

jgcode
-
Posts
2,397 -
Joined
-
Last visited
-
Days Won
66
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jgcode
-
-
This OpenG Review is now closed.
This review relates to this thread here regarding support for the Timestamp datatype in the Format to String VI (among others).
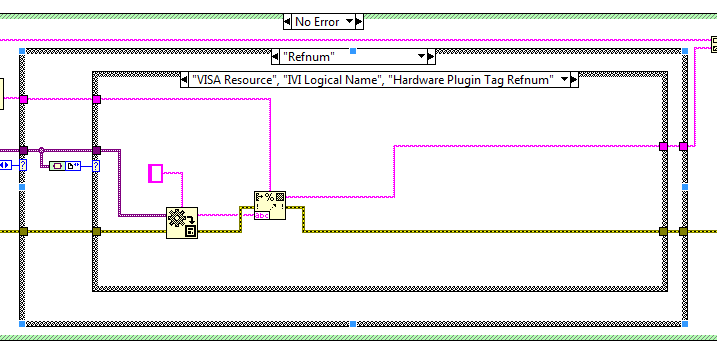
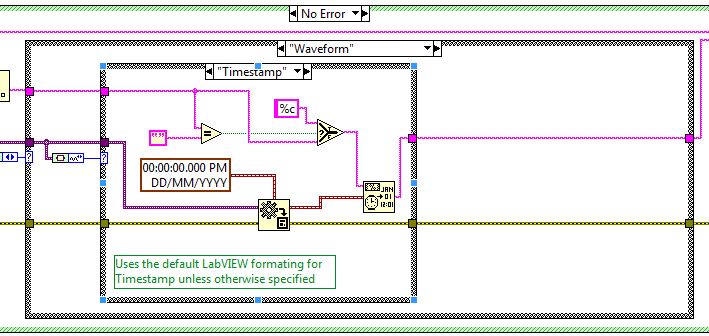
With the release of OpenG LabVIEW Data Library 4.1.0.16 it is now possible to parse Waveform and Refnum datatypes correctly (read about the original ideas here) e.g:
Waveform (Timestamp)

Refnum (VI Server)

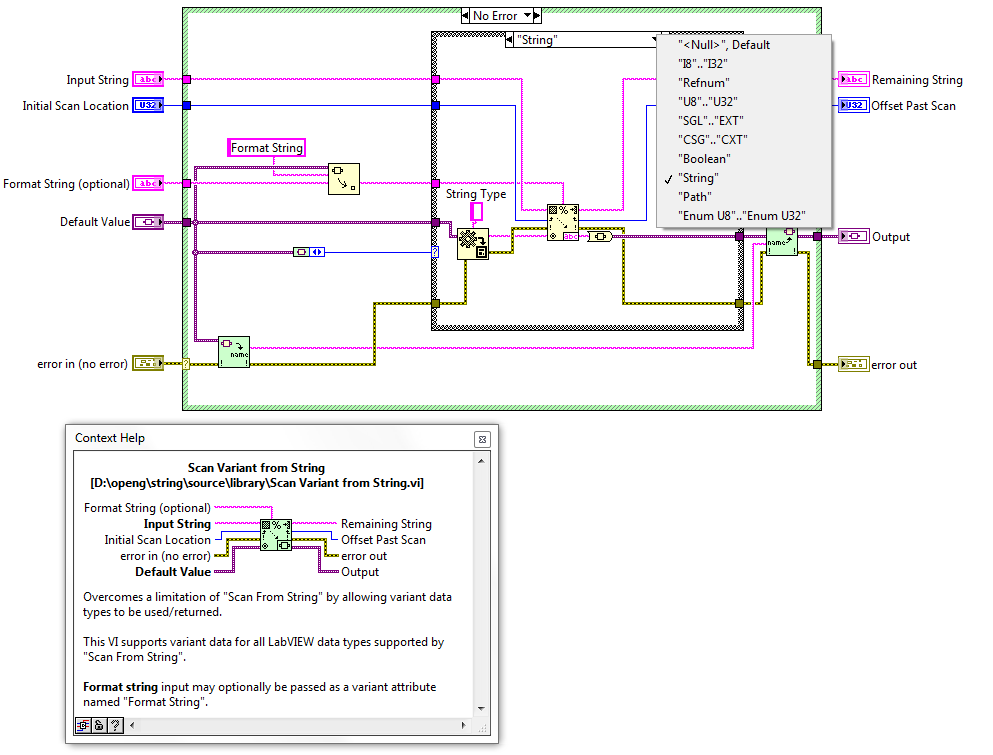
Therefore this review deals with how to modify the Format to String VI and subsequently its complementary VI Scan Variant From String to support Timestamps.
Currently the Format To String VI is in the process of being modified to support:
U64 and I64
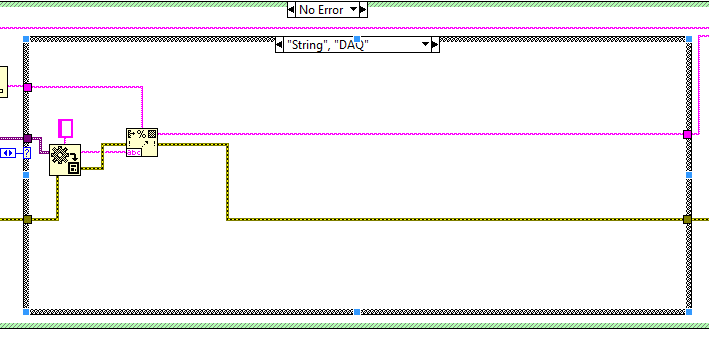
DAQ
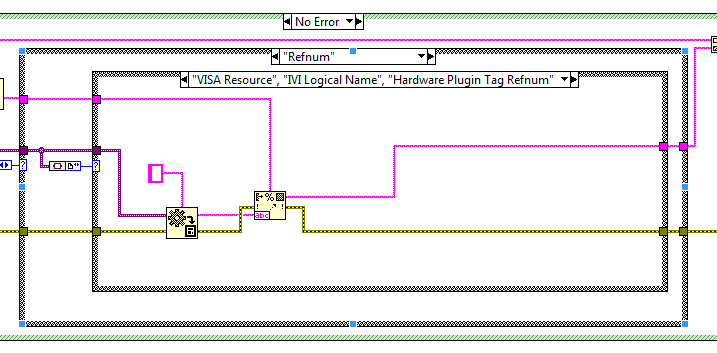
Refnums
Waveforms (example only - to be discussed here in review)
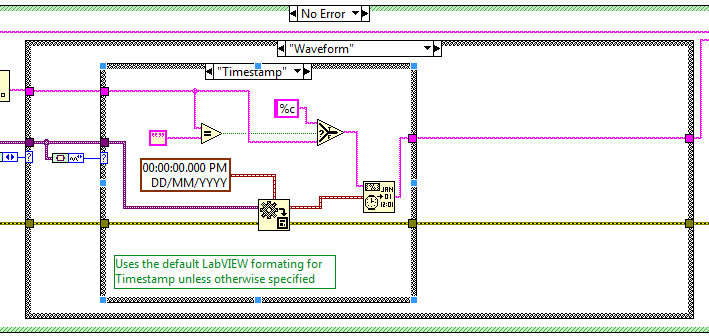
Ideally we would like the same functionality mirrored in Scan Variant From String where possible:
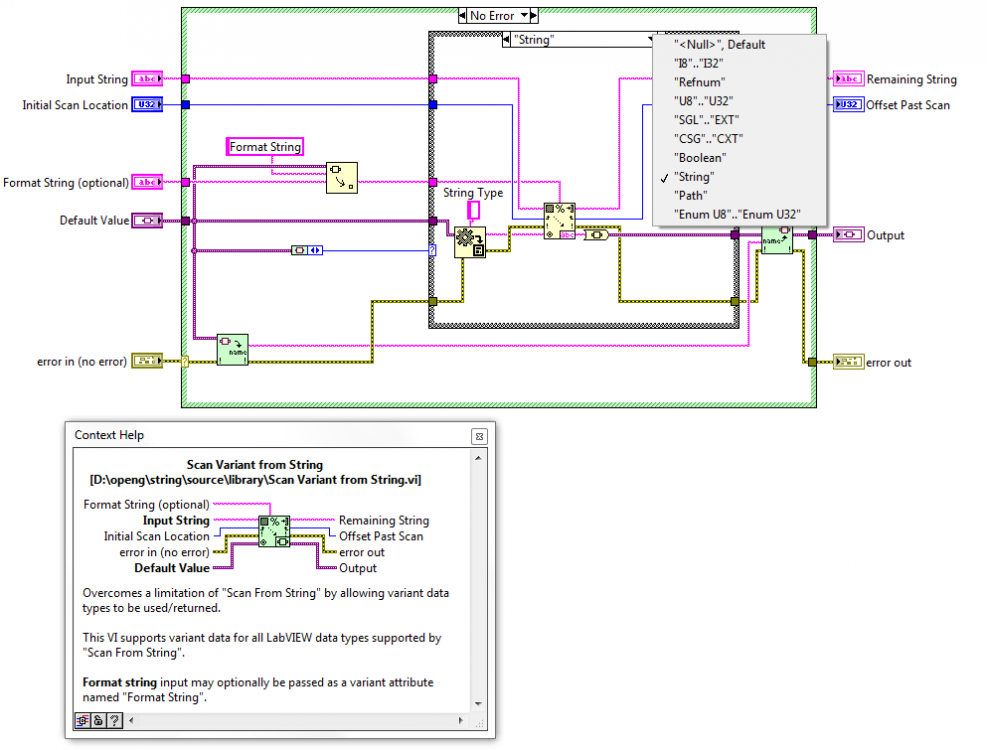
However the issue is that is seems that a Timestamp which has been formatted to a string can only be scanned back using the format specifier %T and must have been formatted using the Format to String and not the Format Date/Time primitive.
