

PJM_labview
-
Posts
784 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by PJM_labview
-
-
I am not sure I understand your problem.
If you put a breakpoint on a template the instance will still brake at the breakpoint location once you run it.
PJM
-
QUOTE(Ben @ Sep 21 2007, 05:38 AM)
Ah,
I missed this nugget.
Anyway, this is such a cool feature that I guess we can talk about more than once

PJM
-
Thanks.
I had not realized that the point32 input was an absolute coordinate and not a relative one.
PJM
-
Has anyone ever use the Byte Offset from Point string method?
What does it do?
How does it work?
NI help is quite parse on the topic, and everything I try (in LV 8.21) returns 0 for Byte Offset from Point...
Thanks
PJM
-
QUOTE(tcplomp @ Sep 20 2007, 10:34 PM)
Thanks.
I am not sure what happened to get that "http:\\blog\" in the begginning.
This is fixed now.
-
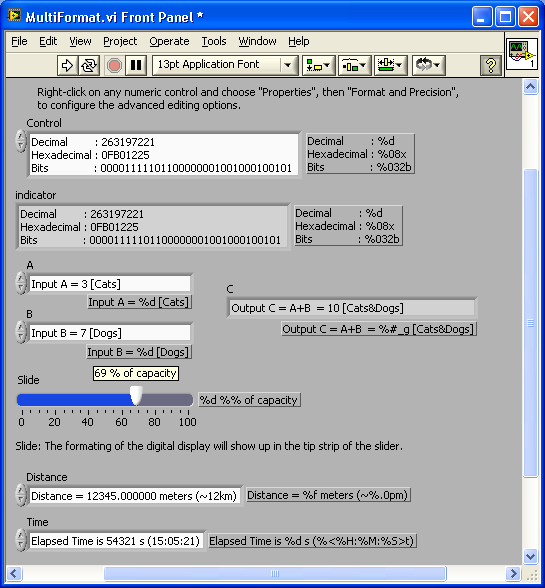
Hi All,
I've written a new article (has been a long time since the last one!), titled: Advanced Numeric Formating
Most of you have probably used the Format and Precision tab of a numeric, but how many of you have ever used the advanced editing mode... Read more
Cheers,
PJM
-
QUOTE(Gary Rubin @ Sep 20 2007, 11:39 AM)
Hmmm, that does seem odd - maybe a difference in memory speed between the single-core and dual-core systems?This was on a PXI chassis (1031 DC). The "Brain" was upgraded from a NI PXI 8196 to a NI PXI 8106 (dual core), and I believe they took the memory from the old one and put it on the new one (2Gb Total).
Other than these specific CBR recursive VIs, everything else run smoother and faster.
PJM
-
QUOTE(Gary Rubin @ Sep 20 2007, 09:39 AM)
This sounds indicative of non-parallel dataflow. What you described sounds like each core is spending half its time waiting for the other to finish.If you do not see total CPU usage over 50%, then you are not actually doing anything in parallel and would not expect any better performance than a single core.
While I would not necessary expect improved performance, I certainly would not expect worse one. But this has happened.
You are probably correct regarding the code not doing anything in parallel though. This was a bunch of VI doing recursive CBR call.
PJM
-
QUOTE(Gary Rubin @ Sep 19 2007, 05:46 PM)
I think the answer is "yes" to both. It depends on how parallel your processing is. You usually can see some increase in performance just by dropping it onto a multicore system, but you might be able to do much better by being careful with your threading and taking advantage of some of the thread priority settings.This is not quite that easy. In some instance your code may run faster, in other it may actually run slower. What I have noticed in LabVIEW 8.21 is that when you get a multicore the load end up spread more or less evenly between the two core, but for some reason it is "harder" to reach high processor usage. So in some situation, you may have some code that may use briefly 90% of a single core processor and take about 1s to run and the same code on the multi core will be balanced at about 50% on each core and take 2s to run.
With LabVIEW 8.5, if you use timed loop, you can explicitly point (if you want to) at which core the code inside the timed loop run. While this feature is market at RT systems, it appear to works just fine on window. I which NI had gone one step further though and did the same thing for while loop and for loop. It would be very nice if I could right click on a while loop and select "run on core1" for example. Fortunately, it seem that you can trick LabVIEW in doing so by wrapping the code you want to run on a specific core inside a time loop (not very elegant at all, but the test I run seem to indicate this work fine).
In conclusion, when you migrate some code from a single core to a multi core, it *may* run faster from the get go, but this is not an absolute certainty.
PJM
-
I believe this is a bug.
In previous LabVIEW version, the property "FP.IsFrontMost" was working regardless of the windows state. Now in LabVIEW 8.5, if the window is set to floating, this property is no longer working.
Anybody has any idea for a workaround (short of not using the floating state of course)?
PJM
-
Here is my rule of thumb:
Whoever open the reference shoud be in charge of closing it.
