
LogMAN
-
Posts
717 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
Also make sure you don't have thousands of files in the installation directory - it slows down the verification process at the end of an installation.
-
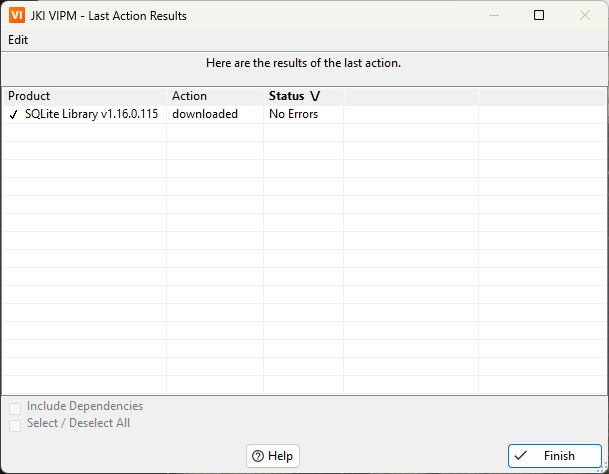
Yes this could be the same issue.
In my case, however, the issue is with SQLite Library (JDP Common Utilities installs normally). Strangely, the reported package URL works in the browser. Only VIPM is not able to download the file.
That said, I just tested it again and now it works for version 1.16.0 but not for 1.15.0. Again, there is no issue downloading the file with the reported URL: http://download.ni.com/evaluation/labview/lvtn/vipm/packages/drjdpowell_lib_sqlite_labview/drjdpowell_lib_sqlite_labview-1.15.0.114.vip

-
Cross-post: Unable to download certain packages through VIPM - VI Package Manager (VIPM) - VIPM Community
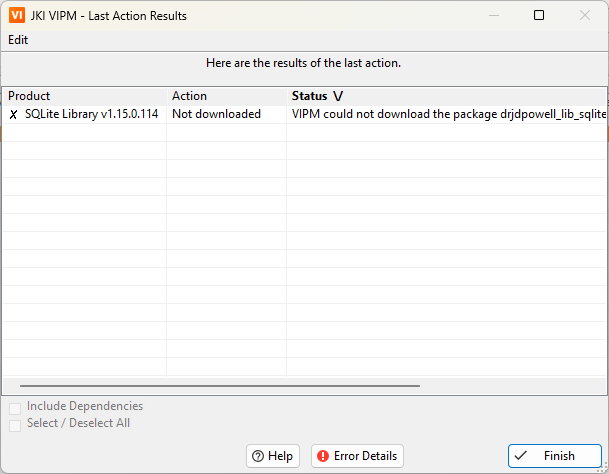
Does anyone else have trouble downloading certain packages through VIPM?
For example, I'm unable to download SQLite Library 1.16.0 because "VIPM could not download the package ... from the remote server."
I checked the error details and was able to locate the package on the server: https://download.ni.com/#evaluation/labview/lvtn/vipm/packages/drjdpowell_lib_sqlite_labview/
I tried different versions of VIPM, including 2019 and 2025.1 (build 2772) with no avail.
Other packages do not appear to be affected. Can someone confirm?
I'm able to download the package directly from the server with no issues so the problem is with VIPM.
-
Just installed it on my Ubuntu 22.04 machine, no problem.
Did you actually install LabVIEW according to the instructions @Bryan posted? Your logs only show the package feed being added to apt.
Make sure to follow the instructions from step 5 onwards. In particular, "sudo apt install ni-labview-2025-community".
QuoteWith the release of version 2023Q1, LabVIEW is installed using package feeds, which is the usual method of installing software on Linux distributions.
- Download the .zip file for the LabVIEW version and edition (Community, Full, Pro.) you wish to install.
- Open the .zip file and extract the package file (.rpm or .deb) for your Linux distribution and version.
- Install the package (e.g., For Ubuntu 20.04 use: sudo apt install ./ni-labview-2023-pro_23.1.0.49229-0+f77-ubuntu2004_all.deb)
-
When the package has installed, refresh the feeds for your package manager.
