Steen Schmidt
-
Posts
156 -
Joined
-
Last visited
-
Days Won
8
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Steen Schmidt
-

[CR] GPower toolsets package
Steen Schmidt replied to Steen Schmidt's topic in Code Repository (Uncertified)
Since nobody else is replying I might as well keep this thread going with an important bit of info : A VIRegister must be located in an unshared call chain if you do not wire the Scope VI reference input! This means that no VI, in the call chain from the Top-Level VI all the way down to each caller that contains a VIRegister function, may be configured as shared reentrant nor non-reentrant. Only preallocated reentrant will work. The reason is that a VIRegister can be seen as equivalent to an uninitialized shift register when the Scope VI reference input isn't wired. The only way to get around this (as far as I can currently see) would be to check the Top-Level VI identity at each read and write - and that would make a huge negative impact on performance. There will be a note about this in a future update to the user guide, unless I find some elegant way to get around this limitation. Cheers, Steen Update: A quick test shows a 100 times performance degredation if I need to pull the call chain on each access. That's unacceptable. But I can make the VIRegister throw an error at runtime if it finds itself in a possibly shared call chain, without any impact on performance. That is acceptable for now I think. -
[CR] GPower toolsets package
Steen Schmidt replied to Steen Schmidt's topic in Code Repository (Uncertified)
Note to self (and Michael et al perhaps ): Should this thread be in the 'LAVA Code on LabVIEW Tools Network' forum instead? Anyways, let's see what you say about the code, if it should be here at all . Cheers, Steen -
Name: GPower toolsets package Submitter: Steen Schmidt Submitted: 15 Mar 2012 Category: *Uncertified* LabVIEW Version: 2009 License Type: BSD (Most common) This is a submission for the GPower toolsets palette, which will also shortly be available on the NI LabVIEW Tools Network. I submit it to Lava to (of course) share it with everyone, but also to establish an open forum to discuss improvements and to provide support. Much better than hiding all this in private email conversations with each user. The toolsets are compiled for LV2009 SP1, are provided as VIPs for VIPM, and will mass compile to at least LV2010 and LV 2011 without problems (this happens automagically during the VIP-install process for those of you that don't know VI Package Manager ). The 'gpower_lib_toolsets-1.0.0.6.vip' is an umbrella for the four other VIPs, it doesn't add anything extra by itself. Currently this consists of 4 toolsets: Dynamic Dispatch Open, pass data to (without using the front panel), run, and close dynamic VIs. A cumbersome process using VI Server made easy with this toolset. Error Streamline common error wire tasks such as set, filter and clear errors and warnings, and unbundle the error cluster. Adds advanced features such as dynamic setting of custom global errors, that you can invoke from anywhere in your application, and bundling errors into a single error wire. No more need for arrays of error clusters! Timing Calculate elapsed and remaining time, and abort a running Wait function for instance. VIRegister High performance "global variables" that lets you pass data between any corners of your application. It's based on queues, so a "global" that does not involve using front panel controls, files, or the LV project - it all happens in the block diagram. In most cases you don't even have to pass a refnum around, just drop a VIRegister somewhere and you're done. If this thread generates too much noise across the different toolsets, we could split this into 4 submissions. But lets see how it goes. More toolsets are awaiting release, but I'll start with these four to get a feel for the process. Cheers, Steen Click here to download this file
-
Version 1.0.0.6
2,478 downloads
