

jdunham
-
Posts
625 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jdunham
-
-
QUOTE (ShaunR @ Apr 27 2009, 07:25 AM)
Quite the converse in fact. You would use a queue to "queue" ( or buffer) the messages/data/etc (because you can't process them fast enough) in the hope that they may ease up later so you can get through the backlog.Queues are cool that they can even the load if your data is bursty, but queue or no queue, if you're not processing fast enough, you have a problem that queues couldn't fix.
QUOTE (ShaunR)
How can you not [need to inspect the incomding data]? Since there is data in the queue how does it know that its not for it? Thats what I call the nature of queues.I would never send data through a queue that wasn't meant for the queue listener. I would just use separate queues to send data to separate loops that were 100% devoted to handling that data.
OK, I give up trying to convince you. We obviously use queues in very different ways. I find them useful, even indispensable. My team's code doesn't suffer from any of those things you say queues suffer from, and we're doing things that you say are nearly impossible in LabVIEW, and they were pretty easy to code up and have great performance and scalability.
It's fine if you don't want to use more queues, but I don't think you'll manage to dissuade the rest of us.
-
QUOTE (ShaunR @ Apr 27 2009, 12:20 AM)
Queues do not have a wait function. Yes you can get similar behaviour IF you only ever have 1 message on the queue at asny one time, but if your producer(s) is faster than your consumer this is rarely the case. Therefore having an indefinite timeout makes no difference as your sub process still needs to inspoect the message to see if it was meant for it. So it is not sleeping, it is inspecting. You would then need a case for if the message wasn't for it and you can't just let it run through a tight loop so a wait so many milliseconds would be needed. So it's not sleeping evertime there is a message on the queue regardless of who it is for.Why would you use a queue if the producer is faster than the consumer? That's what notifiers are for. Why do you need wait functions if there is data available? Why is the receiver inspecting the data? Why would you let a queue consumer get data that wasn't meant for it? That's what I call a bug.
One way I like to think about it is that a queue is a 'dataflow wormhole' between parallel loops. Since you like dataflow as much as I do, maybe that makes it clearer why a queue is so useful.
QUOTE (ShaunR)
The only problem with globals arises when you require synchronisation. But that isn't really a problem, it is (a very useful) feature of globals.Well, do a Google search on "Global variables are bad". I got 400,000 hits. They are considered dangerous in every language. I have been using more unnamed queues and notifiers lately so that they are not available globally.
About my version of the sample application, I tried to add some asynchronous behavior to show the power of the queues. Did you read all the diagram comments? I though that would have answered your questions. It would be easy to modify it to match the original more closely. I took all the globals out because I think they are a defect, not a feature.
-
-
QUOTE (Aristos Queue @ Apr 26 2009, 11:56 AM)
QUOTE (Aristos Queue @ Apr 26 2009, 11:56 AM)
It better not be something that NI could change.I agree that the Not-a-Refnum primitive needs to be reliably the same between versions, but the internal format of the refnum is opaque, and I wouldn't depend on that. Any use of the typecast function to inspect internal formats is risky, and could be changed by NI without protest from me. Of course it's nice that it hasn't been changing a lot, but my code wouldn't depend a typecast anyway. In some decade it's entirely possible LV could go all 64-bit, and then I would expect typecasting a refnum to a U32 would probably break.
I'd rather have a separate namespace for queues and notifiers, if you're trying to fix stuff.
-
OK, I think we're converging: like queues and notifiers, think state machines are over-used. We're also proving that the way I spend my weekends is lame. Hopefully this is the last time I'll take the bait.
QUOTE (ShaunR @ Apr 25 2009, 05:03 PM)
Same thing would work better with a notifier. No polling, no latency.
Still confused why you started this thread!
 Queues are elegant and extremely useful. That's what the fuss is about. Where I think we agree is that if the system is NOT asynchronous and doesn't need event handling, then larding it up with an event handler or a state machine is not good.
Queues are elegant and extremely useful. That's what the fuss is about. Where I think we agree is that if the system is NOT asynchronous and doesn't need event handling, then larding it up with an event handler or a state machine is not good.I generally run these handlers with infinite timeout, so there is no timeout case (and no wait function). LabVIEW's internal execution scheduler may have to poll the queue somewhere deep in the bowels of LV, but that's not exposed to me. We have dozens of queues waiting in parallel with very low overhead and very low latency when an event is fired, so I suspect it's not polling at all, but is really sleeping. I don't know what you mean about a difference between queues and notifiers. As far as waiting and timing out, they act exactly the same.
http://lavag.org/old_files/post-1764-1240766707.zip'>Download File:post-1764-1240766707.zip
-
Can you connect to the camera with any other software running on the same computer? Typically the camera would have an IP address and would be listening on port 80. What happens if you put the camera address into a web browser or type "telnet <camera address> 80" at the Windows or Linux command line?
