GregFreeman
-
Posts
323 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by GregFreeman
-

Library & Class Naming Convention Advice
GregFreeman replied to MartinMcD's topic in Application Design & Architecture
Oh, I do but my "actor" will hold that device driver in its private data and sometimes rather than unbundling the device specific class from the actor and doing the work right on the actor's block diagram where the message comes in, I will put the delegation/unbundling to the specific driver in a private subVI of the actor and pass in the message data. This gives me a subVI per message received in the Actor. Maybe is an unnecessary wrapper, but for one reason or another I have been known to do it. If it's a bad habit or obfuscates things (which it may), please let me know. It is a habit that can be easily broken. Now I do! -
Library & Class Naming Convention Advice
GregFreeman replied to MartinMcD's topic in Application Design & Architecture
I agree with the get and set just because often I'm dealing with hardware and something like Read <name> I feel implies actual communication with the device where Get <name> implies an accessor (as it commonly does in other languages as well). In fact, I wish they'd change the default name to get and set when creating/savings accessors. One follow on I'd like to ask is how you guys handle naming of methods when public/private have the same name. For instance, I may have a public method called "Read Device" which really just sticks a message in a queue, and then a private "read device" method that does the actual work. But if I name them the same they can't be in the same directory on disk. So now this gets into directory hierarchies on disk which may be a whole different animal. Thoughts? -
Application Task Kill on Exit?
GregFreeman replied to hooovahh's topic in Application Design & Architecture
How large is the application. Would it be possible to post? -
Application Task Kill on Exit?
GregFreeman replied to hooovahh's topic in Application Design & Architecture
Normally, something like this would imply a memory leak. Use task manager to monitor your memory usage over a couple of hours; is it gradually increasing? Are you opening a reference repeatedly and not closing it? This can easily happened with "named queues" if you're not careful. -
I was curious when you guys are encrypting files, where do you store the key? I have heard if you open a LV Binary in a hex editor you can relatively easily read string constants, so hardcoding in an encryption key may not be the best idea. In general, I am not worried about this happening as I don't need anything "super secure", but I wanted to get other's opinions/solutions.
-
Dynamic Dispatch: Bug or Expected Behavior
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
Glad to be your guinea pig -
Dynamic Dispatch: Bug or Expected Behavior
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
This was a programming mistake, not something intended. I am assuming the wrong method got pulled out of the class and dropped on the block diagram accidentally. I know we can only protect ourselves from ourselves so much. I just wanted to be sure that this was expected behavior because it seems counter-intuitive to the "standard" expectations. I assumed the reason everything compiled fine had to do with DD and some sort of specific case (such as the one you mentioned) so it is good to have that clarified. Darin, are you running this on a PC? I'm curious if not seeing an error dialog was due to it running on RT. -
Dynamic Dispatch: Bug or Expected Behavior
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
Darin, I have had similar issues as well (also yesterday). But, I can't be sure they weren't attributed to the "crash" itself. The problem seems to have gone away after I fixed it. This is a program running on RT and my top level VI would be unbroken, I'd click run, it would error in deployment and a static dependency VI would now be broken. However, the top level VI still wasn't! When clicking the broken run arrow, the dialog was blank as well. Closing the project and reopening resolved the issue, as well as rebooting the RT. Again, this may have been due to initially deploying with this recursive VI and crashing, as I haven't seen the problem since. However, I have seen this sort of behavior in other scenarios which always, yes, sucks. -
Configuring Git to work with LVCompare and LVMerge
GregFreeman replied to PaulL's topic in Source Code Control