This is a submission for the GPower toolsets palette, which will also shortly be available on the NI LabVIEW Tools Network. I submit it to Lava to (of course) share it with everyone, but also to establish an open forum to discuss improvements and to provide support. Much better than hiding all this in private email conversations with each user. The toolsets are compiled for LV2009 SP1, are provided as VIPs for VIPM, and will mass compile to at least LV2010 and LV 2011 without problems (this happens automagically during the VIP-install process for those of you that don't know VI Package Manager ). The 'gpower_lib_toolsets-1.0.0.6.vip' is an umbrella for the four other VIPs, it doesn't add anything extra by itself. Currently this consists of 4 toolsets: Dynamic Dispatch Open, pass data to (without using the front panel), run, and close dynamic VIs. A cumbersome process using VI Server made easy with this toolset. Error Streamline common error wire tasks such as set, filter and clear errors and warnings, and unbundle the error cluster. Adds advanced features such as dynamic setting of custom global errors, that you can invoke from anywhere in your application, and bundling errors into a single error wire. No more need for arrays of error clusters! Timing Calculate elapsed and remaining time, and abort a running Wait function for instance. VIRegister High performance "global variables" that lets you pass data between any corners of your application. It's based on queues, so a "global" that does not involve using front panel controls, files, or the LV project - it all happens in the block diagram. In most cases you don't even have to pass a refnum around, just drop a VIRegister somewhere and you're done. If this thread generates too much noise across the different toolsets, we could split this into 4 submissions. But lets see how it goes. More toolsets are awaiting release, but I'll start with these four to get a feel for the process. Cheers, Steen -
It's not so much early adoption as it is hours spent up front instead of 10-fold on fixes and more fixes. A well designed application is more or less hitting the ground running, and you can focus on adding functionality or the next application instead of perpetually fixing the old ones. So the pain you feel is just because you do all the work up front, and the sum of it is much less than if you look back at the work put into a poorly designed application . Cheers, Steen PS: I hope the "holiday dinner" feeling has faded - for the record I believe the debate about using Shared Variables or not is very much in synch with the topic (if that was the topic you felt sidetracked your thread a bit here). My experience with SVs, which I described here, was a direct response to your "I now see no reason to avoid shared variables for sharing data between vis when only one vi is ever going to write to them" statement. And that experience didn't come cheap. Just for the record. Didn't want to swamp your voice .
-
OK, then you operate with static IP adresses, since the SV API needs a static SV refnum? In our network enabled SV apps we use DataSocket in one end to allow for dynamic IPs./Steen
-
We started using SVs really heavily 3-4 years ago for streaming. We ran into all sorts of trouble with them, and were thrown around by NI a fair bit while they tried to find the spot where we used those SVs wrong. Finally last year we got the verdict: SVs were not designed for streaming, they can break down when heavily loaded - please use Network Streams for this instead. That NI didn't let this info surface before Network Streams were ready as replacement is quite distasteful, it has cost us and our customers millions chasing SVs with the wrong end of the stick. Had NI told us with a straight face that our implementation weren't going to work, but they were working on a replacement, we'd have been in a much better position. Now, as it is, I never want to touch anything that has to do with SVs. I was burned too badly, and now we have our own much better solution. We need to deploy the SVE on RT since the RT system is usually the always-on part in our applications - our Windows hosts are usually optional connect/disconnect type controllers while the RTs run some stuff forever (or for a long while). Simulation, DAQ, control/regulations etc. It could seem SVs fare better on Windows, both due to the (often) higher availability of system resources there, but also due to the more relaxed approach to determinism (obviously). That's a good thing, and I sense that SVs work for most people. It may just be because SVs were never designed to the load we put on them. It's only when we have problems that it's bad that the toolset is a black box. Otherwise it's just good encapsulation . But with TCPIP-Link we just flip open the bonnet if anything's acting up. If you have a network enabled, buffered, SV, all subscribers (readers) will have their own copy of a receive buffer. This means a fast reader A (a fast loop executing the read SV node) may keep up with the written data and never experience a buffer overrun. A slow reader B of the same SV may experience backlogging, or buffer overwrite, and start issuing the buffer overflow error code (−1950678981, "The shared variable client-side read buffer overflowed"). A bug in the SVE backend means that read