- For example, with Ubuntu use: sudo apt update
- The package manager now includes feeds for the repositories that contain the edition of LabVIEW you wish to install.
- Install LabVIEW with the Linux distribution package manager (apt, zypper, or yum)
-
The package name is in the format: ni-labview-<version>-<edition>
- The name of the .rpm/.deb file you extracted has the same name formatting, with extra numbers and supported OS.
- LabVIEW 2023 Professional Edition is called with ni-labview-2023-pro
- Ubuntu use: sudo apt install ni-labview-2023-pro
- You can use the search tools in package manager to find the correct package (e.g. apt search labview-2024)
- Reboot the PC
- Note: The LabVIEW Run Time Engine (RTE) package name is labview-2023-rte.
-
(Optional) Offline help can be installed with the ni-labview-offline-manual package.
- e.g., sudo apt install ni-labview-offline-manual
- Please note: The offline help application is known to be unstable on Ubuntu 22.04.
-
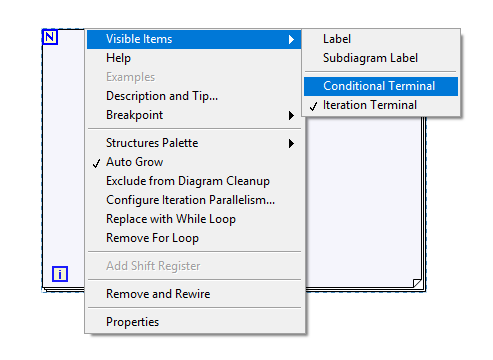
Apparently they moved it under Visible Items
Edit: This also affects other types of structures.
-
 1
1
-
 1
1
-
-
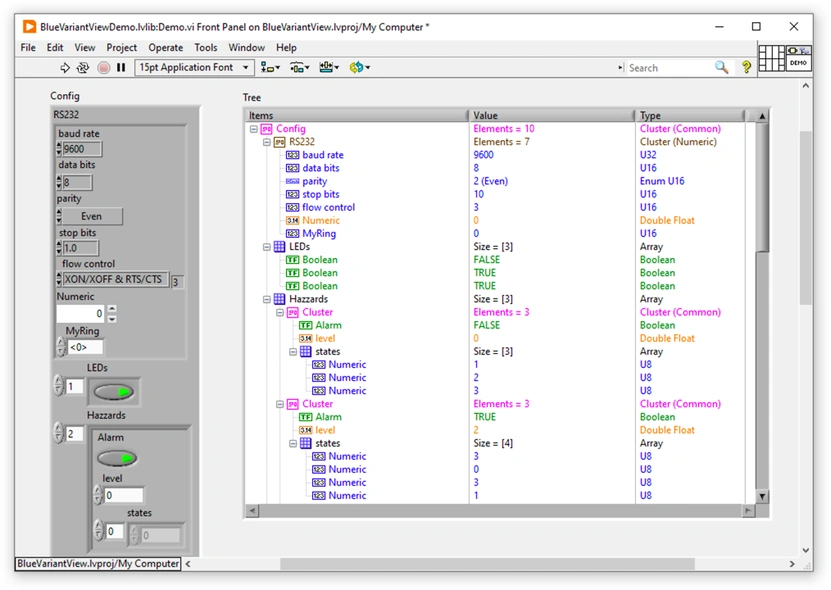
Yes this has been done before. I believe BlueVariantView is what you are looking for. It creates a recursive tree of any data type:
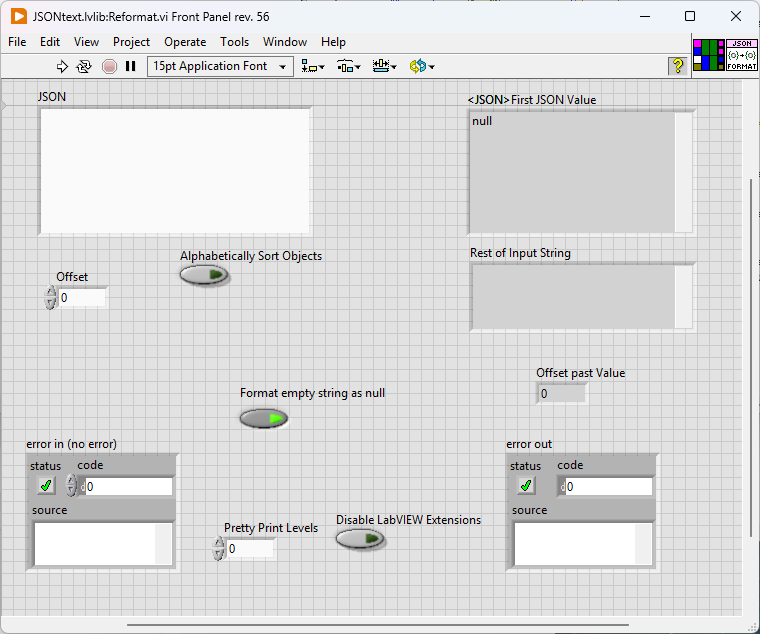
JSONtext on the other hand illustrates how to turn your data back into a data type.