But the Format Data/Time primitive is a more readable string and might be preferred i.e. to format a Timestamp to a string with no intention of converting it back.
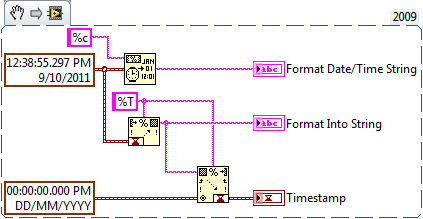
Therefore the main question is: How would you prefer to see this integrated?
- What formats should be supported?
- Should multiple formats be supported so the user can choose which, acknowledging some will not be able to be converted back?
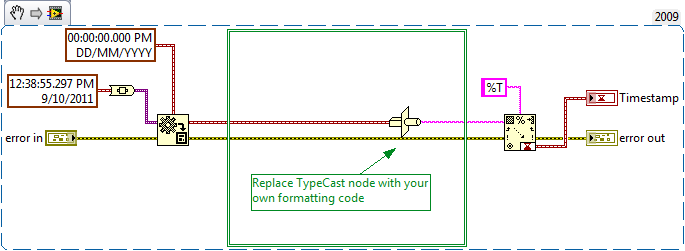
To aid this discussion attached is a code stub (if it helps) to get you started if you want to post code.
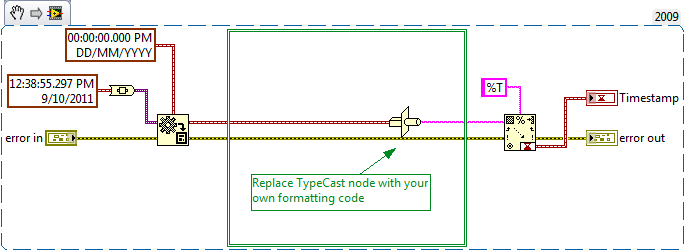
Kind Regards
Jonathon Green
OpenG Manager
- What formats should be supported?
-
I don't see anything wrong with having well-designed icons for OpenG VIs, as long as they all look consistent -- right now I think that the font of "MD5" doesn't really fit with the icon designs of other OpenG VIs.
FWIW, I didn't change that one - it has been there before my time

I just added the Binary and Hex down the bottom.
We can update them in a future release if anyone wants to contribute sexier ones

I was also thinking that if we move to .lvlibs (?) in the future, we could utilise the banner feature in certain situations (Modules/APIs etc...)
-
 1
1
-
-
Mad props to AQ for helping me out with all my LabVIEW Refnum questions on this one :beer:
-
I'm not in love with the current icon, but there really isn't any sexy way of saying "MD5 DIGEST"
Should we call in vugie?

-
Oops, I missed Ton's message too. I'm with Jim on this one, there's a lot of icon real estate that's unused, so I think it makes sense to use the polymorphic instance icons. I don't think it will "cause issues" per se, but it's painless and if it will save some organization grief down the road, why not? WRT DAQmx, typically the icons are already pretty busy, and it would be difficult to convey the multitude of choices adequately in the icon (DAQmx Read, for example). Just my two cents.
I gots no dramas with it given:
- It's not a functional change
- If is the more popular way to go etc...
- That building and releasing packages is so painless in VIPM 2011 I am happy to do it now.
- That is what the fix version number was made for
So I just need the following two questions answered:
- Are you happy with the current VI icons (they are do exist in the released package they are just not shown)?
- Do you want the poly selector on by default still (personally, I don't see the point anymore if we do the above)?
- It's not a functional change
-
Thanks for the feedback Jim.
Place Hexadecimal MD5 instance by default
When the MD5 Message Digest is dropped from the palette, the Binary MD5 instance is placed, since this is the top-most instance of the Poly VI. I'm not sure if this is by design. I expected that Hexadecimal MD5 is more commonly used and that this should be the default instance when dropped.
This was a design decision based on backward compatibility. In polymorhizing the API, anyone's code calling the original MD5 Message Digest (Binary) will not be broken, as it will default to the top of the polymorphic list (Binary) given the connector pane of the two VIs (Binary and Hexadecimal) matches (which is normally not the case).
Its was very important to maintain this with this change (although I agree Hexidecimal will be more popular).
Use Instance VI Icons to distinguish instances
There is currently no difference between the Hexadecimal MD5 and Binary MD5 instance VIs. One can only tell the difference if the Polymorphic VI Selector is visible and many people like to hide that, since it takes up a lot of space. If the Use Instance VI Icons option were enabled and the two instances' icons were different (to reflect the output MD5 encoding), then it would be really helpful.
This was requested in the review that the icons be of polymorphic instance.
Other API's use the selector by default e.g. DAQmx.
You should have chimed in at the review

But if it is causing an issue, it can definitely be changed.
-
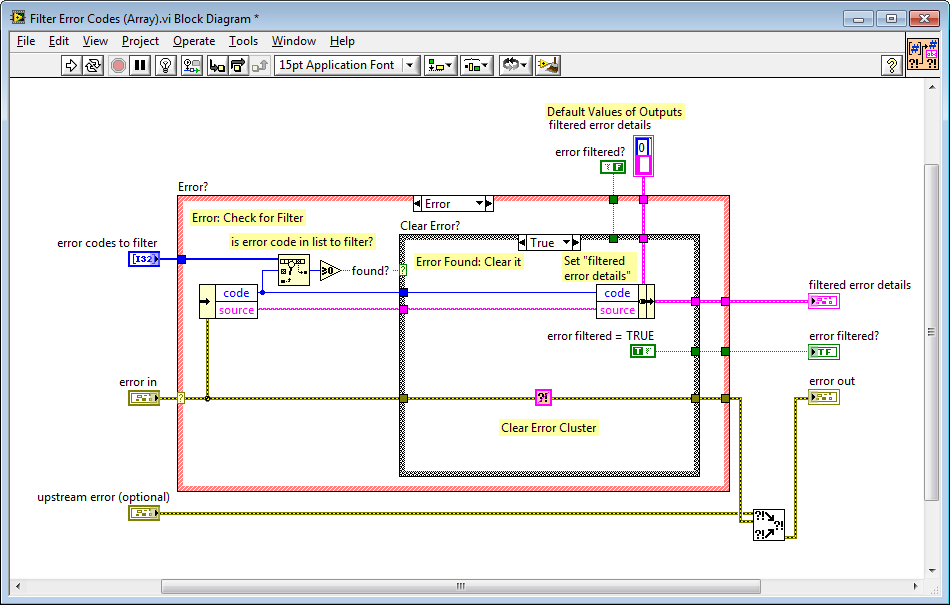
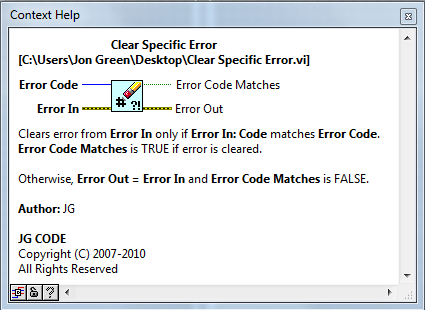
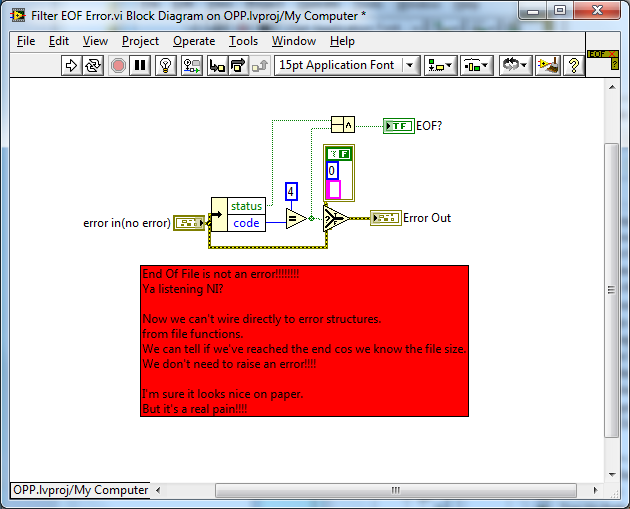
What is exactly the functionality/use of the 'upstream error'?
