

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
I do agree the M/S template doesn't seem to map very well to code I've encountered in the wild.
That's because we generally use the event structure to achieve this.
-
Producer/consumer is 1-1 master slave is 1-many. Also a producer/consumer is loss-less, master,/slave isn't.
-
You ever used DAQmx? Ever read keys out of an ini file using the VIs in vi.lib? I'm guessing you do do* OOP, just without knowing about it.
* wow - "POOP" and "do do" in the same thread - real mature LAVA!
Just because you use a class, doesn't make your program an object oriented design any more than passing a value from one function to another makes it dataflow.
-
 1
1
-
-
-
Nice catch! (And another illustration of how the common practice of connecting all the error terminals can introduce subtle bugs.)
And you've also fallen foul of (reintroduced) the "close" property node being wired. An error on the wire means the dialog will not close (notice in Mje's example it is not wired)
-
Hey folks-
I reckon my question is more windows XPe related than LabVIEW related, but it wouldn't surprise me if someone here has dealt with, or considered this idea before in this arena.
My googling has turned up very little... but I want to know how feasible it may be to turn a box running XPe into a USB device (test and measurement class) that can be recognized by a remote hosting computer - all the while still being able to host USB devices on other USB ports itself for USB DAQ.
Even if someone was willing to point me in the right direction, to documentation or another forum it would be very much appreciated!
Thanks
-pat
A simpler (and proven) solution is to use the XPe box as a host for the USB devices and connect to it using the network interface.
-
- Popular Post
- Popular Post
If you are not using POOP (Predominantly Object Oriented Programming) then a lot of the POOP design patterns are no longer relevant since the problem that they solve becomes trivial and most of the mechanics gets handled by the language (yes I'm looking at you "singleton"). With POOP, the problem is usually "State", transitions of state and how to manage it. That's not to say that there aren't any in non-OOP languages, They are just usually called "frameworks" and tend to be more generic. The thing to bear in mind is that design patterns solve a well known problem. But that problem is usually a restriction in the language or paradigm you are using (sometimes called "Idioms" by the Architecture Astronauts). Therefore design patterns tend to be paradigm/language specific (not all...but most). But you have probably been using non-OOP design patterns for quite some time (State Machines, Producer/consumer, Publisher/Subscriber)
Take Monads for example (a functional programming design pattern)
The monad acts as a framework, as it's a reusable behavior that decides the order in which the specific monadic functions in the pipeline are called, and manages all the undercover work required by the computation.[3] The bind and return operators interleaved in the pipeline will be executed after each monadic function returns control, and will take care of the particular aspects handled by the monad.
Sound like VI's and terminals? We (as Labview programmers) have no need for this "pattern" because it is an in-built feature of the language (we chain VIs [monads] together using wires [pipelines] via their terminals [bind/return operators]).
A good example of a design "Pattern" that IS useful in Labview is the Producer/Consumer (we all know that one - it's a template in Labview). Why? Because it addresses a restriction of the language (it breaks Dataflow). Most of the time dataflow is our friend (it automagically handles state and imposes strict sequencing in a parallel manner) but when we need asynchronous operations this is a simple generic pattern in our arsenal.
So what POOP patterns are useful to us in "classic" labview? As a general rule -.those that break dataflow! So we have a use for things like the "Observer Pattern" or, as we muggles call it, "Publisher/Subscriber". But we also have uses for the more structural patterns such as Strategy (think plugins), State (think state machine) and Facade (think API). although these could arguably be called "idioms" for classical Labview usage.
And those that aren't very useful? Well. Most of them
 Labview itself makes most of the issues associated with POOP patterns fairly trivial. Many are variations on a theme (Mediator and Facade for example). Many revolve around instantiating objects - Creational patterns (we generally define all objects at design time). And many are based around managing communications between objects - Behavioral patterns, (we have wires for that).
Labview itself makes most of the issues associated with POOP patterns fairly trivial. Many are variations on a theme (Mediator and Facade for example). Many revolve around instantiating objects - Creational patterns (we generally define all objects at design time). And many are based around managing communications between objects - Behavioral patterns, (we have wires for that).Why aren't there many references to design patterns outside of POOP? Because they generally solve problems caused by POOP.
Now where's my hard-hat.