-
1
-
-
In the context of this VI, "empty string" refers to the JSON terminal. If you don't provide any input, it will return null. Otherwise, it returns an error.
-
You probably mean https://labviewwiki.org/wiki/User_Groups. I saw your suggestion on the talk page and was going to split it between List of LabVIEW user groups - LabVIEW Wiki and User group - LabVIEW Wiki. Apparently "user groups" is okay, but "user group" is not 🤷♂️
-
Thanks!
On 1/10/2025 at 8:16 PM, Michael Aivaliotis said:I encourage everyone here on LAVA to find whatever LabVIEW topic they are passionate about and start adding some pages or even fleshing out some existing content that needs improvement. One way to start would be to find some information that you always wish NI had easily available on their website but could never get easy access to. Then create that on the Wiki.
Second that! The new wiki is also much more responsive, so editing has become a much more enjoyable experience
")
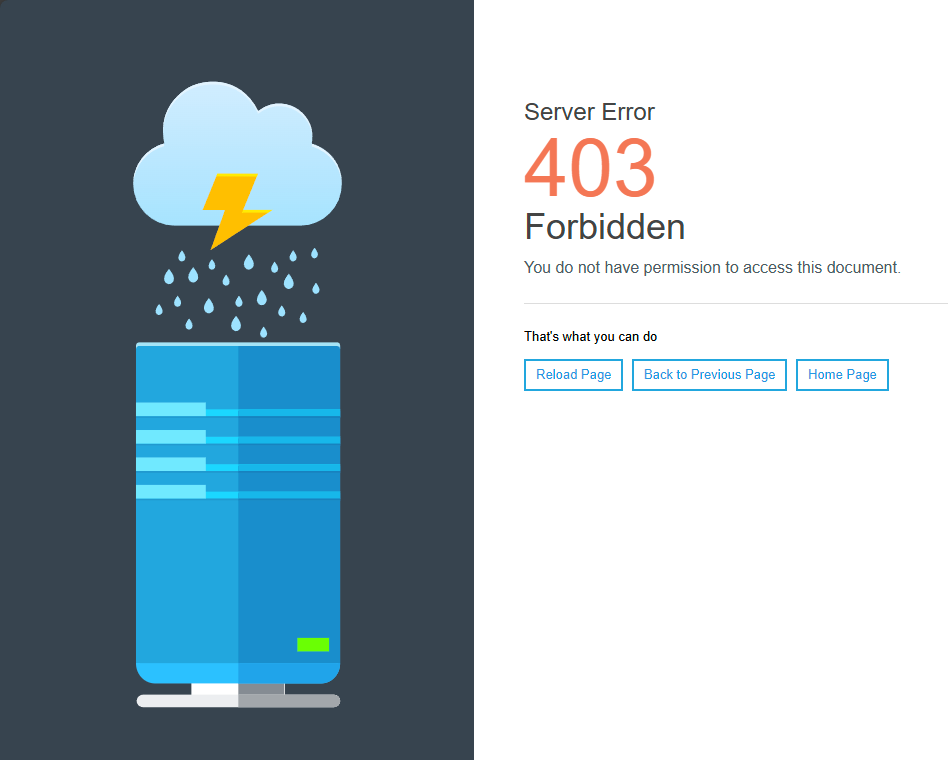
That said, here is another issue I stumbled upon: When attempting to edit https://labviewwiki.org/wiki/User_group (or the associated talk page), the server responds with "Server Error 403 Forbidden" and blocks the IP.
