GregFreeman
-
Posts
323 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by GregFreeman
-
 Alright, this has now happened enough to me that my forehead is starting to hurt from banging it against my desk. I know everyone here gets design exactly right the first time, so maybe this is never an issue for you guys . We changed our architecture a bit, which meant our "process" classes now needed to be given new names because their responsibilities changed slightly, so the original names didn't make sense. Renaming a class from LabVIEW, no problem, F2 works wonders. But now it's contained on disk in a folder that most likely has the old name. When I rename that folder, stuff often goes haywire. All the methods "can't be found" so I have to open them and save them one by one in their new location (even though they are already there - LabVIEW is just looking for a folder that no longer exists - so I just save over them). Then, God forbid you renamed the class outside the project on disk so the LabVIEW project couldn't update the name of the class it was pointing to. At least LabVIEW is nice enough to let you browse on disk to select the proper class in this case...which has a new name and won't be loaded by LabVIEW anyways because it isn't the class it's looking for. If I remember right, I think if you rename the class in the project, close the project, change the directory name on disk, then open the project it will search for the class with the new name and you can just point it at the new location. I'm not entirely sure if these are the exact steps. Anyways, does anyone have a typical workflow for renaming a class and where it exists on disk (wtf, a workflow is needed for this?)
Alright, this has now happened enough to me that my forehead is starting to hurt from banging it against my desk. I know everyone here gets design exactly right the first time, so maybe this is never an issue for you guys . We changed our architecture a bit, which meant our "process" classes now needed to be given new names because their responsibilities changed slightly, so the original names didn't make sense. Renaming a class from LabVIEW, no problem, F2 works wonders. But now it's contained on disk in a folder that most likely has the old name. When I rename that folder, stuff often goes haywire. All the methods "can't be found" so I have to open them and save them one by one in their new location (even though they are already there - LabVIEW is just looking for a folder that no longer exists - so I just save over them). Then, God forbid you renamed the class outside the project on disk so the LabVIEW project couldn't update the name of the class it was pointing to. At least LabVIEW is nice enough to let you browse on disk to select the proper class in this case...which has a new name and won't be loaded by LabVIEW anyways because it isn't the class it's looking for. If I remember right, I think if you rename the class in the project, close the project, change the directory name on disk, then open the project it will search for the class with the new name and you can just point it at the new location. I'm not entirely sure if these are the exact steps. Anyways, does anyone have a typical workflow for renaming a class and where it exists on disk (wtf, a workflow is needed for this?) -
Understandable, just wanted to throw it out there.
-
We have something but it doesn't go to a native windows log; it goes to our own log. It runs as a service and grabs messages via UDP, so messages can be published from RT and Host PCs, and logs them to files. Also comes with a standalone GUI and has different levels of customization for message filtering, along with an ActiveX control and API. Does this sound like something that would meet your needs? I can't promise anything because I know we wrap this into bids to customers so it wouldn't be freeware. Either way, I'd like to see if there is some demand for this type of thing out there.
-
When I heard this, my first though was "I knew it." The software developers at my previous company were all saying 'there's no way this is mechanical, it's software.' Sure enough, 3 years later, they were proven right.
-
I actually came here to look for answers (and possibly post a question) related to this very thing. I found myself moving methods around to try and get them into a common place which made sense (to no avail). Ironic that this is the first thread in the OO section right now. Just putting in my $0.02 that you're not the only one feeling this way.
-
Paul, the likelihood of misuse is pretty small. Most of my coworkers are CLAs who are very competent programmers, but at the same time, OOP is slowly being propagated throughout the company and is a relatively new concept to many of them (myself included, but some much more-so than others.). I have been lucky enough to get more projects than most where I can really practice with it, so I have been driving much of the transition effort. That said, my primary concern is that it's quite easy for someone with limited OO experience to abuse getters/setters, so if I can enforce how and where they are used, it may cause less potential headaches in the long run. I'm trying to see into the future for possible issues (always a tough thing to do!). The above situation may not even be a problem, but I still think it is something worth considering.
