Steen Schmidt
-
Posts
156 -
Joined
-
Last visited
-
Days Won
8
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Steen Schmidt
-
 Ah, now I understand, thanks . I assumed I would incur a runtime error on such a cast. This brings me back to me wondering why the direct inclusion of a circular reference isn't allowed, and in turn why the runtime cast to the self-referencing object does not result in an allocation failure - one of the two ought to be the case. I must think about this some more. The answer is probably quite simple... Thanks Yair! /Steen
Ah, now I understand, thanks . I assumed I would incur a runtime error on such a cast. This brings me back to me wondering why the direct inclusion of a circular reference isn't allowed, and in turn why the runtime cast to the self-referencing object does not result in an allocation failure - one of the two ought to be the case. I must think about this some more. The answer is probably quite simple... Thanks Yair! /Steen -
Which type should be a parent of what? I have this relationship, and none of those two clases currently have a parent:

-
Nope, a class can't have itself in it's data control. Since LVFile contains an object of LVFileRefs, LVFileRefs can't contain a DVR of LVFile. /Steen
-
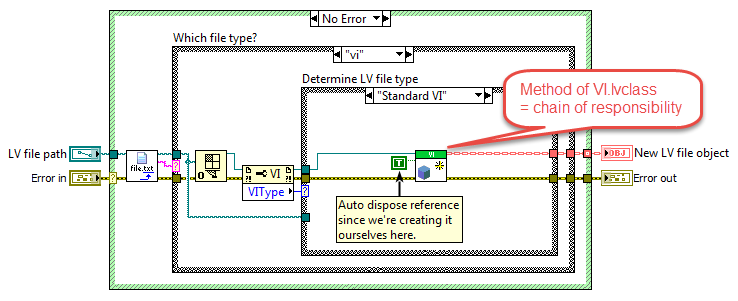
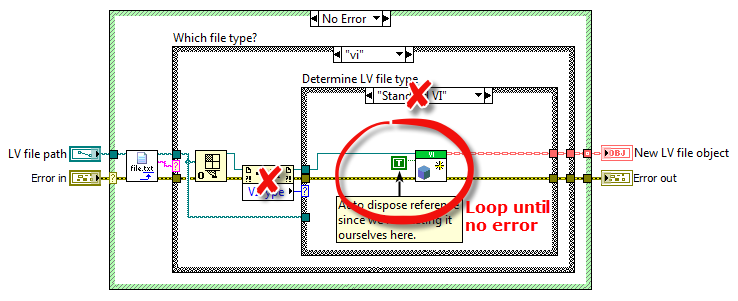
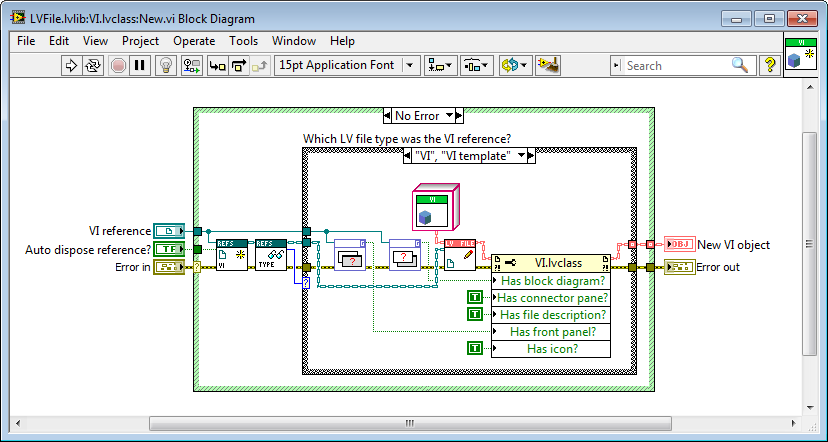
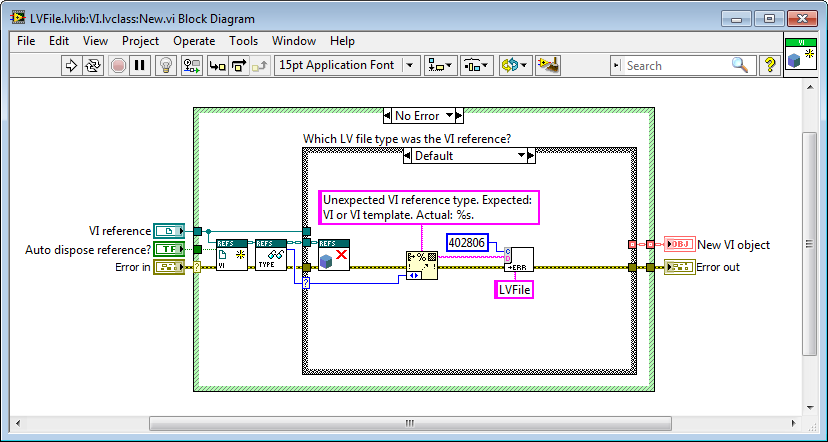
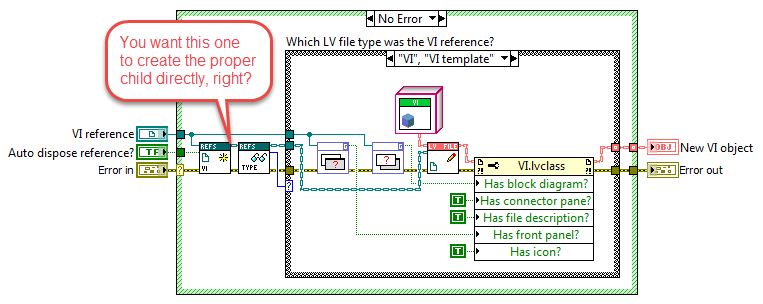
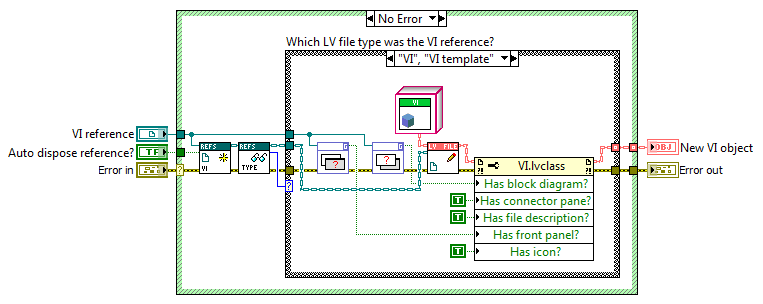
Since there is no constructor for LV classes an object can only "instantiate itself" by proxy, meaning an external VI that runs through the options filtering on errors from each child's "New" method or what it should be called. I actually do 95% that. Here is the frame from the NewLVFileByPath VI that attempts to create a VI child: If more of the responsibility should be left for the children, or really if less of the responsibility should be outside the child as nothing more goes into it, it would be by skipping the pre-filtering: But blindly rifling through each child's New methods in a while loop would be much more cumbersome to implement than what I have above, so this is one of those cases where convenient beats purest by far in my mind. That would mean that each child would have LVFileRefs in its data. That by itself would suggest to me that LVFileRefs should be in a more generic class (as it is now). Exposing the LVFileRefs member isn't a consequence of where in the class hierarchy that field exists, but instead a consequence of that data changing and should be written back into the object in question, whether that object being a child or the parent. It would be the same if the data member was a Boolean or a numeric. But I've stopped exposing LVFileRefs and have made LVFile accessors for it. That works rather well when using the API: Having the child contain its own refnum would be better from an encapsulation standpoint, but unfortunately DD requires the same data types on all instances' conpanes (so a "GetRefnum" method couldn't be DD and return a VI refnum for a VI and a Class refnum for a class). Without that ability (nor any good way of handling a more generic refnum on the user's block diagram) it remains simpler to have those refnums in the parent object. /Steen And just to clarify here is the "New" method of VI.lvclass where it returns an error if it's asked to instantiate a wrong object type: Good object type: Wrong object type (where it's also obvious where the "Type enum" comes in handy):