-
QUOTE (ShaunR @ Apr 23 2009, 11:18 AM)
I'm not exactly sure what you mean. I think the event structure is queued. If you invoke two or more value(signalling) properties then they will be handled on a FIFO basis, since there is some kind of queue behind the event structure. I agree it would be cool if LabVIEW made it easier to handle user and programmatic events in the same structure. I know you can register your own event, but it seems like a pain to me, when the queues are so easy.
QUOTE ( @ Apr 25 2009, 07:52 AM)
I was perusing the internet this afternoon and came accross this: -
QUOTE (Antoine Châlons @ Apr 24 2009, 01:12 AM)
I've just upgraded from TortoiseSVN 1.6.0 to 1.6.1, then restarted my computer and now my windows explorer will take between 5 and 10 seconds just to open a folder...If then I open the task manager and kill the process "TSVNCache.exe" windows explorer goes back to normal speed.
I started using TortoiseSVN only a month ago so I don't have alot of experience with it and I'm a bit scared now.. Anyone has the same behaviour ?
I googled "tortoise 1.6.1 performance" and the mailing list archives from earlier this week show that there is some kind of problem with the latest build. You could either pitch in and help them debug it or else roll back to 1.6.0.
I have used it for a couple years without any major problems. Long ago it was really slow, but then the cache was rewritten and it got a lot better (until last week, I guess). Anyway, don't give up!
-
QUOTE (ShaunR @ Apr 23 2009, 12:08 AM)
I'm not anti-queues. I just don't think they are the magic bullet to program design which some people (not necessarily on this forum) seem to think they are.OK, It's been a fun thread and most things everyones said are basically correct and don't need a response except the quoted line. I have written several large applications, including an enormous one with a team working on it now, and they use lots of queues [and notifiers] for event-driven behavior and they work great. There is plenty of asynchronous behavior, and the various user interface screens feel natural because they are event driven (with the event structure) and they use queues to communicate with the various processes they need to effect. Often the receive status updates via notifier.
Occasionally I am asked to do maintenance from very old programs before I started to use queues (some of them pre-date the introduction of queues), and not only do they work less naturally from the end user perspective, but it is a pain to maintain the code since everything is in one big hairy loop or else there are lots of crazy locals and globals causing race conditions. In addition those apps are not as big, because those problems get exponentially worse as the program size grows, so there is kind of a limit to how big the app can get before it is too much work.
Every time I experience this, I think, "Wow, queues are really the magic bullet to program design that makes large application development feasible in LabVIEW". I'm sure there could be other ways to develop large applications, but queues are very flexible and robust, and have a terrific API (unlike the horrible File I/O library), and have great performance. Obviously you have a different opinion, but I encourage you to try a big application with queues, and I think you won't go back.
-
I just started transferring a huge file with drag and drop on the Windows explorer, and LabVIEW threw error 5 when I tried to open it. I tried the same thing with LabVIEW doing the copy (using the Copy File primitive), and got the same result. So I think the original advice was good, and maybe you should fix your GETFILES.exe to be more compliant with Windows.
-
Thanks for starting a new thread. Here's a link to the old thread.
QUOTE (ShaunR @ Apr 21 2009, 11:42 AM)
I will concede Labview "parallelism" but I I think we are talking about concurrency and I would wholeheartedly agree that labview runs concurrent tasks but not parallel code. But it's not an area I'm an expert in and perhaps I'm being too pedantic (I don't really care how it works as long as it does...lol).If you have multiple processors, LabVIEW will run your nodes truly in parallel whether or not they are in different loops, different VIs, or just in different unconnected sections of a diagram, from everything I understand about their massive marketing blitz on this. If you only have one processor you will still see nice 'thread' scheduling that makes it seem like everything is working smoothly in parallel.
