indices, i:j, then length is j-i.
I am unaware of the history of the OpenG Slice String VI (maybe someone else could comment) but you can see from the Context Help that is has Python origins.
Additionally, I know other languages, e.g js, has both a slice and substring function too.
And whilst you are correct that the end result could be obtained using either function (e.g. use either function to get 'BC' from 'ABCD') - each function has it's differences (and preferred use cases). E.g. Slice string accepts negative numbers to index backward from the end of the string etc...
However both work on Strings as opposed to String Arrays (as per your proposal) so (aside from the above) I think it would be better suggesting a new VI as opposed to revising and replacing the existing Slice String VI.
-
Thanks for looking into the code.
No probs
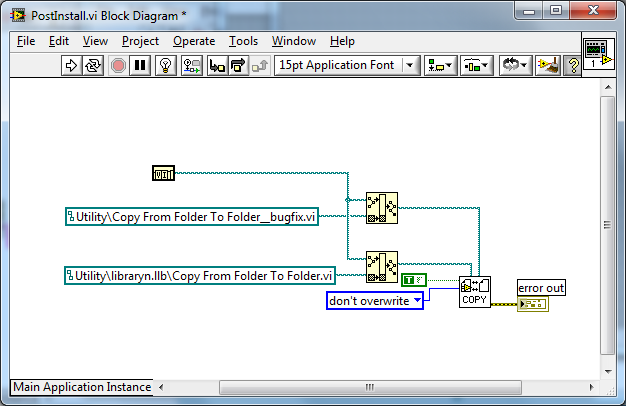
In addition, we all have been installing the OpenG packages the same way -- install/open VIPM, select all of the appropriate packages, and do an en masse install... ...I can well-believe that a "careful" installation of the OpenG packages can successfully install the Librarian patch,What is the definition of careful?
Are you able to install the patch as a single-package install after it has failed in the original-multiple-package install?
If not what happens?
On those systems that I've checked, the "missing file" or 1003 error is also associated with VIPM showing the two bug-fix patches are not installed, and there are some entries in the VIPM "error" Application folder.
Posting these specific errors could be helpful?
I've tried to duplicate the "bug" a few times, but it is in the nature of things that when you are looking for errors, they "run and hide". The best evidence, although indirect at best, that there's a real problem is that (a) I've done a few dozen installations of LabVIEW 7.0 on WinXP systems and have successfully built executables (meaning the missing Librarian file isn't "missing"), (b) since about a year ago I've done several more installs, all following the same pattern, and most (but not all!) of these are missing the Librarian file
Ok. so thinking logically but with limited information I am making the following assumptions based on that
- You are getting errors in the install
- You are missing the VI where it should be
- From what you have said
So it seems logical to conclude that on your failed systems the following is happening:
- The pre install script is renaming the original VI to _buggy
- The post install script is not renaming and moving the patch VI
- The post install script must be generating an error
- This error may report back to VIPM and thus VIPM is stating the package had a failed install
Here is the code from the scripts (its pretty simple code):
Pre-Install Code
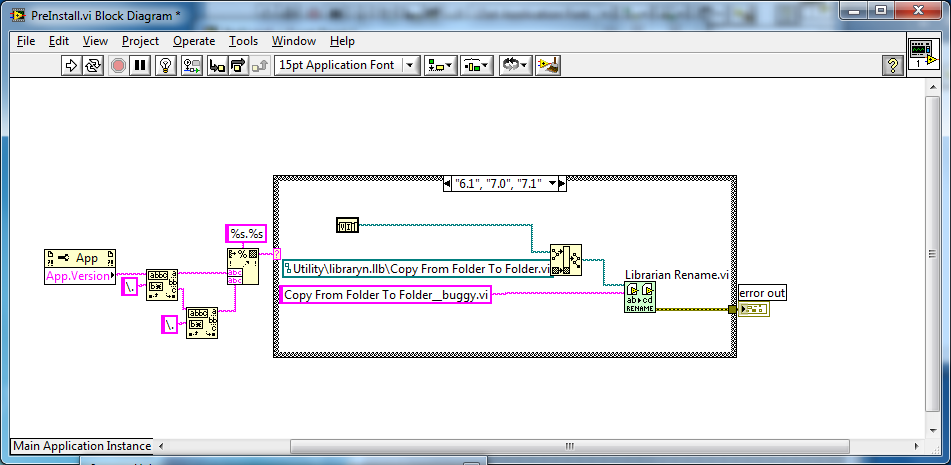
Post-Install Code (I am assuming this is the code failing)
.