-
I've been there, and it went like this : 1) I actually started out with the LVFileRefs fields in the LVFile class. 2) I then wanted to make a subVI of the code that populated these fields to put at the head of the factory, as it's the same for every child. Let's call that subVI "NewRefs". 3) "NewRefs" had to have an object to operate on, and that object can't be the parent LVFile (if I've first instantiated a parent I can't cast that to a specific child later without copying - that wouldn't be the proper solution in this case). 4) "NewRefs" couldn't be a method of LVFile, as "NewRefs" essentially found out for me which child to instantiate. It would be foolish to separate the code that found out the type, from the code that created the object to contain that type info. It could be done of course, but I would basically have a subVI outside the LVFile class hierarchy which found out my child type, then passed out all its info (on 6 wires or in a cluster) into a write-accessor to identical fields within LVFile when the factory created the child. 5) Much better to encapsulate the code that manages type within a class of its own, namely LVFileRefs. LVFileRefs has a simple and understandable role: - It can eat one of four refnum types and find out which specific type it is (that dredded enum). - It holds that type and refnum, and the associated file path. - It offers methods to keep that refnum alive and to update the path if the file is saved or moved, it knows the rules of which type changes are allowed (ctl to ctt for instance, but not lvclass to lvproj), and can output sensible error messages when needed. 6) By encapsulating this into LVFileRefs I could add that class by composition to LVFile, which in turn let me use LVFileRefs to initiate the factory. As a bonus I can use LVFileRefs for any other purpose where I just need a LabVIEW file reference managed, without logging around the LVFile hierarchy. Update: Even simpler answer to your question: I have actually put those fields into LVFile.lvclass. They are just encapsulated in their own class to facilitate reuse and instantiation pre to the LVFile object itself. Bonus is encapsulation of associated methods, scoping of subroutines etc. Those are the benefits of composition in my mind. /Steen
-
I do implement a factory pattern already; "New" determines type and with an object of LVFileRefs instantiates the proper child of LVFile. You do not mean the "factory method pattern" as outlined by GoF? I don't want to use inheritance here, I tried that initially, and found it too inflexible. I actually tend toward composition more than inheritance when I have the choice. I displayed the factory in my first post. Note there are four of these factories, one for each supported base refnum type (Class, Library, Project, and VI): As I note above I think you want "New" to output the proper child object directly, right? I could do that, but then LVFileRefs would depend on children of LVFile, and thus couldn't be part of LVFile's data, and LVFileRefs wouldn't be reusable in any other context without hauling around LVFile.lvclass and all its descendants either. And I want LVFileRefs to be part of LVFile's data, as LVFileRefs' data fields are the cornerstone of each LVFile object. I've shuffled the functionality around many times over the last 3 weeks, and the current code division is what gives me the best flexibility when I build an