-
There are quite a few pages affected. Find below a complete list of the ones found with a quick script. Affected conferences are:
- Americas CLA Summit 2019
- GLA Summit 2020
- NIWeek 2019
- NIWeek 2020
If the channel cannot be restored, it would be great to have the videos for upload to a new channel that is not linked to the domain if anyone still got them. Just ping me and I'll upload them if you don't want to put them on your own channel. Otherwise, feel free to update the pages with the new video IDs.
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Architecting_for_Your_Customers
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Automating_IDE_Setup
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Building_Distributed_Systems_with_LabVIEW_and_ZeroMQ
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Complex_AF_-_Avoid_the_Pitfalls_of_Bad_Asynchronous_Programming
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Composed_Event_Logger_-_How_integrating_a_SOLID_Event_Logger_into_your_Applications_Reduces_Time_Spent_Debugging_Problems
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Decoupling_LabVIEW_and_Continuous_Integration
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Design_for_Research_(A_Case_Study_of_Building_a_Research_Metal_3D_Printer)
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Encapsulating_and_Reusing_your_UI_Code
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Expert_Panel:_Overcoming_Performance_Challenges
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Future_Proofing_Begins_With_Your_People_-_Lessons_Learned_from_My_Life_on_the_Outside
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Futureproofing_Software_with_Clean_Architecture
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/G_Interfaces
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/GCentral:_Removing_Barriers_to_a_Collaborative_Community
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Help!_I'm_out_of_letters_in_Quick_Drop!
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/High-Throughput_Video_Processing_to_Score_Heart_Rate_Responses_to_Xenobiotics_in_Wild-type_Embryonic_Zebrafish
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/How_YOU_can_design_amazing_looking_UIs
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Imperative_to_Functional_Programming
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Introduction_to_the_LabVIEW_Wiki
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Item_Manager_Framework_-_Future_Proofing_with_Dependency_Injection
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Keynote:_How_to_Leave_a_Legacy_Without_Leaving_Legacy_Software
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Keynote:_Practical_Methods_for_Software_Engineering_Idealism
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/LabVIEW_Performance_Tuning_Twenty_Years_Later
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Making_Modern_UIs_with_LabVIEW
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/NI_Presents:_Reusable_Add-on_Libraries
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/NI_Presents:_WebVIs
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/One_Library_To_Rule_Them_All
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Party_in_Front,_Business_in_Back:_Programming_The_Reverse_Mullet
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/PPLs_and_a_Better_Office_Experience
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Quick!_Drop_Your_VI_Execution_Time!