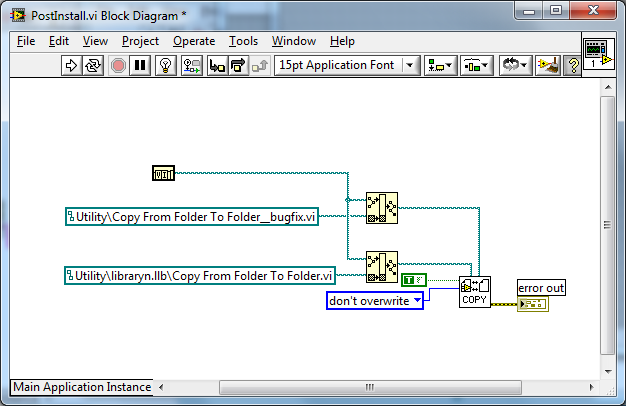
So I was trying to work out what was happening- this would be a good starting point.
Let us know what you find out.
Cheers
-JG
- You are getting errors in the install
-
Jon isn't one of the CCT developers. That would be Ton (mostly) and me.
I could be wrong but I didn't take that as what jcarmody was saying (as in the context of the conversation I would not be the one using the CCT to post a snippet, Wouter would be) - I took it more as eating the LAVA community's dog food.
And yes, I am not a CCT developer - all props to Ton and Yair

-
 1
1
-
-
Danny I am glad you like the work on OpenG, and yes LabVIEW 2011 is very nice
Happy Holidays to everyone on LAVA!!
Thanks to everyone I have worked with, it's been another great year in the LabVIEW Community.
Take care!
-JG
-
I find that proper indention helps a lot in understanding text based code more easily... ...Note: But fighting with the formatting in this editor myself, it's quite possible that your original formatting was in fact more clean than what the post finally showed. Automatic coercion to 8 character tab indention is quite a bad indention format.
Agreed! Seems something got messed up when I cut and pasted - I was able to edit it easily enough tho.
-
When coding in C I wouldn't either comment code like "lenVariable = strlen(strVariable) // get the length of the string"
This was an interesting point and I had a look at this. Here is the same code in a text-based language:
<script type="text/javascript"> // converts a string into an array, where each character is an element in that array function toCharArray(str) { var numChars = str.length; var charArray = new Array(numChars); for (i=0; i<numChars; i++) { charArray[i] = str.substr(i, 1); } return charArray; } </script>[/CODE]The result?
I find that the code is self-documenting - if I use good variable names.
I have added a description of the what the function does - but to me this is the equivalent of VI documentation (so maybe it should have been copied to the BD).
So the documentation is ok if this is how we convert the LabVIEW code in our heads when we read it.
I guess one thing that is missing is variable names - we specify inputs and outputs nicely in LabVIEW, but maybe labels on the wire should definitely be used in the example.
Note: ToCharArray functionality already exists in js, this was just an example.
[CODE] <script type="text/javascript"> var str="OpenG.org"; var toCharArray = str.split(""); </script>[/CODE] -
You can if you use the Code Capture Tool. Something could be said about eating dog food...
As mentioned above - VIs should be posted, as well as (or opposed) to snippets, for reviews.
Save for Previous would be a better workaround to host the VI.
Snippets are good to view the code in the browser (same as posting an image).
-
This is a very interesting topic thus far, as it has gotten me thinking a lot!
 I think it's a great opportunity to highlight best practices for commenting code.
I think it's a great opportunity to highlight best practices for commenting code.I agree that OpenG should comment code well and lead the LabVIEW Community with best practices.
A lot of the OpenG functions are small and readable, but others aren't or require some background knowledge which should definitely be added.
On average, I haven't seen this level of documentation in OpenG VI's yet (no saying we shouldn't start).
On more than one occasion whilst editing OpenG code, there has been a lack of comments (or no comments) and I have added comments (as I was figuring stuff out and thought it would be handy for the next developer to know).
So in the submission of new VIs, we should really aim to get this correct.
Therefore feedback like this (from anyone) for a VI would be really handy during the review, so it could be discussed before release.
However I think we should focus on entire topic:
Given the current feedback (and other end users please continue) - What should the aim of our documentation be?