application with these classes. I could probably do without the enum as type, but it hurts very little (it's just a short typedef'ed list of strings) and relying solely on parsing which child is on the wire (whether it being by DD or by code) is cumbersome in several situations. Mainly those situations where the programmer needs to tell a human being what is going on. Instead of trying to convey some meaning out of a class name I'd much rather pop a name from the types list to put into an error string for instance. OH! (EDIT): I just remembered the primary reason there is a type field; The type can change at runtime! There is only a Control.lvclass for instance, but that can have a type string of either "Control" or "Control template". If a control file at runtime changes into a control template (it gets saved as .ctt) I wouldn't at runtime be able to change the child on the wire. But I can change the type string. I won't rule out that the Type enum could be factored out downstream, but for now it's convenient. I often find myself battling between "Purest" and "Convenient". And I tend to spend only 10% of the time to reach "Convenient" than I would have spent to reach "Purest". And my "Convenient" version is probably 70-80% pure when come release day, so an acceptable tradeoff. I'm learning every day though, so please keep writing . /Steen
-
Hmm, I think the best solution is not to expose the LVFileRefs class at all, but instead create LVFile methods for LVFileRefs access. I've actually had that implemented earlier, but found it superfluous. Perhaps it is, but it eliminates having the same item referenced in two public objects. Usually for composite classes I prefer to have a "GetInnerObject" method on the owning class, and use the Inner class' methods on itself*. In this exact case I think I'll have to make an exception. *One gripe I have with this is that I can't easily protect methods of the inner class by setting an appropriate scope, unless I make the inner class a friend of its owner. And I don't like the friend paradigm too much, as I find that it couples the owner and the inner class strongly. /Steen
-
Bugger, I can't put a DVR to the owning class (LVFile) inside LVFileRefs' data control, since LVFile obviously has LVFileRefs in its data control . Let me think of a workaround here - first I'll have to get my head around why this restriction is in place. Is it perchance a recurrence thing? /Steen
-
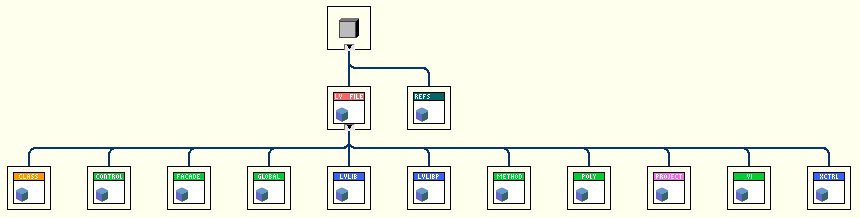
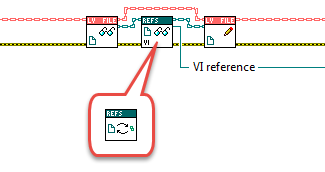
Hi, I would like to play an idea out to you about having a composite class put itself back in its owning object by a DVR. Is that a good or a terrible idea? Background I need a class that represents some different LabVIEW files, and which can offer some operations on those files; LVFile.lvclass. LVFile.lvclass has some children (LV file types) and it owns a composite object LVFileRefs.lvclass: LVFileRefs LVFileRefs contains the following: - An enum stating the file type. - A reference to the LabVIEW file (class reference, library reference, project reference, or VI reference). - The path to the file on disk (if it is saved to disk). - Info if the refnum was created by the object or passed in from the outside (used by the Close method). I need LVFileRefs as a composite object (instead of that data living inside LVFile) since New starts by instantiating an LVFileRefs object before New can decide which child to instantiate: One of the responsibilities