1) TL;DR - Only once per week or so; < 5 VIs conflicting, usually. Not as often as you may think (or at least not as often as I thought) when I started using DVCS with LabVIEW. I am sure separating source from compiled alleviates some of these issues. Also, we try to delegate "actors" to different developers, and avoid static dependencies from within actors (i.e. send data to a mediator, not directly to another actor). This ensures the processes don't touch each other. The problem arise more when two actors contain the same class within, that both developers may need to modify. Even so, I'd say on average I run into conflicts once a week, with no more than 4 or 5 VIs in that conflict. The only thing that is a bit of a pain is in order to keep things in sync, we find ourselves merging feature branches back into the develop branch quite a bit so everyone can pull changes into their local develop branch and rebase/merge their feature branches. We do these merges into develop even when a feature isn't complete. By merging feature branches into develop more frequently, and updating local feature branches via rebasing on, or merging in these commits from develop, it helps limit the number of changes per commit. Therefore, it limits the number of potential conflicts. But, it certainly clutters up the repo by merging in the same feature branch multiple times instead of once when completed. I could see myself running into wanting to diff more often if we truly followed a model where feature branches weren't merged into develop until fully complete. Note: This may also imply our feature branch scope is too large, but the two things are not mutually exclusive. We're working on it. If anyone has questions/comments on that workflow let me know. 2)Merge - about as often as a compare -- maybe a bit less. Sometimes a compare reveals I can just select one file over the other to resolve the conflict, no harm done. 3)In my opinion, diff is a difficult thing to solve in a graphical language, and others may not agree but I find the diff tool pretty decent. Sure, sometimes there are things that aren't represented well (such as when a case has been deleted from a case structure) but it does an OK enough job that my mind can fill in the gaps. YMMV and opinions may differ greatly. I haven't used the diff tool a whole lot, so someone with more experience may be able to provide better feedback here. I think it's the merge tool that opens like 3 windows inside one with splitter bars dividing them or something? I may be wrong here. I've only used it one time at a customer using Mercurial a few months ago so hopefully I'm referencing the correct thing. I found it terribly hard to navigate around the windows etc. I think this tool has bigger issues than the diff tool. It certainly resulted in more Hope that provided you, generally, with what you wanted to know. -
Configuring Git to work with LVCompare and LVMerge
GregFreeman replied to PaulL's topic in Source Code Control
I got about as far as you as well, but couldn't really get things to work. Below are some relevant posts which you may have seen already. I can tell you what I've been doing, which is a bit tedious but has worked ok. I could see it becoming more of a problem if there were lots of changes made, but we have been trying to commit and sync up frequently so that things aren't too out of whack. Sometimes it's enough for me to just visually look at the before and after (selecting them from within Source Tree) and tweak what I need to in my copy, then choose mine to resolve the conflict. One drawback here is dependencies of the remote copy of the VI will be missing, Another thing I have done is cloned the repo twice on disk. I think this is essentially what the first like I posted does for you, but I'm not positive. I checkout the base branch in one clone, and my feature branch in the other. I then do a diff on the conflicting files, resolve diffs on disk in my feature branch copy, then select my copy in Source Tree to resolve the conflict. I should also note something that has caused some headache a couple times is that if you rebase, the first thing it does is checkout the base branch. So, when resolving conflicts, "theirs" is actually your feature branch copy, because the branch you have checked out has changed somewhat unbeknownst to you as part of the rebase. Anyways, I know this doesn't answer your question directly, but maybe these things provide a bit of a work around. At first I was a bit wary of DVCS, honestly, but now that I have played around with git and am becoming more comfortable with it, I must admit I really quite like it. Off topic, but let me know if at any point you would like to compare workflows and what has worked for us/you guys. I know we've touched on this before in another thread, but now that I am more familiar I have more ability to contribute. https://github.com/joerg/LabViewGitEnv https://decibel.ni.com/content/groups/git-user-group/blog/2013/02/19/git-and-labview-merging -
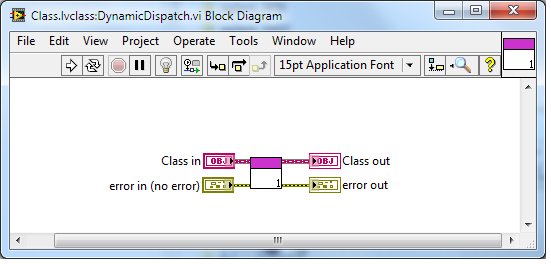
Dynamic Dispatch: Bug or Expected Behavior
GregFreeman posted a topic in Object-Oriented Programming
I ran into an awful bug in my software today, where my application would start then just randomly stop. No crash of LabVIEW; it just stopped running. I traced it back to the following: A parent class's Dynamic Dispatch method had an instance of itself on its block diagram. The method was not set to reentrant execution, but also did not give me a broken run arrow. This caused the VI to recursively call itself until the application died. Is there a fundamental reason this is allowed (something to do with DD perhaps?), or is this an oversight in the compiler? I haven't tested with static methods, but I assume that would cause a broken run arrow as regular VIs do. DynamicDispatch.zip
-
This works, I can probably just make my own write accessor which has the expected type on the connector pane and coerces to the more generic class within the write method, no?