It e.g. allows you to check for an error from a specific task, handle it (e.g. clear it) whilst persisting error information from previous code (upstream).
Normally I would merge this external to the VI, but I like the fact that the merge is included in the VI (one less thing to do).
-
1
-
-
This package will be available for download through VIPM in a few days and covers some bug fixes, performance updates, and new VIs.
- [FIX] 3386531 - Get Array Element Default Data does not support Timestamp
- [FIX] 3252254 - "Set Variant Name.vi" Kills Attributes
- [FIX] 3386530 - Create new Waveform and Refnum TD subtype VIs
- [FIX] 3386538 - Update Variant Constant to LabVIEW 2009 appearance
- [FIX] 3411109 - Recursive VIs should use native recursion (lvdata)
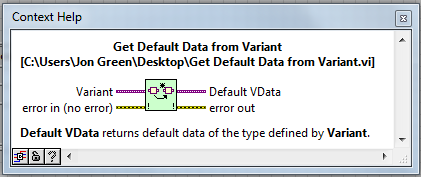
- [FIX] 3411324 - New VI: "Get Default Data from Variant"
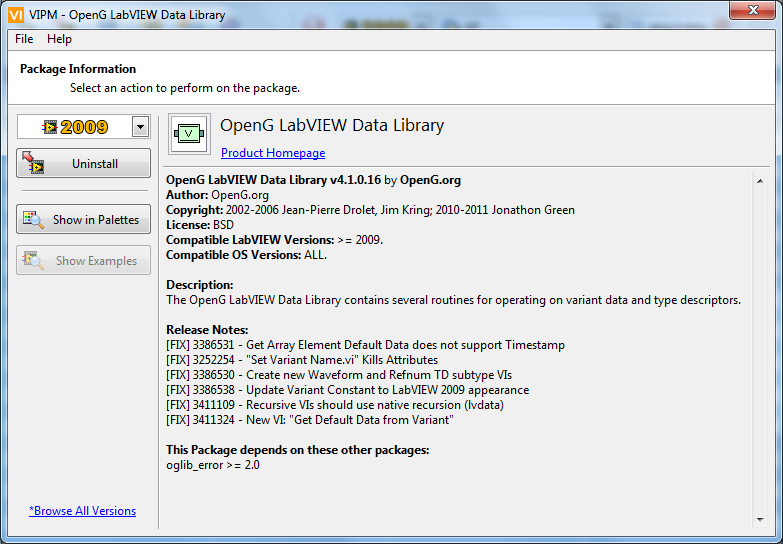
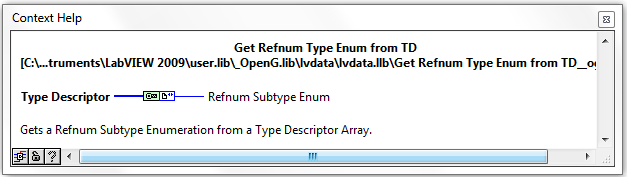
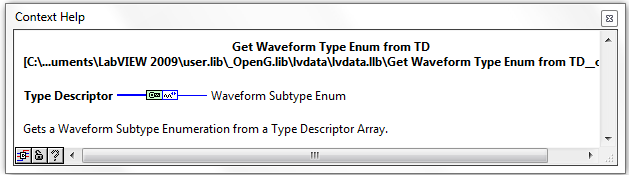
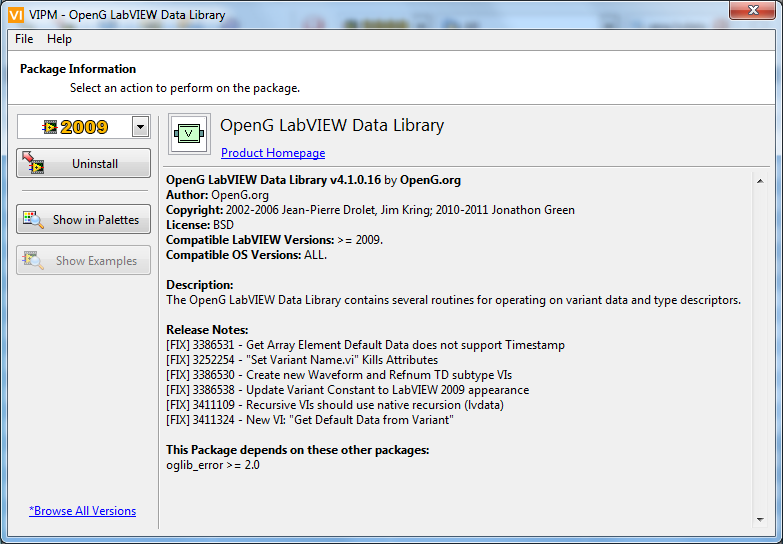
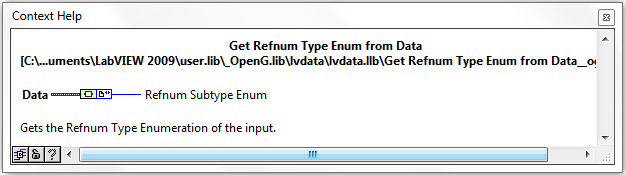
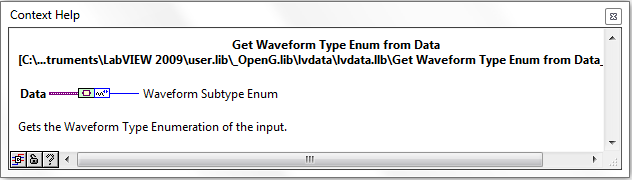
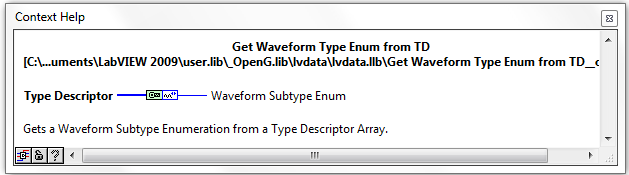
Waveform and Refnum Subtype Enums
There are now new VIs and Enum Controls for determining the sub-type of Waveforms and Refnums datatypes. These VIs were designed by Jim Kring and solve the issue of parsing such datatypes as e.g. Timestamp (Waveform subtype) and VISA (Refnum Datatype). This will allow OpenG support such (sub) datatypes in e.g. Format To String.vi in the near future.