I (personally) think the the number one purpose should be to help the reader understand (i.e. read) the code.
I think this means that we need target a certain LabVIEW level of the end user when we do this.
- How low (or high) do we set the benchmark?
- Should we target the lowest common denominator (newbies) and add comments on wires, for loops etc...?
- Or should we be doing this anyway?
- Should we show the names of the functions (primitive label) etc...?
- Do we assume the user will use Context Help if they are unsure about a primitive (or argument(s) to one)?
- Would all this commenting be annoying for the average user and make it harder to follow?
In the past I have been aiming for intermediate end users (like CLDish level) which I assume would be the average user of OpenG.
I.e. I assume they know the function String Length and it's behaviour.
The BD is not the only place for comments, there is also a VI description in this case.
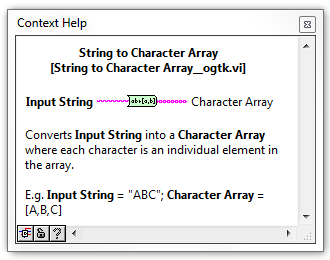
So the VI in question is understandable to me without the suggested documentation and is why I never bought it up as an issue in the review (nor added it at a later date).
However the suggested documentation wouldn't hurt - I just think we should be (or start being) consistent across the entire OpenG Libraries.
If I were to add a comment, it would be that I benchmarked and the simple code turned out the fastest with quick descriptions of the alternative. If I see code like that, I don't question what it is doing, I usually want to know why. If I comment "slightly faster than byte array method", that could save my future self more time than "looping over characters in the input string".
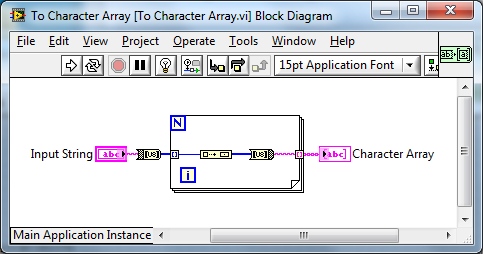
Agreed, that information could be handy in this case e.g. that this implementation was slower:
As a side note: Maybe a link to the review would be good (more work to possibly maintain for the OpenG Developer)? - This is all traceable through it's SoureForge artifact tho.