-
5
-
I would be surprised if there didn't exist a license generator for all versions of LabVIEW.
There is.It also activates all the tool-kits and addons.
-
I think this would be better if your tools took in an array of U8s. You're not sure if you encrypting data or text. Data should be represented as an array of bytes (U8s) and text should be represented as strings.
In LabVIEW we've traditionally (read "incorrectly") treated an array of U8s the same as a string because the data types are essentially the same for our strings. We want to change this in the future and work away from treating strings as data, since you can only represent a small subset of characters as U8s. (For more information, see Text Encoding and Windows-1252. Windows-1252 is the character set / encoding that LabVIEW supports in English (and French and German, IIRC. Japanese, Chinese, and Korean are obviously different).
At a very high level, the guidelines we came up with can be boiled down to three rules:
- Only use the string datatype for things that are actually sequences of characters. Use arrays of U8 for things that are arbitrary binary data.
- APIs that operate on strings should do what makes sense for a sequence of characters.
- APIs that can support either string or [u8] should provide separate entry points.
So does that mean that comms primitives (TCPIP, Serial, Bluetooth etc) are all going to be changed to arrays of U8?
Strings/data....it's symantics. If it's not broke...don't fix it.
- Only use the string datatype for things that are actually sequences of characters. Use arrays of U8 for things that are arbitrary binary data.
-
-
Where does the licensing scheme even remotely touch password security of VIs? Anything license related is really handled in the LabVIEW kernel itself so not sure what the ability to unlock a password protected VI would do there.
I never said it was. I was simply pointing out that NI wouldn't "cry" over a password protection hack and that since the licensing has been compromised; they would be more concerned about that-if at all
-
Great post!
Do you know how to integrate test unit, rspec, cucumber and fitnesse into LabVIEW?
I'd like to manage my tests from Ruby since it's free tools are much more advanced than what I found in LV.
Do you think this is a good idea? Is it possible at all?
If not, do you know how to best implement the agile process in LabVIEW?
Thanks in advance,
Dror.
I know nothing about Ruby...and probably never will. But I would imagine the test tools for it are aimed at that environment in the same way as they are in Labview and (probably) not compatible. If you want to manage your tests in Ruby. Write the tests in Ruby! Whats the point of mixing and matching technologies and the headaches associated with getting them to play nicely (activeX springs to mind).
Agile development is language agnostic. It is also discipline independent since it is a group of project management methodologies. So the answer to how do you implement it in Labview is "the same way you would for anything else". I personally use M$ Project and. at a push, will use Excel - it's not really important. The key point is for some of your incremental release gates (cycle results) to coincide with major milestones on a more encompassing, linear plan (since that is what the upper echelons of management prefer).
-
IF this work,NI will cry.

Nope, It affects the users more than NI. Ni are probably more worried that their whole licensing scheme has been compromised since 2009.
-
1
-
-
Are the two solutions you're considering 1) propogating the fault state up through the component hierarchy, and 2) not propogating the fault state up through the component hierarchy?
If it is..... I would choose No3. Each module is configurable to do No1 or No2 to it's immediate owner.
-
-
I understand now... I think my brain is on autopilot.
That does eliminate the trailing Set Sequence, but the functionality doesn't change--it still makes loop B execute one "extra" time.
You are changing the requirements now