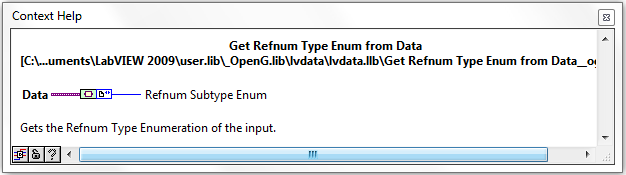
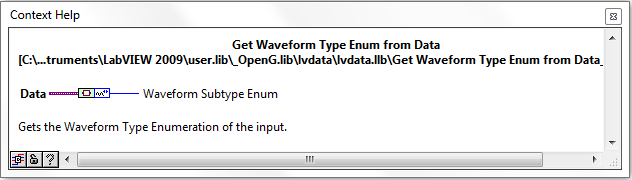
Get Default Data from Variant
This VI forms a thin wrapper around the Get Default Data from TD.vi complementing the Variant API nicely. You can
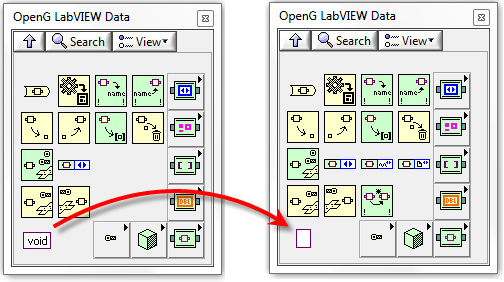
New Variant Constant Image
The Variant Constant image has been updated to be inline with the change made in a previous LabVIEW version both in the palette and on the block diagram.]
There is no functional difference between the two constants.
Here is a Test:
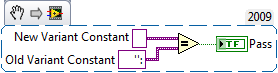
Kind regards
Jonathon Green
OpenG Manager
-
1
- [FIX] 3386531 - Get Array Element Default Data does not support Timestamp
-
This package will be available for download through VIPM in a few days and adds the error constant to the palette for use on the BD.
- [FIX] 3410309 - Add Error Constant to Palette
Kind regards
Jonathon Green
OpenG Manager
-
1
- [FIX] 3410309 - Add Error Constant to Palette
-
This package will be available for download through VIPM in a few days and incorporates a new MD5 Hash? VI and changes to existing MD5 Message Digest.
- [FIX] 3410441 - Add 'MD5 Hash' candidate to package
- [FIX] 3410442 - Add Hexadecimal String output to MD5 Digest
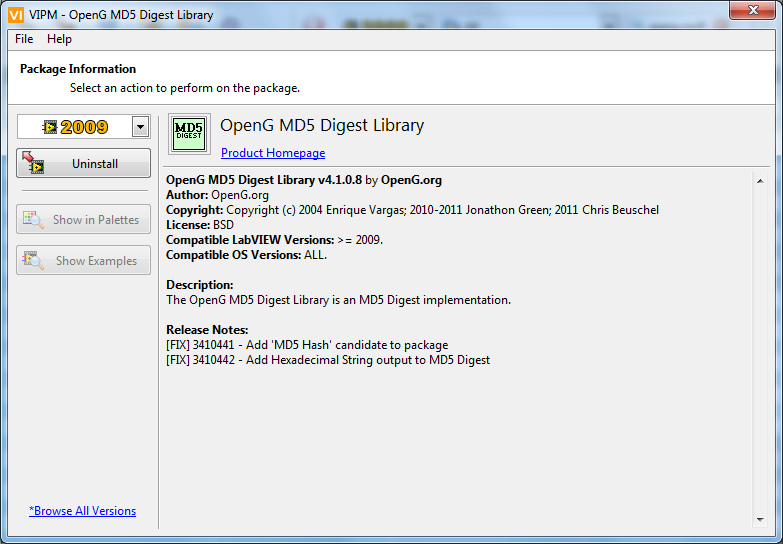
These are the new/updated VIs:

Kind regards
Jonathon Green
OpenG Manager
-
1
- [FIX] 3410441 - Add 'MD5 Hash' candidate to package
-
This package will be available for download through VIPM in a few days and covers a bug fix.
This is the output from buggy code:
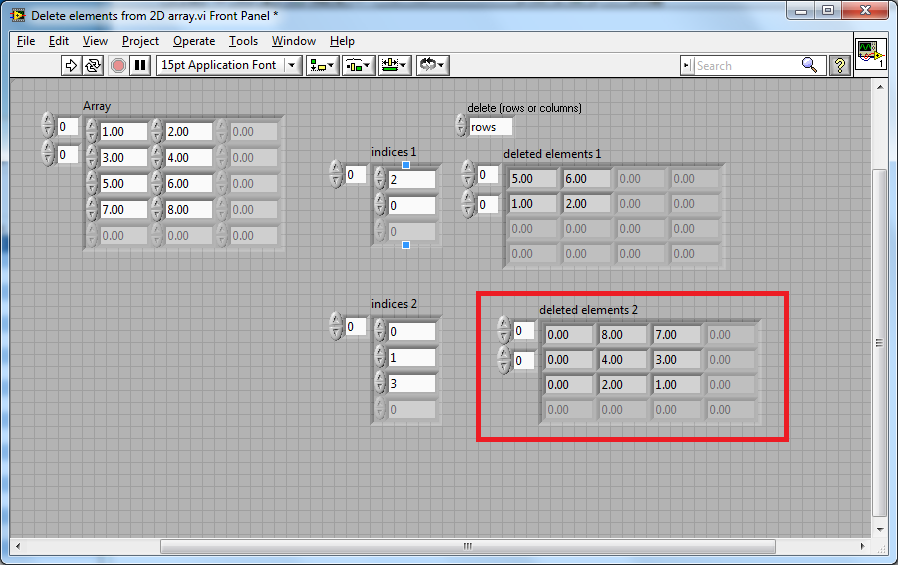
This is the output from the fixed code:
Kind regards
Jonathon Green
OpenG Manager
-
1
-
-
In an effort to support this, JKI has decided to donate (to the community via BSD license) a couple relevant VIs into the mix, in the hope that they might contribute some design inspiration to this discussion:
Awesome - thanks!
Quick design question - why pass out and maintain a new data-type (which is a subset of Error cluster) when an Error cluster could just be passed out?
Cheers!
-JG
-
1
-
-
I have changed this review to pending. If no one has any further comments I will close the review in a few days.
This new VI and change can be tracked here: ID: 3419758
-
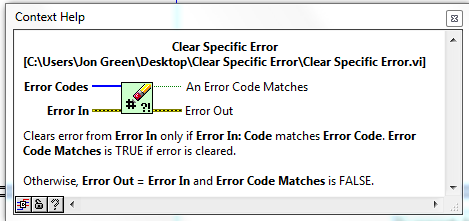
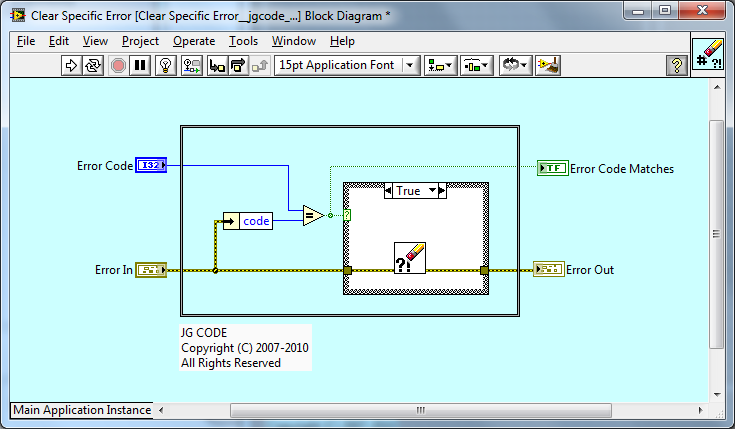
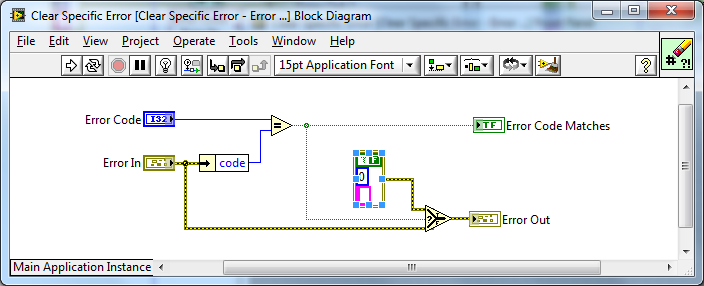
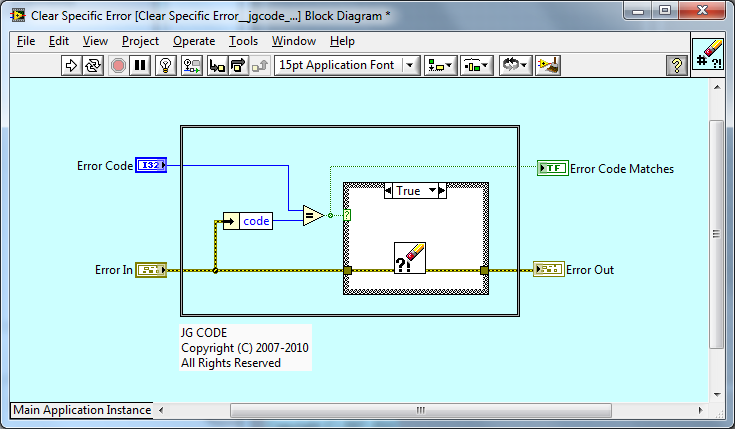
Since this VI is called "Clear Specific Error.vi", it should really be "Error Cleared?".