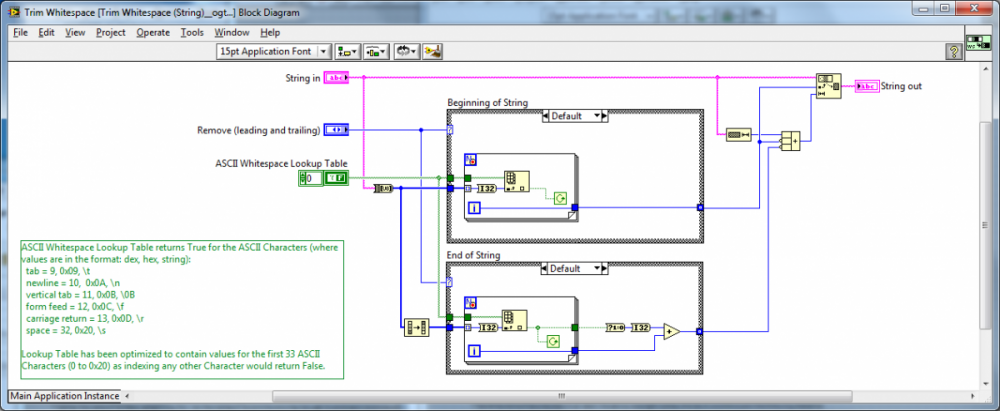
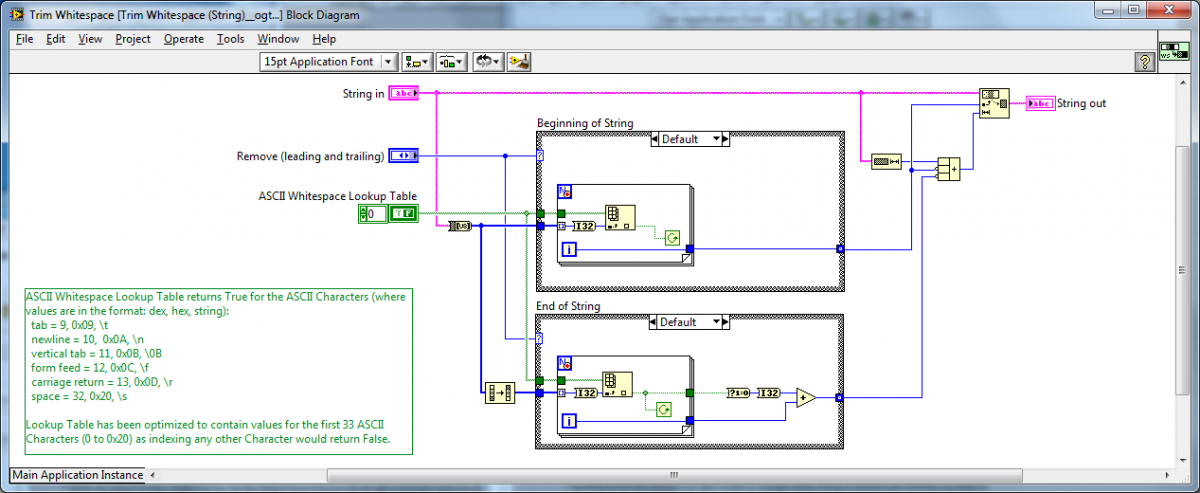
I'd suggest my Trim Whitespace code as needing a few more sticky notes and not this one.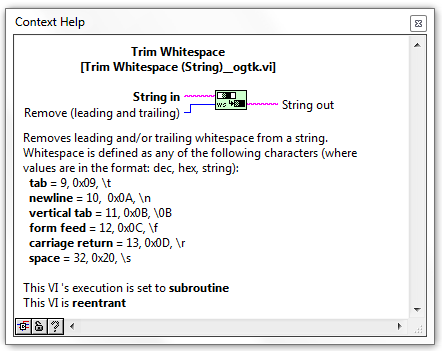
So in re-reviewing this VI based on your comment:
At the time I thought the Trim Whitespace has sufficient documentation as well (I personally added it).
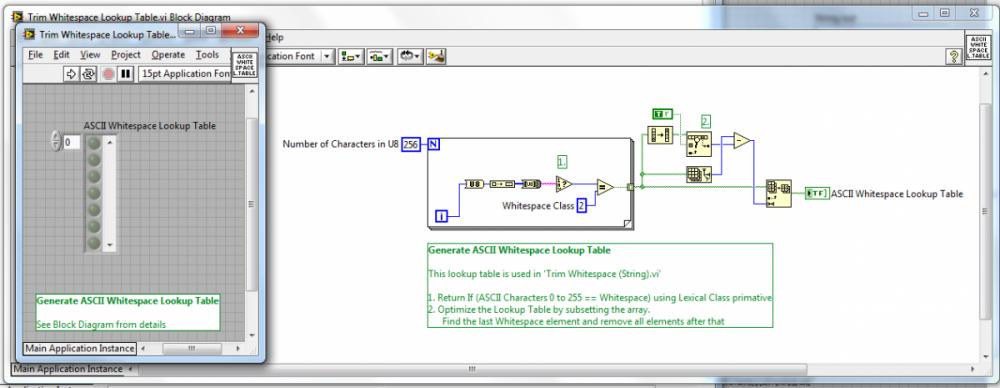
The ASCII table was also programmatically created and is documented (this is more for OpenG developers though and is not included in the released package).
 My usual philosophy is that well-written G is self-documenting, and adding text comments is like writing the letters of the notes on sheet music, unnecessary and redundant. A picture is worth a thousand words, this makes it seem like a picture requires a thousand words.
My usual philosophy is that well-written G is self-documenting, and adding text comments is like writing the letters of the notes on sheet music, unnecessary and redundant. A picture is worth a thousand words, this makes it seem like a picture requires a thousand words.I personally sit slightly on the other side of the fence here - I would prefer a little bit more (clear and concise) documentation, even if it was slightly redundant to the code.
However, given this thread I think it raises another question: How (well) do people read LabVIEW Code?
For me I find that text is always more understandable (and faster to understand) than LabVIEW code.
However, I can quite happily work my way through the code I have posted above and figure out what is happening easily enough.
Is this the same for the average user?
And should e.g. Trim Whitespace have more documentation - I am now thinking yes.
In summary the LabVIEW End User Level we are aiming for and therefore the content/amount of the documentation should definitely be identified, reviewed and standardised for OpenG practices (along with the assumptions we make about everything).