I started wondering how to prevent the extra occurrence, so I added a timeout and removed the tailing Set Occurrence
-
-
On the surface it seems like that should work, but there's a subtle race condition. Because the WoO has a timeout it is possible for loop B to read the stop button, exit, and reset before loop A has an opportunity to read it. With an infinite timeout that will never happen. I suppose you could put the button reset in a sequence structure and wire outputs from both loop A and B to it, but that feels kind of klunky to me. The other alternative is to set the timeout longer than the time between occurrences, so it will only timeout once the occurrences have stopped being generated. That doesn't seem like a very robust solution.
Just OR the =0 with the stop and it will work without an extra occurrence and without a timeout..It is a sequencing issue rather than a race condition-as with AQs version.
-
Occurrences do have a timeout.
I stand correct4ed (when did they add that then?)
The main reason occurrences behave differently than the other sync objects is because occurrence refnums are static. The refnum is created when the VI that contains the Generate Occurence function is loaded, not when it is executed. That means that a VI which is reused, say in a loop, the Generate primitive will return the same occurrence on each invocation. This is often counter-intuitive to those that don't understand the mechanics of how occurrences are created and can lead to some serious bugs due to previous values being in the occurrence.
IMHO this is how the other primitives should behave (and that includes diagram, project and control refs). I've lost count of the number of times I have had to correct others' code because the refs aren't closed. It is these primitives that are counter and intuitive rather than the occurrence. Oh for the days when Labview meant you didn't have to worry about memory leaks.
The fact that they're created on load is also the reason there is no need for a destroy primitive. Memory leaks don't happen because repeated calls to Generate Occurrence in the same VI always return a reference to the same instance.
The behavior is very useful if the primitive behaviors are understood though. They just work completely different from all the other synchronization primitives.
Seems to me that they work similarly to a notifier (since they have a timeout) without the pit-fall of memory leaks.
-
Care to elaborate? (I've never used occurences and I'm finding it a bit confusing.)
Because the local variable will be evaluated well before the first loop reaches the large number and will present a FALSE to the stop terminal. Everything (in the second loop) then waits for the occurance. Once Loop 1 actually fires; loop 2 then proceeds with the FALSE, goes around again and then waits, once more, on the occurance-which never arrives since the first loop has already terminated.
This is why no-one uses them. Its too easy to get race conditions that hang your app because they don't have a time-out.
It will work correctly IF you put the occurance and the local into a sequence structure that guarantees the local is read AFTER the occurance (another reason no-one uses them since they don't have error terminals and forces you to use those pesky sequence structures.)
-
1
-
-
I had a conversation with our chief architect whose been working on LV since version 0.1 and who created the occurrences long long ago. Here is THE correct way to use occurrences:
First build a system which polls busily for whatever it is the occurrence will signal. You need to be able to determine the state of things without an occurrence. This creates a correct, but inefficient busy waiting implementation. Once that works, add an occurrence to alleviate the inefficient waiting. Do not remove the actual polling. In other words, use the occurrence only to indicate that "it is probably a good time to check on that thing...".
In other words, start with this:
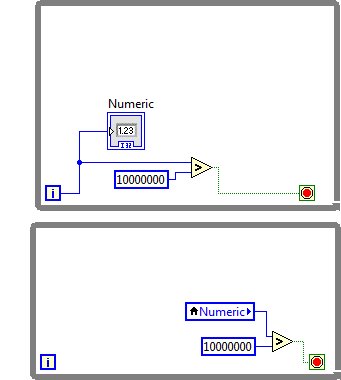
and then go to this:
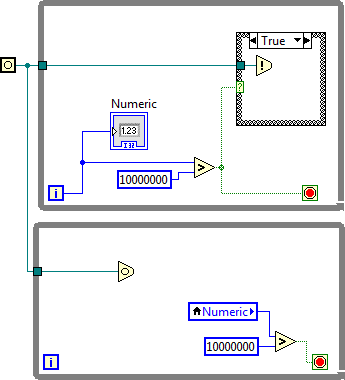
As I understand it, occurrences don't have thread safety on their state because they are the building blocks by which thread safety for state in higher level APIs is built.
That won't work.
-
1
-
-
Sry for gettin off topic here, but Shaun- noobie question, is there a way to set up your structures to have color tint like the for loops ya just posted by default? So every time I lay a for loop its tinted yellow, while loops blue etc etc...
and also- if I did this, would it stick with the vi if I were to send the vi to someone or edit it on another computer?
thx!
-pat
I just set the block diagram background colour in the preferences. I use a different colour for each LV version so I'm aware of what version I'm in. I also use it as a "completion" indicator". I start out with all the diagram in a colour and set cases, frames etc it back to white once that frame/module or whatever is completed. That way I (or my colleagues) can see at a glance where I need to do some more work.
Yes. It sticks with the vi.
-
1
-
-
So how do you hack it then...
Should you really be asking that question?

-
1
-
-
The byte sequence will change every re-compile-so it is unlikely to persist exactly as in that post across versions or even the same versions with different bitness. But at some point you have to say "Is it? or Isn't it? a correct password" and finding it is easier if there is a dialogue since you know where to start.
I think most of NIs password protected files are purely to hide the terrible coding. Not that bothered if someone sees mine.
-
2
-
Master/Slave vs Producer/Consumer templates...?
in LabVIEW General
Posted
Actually. thinking more (briefly). That is not a requirement of a Master/Slave. It is more an implementation of the example.In the same way that Pub/Sub is a subset of client/server, so is M/S and P/C. The differences are in the way that they realise the client/server relationship.