I agree - I will change Error Code Matches to Error Cleared?.
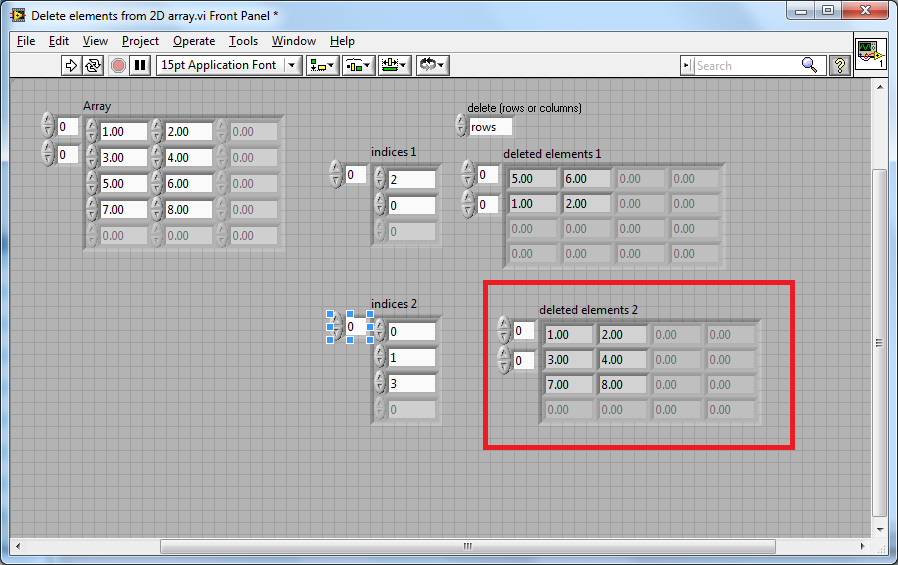
For the error array VIs, would it make more sense for this indicator to be an array so the user can figure out which error was cleared?
The depends - what are your use cases? Are you going need that information to go back through the array and index out that cleared error or make a decision based on that error etc...? Or do you care that an Error was cleared in the Error Array you passed in? That information is there - you could wrap the Core VI in your own For Loop if needed, it guess its a question of what is the main use case.
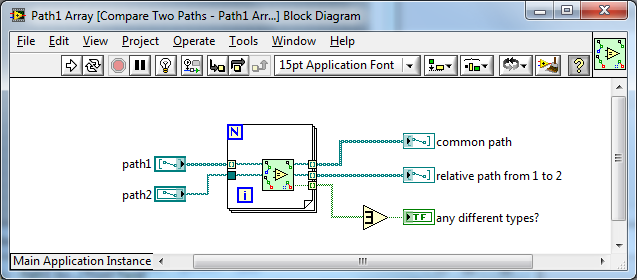
We made a similar design decision for e.g. Compare Two Paths when polymorphizing the API:
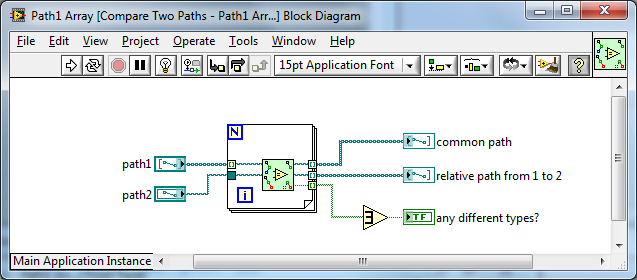
I'm for the smaller icon personally.
I am still not convinced about this given:
- We currently have two inputs and two outputs, and 4x2x2x4 allows for future expand-ability (not a requirement but a nice to have as we have other methods for dealing with this).
- Other Error VIs are of this size (Clear Errors, Merge Errors, Build Error Cluster etc...)
- An inline VI size/shape would still get in the way of the outputs of the Property Nodes anyway (from the above images posted)?
- New users would be familiar with the iconography in the palette as it is similar to Clear Errors etc...
If anyone can provide a list of pros/cons for the smaller icon, please do.
- We currently have two inputs and two outputs, and 4x2x2x4 allows for future expand-ability (not a requirement but a nice to have as we have other methods for dealing with this).
-
I also think the we should polymorphize the API here too for the Error Code input.'
Should we support an array of Errors In too?
This would mean a total of 4 VIs - most likely with the Error In array as a thin wrapper around the above mentioned VIs (no function changes).
I think we all agree on the functionality of the VIs which is good.
The only functionality I am unsure of is this:
I just updated my second implementation from above to add a check for an empty array being passed in. So now all errors will be cleared if the array is empty (which is currently the default). Is this a desired feature to clear all errors?
IMO: If you want to clear all errors then you should use the Clear Errors VI.
If an empty Error Code Array is passed in, then it contains no Error Codes and therefore no Errors should be cleared?
Ok, here is the API I am envisaging...
I have gone with the standard size/shape VI given that other Error VIs are of this size (Clear Errors, Merge Errors, Build Error Cluster etc...)
It seems to me even an inline VI size/shape would still get in the way of the outputs of the Property Nodes anyway?
E.g.