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Re-sizable_UI_and_Pane_Relief
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Scripting_in_LabVIEW_NXG
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Scripting_to_Save_Time
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Separation_Anxiety:_Designing_for_Change
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Sharing_LabVIEW_Code:_What_tools_are_good_for_what%3f
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Test_Driven_Development_in_Actor_Framework
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/The_Little_Things_in_LabVIEW_2020
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/The_Stacked_Sequence_is_Dead._Long_Live_the_Stacked_Sequence
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/UI/UX_Considerations_when_there_is_No_Keyboard_or_Mouse
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Unit_Testing_at_Mock_Speed
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/What's_New_in_GPM
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Why_You_Should_(Not%3f)_Write_Your_Own_Framework
- https://labviewwiki.org/wiki/Americas_CLA_Summit_2019/Zero_to_RF_in_420_Seconds
- https://labviewwiki.org/wiki/GLA_Summit_2020/TestStand_goes_Agile
- https://labviewwiki.org/wiki/NIWeek_2019/Achieve_Better_UIs_With_a_Dynamic_Sizing_Library_and_Object-Oriented_UI_Panels
- https://labviewwiki.org/wiki/NIWeek_2019/Achieve_Success_With_an_Intermodular_Communications_Framework
- https://labviewwiki.org/wiki/NIWeek_2019/Another_Kind_of_Actor_Model_with_LV_NXG
- https://labviewwiki.org/wiki/NIWeek_2019/Best_Practices_for_Building_and_Distributing_Componentized_LabVIEW_Applications
- https://labviewwiki.org/wiki/NIWeek_2019/Better,_Faster,_Stronger:_It's_Not_All_Technical
- https://labviewwiki.org/wiki/NIWeek_2019/By-Reference_Architectures_for_More_Flexible_Software_Design
- https://labviewwiki.org/wiki/NIWeek_2019/Code_Trafficking:_Smuggling_Your_Best_Software
- https://labviewwiki.org/wiki/NIWeek_2019/Creating_Powerful_Web_Apps_With_the_LabVIEW_NXG_Web_Module
- https://labviewwiki.org/wiki/NIWeek_2019/Customizing_Your_WebVIs
- https://labviewwiki.org/wiki/NIWeek_2019/Decoupling_LabVIEW_Object-Oriented_Programming_Classes_via_Abstraction
- https://labviewwiki.org/wiki/NIWeek_2019/Design_Patterns_for_Decoupled_UIs_in_LabVIEW:_Theory_and_Practice
- https://labviewwiki.org/wiki/NIWeek_2019/Designing_Advanced_LabVIEW-Based_HALs_and_Frameworks_for_Mindful_Extension
- https://labviewwiki.org/wiki/NIWeek_2019/Designing_Software_Like_LEGO®_Sets
- https://labviewwiki.org/wiki/NIWeek_2019/Effectively_Using_Packed_Project_Libraries
- https://labviewwiki.org/wiki/NIWeek_2019/Everything_a_Software_Engineer_Needs_to_Know_Outside_Software_Engineering
- https://labviewwiki.org/wiki/NIWeek_2019/From_Variant_Attributes_to_Sets_and_Maps_(New_in_2019)
- https://labviewwiki.org/wiki/NIWeek_2019/Get_Team_Buy-In:_Running_Process_Improvement_Workshops
- https://labviewwiki.org/wiki/NIWeek_2019/Good_Component_Design_for_LabVIEW_NXG
- https://labviewwiki.org/wiki/NIWeek_2019/How_to_Be_Ultra_Productive_With_OOP_in_LabVIEW_NXG_Using_UML
- https://labviewwiki.org/wiki/NIWeek_2019/I_Find_Your_Lack_of_LabVIEW_Programming_Speed_Disturbing
- https://labviewwiki.org/wiki/NIWeek_2019/Introduction_to_Migrating_LabVIEW_Code_to_LabVIEW_NXG
- https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_NXG:_Advisory_Lightning_Rounds
- https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_Reuse_and_Package_Management
- https://labviewwiki.org/wiki/NIWeek_2019/LabVIEW_Unit_Testing:_Outlook_&_Tutorial
- https://labviewwiki.org/wiki/NIWeek_2019/Lean_LabVIEW
- https://labviewwiki.org/wiki/NIWeek_2019/Malleable_VIs:_More_Flexible_Code
- https://labviewwiki.org/wiki/NIWeek_2019/Message_Exchange_Patterns_and_Tools_for_Distributed_Systems
- https://labviewwiki.org/wiki/NIWeek_2019/My_Continuously_Evolving_Practice_of_Software_Engineering
- https://labviewwiki.org/wiki/NIWeek_2019/On_Refactoring:_Real-World_Approaches_for_Improving_Code
- https://labviewwiki.org/wiki/NIWeek_2019/Prof_Watts'_Theory_on_Why_Programming_in_LabVIEW_is_Fun!