Here is some of the rational behind this:
- One of the main reason to proceed like this is to improve code clarity.
- Another reason is to prevent bug. If you close the ref deeper in the hierarchy you might be tempting to branch the source wire upper in the caller to realize later the reference is no longer valid.
Therefore, in your example the caller of the SubVI should be in charge of closing it.
Just my 2c.
PJM
- One of the main reason to proceed like this is to improve code clarity.
-
-
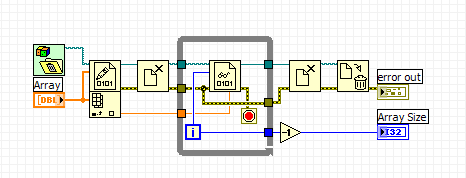
Here is another one that would probably win in the "slowest" category.
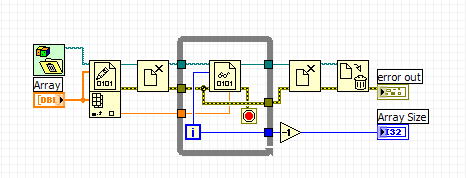
PJM
-
QUOTE(Aristos Queue @ Sep 13 2007, 11:29 AM)
This is not quite correct. If the array is an array of error cluster and if one of the error is the constant used on the BD (as unlikely as it seem) this may return the wrong result.
PJM
-
Ya, this (the Shift+Enter on string constant entry) is pretty usefull and I wish it would work on floating label.
I constantly catch myself trying to shift+enter floating labels...
PJM
-
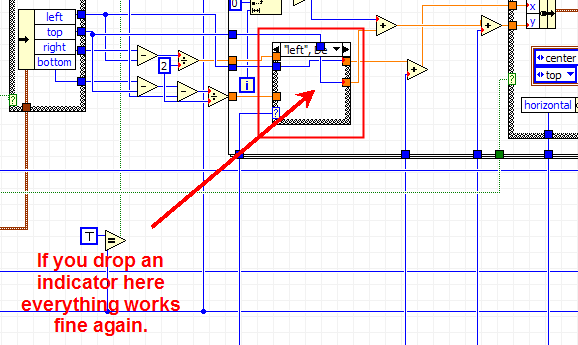
This is quite odd (With debugging off, the text ends up beeing drawn on the top of the image).
After further investigation, it appear that this *might* be happening inside the case strucutre were the I16 is coerced to a double (see image below).
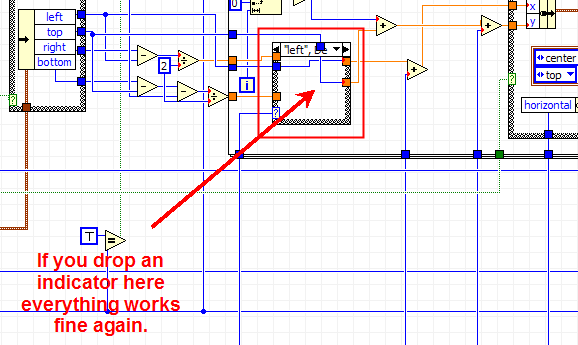
If you drop an indicator connected to the I16 inside the case structure, everything works fine again.
It look like this might be an implaceness optimization bug.
PJM
-
May be I miss it, but what LabVIEW version is the deployed application buidl with?
PJM
-
David
If you were to use OpenG Pakcage file (ogp) then you could defined different versions of your librarie(s) to be installed under different LabVIEW versions. If you were to do this, then the ogp version becomes THE unique version. You do not have to worry about where or how to document the different versions included in your zip file. Unfortunately, if you have never made an ogp, this will requires a little bit of work to get started.
Just a though.
PJM
-
-
-
Win XP, LV 8.21
Getting 0 here.
PJM
-
Here, in the US, NI has been know to organize user group meeting at company site (if there is a large enough number of participant). If this is what you are asking about and you have local NI sales people, you might want to contact NI.
PJM
-
QUOTE(Ben @ Aug 24 2007, 05:22 AM)
Thanks, but I had nothing to do with it. Jim (Kring) wrote it.
QUOTE(Ale914 @ Aug 24 2007, 06:26 AM)
PJM is this package also "relink" all the project VI, after change the name?Yes, after you renamed your folder, everything in it has been relinked of course (it would not be very useful otherwise).
PJM
-
Download VIPM and install this package ogrsc_rename_folder_of_vis.
This install under your file menu a great utility to move rename ("instanciate for your case") folder of VIs.
http://forums.lavag.org/index.php?act=attach&type=post&id=6747
PJM
Change the FP grid spacing programmatically?
in VI Scripting
Posted
I am also VERY interested in finding out if this is possible. I looked for such settings a while back but I could not find anything. Since I have to change this settings manually constantly for every VI I worked on that I did not create, having a way to do this programmatically would be very handy.
Below is what I want to be able to do programmatically:
From:
To:
Basically I hate to have to do this operation several times a day...
PJM