node A will start issuing this error code as well. In fact all read nodes of this SV will output this error code, even though only one of the read buffers overflowed. That is really bad, since it 1) makes it really hard to pinpoint where the failure occurred in the code, and 2) makes it next to impossible to implement proper error handling since some read nodes may be fine with filtering out this error code while other read nodes may need to cause an application shutdown if its buffer runs full. If the neighbors buffer runs full but you get the blame... how will you handle this? NI just says "That's acknowledged, but it's too hard to fix". You connect programmatically through DataSocket, right? With a PSP URL? Unfortunately DataSocket needs root loop access, so it blocks all other processes while reading and writing. I don't know if SVs do the same, but I know raw TCP/IP (and thus TCPIP-Link) doesn't. Anyways, for many applications this might not be an issue. For us it often is. But the main reason I'd like to be able to programmatically deploy SVs on RT would be for when variables undeploy themselves for some reason. If we could deploy them again programmatically we could implement an automatic recovery system for this failure mode. As it is now we sometimes need to get the RT system connected to a Windows host with LabVIEW dev on it to deploy the variables again manually. I know this process can be automated some more, but I'd really like the Windows host out of this equation - the RT systems should be able to recover all by themselves. It was very hard to write TCPIP-Link. But for us NI simply doesn't deliver an alternative. I cannot sell an application that uses Shared Variables - no matter the level of mission criticality. I can't have my name associated with potential bombs like that. Single process (intra-process) SVs seems to work fine, but I haven't used them that much. For these purposes I usually use something along the line of VIRegisters (queues basically), but the possibility to enable RT FIFOs on the single process SV could be handy. But again I'm loath to put too many hours into experimenting with them, knowing how much time we've wasted on their network enabled evil cousins . Cheers, Steen
-
Well, I really hate Shared Variables due to their weight (the SVE among other things), their black-box nature (when do updates happen? Not at 10 ms/8 kB as the white paper says, that's for sure) combined with known bugs (for instance will a buffer overflow warning in one node flow out of error out of all the other SV instances as well, even though their buffer didn't overflow), and due to their inflexibility (you can't programmatically deploy SVs on LV Real-Time for instance, and you need to be able to, since we sometimes experience SVs undeploying themselves spontaneously when the SVE is heavily taxed). There are many better alternatives for intra-process communication (queues, events, and even locals). For network we have developed our own sticky client/multi-server TCPIP-Link solution which is much better (faster, more stable, more features, slimmer) than SVs and Network Streams for network communication. Granted, TCPIP-Link wasn't trivial to make, it currently has clocked up in excess of 1000 man-hours. The only killer feature of SVs is how simple they are to bind to controls. But one or two wrapper-VIs around TCPIP-Link will get you almost the same... And it's a pity you need the DSC module for enabling events on SVs. We transmit waveforms on network without problems for data rates up to maybe 10 kS/s - a cRIO can generate data at that rate as waveforms for 40 channels without any backlogging due to either network or other system resources. For higher data rates we usually select a slimmer approach, but that aslo means more work to make data stay together. On PXI we can easily output data as clusters each with timestamp, some parameters like data origin, data flow settings (usually a couple of Booleans) and the data itself as an array of DBL for instance. This works fine for several MB/s payload. For Gb/s we must pack data in an efficient stream, usually peppered with codes to pick out control data (time/sync/channel info) that flows in a slimmer connection next to it. The latter approach can be rather difficult to keep contiguous if network dropouts can occur (which they will). Every application demands its own pros/cons decission making. That's at least a quite heavy approach, encoding numeric data into strings and stuffing it into a MC listbox or a Tree. But it'll work for really slow data rates of course (a few Hz). Cheers, Steen
-