This thread is a great place to do that.

- How low (or high) do we set the benchmark?
-
Given that the OpenG standard is LV9, we should be posting VIs and snippets in that version. It is important to optimize for that version as well.
Yes, please post in LabVIEW 2009 (however, I understand that you may not be able to)
It's just going to make the reviewing process more difficult.
Additionally proposals should be VIs not snippets.
Cheers
-JG
-
-
Hi Bob
I don't have LabVIEW 7.0 installed but I just downloaded the packages from SF and had a look at for you.
I ran all the Librarian Patch pre/post un/install scripts (I just had to modify one case statement to install in LabVIEW 2009) and it all worked correctly.
Additionally I checked the Notifier package and neither the spec nor the scripts interact with the Librarian destination - so I don't think this would be an issue (unless there was an error passed along during a multiple package install - but I don't think VIPM works like that?)
Seems weird you are missing this Vi across multiple installs you have tested (I was initially thinking some folder/write permissions issues)?
My recommendation is that you unzip the package and try a manual install - move the "bugix" file to its installed folder, run each script in order and see if it reports any errors etc... this is what I just did above. That may shed some light on your issues.
Look forward to hearing what you uncover.
Cheers
-Jon
<edit>
I have left extensive documentation of this issue on the JKI Support Site.Can you provide a cross link for this post?
I could not find it by searching your topics in the JKI forums.
-
This is obviously an IPB thing - not sure if feedback is given by LAVA to Invision Power etc...
But it would be good if you could either:
- Edit tags directly without having to delete the whole tag
- Not having to delete all tags to the right of a tag to edit that tag
- Separate the first tag into it's own textbox so it can be easily edited
The reason being I have a use case where I update the first tag (which is displayed with the Topic Title in the list) as a topic changes (over time) and I have to deleted all tags to edit it, the reenter all other tags. Boo.
Cheers
-Jon
- Edit tags directly without having to delete the whole tag
-
Sometimes I find when I go back in to edit the starting post of a topic, the Use First Tag as Prefix checkbox is unchecked (when it was previously checked).
I think it may be a bug.
Curious to know if anyone else has seen this issue.
-
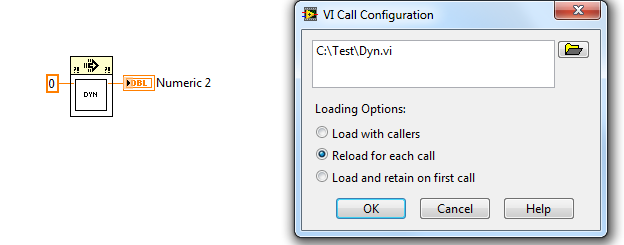
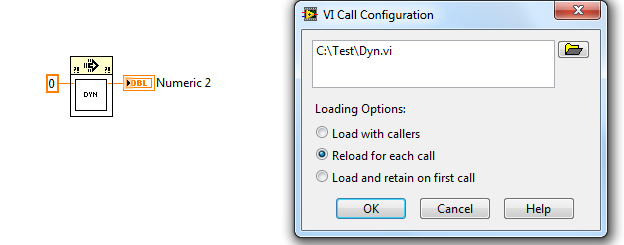
You may also use "Static VI Reference" from Application Control palette. Put it on the diagram, right-click, select Browse for Path, and select VI. Then you can run it with Call by Reference Node and path for this VI doesn't exist explicitly on BD (however it is stored inside "static" node). If you use dynamic calls in such a way, VI is always automatically included into built application. If you break such VI, broken arrow appears also in VI with static reference.
If you want to run it multiple times, it must be reentrant.
My post above was relating to dynamic in the sense of lazy loading.
The Static VI Reference approach will load the VI into memory when the called VI is loaded.
So it really depends on what the OP is trying to achieve.
Using the CBR and specifying a path with an appropriate setting may work?
I have not used this method myself.
I checked and the VI Hierarchy Window shows the called VI when the caller VI is only open (I would have thought it wouldn't?).