-
I know, I meant I think he must have been confused due to my post that was completely irrelevant in this thread . Too many LAVA tabs open at once! Can't post a diagram right now, but yes, I think this sums it up and you're understanding what I'm doing (whether this method is right or wrong I don't know yet!). The channel class has a write accessor. When the configuration class method "generateChannels" is called, it should look at its configuration info typedef, and generate all the channels, setting the channel's properties. What I don't want is somewhere else in my application, someone coming along and dropping that accessor and updating certain private data in the channel class. For example, I don't care if they update a channel's waveform. What I do care about is if they change the channel name or physical channel it respresents!
-
C#/Measurement Studio and TCP with LabVIEW
GregFreeman replied to GregFreeman's topic in Calling External Code
Thanks, I think we are going to go the JSON route, especially since those VIs are now built into LabVIEW 2013. -
Paul, you must be super confused. My response was supposed to be to another thread. I agree with your configuration idea, and I pretty much do this too. But, my configuration class has methods that take it's configuration data and generate objects that will hold that data (maybe herein lies the problem). Let me give an example of what I'm doing and I'm more than open to other ways of doing things. So, in my software there is a typedef cluster of all my channel configuration info. This cluster is held inside the channel configuration class. Now, I have a method in that same channel configuration class that is "generate channels" which takes all that config info and builds an array of channel classes and returns it, giving necessary info from its typedef'd cluster to each channel class that is created. In my application, the only class setting certain parts of the channel (such as which physical channel a specific instance of a channel class is using) should be the configuration class. If a channel class has been created and given its physical channel name by the configuration class, it should not be able to be updated anywhere else in the application. Does that help clarify?
-
So, I'm seeing some weird behavior where I will deploy code to RT and run, then I'll make some changes and it will prompt to save and redeploy a class library. There is no broken run arrow initially, but the deploy will error and when I click OK, I will then have a broken run arrow. I have traced this to classes that have broken VIs that are either 1) unused or 2) diagram disabled. If I close and reopen the project, the issue goes away and I can deploy. Then, sometimes it goes through this cycle again. It's not that big a deal, but is a bit of a hassle. Anyone know the reasoning for this and/or have any suggested workarounds? Edit: I should add this isn't a build and deploy of an EXE, but is just clicking the run arrow in the development environment.
-
Thanks, I think we are going to go the JSON route, especially since those VIs are now built into LabVIEW 2013.
-
I have a customer that is writing an application with C# .Net and measurement studio. Can anyone give advice on flattening and sending structures over TCP/IP to LabVIEW, and unflattening them on the other side? Is there a relatively easy way to accomplish this, or will we have to write my own flattening/unflattening methods? I know we can use shared variables with measurement studio, but I don't like the idea of this. Some of the data is config data, and there is a chance it could be overwritten before we read it. That combined with the fact that I've had painful shared variable experiences means this is not really an option.
-
I have a configuration class that loads a configuration and creates a bunch of channels. I'm having a hard time deciding if accessors like "write physical channel" should be community scoped, so the configuration VIs can write to them, but nothing else can. Or, should I just make these things public? It seems community scope would be the safest option, especially for members that shouldn't be changed once reconfiguration is done, but I'm curious if there are any drawbacks to this design, or things I should take into account when deciding community vs public.
-
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
Paul, this is relatively minor, but I'm curious how you manage your enum and who owns it. Do you do anything for protection such as lvlibs, or just leave it global and define "it's to be used here" purely by convention? -
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
I've still been digging in parallel with implementing. Check it out, Paul...it already does exist on a server somewhere! -
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
To follow up, here are some additional posts on this topic, most likely related to what Paul talked about in his NI Week presentation. -
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
I pretty much understand the flyweight pattern, but as it relates to the state pattern I am a bit lost. Is the idea here that a list of states is stored in the context and if the state exists already, the existing state is returned, otherwise a new one is created? -
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
I'll look into this. I'm not using AF so I should be able to adjust accordingly. -
Returning to state where you left off
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
Basically, I have a base state class, and one of the child states is RunningTest, which sequences through a bunch of steps. I have an array of steps inside the RunningTest class private data. If I'm on step x of 100 and some limits go out of range, we go to another state which adjusts the analog outputs until things are operating normally again, and if this is successful, I need to return to the RunningTest State at step x and continue running. -
I have an application where I am using the state pattern. I'm having an issue with ownership of a state which I may want to return to at a later point. For example, I have a state (call it state1) that needs to do some arbitrary number of things. However, if certain events happen, that state will be interrupted. I go to another state which could go to another and then another etc, but at some point it may need to return to state1, where state1 left off. I can't just create a new instance of state1, I need to reuse the previous isntance. So, my question is, where do I manage the life time of this state1 instance when it's not being used? I could set it in the private data of the next state (with a cast, obviously, because I cannot have a child class in a parent class's private data). But, if the next state doesn't use it, because it determines it needs to go to some other state, then I have to pass the state1 object into this next state...and so on and so on until I need to return to State1 at some point. Now, it seems I could be passing the management of this object from state to state, just in case some other state uses it. Feels ugly. I have to assume there is a better way?