QUOTE (ShaunR)
I see events rather differently.Events (to me) are analogous to interrupts. Events can occur in any order and at any time and, on invocation, handler code is executed. A queue in Labview, however, does not generate events rather (from what you have described) you are taking the presence of data to mean that an event has occurred. You don't know what event has occurred until you have popped the element and decoded it The order is fixed (the position in the queue) and presumably, while this is happening, no other "events" can be processed so they cannot occur at any time (well perhaps they can occur at any time, but not be acted upon). The major difference between notifiers and queues is that notifiers can occur in any order and at any time and the "handler" (the section of code waiting) will be invoked.I would be interested to see how you handle priorities with a queue. Lets say (for example) Event 1 must always be executed straight away (user presses Emergency Stop) but event 2 can wait (acquisition data available. And just to be annoying, lets say processing the acquisition data takes 10 minutes and you've got 100 of them in the queue when the e-stop comes in ;P ).In an event driven environment, when Event 1 comes in its handler can check if the Event 2 is running and stop/pause it or postpone it (cut power and gracefully shut down acquisition).It's been a while since I messed with interrupts, but I don't think they are as different from queues as you think. On the microcontrollers I've used, if an interrupt comes in, other interrupts are masked, except for the non-maskable interrupt (which is your high-priority e-stop). One had to make the interrupt handling code as short as possible, otherwise other interrupts would stack up behind, just like in a labview queue. If you allowed new interrupts to be generated before the interrupt service routine finished, you risked infinite nesting of your interrupt calls.
With any event driven system, the maximum amount of time an event takes to be handled determines the latency of the system to handle new events. It would be nearly pointless to use any event-driven system to handle a 10-minute monolithic process. If you need to handle other events, you can usually break up a long process into many successive events, and throw the follow-on events from inside the handler. That's a state machine, which is another great use for a queue.
If you look at real-time OS design, it is basically the same problem. Every operation of the processor has to be divided into time slices, and between each one, the system has to check whether other higher-priority tasks are pending. You could easily implement this with LV queues, since you can flush the queue, and then evaluate whether the pending items should be reordered, and stuff them back into the front of the queue. How granular each event needs to be is just a design decision, and it's the same decision in an RTOS or a LV Queue-driven event handler.
If you need a high-priority system, like an emergency stop, that can interfere with the code inside any event handler, you should have a separate queue for that (in addition to whatever hardware interlocks you need).
QUOTE (ShaunR)
The major difference between notifiers and queues is that notifiers can occur in any order and at any time and the "handler" (the section of code waiting) will be invoked.No, the major difference is that queues are FIFO, and notifiers are broadcast events with no history. If your notifier handler is not fast enough, you will lose events rather than stacking them up and falling behind like a queue would.
So, I'm tired of typing now. What more is it going to take, besides the ardent fan base of dozens or hundreds of users on this board, to convince you that queues are actually pretty darn useful?
-
QUOTE (Chr1sG @ Apr 20 2009, 09:44 PM)
I mean, in logic terms the question asks which one of the following is false:...
Have I missed something?
Your paraphrase of the question is a lossy data transfer mechanism. The real question was "Which of the following statements about arrays is false..." Answer E is not a statement about arrays, so it can be the answer without having to be false. But you were right about it being confusing.
-
QUOTE (ShaunR @ Apr 20 2009, 04:21 PM)
QUOTE (ShaunR @ Apr 20 2009, 04:21 PM)
Actually Labview is inherently serial in nature (left to right). That is why you have to resort to other techniques to manage parallelism. I also fail to see how they are event driven given that you put something in the queue and take things out...nothing more. It is a serial buffer with access to only the first and/or last entry in the buffer.Well you're right 'inherently' was a poor word choice. Let me try again: In LabVIEW, parallelism is implicit when any two loops are not sequenced by a dataflow connection. In plain english 'parallel execution is easy in LabVIEW'.
Queues are event driven because a loop can be put to sleep until new data arrives. You actually have access to all the data in the buffer (Get Queue Status and Flush Queue). When you say 'nothing more', you are totally off the mark. Check out the Singleton design pattern in the LabVIEW examples for one cool application, and I already mentioned circular buffers.
QUOTE
I don't tend to use queues much, but I do extensively use notifiers for passing data and synchronising, which aren't really event driven either in so much you can wait for a notifier and it will get triggered. The only truely event driven features in Labview are the Event Structure and VISA Event.You can use queues as a notifier with guaranteed delivery. Queues are sort of like TCP and Notifiers like UDP. It turns out that TCP is used a bit more often, because in many situations, missing a message is not acceptable.
OK, I give up. What more would it need to be event driven? Just because the event is generated programmatically doesn't make it any less eventful.
QUOTE
But linking events programmatically accross disembodied vi's (which I use far too often); I've always found troublesome.Maybe if you used more queues, it would be less troublesome
 . I don't see anything wrong with disembodied VIs, especially if there is no direct dataflow (only events) connecting them.
. I don't see anything wrong with disembodied VIs, especially if there is no direct dataflow (only events) connecting them. Anyway Shaun, I don't mean to be jumping all over you. I hope you are enjoying the back-and-forth. (Looks like Mark Y beat me to it anyway).