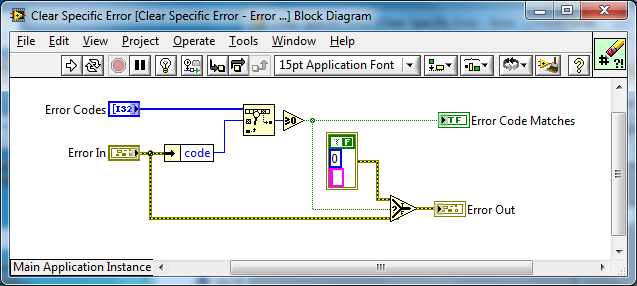
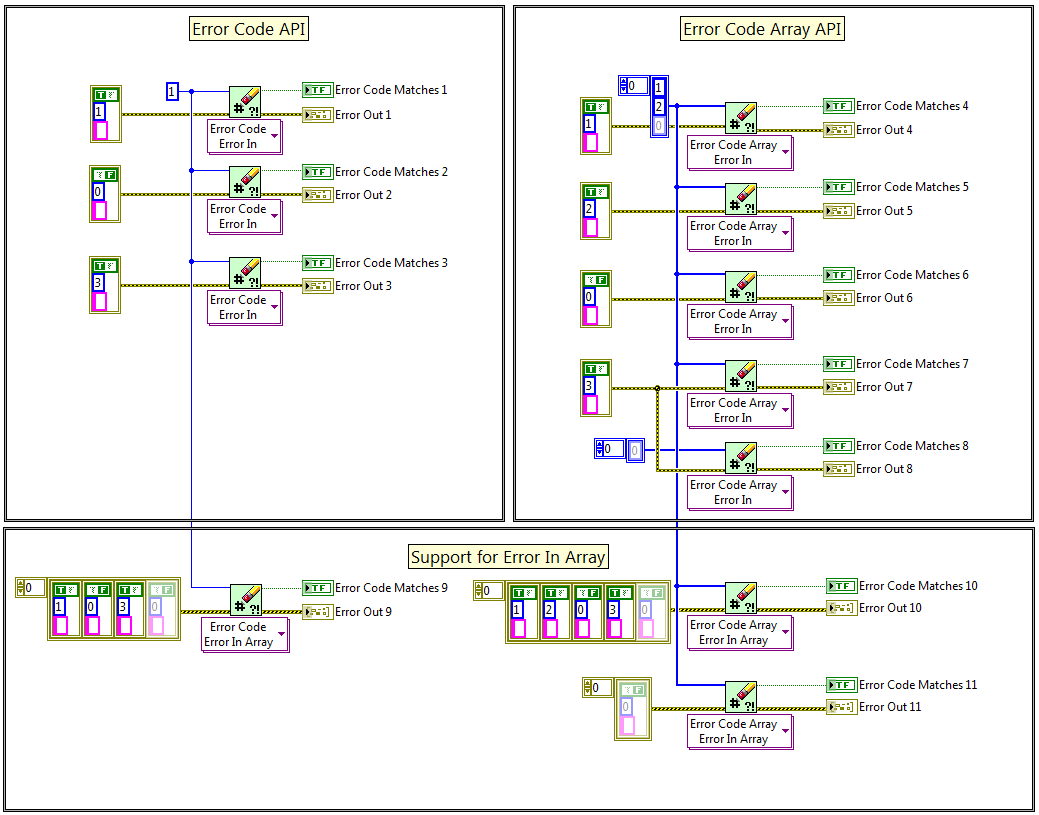
The core VIs:
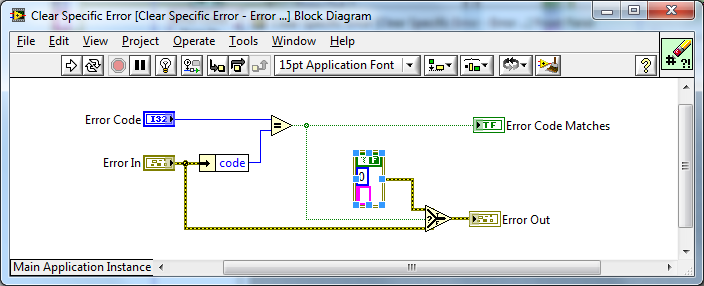
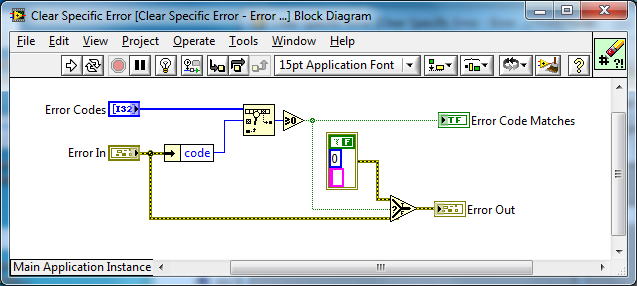
The thin wrappers for Error Array support:
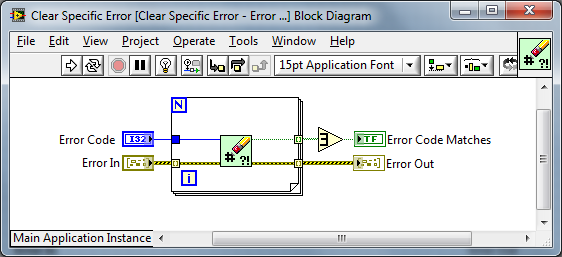
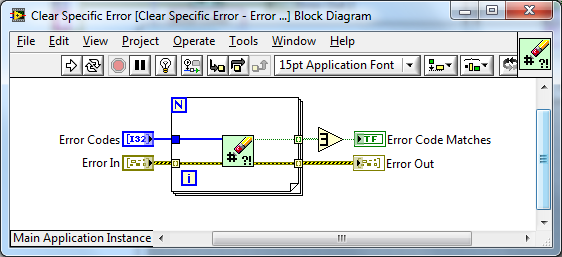
The Polymorphic API:
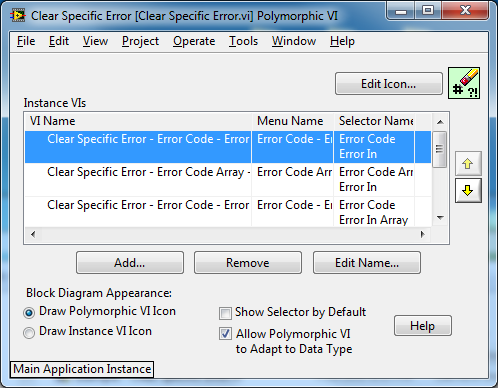
Documentation:
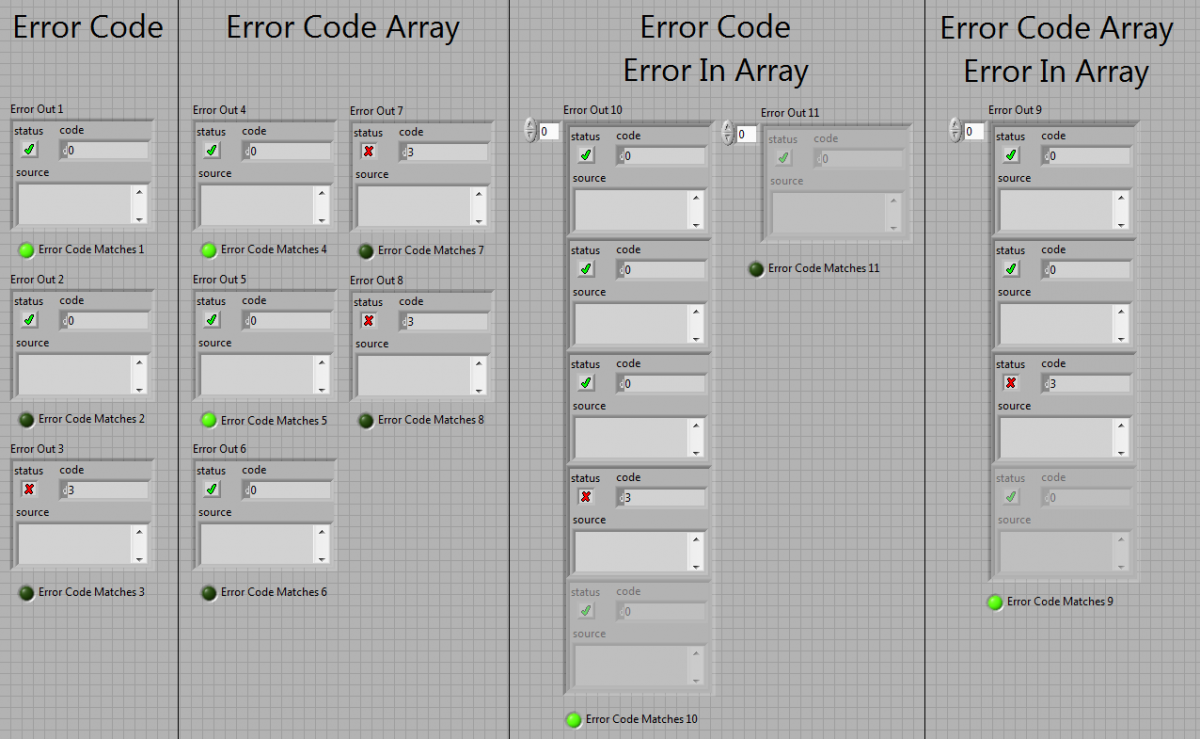
Here are some examples of inputs/outputs of the API:
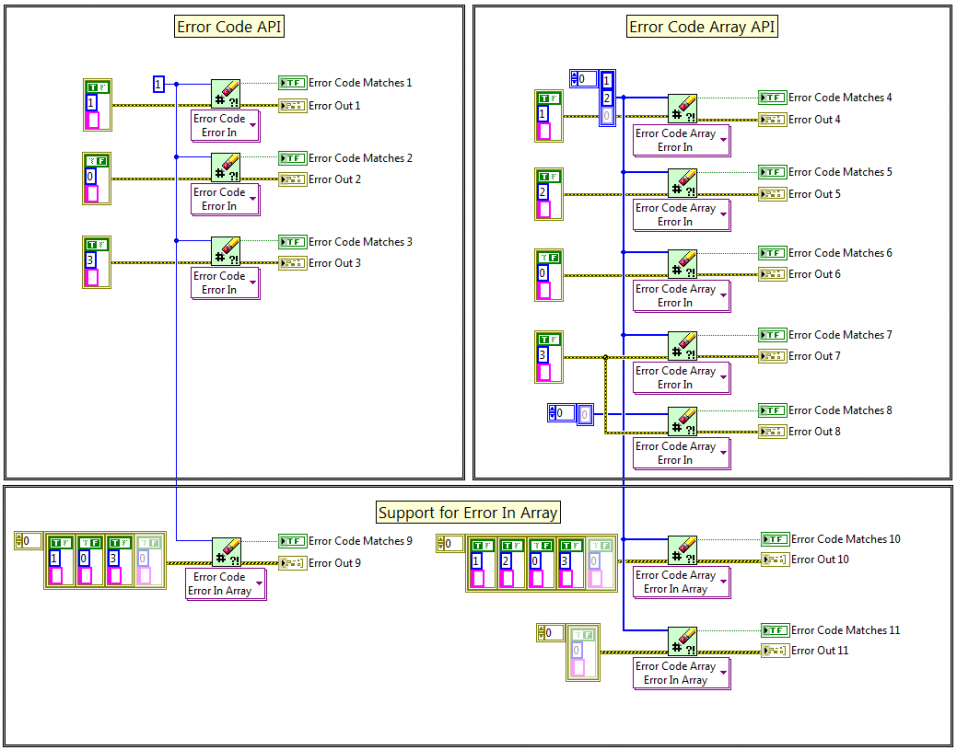
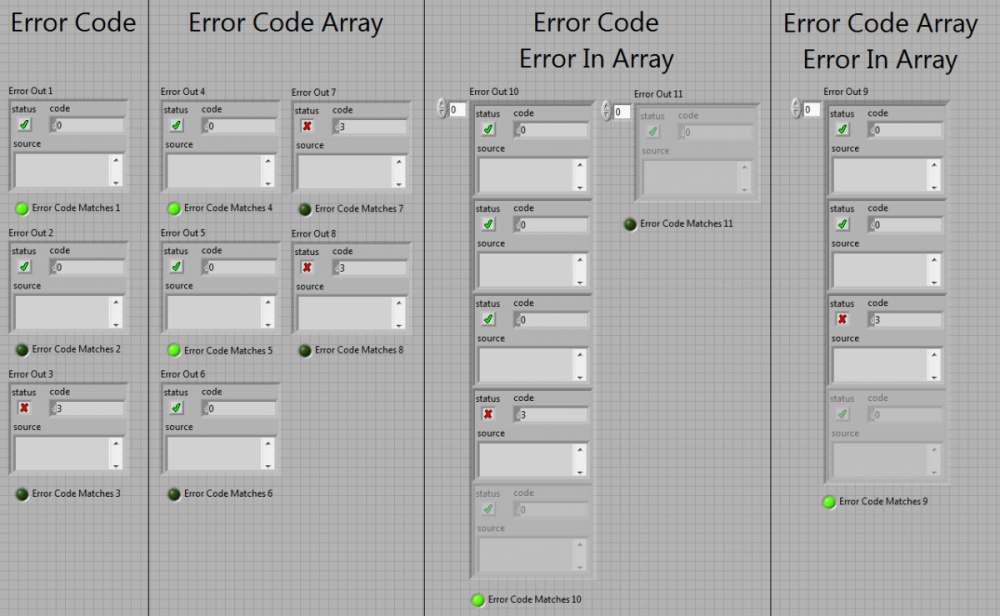
Here are the results:
Code is in LabVIEW 2009
-
1
-
-
You can track the new MD5 Hash VI here: ID: 3410441
You can track changes to the MD5 Message Digested here: ID: 3410442
-
You can track the upgrade for this VI here: ID: 3292424
-
You can track this new VI here: ID: 3419755
-
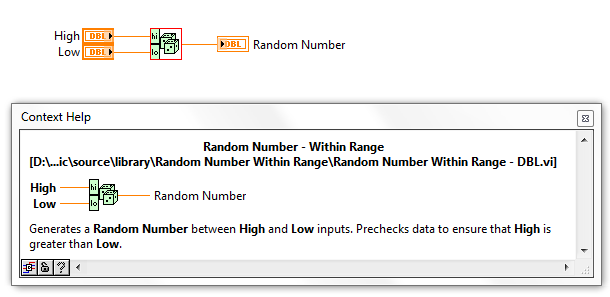
Ok, here is what I have so far:
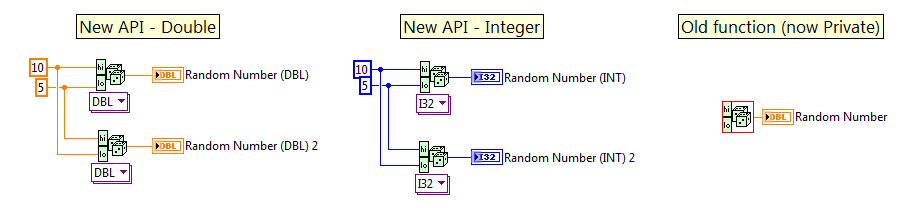
Instead of depreciating the old function, which is still valid and will be used internally to the API, we make it private. Notes:
- A private setting cannot actually be enforced without .lvlib support (a good reason for it) however, the notion is still the same