Hi. Posting updates from many channels into a GUI is not a problem if you are careful about the design. One recent large application of mine (3-4,000 VIs) runs on RT but facilitate a UI on a Host PC that can be connected and disconnected from the running RT application. The UI is used for channel value and status display, as well as giving the operator an opportinuty to override each channel with a user specified value or in some cases a programmed waveform for instance. The RT system generates something like 100,000 events/s (equivalent to channel updates) and the UI just plugs in and out of this event stream as a module by dynamically registering and unregistering the wanted events. There is a module on RT that receives each event that it knows the GUI wants, then the data is transmitted over TCP/IP to the Host PC, where new events are generated to be received by the GUI module. All data is timestamped, so propagation delay is not a problem. Similarly for override-data the other way. It is no problem receiving 100,000 updates/s in the UI module without backlogging at all, but I do filter the events such that each event gets its own local register in the UI module which it may update at any rate, and then 10 times/s all changed registers are written to the GUI front panel. At almost 1,000 channels (and thus 1,000 controls on the GUI in tabs) this still works really smooth. So 8 channels of mechanical relays is no problem. The clue is to filter the updates so you don't update the GUI thousands of times per second, but remember to always maintain the most current value for when you actually do update. And if you run the UI on the same machine as the actual business logic then you need to be careful not to block that business logic - updating the UI will most often switch to the user interface thread or may even demand root loop access. Head that. Cheers, Steen
-
@AlexA: You could take a look at my ModuleControl toolset for inspiration - it's mentioned here. Unfortunately the toolset isn't yet publically available, but will be in the near furture on NI LabVIEW Tools Network (three other of my toolsets are arriving there as I write this, under the GPower name). Cheers, Steen
-
How do you see it get close to 1.5 million elements? On my example machine it allocated ~150 Mb memory before the mem full dialog (~150,000 elements). I've just tried running it again, and now I got to 1,658,935 elements (I think) before the mem full dialog, so I probably had much more fragmented memory earlier. Thanks for this info Greg, it makes perfect sense. A failed mem alloc is most probably a fish (or an app) dead in the water. Cheers, Steen
-
Thanks, Greg, for your thorough explanation. I suspected contiguous memory was the issue here, but while I know that LV arrays and clusters need contiguous memory I didn't believe a queue needed contiguous memory? That's a serious drawback I think, putting an even bigger hit on the dynamic allocation nature of queue buffers. As touched on earlier in this thread I thought a queue was basically an array of pointers to the elements, with only this (maybe 1-10 Mb) array having to fit in contiguous memory, not the entire possibly gigabyte sized buffer of elements. At least for complex data types the linked list approach would lessen the demands for contiguous memory. If the queue data type is simpler that overhead would obviously be a silly penalty to pay, in which case a contiguous element buffer would be smarter. But that's not how it is I gather. A queue is always a contiguous chunk of memory. It would be nice if a queue prim existed that could be used for resizing a finite queue buffer then... Thanks. I know of these workarounds, and use them when necessary. For instance we usually prime queues on LV Real-Time to avoid the dynamic mem alloc at runtime. The case from my original post is solved, so no problem there - I was just surprised that I saw the queue cause a mem full so soon, but the need for contiguous memory for the entire queue is a surprising albeit fitting explanation. Do you have any idea how I could catch the mem full dialog from the OS? The app should probably end when such a dialog is presented, as a failed mem alloc could have caused all sorts of problems. I'd rather end it gracefully if possible though, instead of a "foreign" dialog popping up. Cheers, Steen
-
This happens with all data types, not just arrays. I just used arrays in my example code snippet. My original problem where I could only allocate 150 Mb before mem error happened with a 48 byte constant cluster. I could reproduce it with a queue data type of Boolean, although it took much longer time to enqueue 150 Mb with Booleans :-) /Steen
-