QUOTE ( @ Apr 20 2009, 04:45 PM)
Notifiers are nothing more than a queue of size one.Well, notifiers are a lossy queue of size one, with multiple subscribers allowed, and some bonus features, like wait on notifier from multiple, and notification history.
-
QUOTE (Charles Chickering @ Apr 20 2009, 03:32 PM)
You may also want to check out http://forums.lavag.org/Providing-a-template-for-overrides-t13289.html&p=58591' target="_blank">this thread. It's not your specific problem, but AQ posts some code (which I haven't looked at) involving scripting a new DD VI.
-
QUOTE (ShaunR @ Apr 20 2009, 02:23 PM)
Am I right in thinking you would still have to have all the "NI stuff" anyway? (i.e the run-time engine).Oh for the days of standalone executables !
QUOTE (ShaunR)
And what is this obsession with queues on this site?Yeah the runtime would definitely be needed. Even Microsoft products have a runtime, but theirs is usually preinstalled with Windows or IE or something like that.
Queues help me because I find that it's easier to write pure dataflow on a small scale. Each device or object gets its own while loop to handle messages on its own schedule. If you try to put a whole complex app in one huge while loop, it's just too hard to program it so everything works nicely.
Once you have a bunch of parallel while loops in your application, queues are the best way to share data between them.
Also, LabVIEW dataflow is inherently by-value, and sometimes you really need a by-reference object, like if the dataset is huge, or needs to be protected by a mutex. Queues can do all that and more.
Now that there are lossy queues, you also get a free circular buffer implementation.
-
QUOTE (etipi @ Apr 19 2009, 10:31 AM)
I am new to Labview and started with my first application. I was reviewing an example VI and noticed that every label on block diagram has border which increase code readability. I could not find a way to set a border on labels. I appreciate if anyone explains how to set/configure it.Check your LabVIEW Block Diagram options (Tools -> Options -> Block Diagram) for "Transparent Free Labels". Although I think that the border decreases readability because it make the comments look like more like objects. As my friend Cicero used to say, "de gustibus non est disputandum".
You can also use the coloring tool to change an existing comment's color. However I don't think you can set a default color and border color. You only get to choose between black
+yellow or transparent. using the option I mentioned.
-
QUOTE (jabson @ Apr 17 2009, 12:38 PM)
There's probably an easy way to handle this specific case, but in the future this header could grow and have all sorts of new stuff in it. The suggested approach of just using a variant to hold the contents and a case statement to determine how the variant is interpreted seems like a good one. I've never worked with variants before but I guess this is exactly the type of situation they were created for, situations where the exact data type is not known at compile time.Yes, that's why variants exist.
One other note: When you use the enum to control a case structure, it will usually create a default case. Remove the default unless you absolutely need it. That way when you get a new type of variant to handle, and you add an item to your enum, then each of your relevant VIs will break until you add the required code to handle the new type. If you leave default cases around, it's very easy to forget one of them, and then you will have bugs.
Oh, and make sure the enum is a typedef!
-
QUOTE (jabson @ Apr 17 2009, 10:11 AM)
Thanks to everyone for the suggestions. They've confirmed my suspicion that there's no way to change the typedef at runtime and given me some ideas to try. What I'm leaning towards now is changing my typedef to be a "cluster of clusters" (each cluster corresponding to a different version of header format), and also containing a version field. The version field will get populated with the version number identifying the format of the data stream and then only the appropriate header cluster within the typedef will get populated with header data. The rest will remain at some default value. Code on the diagram then just needs to check the version field to determine which member of the typedef to read.I think you would be better off with a cluster containing an enum and a variant. The enum says which type it is, and then wherever you use the data, you have a case structure driven by the enum and inside that case structure you convert the variant data into the correct cluster. I have done this with plenty of programs and it works fine, and the separate clusters are more manageable than a big supercluster.
LVOOP gives you a cleaner way to do the exact same thing, but for one you don't want to get into that now, and for two, doing with an enum and a variant first will give you more appreciation for LVOOP when you finally get a chance to wrap your head around it.
-
It's kind of lame, but you could check the file modification time, and not copy any file which is less than 5 seconds old. Of course if your network is flaky, that may not be enough time. If you wrote getfiles.exe, then I agree with Ton that you should modify that program to copy to a temporary file name and rename it when the download finishes.