- I have used a red border to show that the private function is different from the public calls of the API
- The documentation states the private function should not be called, and provides the alternative (i.e. how to upgrade existing code)
- This change in iconography for the private function (whatever it will be) should be standardised by the OpenG Board
- This implementation will not break existing code

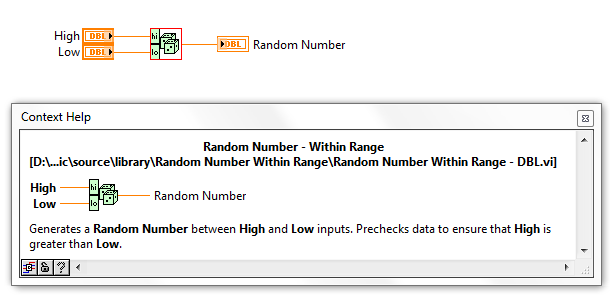
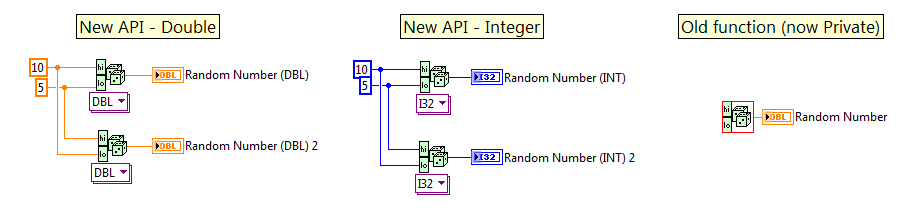
Public Functions were created for Double and I32 which sets the inputs to required. Notes:
- Double does not need to precheck data given the way the original code is implemented, the order of High and Low is irrelevant
- I32 could call the private function directly (functionally equivalent) to optimize the code
----
----

----
Here is an example of what the new and old code:
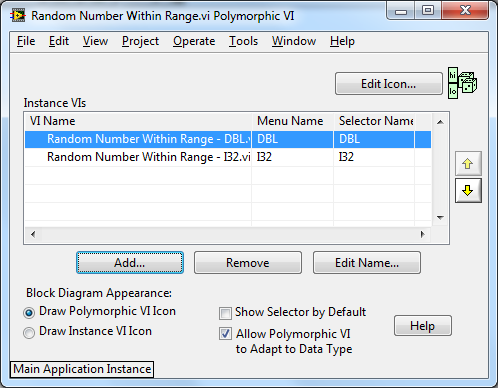
Here are the settings for the Polymorphic VI:
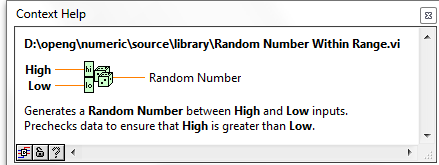
The attached code also contains the I32 Evenly Distributed example from the OpenG Forums (linked to the new code).