- https://labviewwiki.org/wiki/NIWeek_2019/Sharing_LabVIEW_Code:_What_Tools_Are_Good_For_What%3f
- https://labviewwiki.org/wiki/NIWeek_2019/Software_Engineering_in_LabVIEW:_A_Look_at_Tools_and_Processes
- https://labviewwiki.org/wiki/NIWeek_2019/These_Innovative_Tricks_for_ProjectRequirements_Will_Change_Your_Life
- https://labviewwiki.org/wiki/NIWeek_2019/Using_and_Abusing_Channel_Wires:_An_Exercise_in_Flexibility
- https://labviewwiki.org/wiki/NIWeek_2019/VI_Analyzer:_The_Unsung_Hero_of_Software_Quality_Control
- https://labviewwiki.org/wiki/NIWeek_2019/What's_New_on_LabVIEW_2019_and_NXG
- https://labviewwiki.org/wiki/NIWeek_2019/Who_Are_You_Developing_Your_HAL/MAL_For%3f_You_Or_The_Test_Engineer
- https://labviewwiki.org/wiki/VIWeek_2020/8_Reasons_for_encapsulating_your_next_device_driver_inside_a_DQMH_module
- https://labviewwiki.org/wiki/VIWeek_2020/CEF_(configuration_editor_framework)
- https://labviewwiki.org/wiki/VIWeek_2020/Confessions_of_a_Retired_Superhero
- https://labviewwiki.org/wiki/VIWeek_2020/Fast_and_Simple_Unit_Testing_with_Caraya_1.0
- https://labviewwiki.org/wiki/VIWeek_2020/Mock_Object_Framework
- https://labviewwiki.org/wiki/VIWeek_2020/Philosophy_of_Coding_-_How_to_be_a_CraftsPerson
- https://labviewwiki.org/wiki/VIWeek_2020/The_Core_Framework
- https://labviewwiki.org/wiki/VIWeek_2020/Using_a_Message_Broker_with_DQMH_Actors_for_High_Speed/Throughput_Data_logging
-
https://labviewwiki.org/wiki/VIWeek_2020/VIWeek_–_Open_Your_Instruments_With_A_G_Interfaces_HAL_In_LV2020_(No_Lever_Tool_Required!!)
-
12 hours ago, Michael Aivaliotis said:
Several others have reported it broken on the support page.
I did a quick test in a private MediaWiki instance and got it to work using the fix available on GitHub: Switch jquery.cookie to mediawiki.cookie by paladox · Pull Request #1 · debtcompliance/TreeAndMenu · GitHub
-
1
-
-
Thanks. The extension has not been updated since 2021. It is, however, listed as "stable".
There is another issue, the list of recent changes is not updating: https://labviewwiki.org/wiki/Special:RecentChanges
The most recent change listed is from December 27th, 2024.
-
Happy New Year!
This is great! It certainly feels more responsive and modern.
File deletion now also works, which means that we can finally get rid of old inappropriate files
")
The TreeAndMenu extension is missing, however, which breaks certain pages:
-
- Popular Post
- Popular Post
The examples you provide are invalid JSON, which makes it difficult to understand what you are actually trying to do.
In your VI, the input data is a 2D array of string but the JSON output is completely different. Your first step should be to define the types you need to produce the expected JSON output. Afterwards you can map your input data to the output data and simply convert it to JSON.
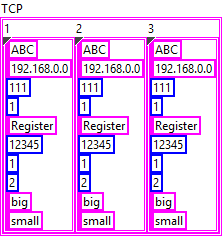
The structure of the inner-most object in your JSON appears to be the following:
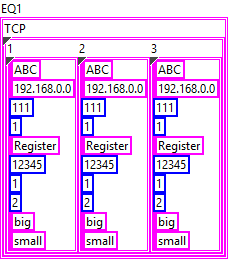
{ "Type":"ABC", "IP":"192.168.0.0", "Port":111, "Still":1, "Register":"Register", "Address":12345, "SizeLength":1, "FET":2, "Size":"big", "Conversion":"small" }In LabVIEW, this can be represented by a cluster:
When you convert this cluster to JSON, you'll get the output above.