of LVFileRefs is to keep disk path and file reference synchronized. This means that you could start out with a VI in memory for instance, and create an LVFile object for that. This does not yet have a File Path. If you then save that VI, then LVFileRefs will update its internal File Path field from <Not-A-Path> to the proper path. If for whichever reason the original file refnum goes stale, LVFileRefs will also be able to open a new refnum from File Path if possible. All transparent to the user. So LVFileRefs maintains a firm grip of the file whether it being in memory only or on disk, and it can tell you which type it is (some types take more programming to tell apart than others, and type can change as well). All stuff that makes writing apps that handle many different file types simpler. No DVR approach Normally I wouldn't expose a naked refnum to the user, but one of the features of LVFile is actually to serve the proper refnum, so in this case I do. That is currently done with accessors on LVFile, and then an LVFileRef method: Since LVFileRefs can update its embedded refnum it is important to write the LVFileRefs object back into the owning LVFile object (or else Close for instance wouldn't close the correct refnum, and several other issues). DVR approach Having to write back the LVFileRefs object is error prone - the user could forget to do it, and having to do it in the first place is irritating. I'd rather you could omit the write back step: The idea is to have LVFile embed a DVR to itself inside its LVFileRefs object, with which LVFileRefs can write itself back into its owning LVFile object with whenever LVFileRefs has updated itself. There shouldn't be any racing possible, as LVFileRefs is actually the representation of the LV file, and DVR access is mutexed. Am I insane considering this? Cheers, Steen
-
Old content remains in lvclass files
Steen Schmidt replied to Steen Schmidt's topic in Object-Oriented Programming
Yeah I know that this is the main reason behind the slow object writes we experience when comparing with clusters. Reads are fast, writes not so much. But all is relative. Ok, I now understand the reason behind choice of mutation history. I'm not sure I like that very much. For one it is still not guaranteed not to fail (the mutation history is only intact as long as I don't delete it), and it forces a lot of comparison and will result in slower than otherwise necessary load times. And it is inconsistent with every other object type in LabVIEW. Not that we shouldn't change just because something else is already implemented... I wonder what tipped the scales toward this design decision? Perhaps that classes were seen as containing large default data constructs primarily? It smells a bit like that shared variables are optimized for single point updates and suck for streaming (not comparing classes and SVs at all btw). I'd rather have the possibility to specify data with a 'static' keyword for instance, and only in those cases get this behavior. If I could do that I could decide when to trade in memory usage for performance and hard linking. /Steen -
Old content remains in lvclass files
Steen Schmidt replied to Steen Schmidt's topic in Object-Oriented Programming