Arrays need contiguous memory even when they don't have to... Anyways, this snippet of code runs out memory before RAM is full: My first encounter was on a WinXP 32-bit machine with ~1 Gb RAM free, LabVIEW reported memory full after ~150 Mb allocation for the queue. Then I ran the above snippet on a Win7 64-bit machine running LV 2010 SP1 32-bit with about 13 Gb RAM free (I know LV 32-bit should be able to use up to about 4 Gb RAM). LV now reported mem full after LV had allocated about 3.8 Gb RAM (don't know how much went to the queue). This memory allocation remained at that level, so following runs of the same code snippet reported memeory full much sooner, almost immediately in fact. LV only deallocated the 3.8 Gb RAM when it was closed and opened again, in which case I was able to fill the queue for a long time again before mem full. Adding a request mem deallocate in the VI didn't help me get the allocated memory back from when the queue ran full. - So at least on the 64-bit machine LV could use about all the memory as to be expected, but it didn't deallocate that memory again when the VI stopped. - Any idea how to avoid the pop-up dialog stating the mem full? I'd really like a graceful handling of this failure scenario. Cheers, Steen

-
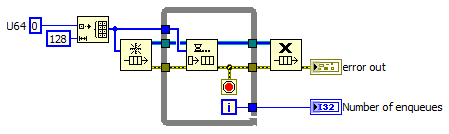
Hi. In an application of mine I came into an issue where a queue ran full, so I want to start a little discussion about which data structures scales the best when the goal is to use RAM to store temporary data (a "buffer"). This is for Desktop and Real-Time (PXI, cRIO etc.). My particular application is a producer-consumer type design, where the consumer can be delayed for a long time but will always catch up given enough time - the resource to support this is of course enough RAM, which in this case is a valid requirement for the system. The issue will present itself in many forms of course, so this might be of interest to a lot of you guys here. My application unexpectedly gave me a memory allocation error (code 2 on error out from the Enqueue prim, followed by a pop-up dialog stating the same) after filling about 150 Mb of data in the queue (that took a couple of seconds). This system was a 32-bit Windows XP running LabVIEW 2010 SP1. Other systems could be 64-bit, LV 2009-2011, or it could be Real-Time, both VxWorks and ETS-Pharlap. Is 150 Mb really the limit of a single queue, or is it due to some other system limit - free contiguous memory for instance? The same applies for arrays, where contiguous memory plays an important role for you running out of memory before your 2 or 3 Gb is used up. And, at least as important; how do I know beforehand when my queue is about to throw this error? An error from error out on the Enqueue prim I can handle gracefully, but the OS pop-up drops a wrench in the gears - it's modal, it can stop most other threads, and it has to be acknowledged by the user. On Real-Time it's even worse. Cheers, Steen
-
Hi. Version 1.3 of VIRegister is now ready for download: Version changes from v1.2: - Warning propagation through 'VIRegister - Read.vi' improved (in response to Götz Becker's post). Cheers, Steen
-
Yes, that's on purpose. I'm usually quite anal about wiring the error terminals, so it's quite rare I choose not to. In this case the error in will always be "no error" due to the error-case before, and no nodes in between to generate an error. I thought only wiring from error out on the lossy enqueue underlined the fact that any error out of this case was from that node. And as I write this I realize that any warnings coming in through the error wire will be dropped. I don't know if any warnings can be generated by the nodes before, as there is no way to tell which errors and warnings each LabVIEW function can generate. This means I also don't know if I really want to propagate any warnings or not... Oh well... And I like nit-picking, it's a great way to improvement . Cheers, Steen
-
Hi. Version 1.2 of VIRegister is now ready for download: Version changes from v1.1: - Significant performance improvement. Cheers, Steen
-
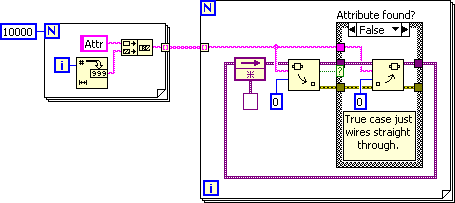