-
Mind. Blown. So, awesome, in depth response AQ, but I don't think the benefits outweigh the increased implementation time and potential support of this all. I have stuck it in my back pocket for future reference, but when I sit down and think about the ramifications of a potential incorrect input being wired to the connector pane and getting a run time error vs the implementation time of the above suggestions, I actually feel the right decision is to just deal with and handle a run time error. Of course, there is always the argument that putting in the upfront time can save you run time debugging down the road, but since it sounds like these implementations all have their own potential drawbacks, I'm kind of just picking my poison.
-
Is this purely for read accessors? Why not massage the data when you write it, and store it in that state, rather than massaging it on the way out? Of course, this just moves the issue to the bundle/set method instead of the unbundle/read method. At some point, I think you can only get so much compile time protection, and protect a developer from themselves so much I am of the opinion (and this is just my opinion) that this would be a bit of an unnecessary enforcement, since I think you could just call the member variable something more descriptive like "scaled data" rather than "raw data" and store data in the scaled state. I think for a most developers this would be enough to imply what needs to be done. That said, I can see why this could be beneficial. On the other hand, since this is only the case for accessors when used inside the class (private accessors?), it implies some enforcement over what a class can do to its own private data, which seems a bit off. Edit: the more I think about this, is this a code smell for the possibility that the data you are accessing in this class should be moved to another class? Then, the initial class could hold the new class in its member data. The new class could provide public methods or accessors that the current class would now be forced to call in order to set and "massage" the data? I know this doesn't directly answer your question, but I think it would resolve the enforcement issue you're having (i think...)
-
Yeah, I know I can use to more specific. Was just wondering if I could avoid any run time type checking also. Looks like that may be unavoidable.
-
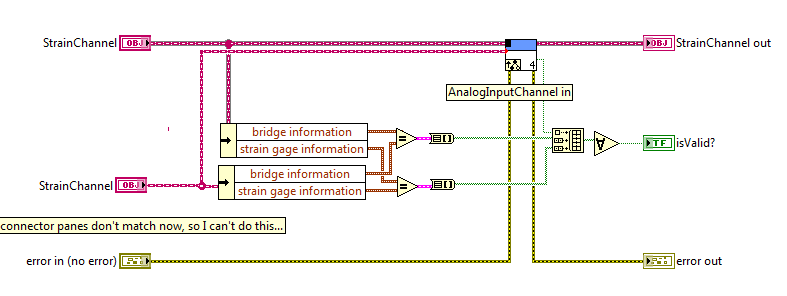
cross posted: http://forums.ni.com/t5/LabVIEW/Compare-parts-of-two-child-objects-and-use-call-parent-method/td-p/2530980 I am trying to validate if two child objects can be grouped together, based on some conditions in their private data. So, I would like to have a "checkIfValid" method in the parent class that has both the settings must override and must call parent method. However, I am running into problems because the connector panes must match. The following VI gives me a broken run arrow. Is there any way to implement what I want? A picture is worth a thousand words so here you go. Is there any way for me to do this comparison, while using DD to force the call parent method?

-
I am doing design and want to show the following in a UML diagram: Method is "GenerateNextX" and it returns class "X." X won't be held in private data, just stuck in a queue to go elsewhere, where it will be immediately consumed. There really is no single object that is holding onto this "X" object. So, where in my UML do I define the "X" class? It seems aggregation and composition don't really fit, so I can't stick it on an existing diagram, as it relates to another class. But, I do want to define the class somewhere.