So a built-in feature. I'd still like some official response on these topics then: - Exactly how does this help VIs adapt to a newer version? In my experience new versions of classes aren't more robust than new versions of clusters. And as far as I know clusters do not log around such huge sections of old state. - Is the default value of each data field really necessary to store? Or could we shed 1.1 meg from the class in my example and just store the name and type of old data members? - Is the history really necessary to drag with us onto new copies of a class? Typically I find I mostly copy a class to avoid doing some similar work again, not because I'm creating a new version of it. /Steen A) Perhaps worth investigating internally at NI then? B) Not something the average LV dev will or can do. And I have had devs ask me why their classes keep growing in size. /Steen -
Hi, I've decided to take the temperature on a known issue, that lvclass files retain knowledge of some of their old content after it's deleted. Proof For some reason I'm not allowed to upload lvclass files, so I'll describe it instead (using LV2014SP1): 1) Create a new class and save it on disk as class1.lvclass. No member data nor methods, file size on disk is 8 kB. 2) Add one piece of significantly sized (to easier see the issue) member data, I added a 1000x100 array of DBL (with random default data in it). Save the class again, and now class1.lvclass is 4604 kB (why so much, should be around 1000 kB?). 3) Delete all member data again and resave the class. File size on disk is now 1171 kB, I'd have expected 8 kB. 4) I can't ever get rid of that extra data in the lvclass file, not even when I "save as" to create a similar class. Questions A) What's the reason behind this issue? B) Is there any way to really delete stuff from a class file, or is the only way to recreate every class from scratch if you want something truly gone? C) Is there a list (perhaps internal to NI) of which problems this issue causes? Here I'm talking about stuff like this and numerous other threads about class data suddenly not being updated or member data or methods not being called correctly with DD. Cheers, Steen
-
Just registered. Looking forward to seeing you there :-) Cheers, Steen
-
"Does VI have block diagram?" at runtime?
Steen Schmidt replied to Steen Schmidt's topic in LabVIEW General
Yeah, I know Brian, I was referring to the direct REdLoadResFile approach as that takes a path on which it croaks if that path is within an exe. /Steen -
"Does VI have block diagram?" at runtime?
Steen Schmidt replied to Steen Schmidt's topic in LabVIEW General
Nope, not a specific use. The thing is that the built-in way works perfectly well in the IDE: and It's only under the RTE that we need an alternative solution. Half the time under the RTE we're accessing wild VIs (dynamically loaded source distribs typically), the other half we're accessing VIs within the exe. Within the exe doesn't work that smoothly. Yes, I could grab those bits and shove them through REdLoadResFile through a proxy... But my current use case is in the IDE (as we're talking about an edit workflow). I just like my classes to work in as many worlds as possible, so it pains me these won't work under the RTE . NI US is looking into what's wrong with VI Server here. They'll probably end up fixing the documentation instead of the function . /Steen -
"Does VI have block diagram?" at runtime?
Steen Schmidt replied to Steen Schmidt's topic in LabVIEW General
Yes, and I'll likely use this approach until a better one emerges (e.g. when VI Server gets fixed to support this natively as the doc suggests it should be able to). /Steen -
"Does VI have block diagram?" at runtime?