Cheers
-JG
<edited>
-
1
-
-
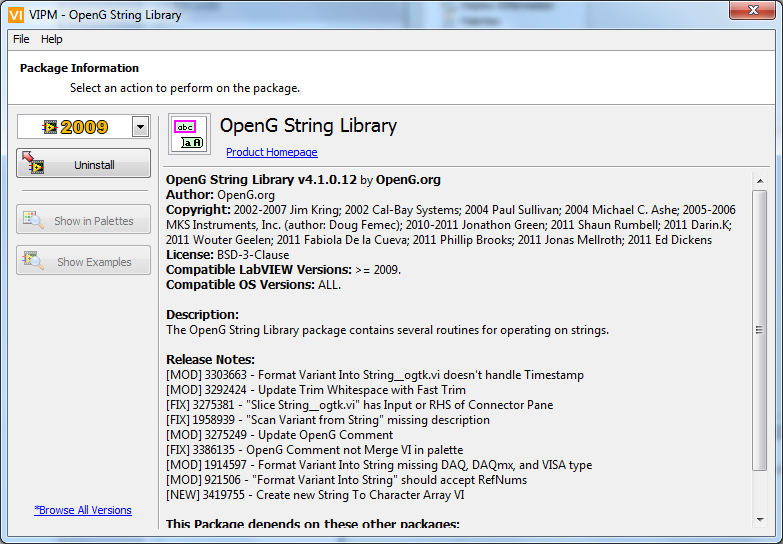
I am very pleased to announce the release of the OpenG String Library 4.1.0.12 package as the features were driven by the LAVA community.
This package will be available for download through VIPM in a few days.
Thanks to Ed Dickens for helping to review changes.
And thank you to everyone who participated in the online discussions.
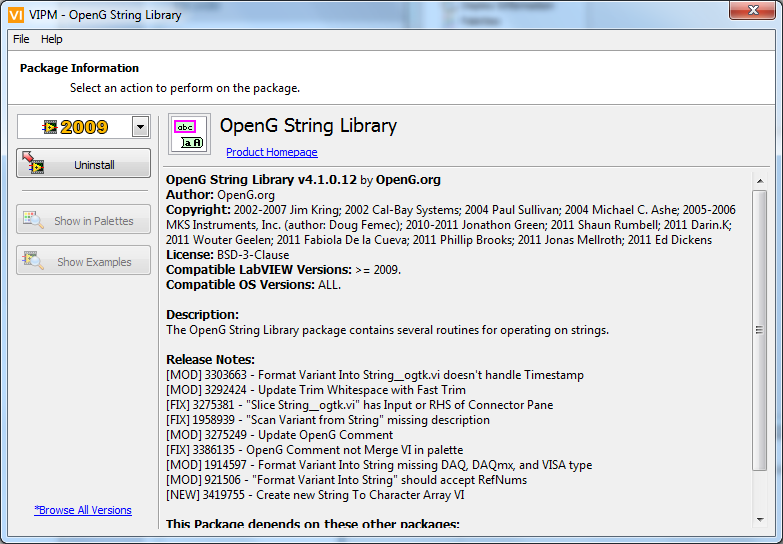
[MOD] 3303663 - Format Variant Into String__ogtk.vi doesn't handle Timestamp
[MOD] 3292424 - Update Trim Whitespace with Fast Trim
[FIX] 3275381 - "Slice String__ogtk.vi" has Input or RHS of Connector Pane
[FIX] 1958939 - "Scan Variant from String" missing description
[MOD] 3275249 - Update OpenG Comment
[FIX] 3386135 - OpenG Comment not Merge VI in palette
[MOD] 1914597 - Format Variant Into String missing DAQ, DAQmx, and VISA type
[MOD] 921506 - "Format Variant Into String" should accept RefNums
[NEW] 3419755 - Create new String To Character Array VI
Below are some of the changes in detail.
New, Faster Trim Whitespace Code
This was the first community review that integrated Shaun R's Fast Trim code which was further optimized by Darin K.
The VI is ~7x faster than the native implementation!