-
-
-
QUOTE (Black Pearl @ Apr 14 2009, 12:16 AM)
Our main issue is the security on the server side. Only those developers that are on a certain project should have access to the source code. And we would like not to completley relay on the OS permissions.There are lots of good suggestions here, but if you care about server security, you would be *crazy* not to run SVN over https://. Many, many engineers have devoted huge efforts in making https reasonably secure (if administered properly) and no other hack you can do yourself is going to be as effective or have as much engineering and reliability behind it.
Start with https, and if that's not secure enough (using TrueCrypt for your working copies may be advisable too) then you can either ask here or on many of the internets security forums for more advice.
-
QUOTE (Mark Yedinak @ Apr 14 2009, 10:44 AM)
I have been burned in the past using NI's binary save when as you mentioned newer versions were not able to open older versions.I don't understand this. The flatten/unflatten functions have compatilibility modes. If you right-click on them, you can specify 4.x data or 7.x data. If you upgrade software written in those versions, those options will be automatically selected. NI has generally been good about this.
I'm not sure flattened data is my favorite storage format, but I wouldn't think to worry about upgrade issues. Since I haven't been storing that way, maybe I am off base here.
If you have performance issues, then I think you would need to explain the constraints before anyone else could give you an opinion about the easiest way to program around them. If you have real performance issues, then a real database with native data types like Mark suggested could be appropriate. If you are just 'worried' about performance, then just code up what is easiest, and if it performs acceptably, you could probably leave it alone.
-
QUOTE (Pollux @ Apr 13 2009, 12:30 PM)
I have implemented the queue version and it works fine.New question: what would be a clean method to close my program?
There was a diagram earlier in the thread which showed checking the App.Kind property and only exiting LabVIEW if the run-time system (a built executable) is running.
For killing a queued message handler, you can just destroy the queue itself (put this at the end of your event handler loop), and any other loop waiting on that queue will terminate immediately. Those other loops with throw Error 1, which you should filter out.
 . Never mind.
. Never mind.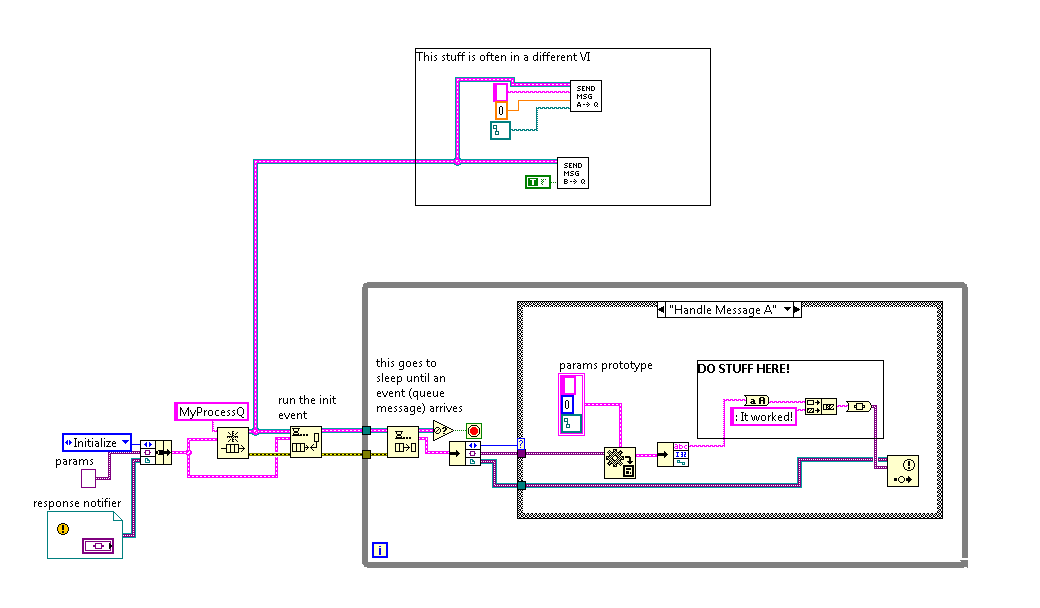
installing TortoiseSVN 1.6.1 slowed windows explorer alot !
in Source Code Control
Posted
QUOTE (Antoine Châlons @ Apr 27 2009, 05:17 AM)
I suspect you are fine. AFAIK, TSVNCache is just a performance enhancement. It's job is to keep all the SVN glyphs on your icons accurate, so that if you change one file five subfolders down, then all if its parents in any open Explorer window will change their glyphs to show they've been modified. It's all about the icons and has nothing to do with your data or your working copy except for monitoring the status. I don't see how killing it could cause any problem except the icons are slower to update or fail to refresh themselves.