Steen Schmidt replied to Steen Schmidt's topic in LabVIEW General
Thanks Jack, Brian and Stinus :-) Sure, raw VI file examination will work (and thanks for the work you did on this). I'd rather avoid it, as the file format will change and thus we'll have some work cut out for us to keep up with different LabVIEW versions. Stinus, your VI can't grab a subVI by path inside an executable (I've attached a project that demos this). This might be due to something external to LabVIEW, didn't put too much thought into it just now (I'm on vacation ;-). I'll take a look at it again later. Take care y'all! Cheers, Steen PanelsPresentTest.zip -
Hi, I'm looking for a way to determine if a VI has its block diagram or not in the runtime engine. Assume I have the VI reference. In the dev environment it's no problem, but the runtime engine does not support either of these methods: The latter should be supported in the RTE, according to NI documentation, but in fact it is not. Any clever ideas short of examining the file bits on disk (which is a flaky approach)? Cheers, Steen
-
'Draw Text' bad font anti aliasing
Steen Schmidt replied to Steen Schmidt's topic in LabVIEW General
I have to end up with a jpg on disk, and the 3D picture control renders the text with the same old-school aliasing as the 2D pictures. The aliasing happens already in the 'Picture to Pixmap.vi'. /Steen -
Hi, I just attempted to use LabVIEW (2014) to make a few custom JPEGs - the customization being definition of image background color and adding some text. Then I realized that the 'Draw Text at Point.vi' and relatives really does a bad job at font anti aliasing. Comparison with a simple graphics editor (zoomed in view of a very large capital G): LabVIEW 'Draw Text at Point.vi': Paint.Net: And yes, this is very noticable even for smaller text sizes. Question: Has anybody made any good graphics creation toolkits for LabVIEW, or do I have to live with these built-in anti aliasing algorithms from 1990? Bonus question: How on earth does those image VIs font point size correlate to the font size in non-LabVIEW image editors? In Paint.Net I used font size 216, while I had to use 350pt for font size with 'Draw Text at Point.vi'. In Paint.Net the image was 96 PPI, and I reckon LV does 72 DPI only (Windows 7 was set at 96 DPI with 100% scaling). So I would've expected to set the user defined font for 'Draw Text at Point.vi' at 288pt (216 * 96/72) to get the same size letter, but I had to go up to 350pt in LabVIEW to match 216pt in Paint.Net. What gives? Cheers, Steen
-
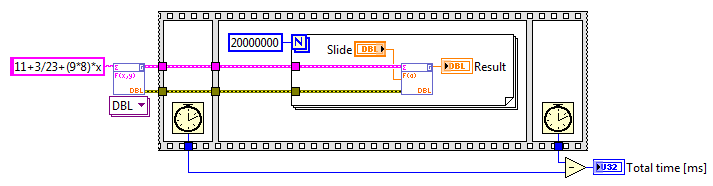
Hi, Cool with the general GOLD parser, but performance wise it's very slow in the specific case. One specific case being math expressions like your example. For that you could use a specialized toolkit like Expression Parser, which is thousands of times faster. Example with your expression "11+3/23+(9*8)*x": Loop with Parse + Evaluate: 124 us/iteration. Typically you'd parse once and then evaluate multiple times with differing x-values; Loop with Evaluate only: 305 ns/iteration. Add to that the vastly larger feature list of Expression Parser (I don't know how that would affect the GOLD parser): - More than 260 math functions and constants supported. - Supports any number of variables of any name. - Supports VI Registers. - Reports overflow if that occurs during evaluation. - Supports all 14 numeric data types that LabVIEW offers, including complex evaluation. - Offers special expression control like conditionals, piecewise defined functions, pulse trains, and defining your own custom periodic functions. - Supported on desktop and real-time. Not to steal any thunder, but parsers aren't easy to make performant. Cheers, Steen
-
Totally non-valuable addition of characters here, I know, but it's mindblowing that an action such as renaming a class can lead to so much headache. Class-editing is broken in so many major ways in LabVIEW. I know of people not using OO in LabVIEW for this exact reason - one of them is an employee of mine, and I'm actually forcing him to give up his resistance and just suck it up. But that's no fun I tell you /Steen
-
Do you know where this recording can be found? Mark doesn't seem to have the US CLA Summit 2014 videos online currently... /Steen
-
Beautiful discussion - this is one of the few things I find really awful about LabVIEW, and a thing I really really hope will change. For deployment LVLIBP can work, but not for dev tools (which I do most of involving libs) as they need to be cross-platform and cross-version. LLBs are out of the question for me because they're so arcane. Everybody has mentioned all the pros and cons of these files except for one thing: Security. I use LVLIBs for three features, here in the order of importance (for me): 1) Namespacing. 