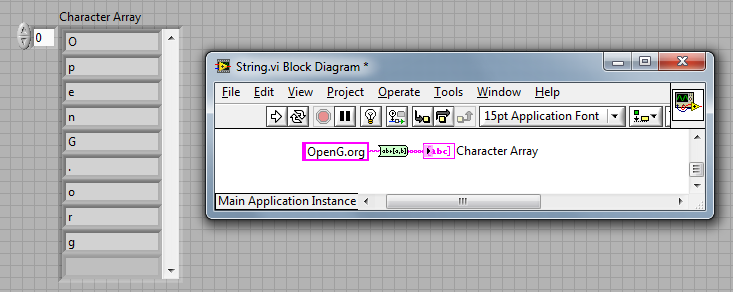
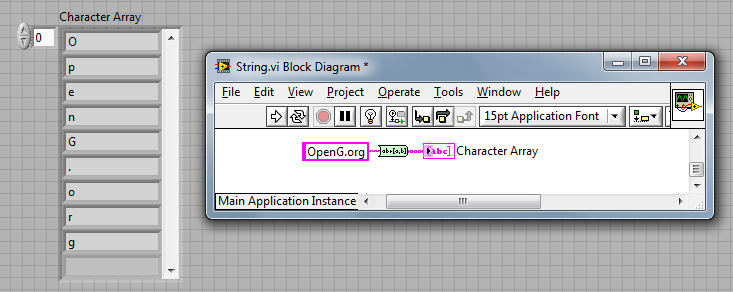
New String To Character Array VI
Wouter proposed this new VI which splits a string into an array where each element is a character.
The code was optimised by Fab and Darin K.
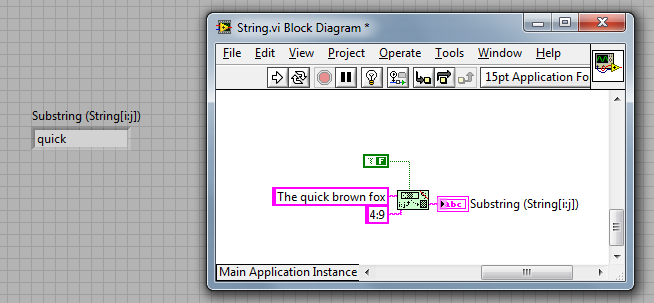
Slice String Connector Pane Fixed
The connector pane for Slice String no longer has an input on the right hand side.
The original VI was deprecated.
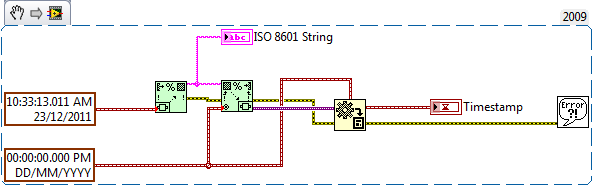
I64, U64, VISA, DAQ, Timestamp Support Added to Format Variant to String and Scan Variant From String
One of the more requested features is that the Timestamp datatype is now supported in these VIs.
ISO 8601 was proposed by Phillip as the default timestamp format however, you can specify any %T type formatting.
Thanks to Mellroth with helping out with the format code.
Once you have installed the new package, download this snippet to test for yourself:
Kind regards
Jonathon Green
OpenG Manager
-
1
-
-
To call a VI dynamically you are going to have to:
- Know where that VI exists in a hierarchy (on disk or inside and .exe)
- Open a reference to it using Open VI Reference and the above path
- At some point, load the VI and run it
Maybe it would be best discussing what you are trying to accomplish with your request?
There may be another way.
- Know where that VI exists in a hierarchy (on disk or inside and .exe)
-
One thing to note is that the company name is 'Openg_org' instead of 'Openg.org'
Hi Ton
This is because of a feature change in the 2011.0.1 release.
I have added feedback here if you are interested.
Cheers
-Jon
-
This window can be called by a CIN code, by using the function
DbgPrintf("Value to debug : %d", value);
Is is very useful to debug CIN functions.
It is defined in the /LabVIEW folder/cintools/extcode.h
Thx - that would explain it
-
No, do you have any extra "debugging keys setup in your LabVIEW.ini file.
Negative.
I was working with some code calling dll's, the only difference was this popped up on my 64-bit OS install but not my 32-bit OS install (both Win7 with 32-bit LabVIEW 2009).
-
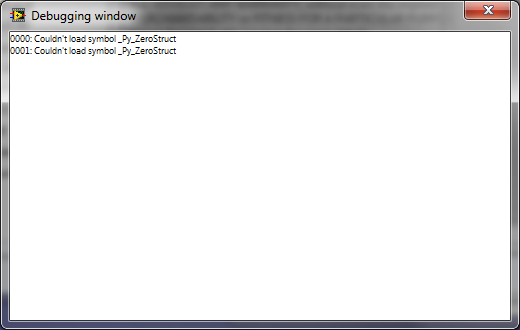
I had never seen this Window before until the other day.