-
I am curious how others have solved the problem of holding a class of hte same type in its private data. For instance, a window class that needs other windows in its private data. I know how to do it; I would just like to see if we can have a discussion on what people have found to be the best method for handling this and why. You obviously can't have a by ref class in the "more generally accepted sense" of a DVR inside the class's private data. This still results in recursive loading a compile time error. I have seen storing the aggregated object in a variant, or creating a DVR of the object's type and storing it in the private data of a class. Are there any potential benefits or drawbacks to each? Any other methods you have found to work well?
-
Issue Parsing HTML
GregFreeman replied to GregFreeman's topic in Remote Control, Monitoring and the Internet
Whatttt? I didn't crash at all on mine and I ran lots of times. Must be your Mac (disregard if running in a Windows VM...which it looks like you are). This program I'm trying to write is generally simple. I don't actually have to modify the HTML, just pull a couple numbers out from the table. I was just open to modifying the HTML if there was a simple change that would make it compatible with the LabVIEW DOM Parser which wouldn't effect the data I needed to grab. That said, I will probably go the regex route, but it will be a good exercise for me. So, I'll post back if I get stuck on that. With all do respect, I'd like to forge (see: hack) ahead on my own for the time being, for learning's sake. -
Issue Parsing HTML
GregFreeman replied to GregFreeman's topic in Remote Control, Monitoring and the Internet
This will be on a windows machine, maybe I can use .NET in LabVIEW, but we'll see. Is there something about regular HTML that itself would allow a generic parser not to be written and it's not worth digging for one? If that fails I'll just manipulate the string myself (ugh). -
I'm trying to use the DOM parser in LabVIEW and the HTML I'm trying to parse is throwing errors. I am wondering if someone can help me work around this. The device that is publishing the HTML is quite old and my knowledge with regards to HTML is limited. I've played around for a bit and been unable to get it to work so I figured I'd some here and see if anyone could troubleshoot. I'm open to minor manipulations to the HTML to get the parser to work, so feel free to modify as needed. test.html ParseHTML.vi
-
Reusable connection process
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
I agree. However, the problem I run into here is I don't want to reply directly to the client. I have a mediator which manages a list of all connections, error handling if a connection has been lost, etc. This mediator exists because my opener, readers, and writers are all separate parallel processes. So, the reply will actually go through the mediator, at which point the mediator should be the one distributing the message to the proper client via this reply method. The only way I can figure to get this safety (force the reply to go through the mediator) is make the mediator a friend of the client, and make the reply method community scope. Again, I reiterate the reason I want this safety in case it is unclear. If the connection closes, I will get an error because the transport mechanism to the client will no longer exist. So, if I reply to the client directly, any loop that wants to send a reply now has to have error handling for this case. By forcing things to go through a mediator, I can put all this handling in a single location. -
Reusable connection process
GregFreeman replied to GregFreeman's topic in Object-Oriented Programming
My concern was if I package the TCP refnum in the request message it needs to be taken out of the request message to be packaged in with the response message. That means I'd need a "getter" which I don't want because it would expose the reference itself. I suppose I could wrap the reference up in a class and pass that class holding the reference around, not exposing any methods that allow direct access to the reference itself. -
So, i currently have a reusable connection process and you can easily plug in override VIs for open/close/read/write and basically use any connection type you want (UDP, TCP, VISA etc). As it stands now, our process handles multiple connections but if a message is sent out it is sent to all client connections. We are going to be adding some functionality for request-response which will require an outgoing response message to a specific client connection that made the request. I am not sure how to handle the managing of which connection sent the message and needs the response. One idea I had was give each connection an ID, when a request is received, pass the request with the ID to the loop which processes the data, then sends the result back with the ID so the connection process knows where to send it. I could also use the refnum but I don't like the idea of other processes having access to the connection references, even if it's protected by being wrapped in a class, because I have to add in error handling for lost connections outside of the process which already has the code to manage them. So, I'm curious how people have handled this and if my approach seems reasonable.