2) Security against someone else replacing my code. 3) Scope. I wish LVLIBs also had this fourth feature: 4) Single file on disk. Namespaces Generally I can't get manual namespaces to work. The teams I work in aren't structured enough to adhere to one convention, and they are typically those middle-of-the-road programmers that have enough experience to boost their self confidence but not enough to make them put their egos aside and stick to the plan. Something like that. I want namespaces in LabVIEW, and I hate that I have to stick my VIs into a library to get that - or I hate what I must lug around as well when I just want namespaces. Namespacing through the physical file name also has its advantages - one being that you can identify a VI's purpose without the context of its library. But namespacing in file names create long file names, and it creates long paths due to all the duplicate information (the file name being almost the sum of folders leading into the file location). And we have some limitation to maximum path length in characters when we build executables and load VIs dynamically (~230 chars IIRC). Security For many applications it's unsafe if someone external to the dev team can just replace a file in your deployment and either change functionality or snoop into your code. Thus it's a great thing that libraries bind their members so tightly that this isn't possible. Scope I don't use this as much in LVLIBs, but I do in LVCLASSes. But what about the load everything feature? Besides the physical distrib size, the load time, and the mem usage issues, there is another really bad consequence of this: the "Only one file in memory with any given file name" feature. I feel the "contract" that LabVIEW imposes on us that a library will be loaded into memory, always together with all its members, is the single thing that stands in the way of two distinct modules appending functions from the same namespace (LVLIB) into memory. This issue: - You have A.lvlib that owns a.vi, b.vi, and 100 other VIs. - Someone has built a source distrib, Module X, that uses a.vi of A.lvlib. - Someone else has built another source distrib, Module Y, that uses b.vi of A.lvlib. - Since both source distrib builders wanted their modules to be as small as possible they made their build script such that unused lib member functions were stripped from their build. Now you make an application that must load Module X and Module Y, but it can't. Your app loads Module Y first, and Module Y loads A.lvlib into memory. This version of A.lvlib only has one VI in it, namely b.vi. Now your app attempts to load Module X, but Module X fails to load, as it can't load its own dependency a.vi. It's not allowed to do anything with its own copy of A.lvlib that references a.vi, as there is already a file called A.lvlib loaded. I'd guess that everybody here has experienced the above and works around it on a regular basis. If LVLIBs weren't so atomic this issue could be fixed by allowing gradual loading of library member functions. Then Module Y would just load b.vi, and Module X would later load a.vi and merge the namespace. If on-request loading was supported that would already be built in. Of course there would need to be certain checksums etc, but you wouldn't have to jump through hoops to make several source distributions actually work together, with a potential rebuild of ALL modules when you add a new module. Does it even matter for smaller reuse tools? The opinion that the issues we're discussing here are only relevant for 8000 VI applications, and that we don't run into them on a daily basis, was aired (Neil perhaps?). I think this issue is an armed grenade from the first library we make - it might well first blow up later, but eventually we reuse something or stuff our lib into an executable that loads two modules, and then we're presented with two options, both of which cause tremendous headache: either 1) careful design and re-design of the application as it evolves, or 2) total redesign of our reuse components (and how much reuse is that?). Case in point; We (GPower) has a bunch of reuse libs for public download. They are GPArray.lvlib, GPMath.lvlib, GPString.lvlib, GPError.lvlib etc. These libs are used by many people around the world, so need namespacing as they are quite low-level and common. They are reuse tools that support a large number of LabVIEW datatypes, so they are also full of polyVIs with many many instances of almost identical functions just with different datatypes for inputs and outputs (also slight variations in realization, but that's not the heavy part). Not too big a deal on a lib by lib case, you hardly notice this in the IDE, even though some of the libs have maybe 200 VIs in them (they are small). Now we've made a new toolset, Expression Parser, which uses ~10 of our own libs. When you drop the first VI from the Expression Parser toolset into your block diagram, LabVIEW loads almost 1200 VIs from disk! Why the h*** is it designed to do that? Expression Parser is also heavily inlined and recursive, so on most dev machines you notice - let's be frank. Afterwards everything is fine, but it's not necessary to load all that before you need it. Often times you won't even need 30 of those VIs. Building the VIP for Expression Parser takes around 20 minutes. Building an executable containing Expression Parser will never get below ~10 minutes. For those reasons. That is totally unecessary. So, I use LVLIBS, but I hate them. I can't live with the alternatives currently though, so I jush push at NI all I'm able to, to get some of this moving in a slightly different direction. I hope it eventually will. /Steen
-
That is quite clear what happens, unless there is a bug I'm not familiar with? Both event structures will receive the event, so you better be prepared to handle that event at both structures :-) What can really make things odd is when "Lock panel (...) until the case for this event completes" is enabled in an event structure that doesn't run, and it receives a UI event. Even though that ES isn't running it'll still lock the FP from seemingly far away... There's no way to probe your way into this. I set up stuff like that to test potential employees, to see if they have the LV skills to fix such a bug. /Steen