Random Number Within Range.zip
Code is in LabVIEW 2009
- A private setting cannot actually be enforced without .lvlib support (a good reason for it) however, the notion is still the same
-
Actually, I can confirm that the basic concept does apply in 2009 and probably in later versions as well...
So how do you hack it then...
-
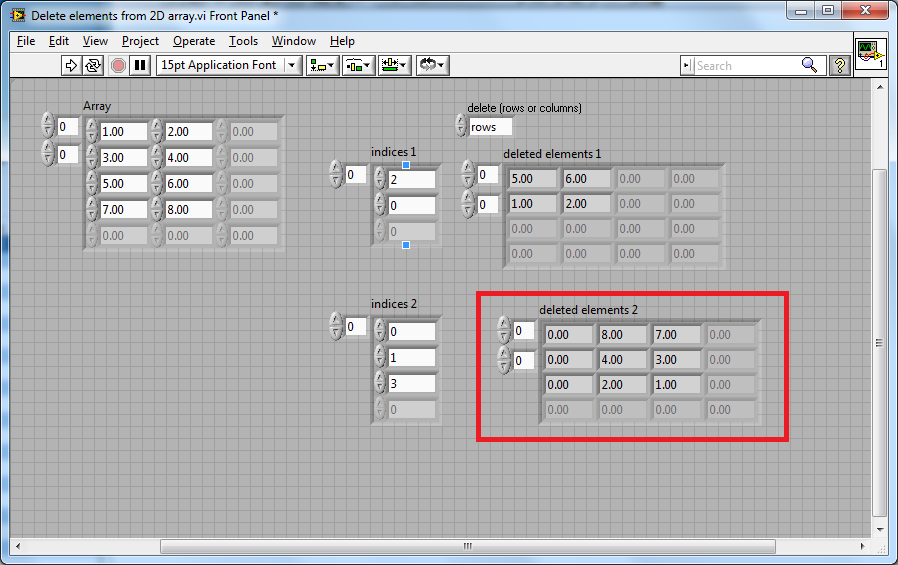
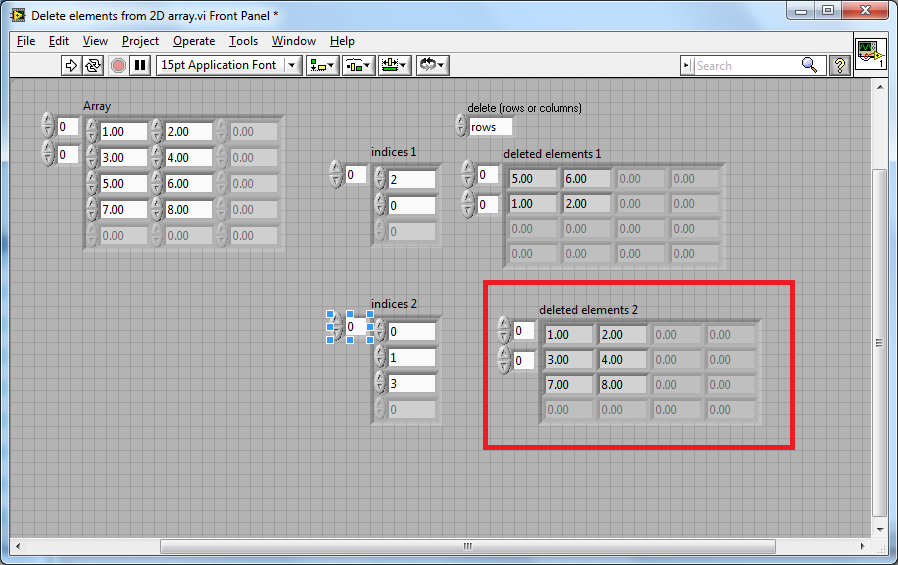
These are my versions of the clear error and clear specific error (you can find them in many of my submissions to the CR) that uses far less realestate and can be placed between property nodes (and similar) without having to route wires around.
Really?
I had a hunt as to aid the discussion. I could only find this in OPP from your LAVA CR files but I may have missed it?
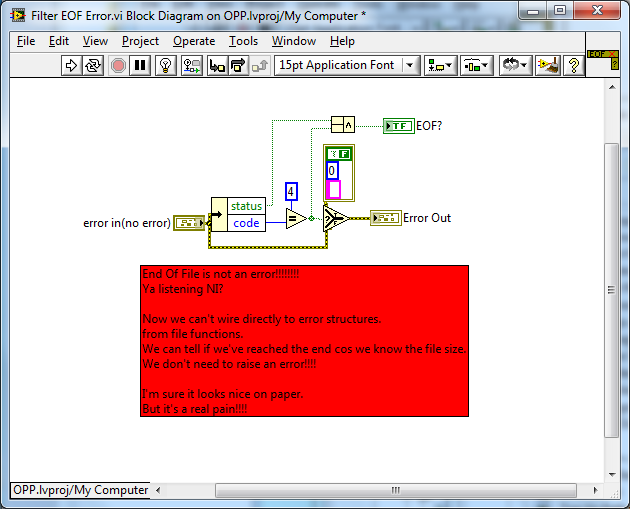
Your snippet obviously is missing your reuse subVIs - do you mind posting?
Cheers
-JG
I also think the we should polymorphize the API here too for the Error Code input.'
Should we support an array of Errors In too?
This would mean a total of 4 VIs - most likely with the Error In array as a thin wrapper around the above mentioned VIs (no function changes).
I have made this into an OpenG Review.
-
The second method won't work with 2011 since that hex pattern doesn't exist. I checked. I also looked for the method he described in going and searching around a starting offset. No go. Not too surprising since the original was in reference to LabVIEW 8.6.1.
I checked in 2009 and 8.6.1 - with no luck too.
-
A) I definitely would not provide default values for those input terminals. Make them required.
B) What happens if High is less than Low? Perhaps an absolute value node should be added to the subVI?
On the topic of B) I use the Min/Max primitive as Ton suggested:
I would suggest to make the Upper limit required, and check for the min/max (use the native sort 2 number primitive).
E.g. when converting a Start/End Index to Index/Length for arrays, I do the precheck and also output a pass result (if ever of interest).
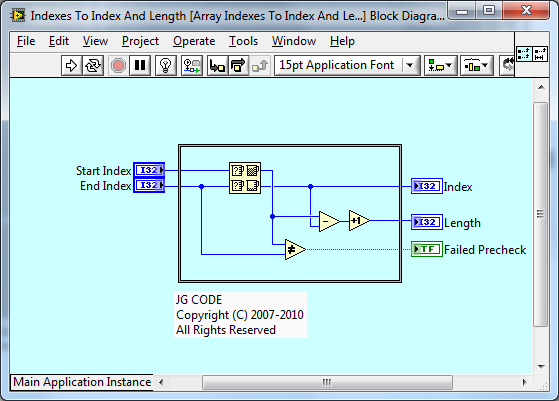
We could do something similar here however, I recommend we depreciate the original VI as this will cause a behavior change of the function. If we depreciate the VI, then IMO we should also do A) and make the inputs required for all new VIs.
-
FWIW, I have a similar reuse VI in my library (I think it was originally based on one from an NI course)
Anyway, I would recommended clearing the error as opposed to using the constant (just in case there is anything NI handles under the hood in the future etc...)
I never created an array version (as never have the need) - not saying one wouldn't be useful.
Code is in LabVIEW 2009.



Filter Error Codes (Error Package)
in OpenG Developers
Posted
Here is an example of Clear All Errors with the Upstream Error, pretty simple BD:
Can anyone help with the Connector Pane
3x1x1
Shows the Upstream coming in from the top in context help (although you can wire it from the bottom).
5x3x3x5
(Note: Upstream will actually be optional, I was just playing around with the CP).
What are peoples thoughts on the VIs that Jim has donated?
Personally aside from the Upstream Error feature, I like that the core VI is the Array and the Scalar is the wrapper so there is only really one lot of code to maintain.
Another question following on from my previous ones - there is enough CP outputs to output all three cluster elements separately (as opposed to the boolean and new cluster) - was there a specific reason not to do this?
Clear All Errors.vi
Code is in LabVIEW 2009