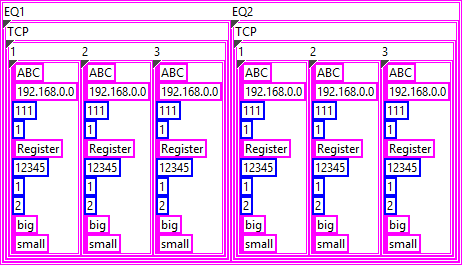
Now, the next level of your structure is a bit strange but can be solved in a similar manner. I assume that "1", "2", and "3" are instances of the object above:
{ "1": {}, "2": {}, "3": {} }So essentially, this is a cluster containing clusters:
The approach for the next level is practically the same:
{ "TCP": {} }
And finally, there can be multiple instances of that, which, again, works the same:
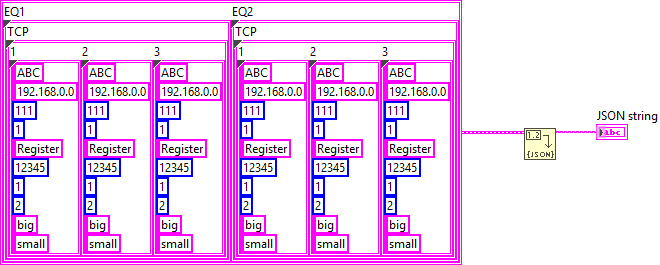
{ "EQ1": {}, "EQ2": {} }
This is the final form as far as I can tell. Now you can use either JSONtext or LabVIEW's built-in Flatten To JSON function to convert it to JSON
{"EQ1":{"TCP":{"1":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"2":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"3":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"}}},"EQ2":{"TCP":{"1":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"2":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"},"3":{"Type":"ABC","IP":"192.168.0.0","Port":111,"Still":1,"Register":"Register","Address":12345,"SizeLength":1,"FET":2,"Size":"big","Conversion":"small"}}}}The mapping of your input data should be straight forward.
-
3
-
Glad to hear you got it working!
The reason it doesn't update is explained in the documentation: https://www.ni.com/docs/en-US/bundle/labview/page/loading-net-assemblies.html#d62572e60
QuoteAfter LabVIEW loads an assembly into memory, the assembly stays in memory until you close the application instance that loaded the assembly. While an assembly is in memory, LabVIEW does not detect changes that you make to the assembly on disk. Therefore, before LabVIEW can access any changes to the assembly, you must update the assembly version in memory.
-
1
-
-
Welcome to the LAVA!
14 hours ago, jayfly said:Is there a way to allow for labview to exchange a struct and get the value back from the .net method?
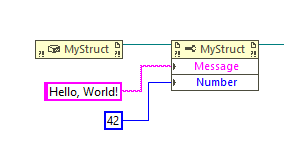
Wire your struct to a Property Node to access public properties and fields. You can set it to either read or write a value.
14 hours ago, jayfly said:In the dll code if I change the input to myStruct data1 (without the ref) I am able to invoke it but once I make it ref (as shown in the code) I get an error - 1316
Please be careful when changing signatures. LabVIEW does not automatically detect when the type of an argument changes. You'll have to manually update all calling sites to match the new signature which can lead to bad behavior.