It just popped up, couldn't do much with it - I am guessing it is an internal LabVIEW thing?
Anyone seen it before?


Robustness of Functional Global pattern at large scales?
in Application Design & Architecture
Posted
The class is the state data of the module (in this example!).
This state data is stored in the shift register (in both the AE and the LV2009 Singleton)
But as I mentioned before it does not have to be a class - it could be a cluster.
No different to the state data of the AE could be a class or a cluster.
But it has nothing to do with how the DVR-IPE works - so it can be ignored.
Yes, an AE is a singleton.
But no, I prefer using the DVR because it is less work.
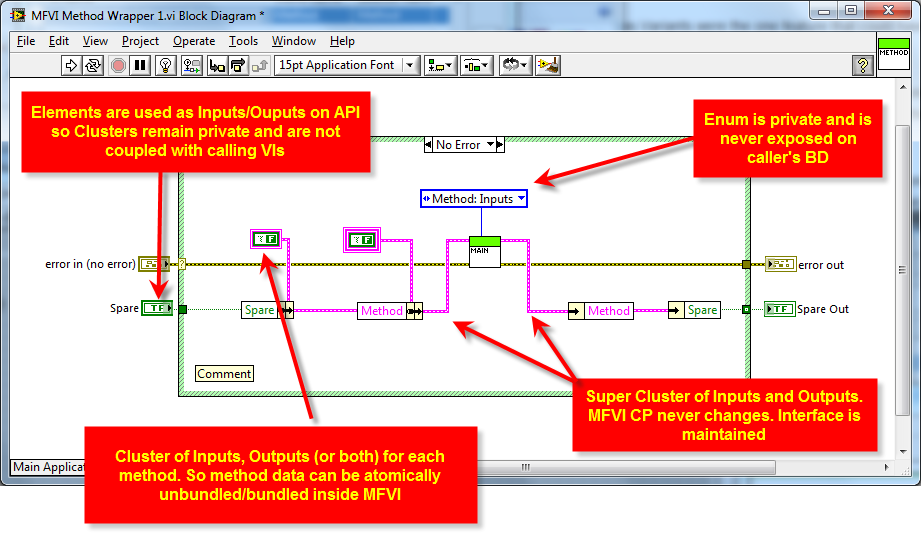
No, the clusters are all private data of the module - no clusters are exposed to the end user.
The reason for having an (input/output) cluster per method (where needed) is so that each method's data is separate from another method.
I.e. you cannot accidentally bundle the wrong data at edit time into another method.
Then in the AE (main VI) you can unbundle that methods data easily.
The input to the AE (main VI) is a super-cluster of the input clusters (and the output to the AE is a super-cluster of the method output clusters) - so the CP of the AE does not ever need to change - it's interface is maintained.
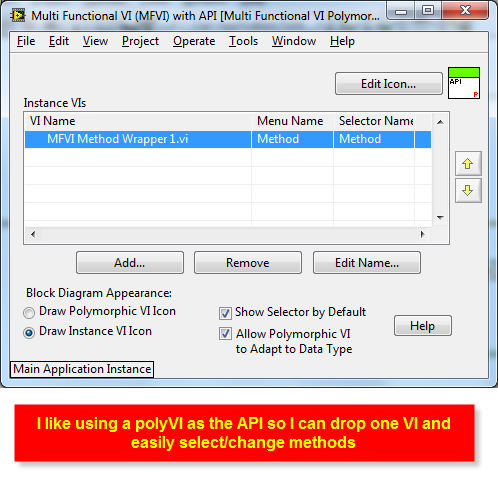
The polyVI is just so you can drop one VI (the polyVI) and select which method you want.
I like to do that when creating APIs.
Both the AE and LV2009 Singleton could do this (that is why I ignored it from the stats).
No, that would violate encapsulation.
No, they are not class accessors - it is DVR based.
But yes, each method is a VI.
Accessing elements from the state data is the same as for the AE (you use unbundle).
If the state data is too complex to manage then it should be broken down e.g. into classes or clusters or whatever - but this doesn't differ between the two implementations.
No I am saying that if I want to create a robust AE I prefer to use the LV2009 Singleton method (or whatever you want to call it).
To an end user, both will have the exact same API, but for the developer there is less code.
Using the DVR with the IPE means that the singleton feature is not broken then rebuilt - it's simply implemented a different way from the get-go.