-
Jack, can you go into more detail about why you would like to see UE behave more like queues with regards to registration? Is it purely so that communication mechanisms all behave as one would expect or do you see some sort of functional advantage to this? I am assuming the former, but I just wanting to clarify.
-
Ours are the same size. Six would be a relatively big team in fact. We usually have developers come on and off projects throughout their life cycle as they get interrupted by support for other projects etc. I completely agree and we have been starting to do daily standups. We have one person we are managing offsite for one particular project, so we're really throwing ourselves in the deep end with this one! I'll do my best to keep this thread updated as we learn from our mistakes so others can try to avoid them in the future. I have yet to set up LabVIEW Compare and what not, which I need to hack my way through this week. I found something on github that is supposed to help with this https://github.com/joerg/LabViewGitEnv so that is my next step. We'll see if I can manage.
-
Can I ask how big your development team(s) is/are?
-
So, I have been using the same tools, and pushing everything out to bitbucket. Are you doing the same? I will outline the workflow I have been following (essentially the gitflow built in to SourceTree), which may be complete overkill for small projects, but I also think it will work well for large projects. That said, I am debating with myself on the workflow between the following two things: ease of use for a particular project vs using a familiar workflow for all projects. If you use the same workflow for everything, it can be total overkill when you have a project that has a single developer. Yet, it can be more inefficient because you need to use a different workflow than you are used to using on larger projects. So, to be honest, right now I'm "playing" with each one to see how difficult it is to transition. So, because I am using bitbucket, my current workflow is as follows: 1) Every developer forks the main repo on bitbucket 2) In SourceTree, every developer adds two remotes: First is the upstream pointing at the main repo, second is the origin, pointing at their forked repo. (there is some debate out there as to which should be named which, but I am ignoring those things for now) 3) Each user clones the upstream repo giving them a "master" branch and a "develop" branch. 4) Set the local develop to track the master develop. Now, if any changes by other developers are pulled into the master develop, I will see I am behind locally. I then pull in those changes, merge with my local code, then push to my "origin" out on my forked remote in the cloud. When I am ready to add any changes I have made, I merge that feature branch into my develop. I push the develop to the origin (i.e. my fork in the cloud). From there I create a pull request, and pull everything into the master. The cycle then repeats itself. I do like the fork, because I can push my code to my origin and manage stuff there, without pushing it all to the master repo. Then, if I am working on a feature with others, they can pull those feature branches from my fork, but those features aren't out in the master repo. I also like the idea of pull requests because what I'm hoping to enforce is someone minimally involved in a project will be the main repo manager. The pull requests then force code reviews and discussion before anything is merged. This may be too big a bottle neck, but we will see. I like the idea of developers developing, and not dealing with repo management, and this helps that. Now, this all seems great in my head, but I haven't tested it much, so I have to put that disclaimer in here. I also haven't had to do any nightmare diffs and merges when there are conflicts, so we'll see how that goes. I think breaking tasks and features up into small chunks and committing early and committing often will help resolve some of these pain points. I'll let you know how things go as I move along. It's good to know other people are using similar tools. I also know this may be an opinionated subject and largely based on the types of development each of us does and the end customers we support. As such, I expect there to be different methods and work flows that all ensure equal success, so I think it's best to have as many outlined as possible allowing people to pick and choose, mix and match as they see fit. Edited for minor grammatical errors...
-
Hey everyone, I was just curious how many of you are using Git and what workflows you have found to work well with git and LabVIEW? Do you use the same workflow no matter the project, or the stage in the project? What about depending on the number of developers. I'm just looking for what others have found to be successful so I can avoid reinventing the wheel. This doesn't have to be only with relation to Git, but I'm assuming a workflow with regards to Mercurial will still translate relatively nicely. So, more generally, I suppose this question has to do with DVCS workflows. I know there are lists of them out there but I want to know what you, the LabVIEW developer, finds to work best. Feel free to add into the workflow github and bitbucket tidbits, since I am playing around with both of these to host the repositories as well.
-
Wow, I'm glad this sparked so many responses. To be honest, I never switched to file view except when I hit ctrl + e while the project was selected by accident instead of a VI . I think some of these methods listed above will be fine for what I'm trying to do. In general, I'm not sharing classes between projects too often, except for reuse code which is unlikely to change, so that shouldn't be an issue. I will play around with some of these and see how they work.