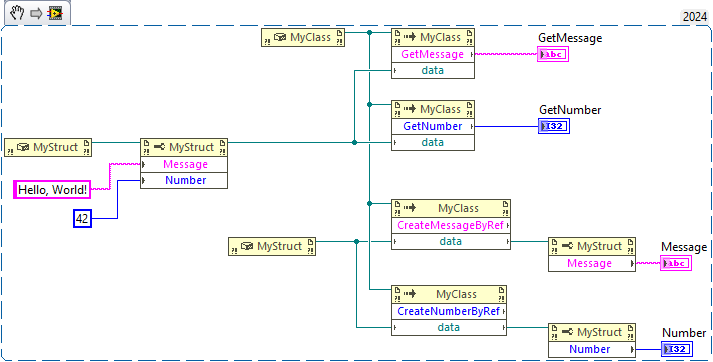
That said, calling by ref or by value both work. Here is a complete example for both of them:
namespace DemoLib { public struct MyStruct { public string Message { get; set; } public int Number { get; set; } } public class MyClass { public string GetMessage(MyStruct data) { return data.Message; } public int GetNumber(MyStruct data) { return data.Number; } public string CreateMessageByRef(ref MyStruct data) { data.Message = "Hello from CreateMessageByRef"; return data.Message; } public int CreateNumberByRef(ref MyStruct data) { data.Number = 42; return data.Number; } } }
-
1
-
-
Given a parent node, using Forward Browse should give you a list of child nodes, including their node ID: https://www.ni.com/docs/en-US/bundle/labview-opc-ua-toolkit-api-ref/page/opcuavis/opcua_forward_browse.html
-
I just went through the examples and everything appears to be working.
Edit: Running on Windows 11, using LabVIEW 2019 (32-bit)
As someone who is familiar with your SQLite library, it feels very familiar
Thanks for sharing!

-
1
-
-
Welcome to the forums!
1 hour ago, Cat said:If I have a "perpetual" license with 1 year service duration for LabVIEW, at the end of that year, if I don't renew the service, can I still use LabVIEW like always, as if I still had my old permanent license?
Yes this is exactly how the good old perpetual license works. Even without SSP the license is valid indefinitely.
At my work we also stayed with LabVIEW 2019 for our codebase. The old licenses are still valid and haven’t been renewed.
We have an additional subscription license for support reasons, though.
-
1
-
-
5 minutes ago, Bruniii said:
I simply want to make inconvenient to keep using it and, most importantly, to go to a third party client and distributed the application forever even if our partnership doesn't go thorough.
A couple of ideas:
- Include a license file that clearly explains what they can and cannot do (e.g., no distribution, no use without a valid license, 30 day trial period, etc.)
- Use a hardware dongle to prevent copies (you can just encrypt the executable, which can then only be started when the dongle is present. No programming required.)
-
If the application is not licensed (e.g., during a 30 day trial period
- Automatically shutdown the application after 30 minutes
- Limit the number of data points they can collect (e.g., limit file size to 1 Mib or 100k samples)
- Turn off certain features (e.g., limit the types of reports that can be produced)
Of course, it depends on what value the application represents and how "useful" it is outside your partnership. At some point, however, you will have to trust them enough to not misuse your software outside what is being agreed. If you don't trust them enough to uphold such an agreement, it is probably better not to go into a partnership...
-
Yes this happens sometimes. It typically fixes itself after reloading a few times.
To be fair, it never happened when actively browsing or editing pages. For me it mostly happens in the morning when I access it for the first time. And it manifests as a DNS lookup error.
-
I'm not familiar with FPGAs so this might not work, but there is a Timed Loop in LabVIEW: https://www.ni.com/docs/en-US/bundle/labview-api-ref/page/structures/timed-loop.html
Edit: Just noticed this note in the article linked above:
QuoteIf you use the Timed Loop in an FPGA VI, you must use a single-cycle Timed Loop. A single-cycle Timed Loop executes one subdiagram per FPGA clock cycle. Single-cycle Timed Loops do not support frames.
This might be relevant too: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000P8sWSAS&l=en-US
-
Yes! It is so much better now. Excellent work!
20 hours ago, Michael Aivaliotis said:BTW, I just discovered that if you ctrl+right click a posted image you can set its' size! neat.
-
Unfortunately, it seems that the site upgrade did not fix the spam issue. Are there any new options at your disposal?



[CR] JSONtext
in Code Repository (Certified)
Posted
This works as expected in version 1.7.0.118
Tested with LV2019 SP1 (32-bit)
{"status":false,"code":0,"source":""}