Not to split hairs over words, but several orders of magnitude slower (~4000 times), for a specific data type only (variant), in a specific configuration (initialized feedback node) equals highly unexpected behaviour. For sure the code runs without error, so the computation itself is fine. It's a question of how we define a bug. When I see performance vary so greatly between neighboring configurations I can't help but wonder if no memory got hurt in the longer computation? In LabVIEW 8.6.1 the same code runs in about 50 ms, so very comparable to LV 2010 SP1. But in LV 2009 SP1 that figure is 3 minutes. I'm not sniping at you in R&D, who make huge improvements to the LabVIEW we love without ever getting due credit for what you're doing, but something did happen here. In this case it almost made me abandon variant attributes as a means of key cache, since VAs have varied greatly in performance over the last several versions of LabVIEW. Had I (falsely) concluded that VAs were unreliable performance wise, that would've had widespread consequences for many people, including myself, since my recommendations in regards of LabVIEW and NI SW/HW in general is taken very seriously by alot of people in Denmark. The only thing that made me stick to digging in this until I found out what was wrong, was the fact that I started out by making two small code snippets that clearly demonstrated that the binary and linear algorithms were in fact still used as expected, and thus setup my expectations toward performance. My VIRegister implementation using VAs showed a completely different picture though, and it took me a long time to give up finding where I'd made a mistake in my code. Then I was forced to decimate my code until I was down to the snippet I posted earlier, which hasn't got more than a handful of nodes in it. Big was my surprise when performance went up by a factor of 4000 just by replacing the feedback node with shift registers. But nevermind, I couldn't find anywhere to report this "bug" onlline (I usually go through NI Denmark, but it's weekend), so it hasn't been reported to anyone. If it isn't a bug I won't bother pursuing it. Now I at least know of another caveat in LV 2009 SP1 . Cheers, Steen
-
First benchmarks indicate a performance improvement especially when using variable register names (500-1000 times better performance), but also when using constant register names (15-20%). When using variable register names you actually only halve performance now compared to a constant name. I wouldn't have believed that possible a few days ago. With v1.1 the two use cases are a world apart, but that's the difference between n and Log(n) search performance right there. Performance on LV 2010 SP1 seems slightly better even than 2009 SP1 (5-10%). Thanks Mads, for pushing me to investigate this in depth . /Steen
-
Ok, I quickly ported a VIRegister (read/write Boolean) to use variant attributes (let's call that v1.2), but was sorely disappointed when I benchmarked it against v1.1. v1.2 came out 1000 times slower than v1.1 on 10000 variable registers. 6 hours later I've isolated a bug in LabVIEW 2009 SP1 regarding initialized feedback nodes of variant data . The code snippet below runs in almost 3 minutes on LabVIEW 2009 SP1, but in just 40 milliseconds on LabVIEW 2010 SP1: Just by changing the feedback node into a shift register equalizes the performance on LV 2009 SP1 and 2010 SP1: But it has something to do with initialization or not, and how the wire of the feedback/shift register branches, so it can also fail with a shift register under some circumstances. I think I can get around that bug, but it'll cause a performance hit since none of the optimum code solutions work on 2009 SP1 (I need this code to work on 2009 SP1 also). This means I'll probably release v1.2 implementing VAs soon. /Steen
-
Thx.
-
Heh Now you mention it... In the context of Real-Time; does this (these) nodes use the FP for data transfer or is the con pane on the node just an interface directly to the terminals on the BD of the receiver? I'm basically asking if input data winds up in the user interface thread and so must cross in the transfer buffer, or if it is injected directly into the execution thread without forcing a thread switch? The pre-11 Synchronous node forces an initial swap to the user interface thread on the receiver end to deliver input data as I understand it... /Steen
-
You must mean unnamed queues... But using FGVs and globals are using references, so therefore deemed "unworthy" apparently. Call by reference and using the FP specifically isn't a good option on Real-Time. I'm wondering about dynamic code myself in this context, hence my earlier question regarding that. /Steen
-
Ok, so you have 1.5 seconds in v1.1 and 39 ms for the same operation in your v1.1 modified for VA? Looks promising, but the hit on constant-name lookup better be small! . How do you solve the lookup problem regarding not being able to lookup the VA by Register name alone, but will need to use Register ID (currently a cluster of both Register name and Scope VI refnum)? I have a use case where only Scope VI refnum differ, while Register name is constant. /Steen